
 Technology peripherals
AI
Break the black box of large models and completely decompose neurons! OpenAI rival Anthropic breaks down AI unexplainability barrier
Technology peripherals
AI
Break the black box of large models and completely decompose neurons! OpenAI rival Anthropic breaks down AI unexplainability barrier
Break the black box of large models and completely decompose neurons! OpenAI rival Anthropic breaks down AI unexplainability barrier

For many years, we have been unable to understand how artificial intelligence makes decisions and produces output
Model developers can only decide on algorithms, data, and finally get the model Output results, and the middle part - how the model outputs results based on these algorithms and data, becomes an invisible "black box".

So there is a joke like "model training is like alchemy".
But now, the model black box is finally interpretable!
The research team from Anthropic extracted the interpretable features of the most basic unit neurons in the model’s neural network.

This will be a landmark step for mankind to uncover the black box of AI.
Anthropic expressed excitedly:
"If we can understand how the neural network in the model works, then we can diagnose the faults of the model. Patterns, design fixes, and safe adoption by businesses and society will become a within-reaching reality!"
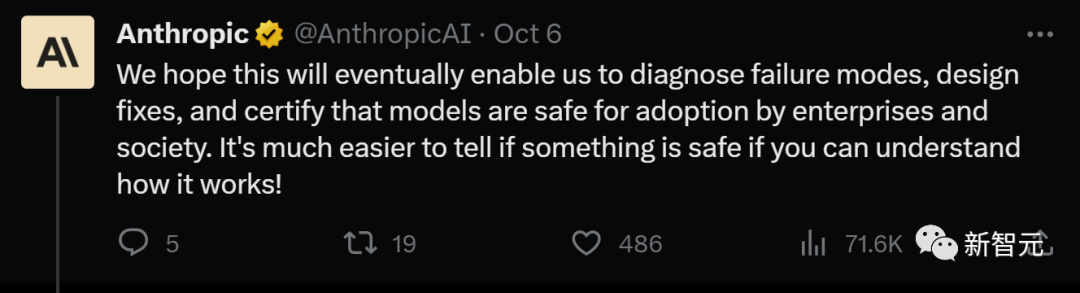
at Anthropic In the latest research report "Towards Monosemanticity: Using Dictionary Learning to Decompose Language Models", researchers used dictionary learning methods to successfully decompose a layer containing 512 neurons into more than 4,000 interpretable features

Research report address: https://transformer-circuits.pub/2023/monosemantic-features/index.html
These features represent DNA sequences, legal language, HTTP requests, Hebrew text, and nutrition instructions, etc.
When we look at the activation of a single neuron in isolation, we It is impossible to see most of these model properties
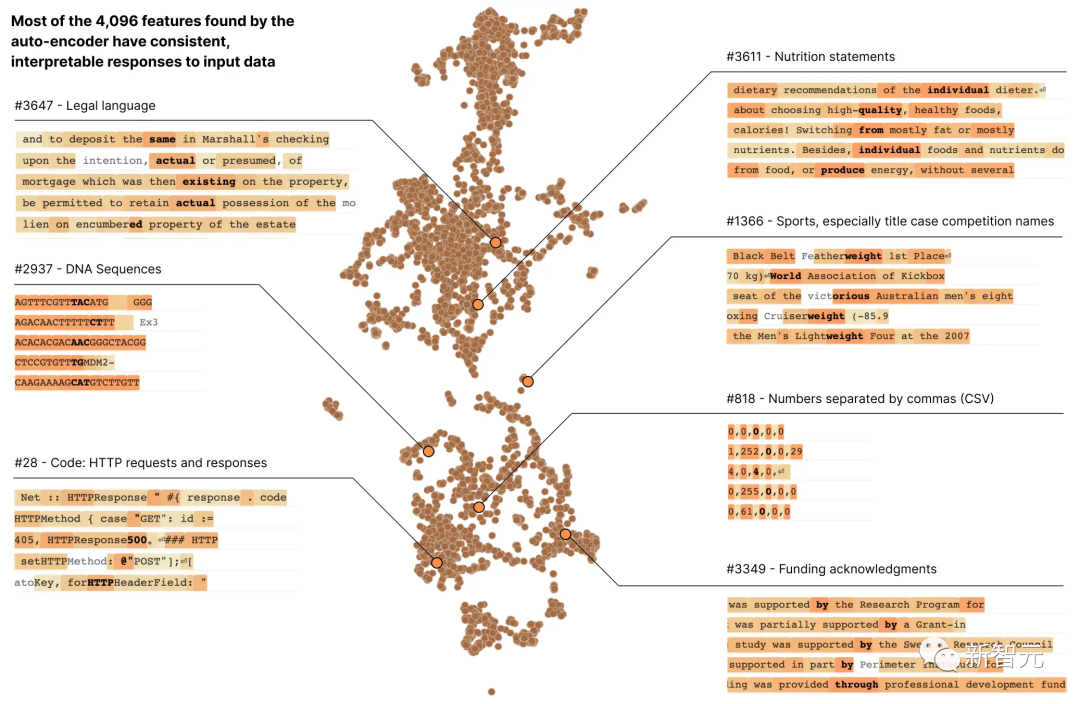
Most neurons are "polysemantic", meaning that a single neuron is There is no consistent correspondence between network behaviors
For example, in a small language model, a single neuron is active in many unrelated contexts, including: academic citations, English Conversations, HTTP requests, and Korean text.
In the classic vision model, a single neuron responds to the face of a cat and the front of a car.
In different contexts, many studies have demonstrated that the activation of a neuron can have different meanings
One potential reason is that the polysemantic nature of neurons is due to the additive effect. This is a hypothetical phenomenon whereby neural networks represent independent features of data by assigning each feature its own linear combination of neurons, and the number of such features exceeds the number of neurons
If each feature is regarded as a vector on a neuron, then the feature set forms an overcomplete linear basis for the activation of network neurons.
In Anthropic’s previous Toy Models of Superposition paper, it was proved that sparsity can eliminate ambiguity in neural network training and help the model better understand features. relationship between them, thereby reducing the uncertainty of the source features of the activation vector and making the model’s predictions and decisions more reliable.
This concept is similar to the idea in compressed sensing, where the sparsity of the signal allows the complete signal to be restored from limited observations.

But among the three strategies proposed in Toy Models of Superposition:
# (1) Create a model without superposition, Perhaps activation sparsity can be encouraged;
(2) In models that exhibit superposition states, dictionary learning is used to find overcomplete features
(3) relies on a hybrid approach that combines the two.
What needs to be rewritten is: method (1) cannot solve the problem of ambiguity, while method (2) is prone to serious overfitting
So this time Anthropic researchers used a weak dictionary learning algorithm called a sparse autoencoder to generate learned features from the trained model that provide better performance than model neurons itself a more unitary unit of semantic analysis.
Specifically, the researchers adopted an MLP single-layer transformer with 512 neurons, and finally trained a sparse autoencoder on MLP activations from 8 billion data points. Decomposing MLP activations into relatively interpretable features, expansion factors range from 1× (512 features) to 256× (131,072 features).
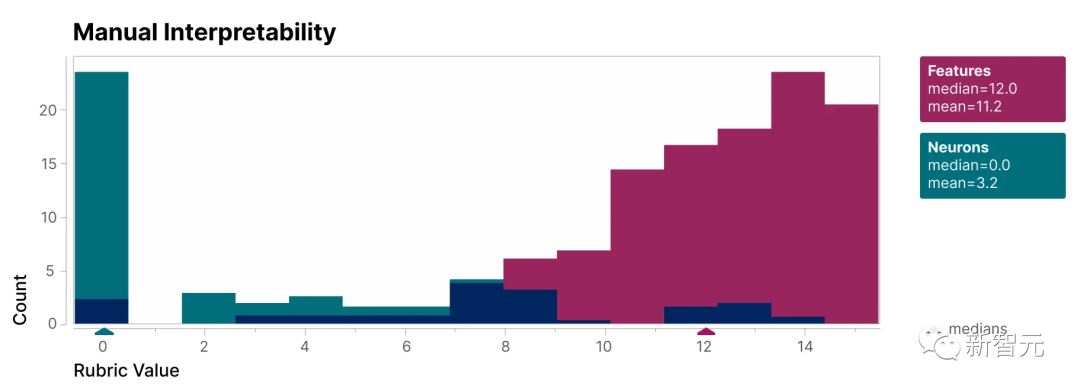
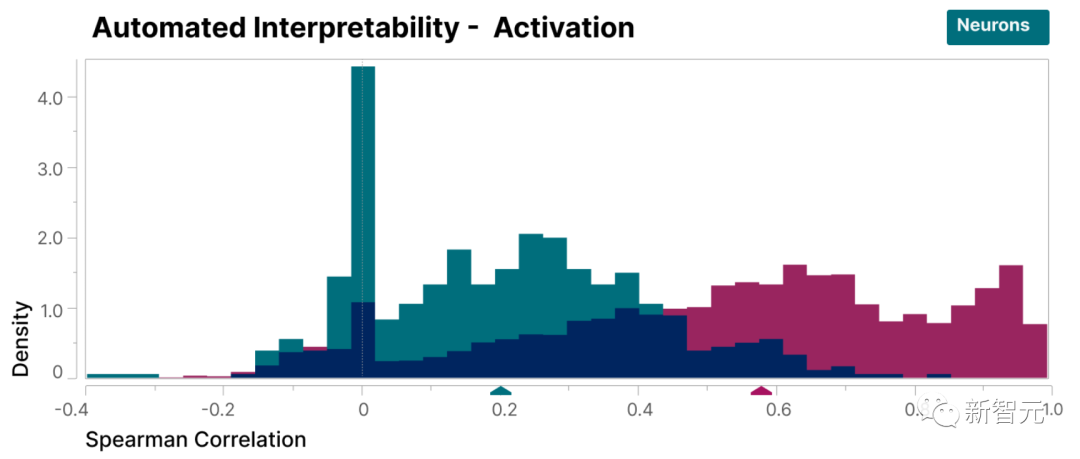
To verify that the features found in this study are more interpretable than the model's neurons, we conducted a blind review and asked a human evaluator to evaluate their interpretability. Rating
As you can see, the feature (red) has a much higher score than the neuron (cyan).
It has been shown that the features discovered by the researchers are easier to understand relative to the neurons inside the model
Additionally, the researchers adopted an "automated interpretability" approach by using a large language model to generate a short description of a small model's features and having another model score that description based on its ability to predict feature activation. .
Likewise, features score higher than neurons, demonstrating a consistent interpretation of the activation of features and their downstream effects on model behavior.
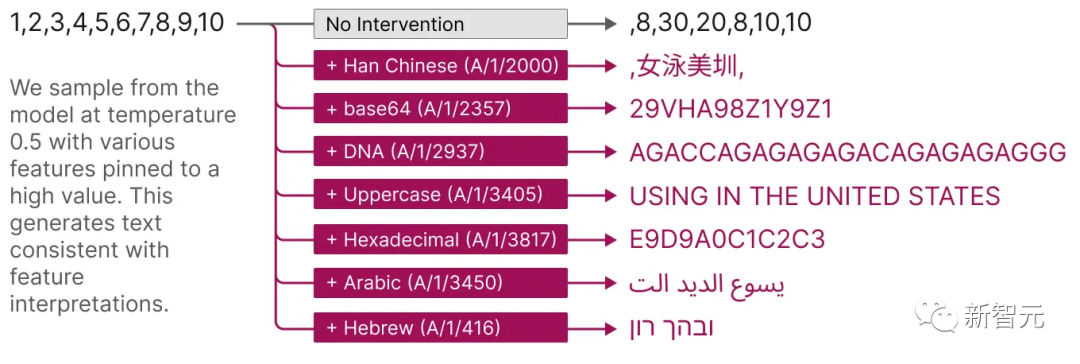
Moreover, these extracted features also provide a targeted method to guide the model.
As shown in the figure below, artificially activating features can cause model behavior to change in predictable ways.
The following is a visualization of the extracted interpretability features:
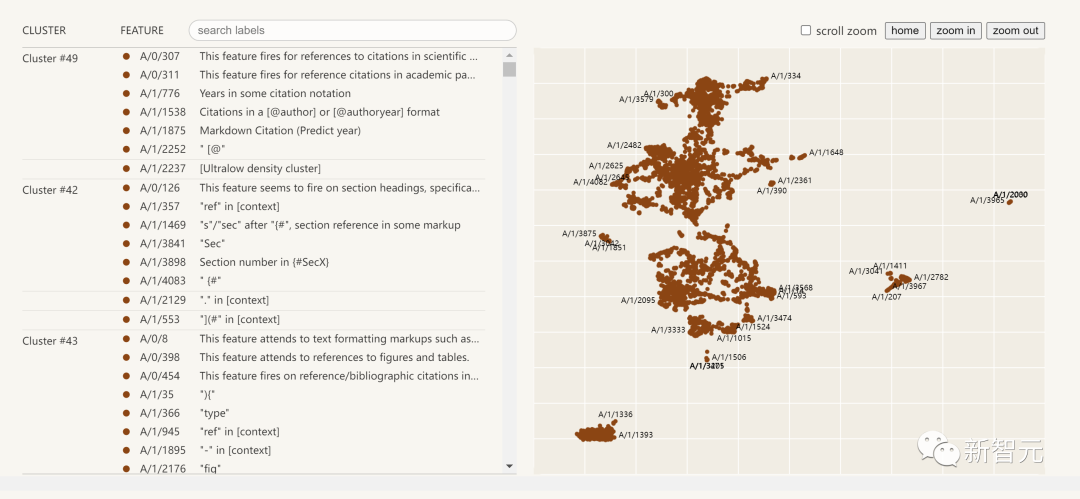
Click on the feature list on the left to interactively explore the feature space in the neural network
Research Report Summary
This research report from Anthropic, Towards Monosemanticity: Decomposing Language Models With Dictionary Learning, can be divided into four parts.
Problem setting, the researchers introduced the research motivation and elaborated on the trained transfomer and sparse autoencoder.
Detailed investigation of individual features proves that several features found in the study are functionally specific causal units.
Through global analysis, we conclude that the typical features are interpretable and they are able to explain important components of the MLP layer
Phenomenon analysis describes several properties of features, including feature segmentation, universality, and how they form systems similar to "finite state automata" to achieve complex behaviors.
The conclusions include the following 7:
Sparse autoencoder has the ability to extract relatively single semantic features
Sparse autoencoders are able to generate interpretable features that are actually invisible in the basis of neurons
3. Sparse Autoencoders Features can be used to intervene and guide the generation of transformers.
4. Sparse autoencoders can generate relatively general features.
As the size of the autoencoder increases, features tend to "split". After rewriting: As the size of the autoencoder increases, features show a trend of "splitting"
#6. Only 512 neurons can represent thousands of features
7. These features are connected together, similar to a "finite state automaton" system, to achieve complex behaviors, as shown in the figure below
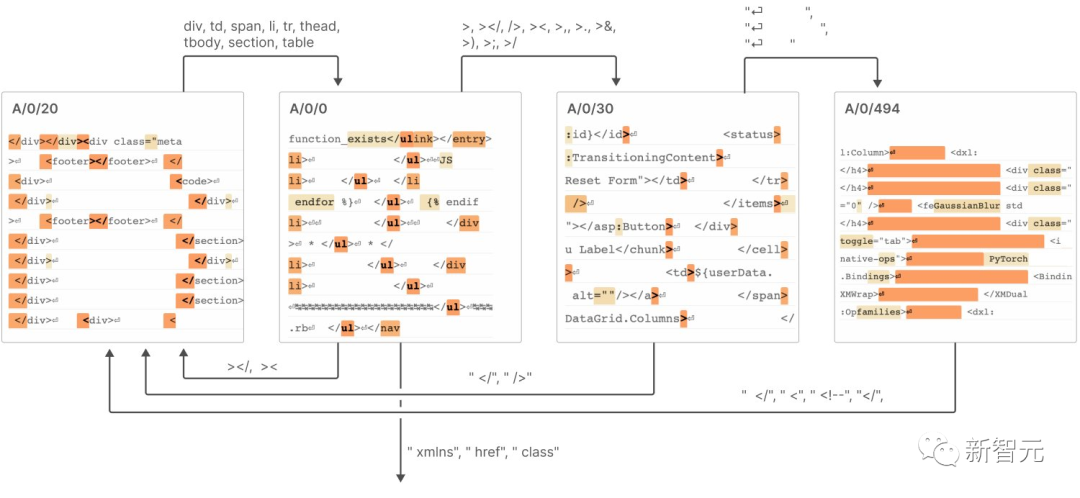
Specific details can be found in the report.
Anthropic believes that to replicate the success of the small model in this research report to a larger model, the challenge we face in the future will no longer be a scientific problem, but an engineering problem
Achieving interpretability on large models requires more effort and resources in engineering to overcome the challenges posed by model complexity and size
Includes developing new tools, techniques and methods to cope with the challenges of model complexity and data scale; it also includes building scalable interpretive frameworks and tools to adapt to the needs of large-scale models.
This will become the latest trend in interpretive artificial intelligence and large-scale deep learning research
The above is the detailed content of Break the black box of large models and completely decompose neurons! OpenAI rival Anthropic breaks down AI unexplainability barrier. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1377
1377
 52
52

 Use ddrescue to recover data on Linux
Mar 20, 2024 pm 01:37 PM
Use ddrescue to recover data on Linux
Mar 20, 2024 pm 01:37 PM
DDREASE is a tool for recovering data from file or block devices such as hard drives, SSDs, RAM disks, CDs, DVDs and USB storage devices. It copies data from one block device to another, leaving corrupted data blocks behind and moving only good data blocks. ddreasue is a powerful recovery tool that is fully automated as it does not require any interference during recovery operations. Additionally, thanks to the ddasue map file, it can be stopped and resumed at any time. Other key features of DDREASE are as follows: It does not overwrite recovered data but fills the gaps in case of iterative recovery. However, it can be truncated if the tool is instructed to do so explicitly. Recover data from multiple files or blocks to a single
 Open source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!
Apr 03, 2024 pm 12:04 PM
Open source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!
Apr 03, 2024 pm 12:04 PM
0.What does this article do? We propose DepthFM: a versatile and fast state-of-the-art generative monocular depth estimation model. In addition to traditional depth estimation tasks, DepthFM also demonstrates state-of-the-art capabilities in downstream tasks such as depth inpainting. DepthFM is efficient and can synthesize depth maps within a few inference steps. Let’s read about this work together ~ 1. Paper information title: DepthFM: FastMonocularDepthEstimationwithFlowMatching Author: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 How to use Excel filter function with multiple conditions
Feb 26, 2024 am 10:19 AM
How to use Excel filter function with multiple conditions
Feb 26, 2024 am 10:19 AM
If you need to know how to use filtering with multiple criteria in Excel, the following tutorial will guide you through the steps to ensure you can filter and sort your data effectively. Excel's filtering function is very powerful and can help you extract the information you need from large amounts of data. This function can filter data according to the conditions you set and display only the parts that meet the conditions, making data management more efficient. By using the filter function, you can quickly find target data, saving time in finding and organizing data. This function can not only be applied to simple data lists, but can also be filtered based on multiple conditions to help you locate the information you need more accurately. Overall, Excel’s filtering function is a very practical
 Google is ecstatic: JAX performance surpasses Pytorch and TensorFlow! It may become the fastest choice for GPU inference training
Apr 01, 2024 pm 07:46 PM
Google is ecstatic: JAX performance surpasses Pytorch and TensorFlow! It may become the fastest choice for GPU inference training
Apr 01, 2024 pm 07:46 PM
The performance of JAX, promoted by Google, has surpassed that of Pytorch and TensorFlow in recent benchmark tests, ranking first in 7 indicators. And the test was not done on the TPU with the best JAX performance. Although among developers, Pytorch is still more popular than Tensorflow. But in the future, perhaps more large models will be trained and run based on the JAX platform. Models Recently, the Keras team benchmarked three backends (TensorFlow, JAX, PyTorch) with the native PyTorch implementation and Keras2 with TensorFlow. First, they select a set of mainstream
 Slow Cellular Data Internet Speeds on iPhone: Fixes
May 03, 2024 pm 09:01 PM
Slow Cellular Data Internet Speeds on iPhone: Fixes
May 03, 2024 pm 09:01 PM
Facing lag, slow mobile data connection on iPhone? Typically, the strength of cellular internet on your phone depends on several factors such as region, cellular network type, roaming type, etc. There are some things you can do to get a faster, more reliable cellular Internet connection. Fix 1 – Force Restart iPhone Sometimes, force restarting your device just resets a lot of things, including the cellular connection. Step 1 – Just press the volume up key once and release. Next, press the Volume Down key and release it again. Step 2 – The next part of the process is to hold the button on the right side. Let the iPhone finish restarting. Enable cellular data and check network speed. Check again Fix 2 – Change data mode While 5G offers better network speeds, it works better when the signal is weaker
 The vitality of super intelligence awakens! But with the arrival of self-updating AI, mothers no longer have to worry about data bottlenecks
Apr 29, 2024 pm 06:55 PM
The vitality of super intelligence awakens! But with the arrival of self-updating AI, mothers no longer have to worry about data bottlenecks
Apr 29, 2024 pm 06:55 PM
I cry to death. The world is madly building big models. The data on the Internet is not enough. It is not enough at all. The training model looks like "The Hunger Games", and AI researchers around the world are worrying about how to feed these data voracious eaters. This problem is particularly prominent in multi-modal tasks. At a time when nothing could be done, a start-up team from the Department of Renmin University of China used its own new model to become the first in China to make "model-generated data feed itself" a reality. Moreover, it is a two-pronged approach on the understanding side and the generation side. Both sides can generate high-quality, multi-modal new data and provide data feedback to the model itself. What is a model? Awaker 1.0, a large multi-modal model that just appeared on the Zhongguancun Forum. Who is the team? Sophon engine. Founded by Gao Yizhao, a doctoral student at Renmin University’s Hillhouse School of Artificial Intelligence.
 The first robot to autonomously complete human tasks appears, with five fingers that are flexible and fast, and large models support virtual space training
Mar 11, 2024 pm 12:10 PM
The first robot to autonomously complete human tasks appears, with five fingers that are flexible and fast, and large models support virtual space training
Mar 11, 2024 pm 12:10 PM
This week, FigureAI, a robotics company invested by OpenAI, Microsoft, Bezos, and Nvidia, announced that it has received nearly $700 million in financing and plans to develop a humanoid robot that can walk independently within the next year. And Tesla’s Optimus Prime has repeatedly received good news. No one doubts that this year will be the year when humanoid robots explode. SanctuaryAI, a Canadian-based robotics company, recently released a new humanoid robot, Phoenix. Officials claim that it can complete many tasks autonomously at the same speed as humans. Pheonix, the world's first robot that can autonomously complete tasks at human speeds, can gently grab, move and elegantly place each object to its left and right sides. It can autonomously identify objects
 The U.S. Air Force showcases its first AI fighter jet with high profile! The minister personally conducted the test drive without interfering during the whole process, and 100,000 lines of code were tested for 21 times.
May 07, 2024 pm 05:00 PM
The U.S. Air Force showcases its first AI fighter jet with high profile! The minister personally conducted the test drive without interfering during the whole process, and 100,000 lines of code were tested for 21 times.
May 07, 2024 pm 05:00 PM
Recently, the military circle has been overwhelmed by the news: US military fighter jets can now complete fully automatic air combat using AI. Yes, just recently, the US military’s AI fighter jet was made public for the first time and the mystery was unveiled. The full name of this fighter is the Variable Stability Simulator Test Aircraft (VISTA). It was personally flown by the Secretary of the US Air Force to simulate a one-on-one air battle. On May 2, U.S. Air Force Secretary Frank Kendall took off in an X-62AVISTA at Edwards Air Force Base. Note that during the one-hour flight, all flight actions were completed autonomously by AI! Kendall said - "For the past few decades, we have been thinking about the unlimited potential of autonomous air-to-air combat, but it has always seemed out of reach." However now,
