

Inference efficiency issues of machine learning models


The inference efficiency of machine learning models requires specific code examples
Introduction
With the development and widespread application of machine learning, people are concerned about Model training is attracting more and more attention. However, for many real-time applications, the inference efficiency of the model is also crucial. This article will discuss the inference efficiency of machine learning models and give some specific code examples.
1. The Importance of Inference Efficiency
The inference efficiency of a model refers to the ability of the model to quickly and accurately provide output given the input. In many real-life applications, such as real-time image processing, speech recognition, autonomous driving, etc., the requirements for inference efficiency are very high. This is because these applications need to process large amounts of data in real time and respond promptly.
2. Factors affecting reasoning efficiency
- Model architecture
Model architecture is one of the important factors affecting reasoning efficiency. Some complex models, such as Deep Neural Network (DNN), may take a long time during the inference process. Therefore, when designing models, we should try to choose lightweight models or optimize them for specific tasks.
- Hardware equipment
Hardware equipment also affects inference efficiency. Some emerging hardware accelerators, such as Graphic Processing Unit (GPU) and Tensor Processing Unit (TPU), have significant advantages in accelerating the inference process of models. Choosing the right hardware device can greatly improve inference speed.
- Optimization technology
Optimization technology is an effective means to improve reasoning efficiency. For example, model compression technology can reduce the size of the model, thereby shortening the inference time. At the same time, quantization technology can convert floating-point models into fixed-point models, further improving inference speed.
3. Code Examples
The following are two code examples that demonstrate how to use optimization techniques to improve inference efficiency.
Code Example 1: Model Compression
import tensorflow as tf
from tensorflow.keras.applications import MobileNetV2
from tensorflow.keras.models import save_model
# 加载原始模型
model = MobileNetV2(weights='imagenet')
# 保存原始模型
save_model(model, 'original_model.h5')
# 模型压缩
compressed_model = tf.keras.models.load_model('original_model.h5')
compressed_model.save('compressed_model.h5', include_optimizer=False)In the above code, we use the tensorflow library to load a pre-trained MobileNetV2 model and save it as the original model. Then, use the model for compression, saving the model as compressed_model.h5 file. Through model compression, the size of the model can be reduced, thereby increasing the inference speed.
Code Example 2: Using GPU Acceleration
import tensorflow as tf
from tensorflow.keras.applications import MobileNetV2
# 设置GPU加速
physical_devices = tf.config.list_physical_devices('GPU')
tf.config.experimental.set_memory_growth(physical_devices[0], True)
# 加载模型
model = MobileNetV2(weights='imagenet')
# 进行推理
output = model.predict(input)In the above code, we use the tensorflow library to load a pre-trained MobileNetV2 model and set the model's inference process to GPU acceleration. By using GPU acceleration, inference speed can be significantly increased.
Conclusion
This article discusses the inference efficiency of machine learning models and gives some specific code examples. The inference efficiency of machine learning models is very important for many real-time applications. Inference efficiency should be considered when designing models and corresponding optimization measures should be taken. We hope that through the introduction of this article, readers can better understand and apply inference efficiency optimization technology.
The above is the detailed content of Inference efficiency issues of machine learning models. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



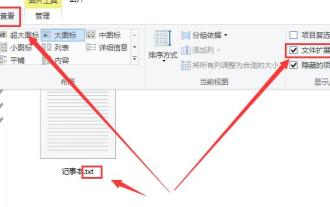 How to change the file extension of Win10 Notepad
Jan 04, 2024 pm 12:49 PM
How to change the file extension of Win10 Notepad
Jan 04, 2024 pm 12:49 PM
When using Notepad, we need to change the extension of Notepad due to different things we need to deal with. So how do we change the extension? In fact, we only need to use the rename function to modify the extension. How to change the extension of Win10 Notepad: 1. In the folder, first click on the top and check it. 2. In this way, the file extension will be displayed, then right-click your notepad and select 3. Select. Change the following. 4. If changed to .jpeg format. Then a prompt will pop up, click on it. 5. The change is completed, and that’s it.
 Call SQL trigger to execute external program
Feb 18, 2024 am 10:25 AM
Call SQL trigger to execute external program
Feb 18, 2024 am 10:25 AM
Title: Specific code examples for SQL triggers to call external programs Text: When using SQL triggers, sometimes it is necessary to call external programs to process some specific operations. This article will introduce how to call external programs in SQL triggers and give specific code examples. 1. Create a trigger First, we need to create a trigger to listen for an event in the database. Here we take the "order table (order_table)" as an example. When a new order is inserted, the trigger will be activated, and then an external program will be called to perform an operation.
 How to convert HTML to MP4 format
Feb 19, 2024 pm 02:48 PM
How to convert HTML to MP4 format
Feb 19, 2024 pm 02:48 PM
Title: How to convert HTML to MP4 format: Detailed code example In the daily web page production process, we often encounter the need to convert HTML pages or specific HTML elements into MP4 videos. For example, save animation effects, slideshows or other dynamic elements as video files. This article will introduce how to use HTML5 and JavaScript to convert HTML to MP4 format, and provide specific code examples. HTML5 video tag and CanvasAPI HTML5 introduction
 How to extract Dump files
Feb 19, 2024 pm 12:15 PM
How to extract Dump files
Feb 19, 2024 pm 12:15 PM
How to grab Dump files In a computer system, a Dump file is a file that records the operating status and data of the system. In software development and system troubleshooting, grabbing Dump files can help program developers and system administrators analyze and diagnose various problems, such as program crashes, memory leaks, and system abnormalities. This article will introduce some common methods and tools to grab Dump files. 1. How to grab Dump files under Windows system using Task Manager: In Windows operating system,
 Windows 12 release date
Jan 05, 2024 pm 05:24 PM
Windows 12 release date
Jan 05, 2024 pm 05:24 PM
Previously, win11 was officially released, and many users have already started to enjoy win12. They want to know when win12 will be released. In fact, according to the rules, it will be released around 2024. When was win12 released: A: Win12 is expected to be released around the fall of 2024. 1. According to Microsoft’s latest breaking information, win12 is expected to be released in the fall of 2024. 2. And this time win12 will have multiple new design concepts, and there will be more improvements in neatness and visual appearance. 3. At the latest developer meeting, Microsoft developers revealed that they will create a floating taskbar to give the taskbar a floating feeling.
 What is the role of the NVIDIA Control Panel?
Feb 19, 2024 pm 03:59 PM
What is the role of the NVIDIA Control Panel?
Feb 19, 2024 pm 03:59 PM
What is the NVIDIA Control Panel? With the rapid development of computer technology, the importance of graphics cards has become more and more important. As one of the world's leading graphics card manufacturers, NVIDIA's control panel has attracted even more attention. So, what exactly does the NVIDIA control panel do? This article will give you a detailed introduction to the functions and uses of the NVIDIA control panel. First, let's understand the concept and definition of NVIDIA control panel. The NVIDIA Control Panel is a software used to manage and configure graphics card-related settings.
 How to open psd files on mobile phone
Feb 21, 2024 pm 05:48 PM
How to open psd files on mobile phone
Feb 21, 2024 pm 05:48 PM
Mobile phone PSD files are opened using Photoshop software. PSD is Photoshop's proprietary file format and can retain information such as layers, channels, paths, transparency, etc. Therefore, if you want to open a mobile phone PSD file, first make sure you have installed Photoshop software. First, open the Photoshop software, then click the "File" option in the menu bar, and select "Open" in the pop-up drop-down menu. Next, you need to browse your folders to find the phone where you saved
 The role of full-width and half-width in Chinese input method
Mar 25, 2024 am 09:57 AM
The role of full-width and half-width in Chinese input method
Mar 25, 2024 am 09:57 AM
Full-width and half-width are common concepts in Chinese input methods, and they represent different character widths. In the computer field, the concepts of full-width and half-width are mainly used to describe the size of space occupied by Chinese characters and English letters on the screen or in print. First of all, full-width and half-width originally originated in the era of typewriters. On typewriters, Chinese characters are usually displayed in full-width form, while English characters are displayed in half-width form. This is because Chinese characters are relatively wide, and using full-width can make the entire article look more beautiful and the layout more compact. The English characters are
