
 Technology peripherals
AI
In image and video generation, the language model defeated the diffusion model for the first time, and tokenizer is the key
Technology peripherals
AI
In image and video generation, the language model defeated the diffusion model for the first time, and tokenizer is the key
In image and video generation, the language model defeated the diffusion model for the first time, and tokenizer is the key

Large-scale language models (LLM or LM) were originally used to generate language, but over time they have been able to generate content in multiple modalities and have found applications in audio, speech, code generation, medical applications, Fields like robotics are starting to dominate
Of course, LM can also generate images and videos. During this process, image pixels are mapped into a series of discrete tokens by the visual tokenizer. These tokens are then fed into the LM transformer and used like vocabularies for generative modeling. Despite significant progress in visual generation, LM still performs worse than diffusion models. For example, when evaluated on the ImageNet dataset, the gold standard benchmark for image generation, the best language model performed a whopping 48% worse than the diffusion model (FID 3.41 vs. 1.79 when generating images at 256ˆ256 resolution).
Why do language models lag behind diffusion models in visual generation? Researchers from Google and CMU believe that the main reason is the lack of a good visual representation, similar to our natural language system, to effectively model the visual world. To confirm this hypothesis, they conducted a study.

Paper link: https://arxiv.org/pdf/2310.05737.pdf
This The study shows that with the same training data, comparable model size and training budget, using a good visual tokenizer, masked language models surpass SOTA diffusion models in both generation fidelity and efficiency on image and video benchmarks. This is the first evidence that a language model beats a diffusion model on the iconic ImageNet benchmark.
It should be emphasized that the purpose of the researchers is not to assert whether the language model is better than other models, but to promote the exploration of LLM visual tokenization methods. The fundamental difference between LLM and other models (such as diffusion models) is that LLM uses discrete latent formats, i.e. tokens obtained from a visual tokenizer. This research shows that the value of these discrete visual tokens should not be ignored because of their following advantages:
1. Compatibility with LLM. The main advantage of the token representation is that it shares the same form as the language token, thereby directly leveraging the optimizations the community has made over the years to develop LLM, including faster training and inference speeds, advances in model infrastructure, ways to extend the model, and Innovations such as GPU/TPU optimization. Unifying vision and language through the same token space could lay the foundation for truly multimodal LLMs that can understand, generate, and reason within our visual environments.
2. Compressed representation. Discrete tokens can provide a new perspective on video compression. Visual tokens can be used as a new video compression format to reduce the disk storage and bandwidth occupied by data during Internet transmission. Unlike compressed RGB pixels, these tokens can be fed directly into the generative model, bypassing traditional decompression and latent encoding steps. This can speed up the processing of video-generating applications and is especially beneficial in edge computing situations.
3. Advantages of visual understanding. Previous research has shown the value of discrete labels as pre-training targets in self-supervised representation learning, as discussed in BEiT and BEVT. In addition, the study found that using markers as model inputs can improve its robustness and generalization performance
In this paper, the researchers proposed a model called MAGVIT-v2 A video tokenizer designed to convert videos (and images) into compact discrete tokens
This content is rewritten as follows: The model is based on the SOTA video tokenizer within the VQ-VAE framework ——Improvements made by MAGVIT. The researchers proposed two new technologies: 1) an innovative lookup-free quantification method that allows learning a large vocabulary, thereby improving the quality of language model generation; 2) through extensive empirical analysis, they determined Modifications to MAGVIT not only improve the generation quality, but also allow images and videos to be tokenized using a shared vocabulary
Experimental results show that the new model outperforms in three key areas The best performing video tokenizer before - MAGVIT. First, the new model significantly improves MAGVIT’s generation quality, achieving state-of-the-art results on common image and video benchmarks. Second, user studies show that its compression quality exceeds MAGVIT and the current video compression standard HEVC. Furthermore, it is comparable to the next-generation video codec VVC. Finally, the researchers show that their new word segmentation performs better than MAGVIT on video understanding tasks in two settings and three datasets
Method introduction
This paper introduces a new video tokenizer, aiming to map the time-space dynamics in the visual scene into compact discrete tokens suitable for language models . Furthermore, the method builds on MAGVIT.
The study then highlights two novel designs: Lookup-Free Quantization (LFQ) and enhancements to the tokenizer model.
Lookup-free quantification
Recently, the VQ-VAE model has made great progress, but there is a problem with this method The problem is that the relationship between improvements in reconstruction quality and subsequent generation quality is unclear. Many people mistakenly believe that improving reconstruction is equivalent to improving language model generation, for example, expanding the vocabulary can improve the quality of reconstruction. However, this improvement only applies to generation with a small vocabulary, and when the vocabulary is very large, it will harm the performance of the language model
This article reduces the VQ-VAE codebook embedding dimension to 0, that is, Codebook 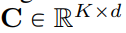 is replaced by an integer set
is replaced by an integer set 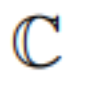 where
where 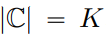 .
.
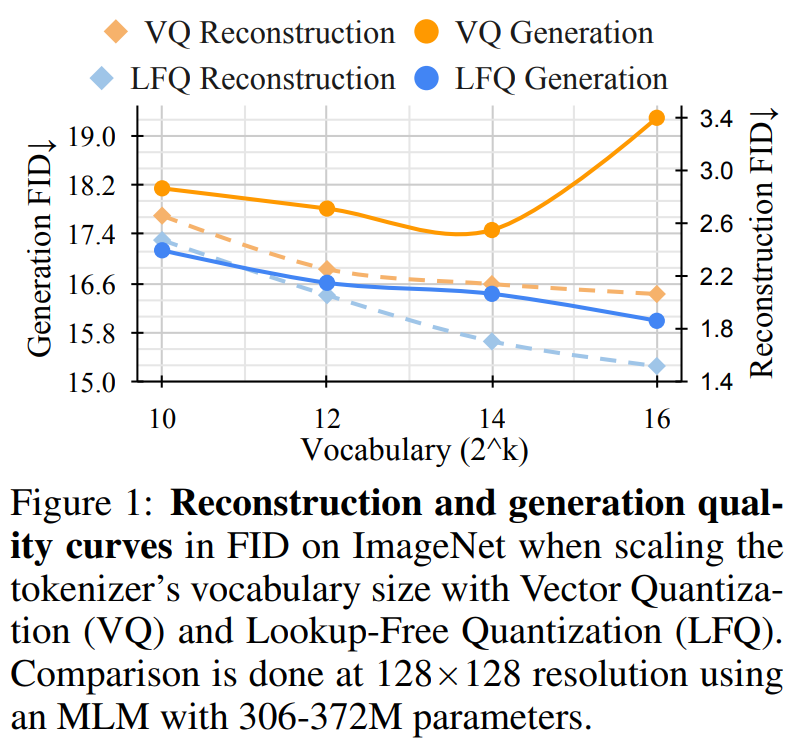
Unlike the VQ-VAE model, this new design completely eliminates the need for embedded lookups, hence the name LFQ. This paper finds that LFQ can improve the quality of language model generation by increasing vocabulary. As shown by the blue curve in Figure 1, both reconstruction and generation improve as vocabulary size increases—a property not observed in current VQ-VAE methods.
There are many LFQ methods available so far, but this article discusses a simple variant. Specifically, the latent space of LFQ is decomposed into the Cartesian product of single-dimensional variables, that is, 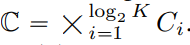 . Assuming that given a feature vector
. Assuming that given a feature vector 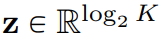 , each dimension of the quantified representation q (z) is obtained from:
, each dimension of the quantified representation q (z) is obtained from:
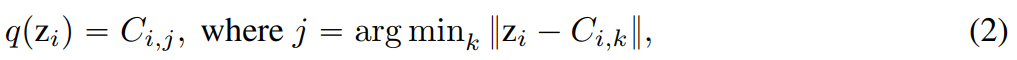
With respect to LFQ, q ( The token index of z) is:
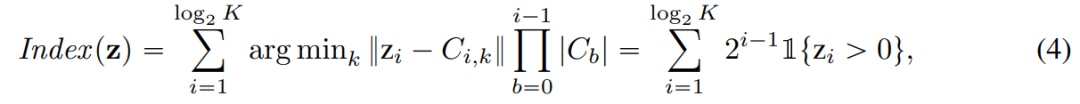
In addition, this article also adds an entropy penalty during the training process:
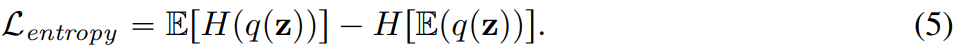
Improvements of the visual tokenizer model
In order to build a joint image-video tokenizer, a redesign is required. The study found that compared with the spatial transformer, the performance of 3D CNN is better
This paper explores two feasible design solutions, as shown in Figure 2b, which combines C-ViViT and MAGVIT; Figure 2c uses temporal causal 3D convolution instead of regular 3D CNN.
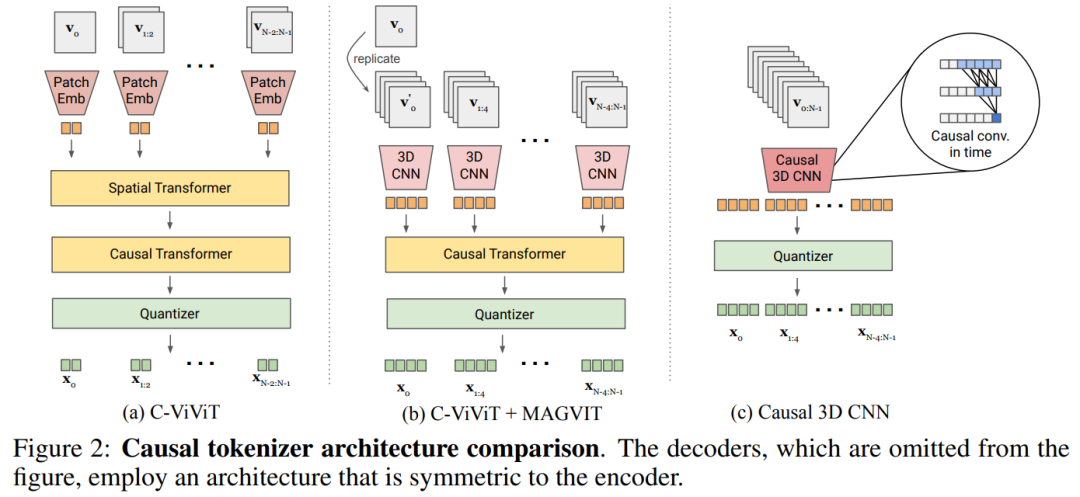
Table 5a empirically compares the designs in Figure 2 and finds that the causal 3D CNN performs best.
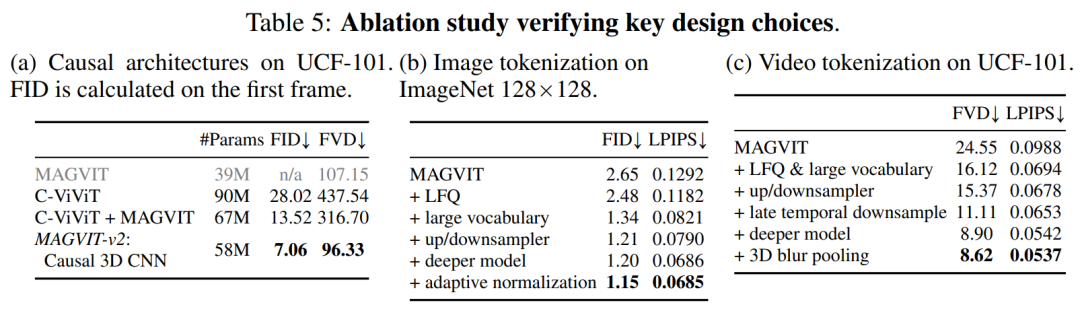
This article makes other architectural modifications to improve MAGVIT performance. In addition to using causal 3D CNN layers, this paper also changes the encoder downsampler from average pooling to strided convolution and adds an adaptive group normalization before the residual block at each resolution in the decoder. Layer etc
Experimental results
This paper verifies the performance of the proposed word segmenter through three parts of experiments: video and image generation, Video compression and action recognition. Figure 3 visually compares the tokenizer with the results of previous research

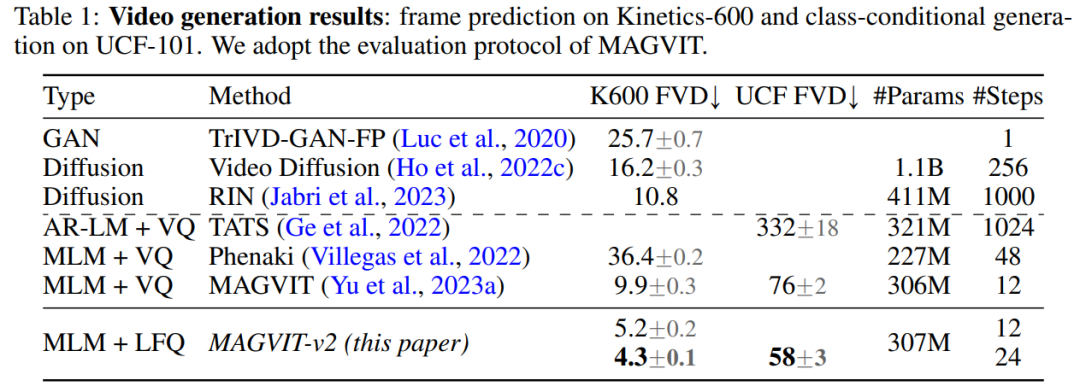
video generation. Table 1 shows that our model outperforms all existing techniques on both benchmarks, demonstrating that a good visual tokenizer plays an important role in enabling LM to generate high-quality videos.
The following is a description of the qualitative sample in Figure 4

By evaluating the image generation results of MAGVIT-v2, this study found that our model exceeded the best in terms of sampling quality (ID and IS) and inference time efficiency (sampling step) under standard ImageNet-like condition settings. The performance of the best diffusion model
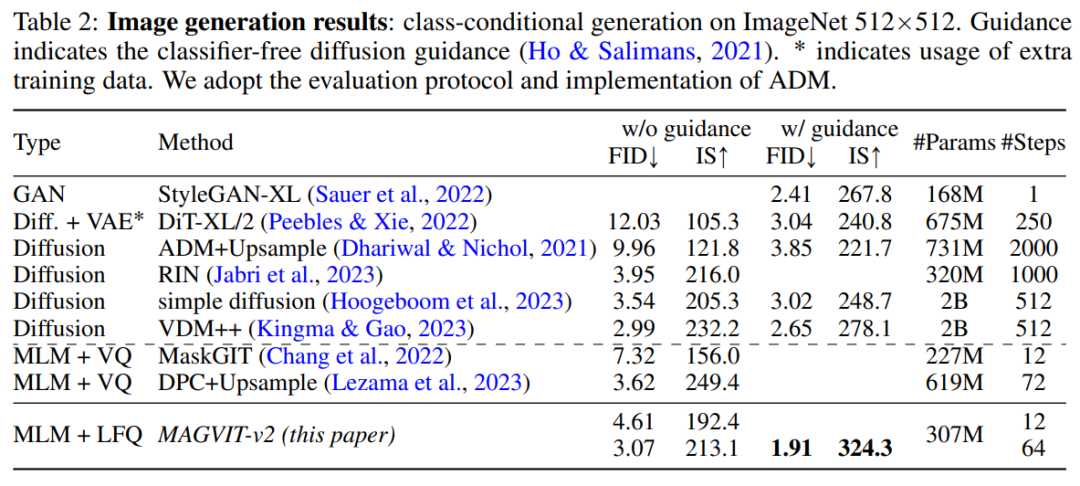
# Figure 5 shows the visualization results.

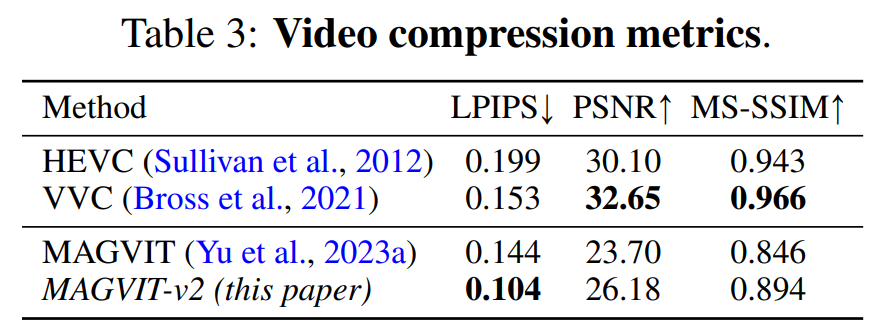
Video compression. The results are shown in Table 3. Our model outperforms MAGVIT on all indicators and outperforms all methods on LPIPS.
As shown in Table 4, MAGVIT-v2 outperforms the previous best MAGVIT
## in these evaluations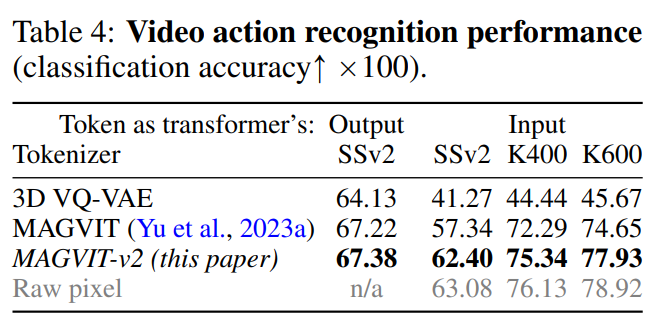 #
#
The above is the detailed content of In image and video generation, the language model defeated the diffusion model for the first time, and tokenizer is the key. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1377
1377
 52
52

 Open source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!
Apr 03, 2024 pm 12:04 PM
Open source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!
Apr 03, 2024 pm 12:04 PM
0.What does this article do? We propose DepthFM: a versatile and fast state-of-the-art generative monocular depth estimation model. In addition to traditional depth estimation tasks, DepthFM also demonstrates state-of-the-art capabilities in downstream tasks such as depth inpainting. DepthFM is efficient and can synthesize depth maps within a few inference steps. Let’s read about this work together ~ 1. Paper information title: DepthFM: FastMonocularDepthEstimationwithFlowMatching Author: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Imagine an artificial intelligence model that not only has the ability to surpass traditional computing, but also achieves more efficient performance at a lower cost. This is not science fiction, DeepSeek-V2[1], the world’s most powerful open source MoE model is here. DeepSeek-V2 is a powerful mixture of experts (MoE) language model with the characteristics of economical training and efficient inference. It consists of 236B parameters, 21B of which are used to activate each marker. Compared with DeepSeek67B, DeepSeek-V2 has stronger performance, while saving 42.5% of training costs, reducing KV cache by 93.3%, and increasing the maximum generation throughput to 5.76 times. DeepSeek is a company exploring general artificial intelligence
 AI subverts mathematical research! Fields Medal winner and Chinese-American mathematician led 11 top-ranked papers | Liked by Terence Tao
Apr 09, 2024 am 11:52 AM
AI subverts mathematical research! Fields Medal winner and Chinese-American mathematician led 11 top-ranked papers | Liked by Terence Tao
Apr 09, 2024 am 11:52 AM
AI is indeed changing mathematics. Recently, Tao Zhexuan, who has been paying close attention to this issue, forwarded the latest issue of "Bulletin of the American Mathematical Society" (Bulletin of the American Mathematical Society). Focusing on the topic "Will machines change mathematics?", many mathematicians expressed their opinions. The whole process was full of sparks, hardcore and exciting. The author has a strong lineup, including Fields Medal winner Akshay Venkatesh, Chinese mathematician Zheng Lejun, NYU computer scientist Ernest Davis and many other well-known scholars in the industry. The world of AI has changed dramatically. You know, many of these articles were submitted a year ago.
 Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas officially enters the era of electric robots! Yesterday, the hydraulic Atlas just "tearfully" withdrew from the stage of history. Today, Boston Dynamics announced that the electric Atlas is on the job. It seems that in the field of commercial humanoid robots, Boston Dynamics is determined to compete with Tesla. After the new video was released, it had already been viewed by more than one million people in just ten hours. The old people leave and new roles appear. This is a historical necessity. There is no doubt that this year is the explosive year of humanoid robots. Netizens commented: The advancement of robots has made this year's opening ceremony look like a human, and the degree of freedom is far greater than that of humans. But is this really not a horror movie? At the beginning of the video, Atlas is lying calmly on the ground, seemingly on his back. What follows is jaw-dropping
 KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
Earlier this month, researchers from MIT and other institutions proposed a very promising alternative to MLP - KAN. KAN outperforms MLP in terms of accuracy and interpretability. And it can outperform MLP running with a larger number of parameters with a very small number of parameters. For example, the authors stated that they used KAN to reproduce DeepMind's results with a smaller network and a higher degree of automation. Specifically, DeepMind's MLP has about 300,000 parameters, while KAN only has about 200 parameters. KAN has a strong mathematical foundation like MLP. MLP is based on the universal approximation theorem, while KAN is based on the Kolmogorov-Arnold representation theorem. As shown in the figure below, KAN has
 Kuaishou version of Sora 'Ke Ling' is open for testing: generates over 120s video, understands physics better, and can accurately model complex movements
Jun 11, 2024 am 09:51 AM
Kuaishou version of Sora 'Ke Ling' is open for testing: generates over 120s video, understands physics better, and can accurately model complex movements
Jun 11, 2024 am 09:51 AM
What? Is Zootopia brought into reality by domestic AI? Exposed together with the video is a new large-scale domestic video generation model called "Keling". Sora uses a similar technical route and combines a number of self-developed technological innovations to produce videos that not only have large and reasonable movements, but also simulate the characteristics of the physical world and have strong conceptual combination capabilities and imagination. According to the data, Keling supports the generation of ultra-long videos of up to 2 minutes at 30fps, with resolutions up to 1080p, and supports multiple aspect ratios. Another important point is that Keling is not a demo or video result demonstration released by the laboratory, but a product-level application launched by Kuaishou, a leading player in the short video field. Moreover, the main focus is to be pragmatic, not to write blank checks, and to go online as soon as it is released. The large model of Ke Ling is already available in Kuaiying.
 The vitality of super intelligence awakens! But with the arrival of self-updating AI, mothers no longer have to worry about data bottlenecks
Apr 29, 2024 pm 06:55 PM
The vitality of super intelligence awakens! But with the arrival of self-updating AI, mothers no longer have to worry about data bottlenecks
Apr 29, 2024 pm 06:55 PM
I cry to death. The world is madly building big models. The data on the Internet is not enough. It is not enough at all. The training model looks like "The Hunger Games", and AI researchers around the world are worrying about how to feed these data voracious eaters. This problem is particularly prominent in multi-modal tasks. At a time when nothing could be done, a start-up team from the Department of Renmin University of China used its own new model to become the first in China to make "model-generated data feed itself" a reality. Moreover, it is a two-pronged approach on the understanding side and the generation side. Both sides can generate high-quality, multi-modal new data and provide data feedback to the model itself. What is a model? Awaker 1.0, a large multi-modal model that just appeared on the Zhongguancun Forum. Who is the team? Sophon engine. Founded by Gao Yizhao, a doctoral student at Renmin University’s Hillhouse School of Artificial Intelligence.
 The U.S. Air Force showcases its first AI fighter jet with high profile! The minister personally conducted the test drive without interfering during the whole process, and 100,000 lines of code were tested for 21 times.
May 07, 2024 pm 05:00 PM
The U.S. Air Force showcases its first AI fighter jet with high profile! The minister personally conducted the test drive without interfering during the whole process, and 100,000 lines of code were tested for 21 times.
May 07, 2024 pm 05:00 PM
Recently, the military circle has been overwhelmed by the news: US military fighter jets can now complete fully automatic air combat using AI. Yes, just recently, the US military’s AI fighter jet was made public for the first time and the mystery was unveiled. The full name of this fighter is the Variable Stability Simulator Test Aircraft (VISTA). It was personally flown by the Secretary of the US Air Force to simulate a one-on-one air battle. On May 2, U.S. Air Force Secretary Frank Kendall took off in an X-62AVISTA at Edwards Air Force Base. Note that during the one-hour flight, all flight actions were completed autonomously by AI! Kendall said - "For the past few decades, we have been thinking about the unlimited potential of autonomous air-to-air combat, but it has always seemed out of reach." However now,
