
 Technology peripherals
AI
MiniGPT-5, which unifies image and text generation, is here: Token becomes Voken, and the model can not only continue writing, but also automatically add pictures.
Technology peripherals
AI
MiniGPT-5, which unifies image and text generation, is here: Token becomes Voken, and the model can not only continue writing, but also automatically add pictures.
MiniGPT-5, which unifies image and text generation, is here: Token becomes Voken, and the model can not only continue writing, but also automatically add pictures.

Large-scale models are making the leap between language and vision, promising to seamlessly understand and generate text and image content. In a series of recent studies, multimodal feature integration is not only a growing trend but has already led to key advances ranging from multimodal conversations to content creation tools. Large language models have demonstrated unparalleled capabilities in text understanding and generation. However, simultaneously generating images with coherent textual narratives is still an area to be developed
Recently, a research team from the University of California, Santa Cruz proposed MiniGPT-5, a method based on Innovative interleaved visual language generation technology based on the concept of "generative vote".

- Paper address: https://browse.arxiv.org/pdf /2310.02239v1.pdf
- Project address: https://github.com/eric-ai-lab/MiniGPT-5
By combining the stable diffusion mechanism with LLM through a special visual token "generative vote", MiniGPT-5 heralds a path for skilled multi-modal generation. a new model. At the same time, the two-stage training method proposed in this article emphasizes the importance of the description-free basic stage, allowing the model to thrive even when data is scarce. The general phase of the method does not require domain-specific annotations, which makes our solution distinct from existing methods. In order to ensure that the generated text and images are harmonious, the double loss strategy of this article comes into play, and the generative vote method and classification method further enhance this effect
On the basis of these techniques , this work marks a transformative approach. By using ViT (Vision Transformer) and Qformer and a large language model, the research team converts multi-modal input into generative votes and seamlessly pairs them with high-resolution Stable Diffusion2.1 to achieve context-aware image generation. This paper combines images as auxiliary input with instruction adjustment methods and pioneers the use of text and image generation losses, thereby expanding the synergy between text and vision
MiniGPT-5 and CLIP Constraints and other models are matched, and the diffusion model is cleverly integrated with MiniGPT-4 to achieve better multi-modal results without relying on domain-specific annotations. Most importantly, our strategy can take advantage of advances in basic models of multimodal visual language and provide a new blueprint for enhancing multimodal generative capabilities.
As shown in the figure below, in addition to the original multi-modal understanding and text generation capabilities, MiniGPT5 can also provide reasonable and coherent multi-modal output:
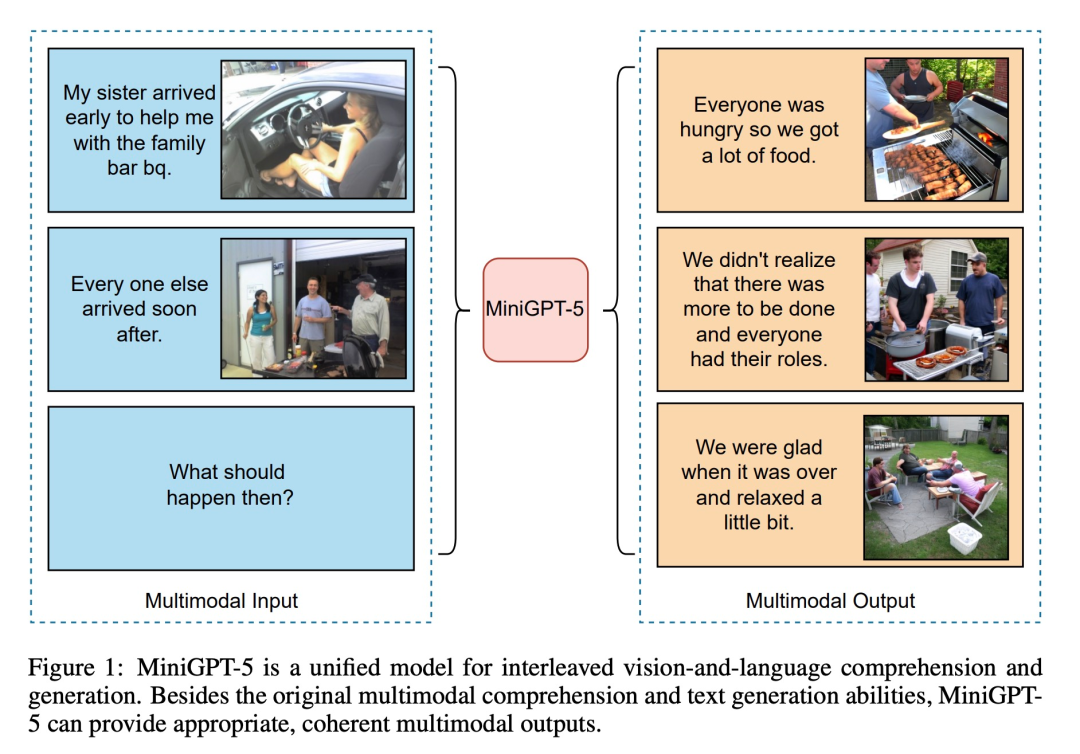
The contribution of this article is reflected in three aspects:
- It is recommended to use a multi-modal encoder, which represents a A novel general-purpose technique that has been proven to be more efficient than LLM and inverted generative votes, and combines it with Stable Diffusion to generate interleaved visual and language output (a multi-modal language model capable of multi-modal generation) ).
- focuses on a new two-stage training strategy for description-free multi-modal generation. The single-modal alignment stage obtains high-quality text-aligned visual features from a large number of text-image pairs. The multimodal learning phase includes a novel training task, prompt context generation, ensuring that visual and textual prompts are well coordinated and generated. Adding classifier-free guidance during the training phase further improves the generation quality.
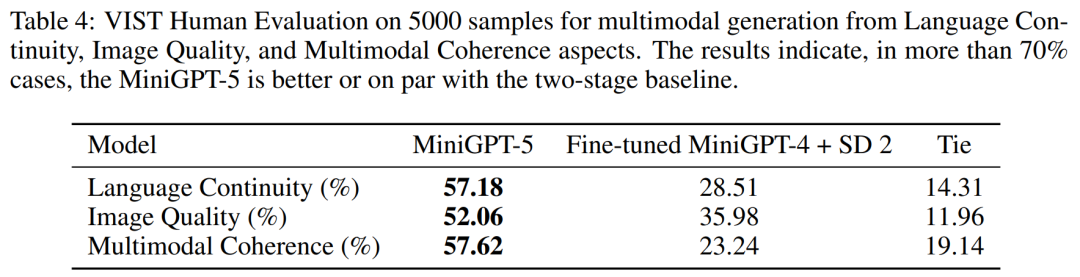
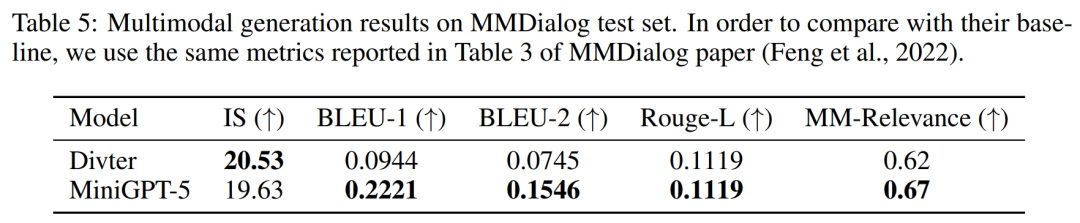
- Compared with other multi-modal generative models, MiniGPT-5 achieves state-of-the-art performance on the CC3M dataset. MiniGPT-5 also establishes new benchmarks on well-known datasets such as VIST and MMDialog.
Now, let’s learn more about what this study is about
Methodology Overview
In order to enable large-scale language models to have multi-modal generation capabilities, researchers introduced a structured framework to integrate pre-trained multi-modal large-scale language models and text-to-image generation models. In order to solve the differences between different model fields, they introduced special visual symbols "generative votes" (generative votes), which can be trained directly on the original images. Additionally, a two-stage training method is advanced, combined with a classifier-free bootstrapping strategy, to further improve the generation quality.
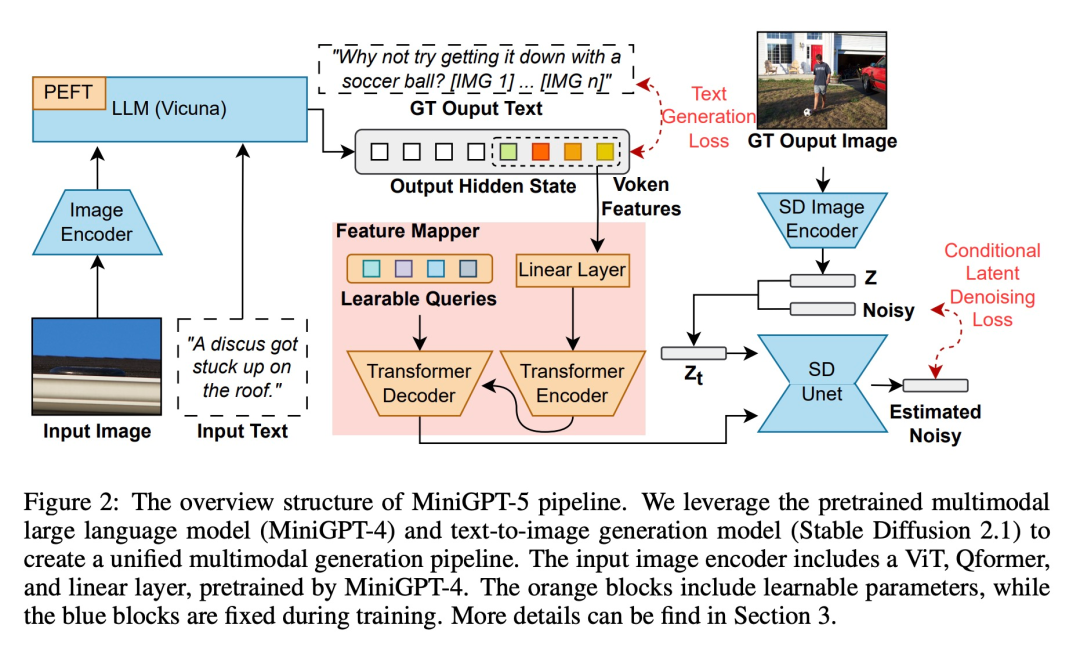
Multimodal input stage
Multimodal large model ( Recent advances such as MiniGPT-4 mainly focus on multi-modal understanding and are able to handle images as continuous input. To extend its functionality to multi-modal generation, researchers introduced generative Vokens specifically designed to output visual features. In addition, they also adopted parameter-efficient fine-tuning techniques within a large language model (LLM) framework for multi-modal output learning
Multi-modal output generation
To ensure that the generative tokens are accurately aligned with the generative model, the researchers developed a compact mapping module for dimension matching and introduced several supervised losses, including text Spatial loss and potential diffusion model loss. The text space loss helps the model accurately learn the location of tokens, while the latent diffusion loss directly aligns tokens with appropriate visual features. Since the features of generative symbols are directly guided by images, this method does not require complete image descriptions and achieves description-free learning
##Training strategy
Given that there is a non-negligible domain shift between the text domain and the image domain, the researchers found that training directly on a limited interleaved text and image dataset may lead to misalignment and Image quality deteriorates.
Therefore, they used two different training strategies to alleviate this problem. The first strategy involves employing classifier-free bootstrapping techniques to improve the effectiveness of generated tokens throughout the diffusion process; the second strategy unfolds in two phases: an initial pre-training phase focusing on rough feature alignment, followed by a fine-tuning phase Working on complex feature learning.
Experiments and results
In order to evaluate the effectiveness of the model, the researchers selected multiple benchmarks and conducted a series of evaluations. The purpose of the experiment is to address several key questions:
- Can MiniGPT-5 generate credible images and reasonable text?
- How does MiniGPT-5 perform compared to other SOTA models in single- and multi-round interleaved visual language generation tasks?
- What impact does the design of each module have on overall performance?
In order to evaluate the performance of the MiniGPT-5 model at different training stages, we conducted a quantitative analysis, and the results are shown in Figure 3:

To demonstrate the generality and robustness of the proposed model, we evaluated it covering both visual (image-related metrics) and language (text metrics) domains
VIST Final-Step Evaluation
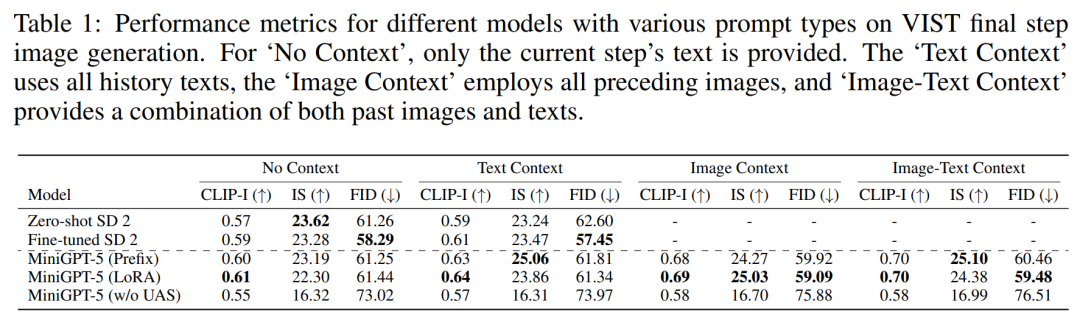
The first set of experiments involves single-step evaluation, i.e. The corresponding image is generated according to the prompt model in the last step, and the results are shown in Table 1.
MiniGPT-5 outperforms the fine-tuned SD 2 in all three settings. Notably, the CLIP score of the MiniGPT-5 (LoRA) model consistently outperforms other variants across multiple prompt types, especially when combining image and text prompts. On the other hand, the FID score highlights the competitiveness of the MiniGPT-5 (Prefix) model, indicating that there may be a trade-off between image embedding quality (reflected by the CLIP score) and image diversity and authenticity (reflected by the FID score). Compared to a model trained directly on VIST without including a single-modality registration stage (MiniGPT-5 w/o UAS), although the model retains the ability to generate meaningful images, image quality and consistency are significantly reduced . This observation highlights the importance of a two-stage training strategy
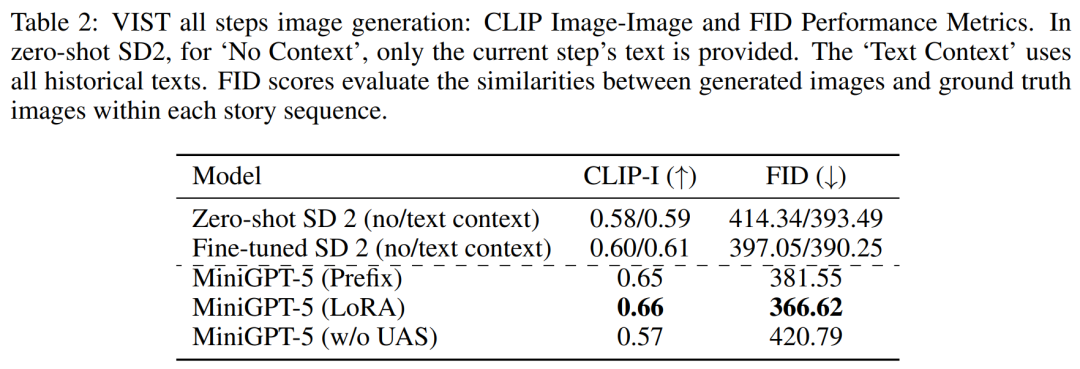
##VIST Multi-Step Evaluation
In a more detailed and comprehensive evaluation, the researchers systematically provided the model with prior historical context and subsequently evaluated the generated data at each step. Images and narratives are evaluated.Tables 2 and 3 summarize the results of these experiments, providing an overview of the performance on image and language metrics respectively. Experimental results show that MiniGPT-5 is able to exploit long-level multi-modal input cues to generate coherent, high-quality images across all data without compromising the multi-modal understanding capabilities of the original model. This highlights the effectiveness of MiniGPT-5 in different environments ##VIST Human Evaluation As shown in Table 4, MiniGPT-5 generated updates in 57.18% of the cases. Appropriate text narration provided better image quality in 52.06% of cases and generated more coherent multi-modal output in 57.62% of scenes. Compared with a two-stage baseline that adopts text-to-image prompt narration without subjunctive mood, these data clearly demonstrate its stronger multi-modal generation capabilities. ##MMDialog Multiple rounds of evaluation##According to The results in Table 5 show that MiniGPT-5 is more accurate than the baseline model Divter in generating text replies. Although the generated images are of similar quality, MiniGPT-5 outperforms the baseline model in MM correlations, suggesting that it is better able to learn how to position image generation appropriately and generate highly consistent multi-modal responses

 Let’s take a look at the output of MiniGPT-5 and see how effective it is. Figure 7 below shows the comparison between MiniGPT-5 and the baseline model on the CC3M validation set
Let’s take a look at the output of MiniGPT-5 and see how effective it is. Figure 7 below shows the comparison between MiniGPT-5 and the baseline model on the CC3M validation set Figure 8 below shows Comparison of baseline models between MiniGPT-5 and VIST verification sets
Figure 8 below shows Comparison of baseline models between MiniGPT-5 and VIST verification sets ##Figure 9 below shows the MiniGPT-5 and MMDialog test sets Comparison of baseline models.
##Figure 9 below shows the MiniGPT-5 and MMDialog test sets Comparison of baseline models.  For more research details, please refer to the original paper.
For more research details, please refer to the original paper.
The above is the detailed content of MiniGPT-5, which unifies image and text generation, is here: Token becomes Voken, and the model can not only continue writing, but also automatically add pictures.. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1385
1385
 52
52

 Use ddrescue to recover data on Linux
Mar 20, 2024 pm 01:37 PM
Use ddrescue to recover data on Linux
Mar 20, 2024 pm 01:37 PM
DDREASE is a tool for recovering data from file or block devices such as hard drives, SSDs, RAM disks, CDs, DVDs and USB storage devices. It copies data from one block device to another, leaving corrupted data blocks behind and moving only good data blocks. ddreasue is a powerful recovery tool that is fully automated as it does not require any interference during recovery operations. Additionally, thanks to the ddasue map file, it can be stopped and resumed at any time. Other key features of DDREASE are as follows: It does not overwrite recovered data but fills the gaps in case of iterative recovery. However, it can be truncated if the tool is instructed to do so explicitly. Recover data from multiple files or blocks to a single
 Open source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!
Apr 03, 2024 pm 12:04 PM
Open source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!
Apr 03, 2024 pm 12:04 PM
0.What does this article do? We propose DepthFM: a versatile and fast state-of-the-art generative monocular depth estimation model. In addition to traditional depth estimation tasks, DepthFM also demonstrates state-of-the-art capabilities in downstream tasks such as depth inpainting. DepthFM is efficient and can synthesize depth maps within a few inference steps. Let’s read about this work together ~ 1. Paper information title: DepthFM: FastMonocularDepthEstimationwithFlowMatching Author: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 How to use Excel filter function with multiple conditions
Feb 26, 2024 am 10:19 AM
How to use Excel filter function with multiple conditions
Feb 26, 2024 am 10:19 AM
If you need to know how to use filtering with multiple criteria in Excel, the following tutorial will guide you through the steps to ensure you can filter and sort your data effectively. Excel's filtering function is very powerful and can help you extract the information you need from large amounts of data. This function can filter data according to the conditions you set and display only the parts that meet the conditions, making data management more efficient. By using the filter function, you can quickly find target data, saving time in finding and organizing data. This function can not only be applied to simple data lists, but can also be filtered based on multiple conditions to help you locate the information you need more accurately. Overall, Excel’s filtering function is a very practical
 Google is ecstatic: JAX performance surpasses Pytorch and TensorFlow! It may become the fastest choice for GPU inference training
Apr 01, 2024 pm 07:46 PM
Google is ecstatic: JAX performance surpasses Pytorch and TensorFlow! It may become the fastest choice for GPU inference training
Apr 01, 2024 pm 07:46 PM
The performance of JAX, promoted by Google, has surpassed that of Pytorch and TensorFlow in recent benchmark tests, ranking first in 7 indicators. And the test was not done on the TPU with the best JAX performance. Although among developers, Pytorch is still more popular than Tensorflow. But in the future, perhaps more large models will be trained and run based on the JAX platform. Models Recently, the Keras team benchmarked three backends (TensorFlow, JAX, PyTorch) with the native PyTorch implementation and Keras2 with TensorFlow. First, they select a set of mainstream
 Slow Cellular Data Internet Speeds on iPhone: Fixes
May 03, 2024 pm 09:01 PM
Slow Cellular Data Internet Speeds on iPhone: Fixes
May 03, 2024 pm 09:01 PM
Facing lag, slow mobile data connection on iPhone? Typically, the strength of cellular internet on your phone depends on several factors such as region, cellular network type, roaming type, etc. There are some things you can do to get a faster, more reliable cellular Internet connection. Fix 1 – Force Restart iPhone Sometimes, force restarting your device just resets a lot of things, including the cellular connection. Step 1 – Just press the volume up key once and release. Next, press the Volume Down key and release it again. Step 2 – The next part of the process is to hold the button on the right side. Let the iPhone finish restarting. Enable cellular data and check network speed. Check again Fix 2 – Change data mode While 5G offers better network speeds, it works better when the signal is weaker
 The vitality of super intelligence awakens! But with the arrival of self-updating AI, mothers no longer have to worry about data bottlenecks
Apr 29, 2024 pm 06:55 PM
The vitality of super intelligence awakens! But with the arrival of self-updating AI, mothers no longer have to worry about data bottlenecks
Apr 29, 2024 pm 06:55 PM
I cry to death. The world is madly building big models. The data on the Internet is not enough. It is not enough at all. The training model looks like "The Hunger Games", and AI researchers around the world are worrying about how to feed these data voracious eaters. This problem is particularly prominent in multi-modal tasks. At a time when nothing could be done, a start-up team from the Department of Renmin University of China used its own new model to become the first in China to make "model-generated data feed itself" a reality. Moreover, it is a two-pronged approach on the understanding side and the generation side. Both sides can generate high-quality, multi-modal new data and provide data feedback to the model itself. What is a model? Awaker 1.0, a large multi-modal model that just appeared on the Zhongguancun Forum. Who is the team? Sophon engine. Founded by Gao Yizhao, a doctoral student at Renmin University’s Hillhouse School of Artificial Intelligence.
 Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
The latest video of Tesla's robot Optimus is released, and it can already work in the factory. At normal speed, it sorts batteries (Tesla's 4680 batteries) like this: The official also released what it looks like at 20x speed - on a small "workstation", picking and picking and picking: This time it is released One of the highlights of the video is that Optimus completes this work in the factory, completely autonomously, without human intervention throughout the process. And from the perspective of Optimus, it can also pick up and place the crooked battery, focusing on automatic error correction: Regarding Optimus's hand, NVIDIA scientist Jim Fan gave a high evaluation: Optimus's hand is the world's five-fingered robot. One of the most dexterous. Its hands are not only tactile
 The first robot to autonomously complete human tasks appears, with five fingers that are flexible and fast, and large models support virtual space training
Mar 11, 2024 pm 12:10 PM
The first robot to autonomously complete human tasks appears, with five fingers that are flexible and fast, and large models support virtual space training
Mar 11, 2024 pm 12:10 PM
This week, FigureAI, a robotics company invested by OpenAI, Microsoft, Bezos, and Nvidia, announced that it has received nearly $700 million in financing and plans to develop a humanoid robot that can walk independently within the next year. And Tesla’s Optimus Prime has repeatedly received good news. No one doubts that this year will be the year when humanoid robots explode. SanctuaryAI, a Canadian-based robotics company, recently released a new humanoid robot, Phoenix. Officials claim that it can complete many tasks autonomously at the same speed as humans. Pheonix, the world's first robot that can autonomously complete tasks at human speeds, can gently grab, move and elegantly place each object to its left and right sides. It can autonomously identify objects
