
 Technology peripherals
AI
Zhipu AI cooperated with Tsinghua KEG to release an open source multi-modal large model called CogVLM-17B
Technology peripherals
AI
Zhipu AI cooperated with Tsinghua KEG to release an open source multi-modal large model called CogVLM-17B
Zhipu AI cooperated with Tsinghua KEG to release an open source multi-modal large model called CogVLM-17B

whip牛士 News on October 12th, recently, Zhipu AI & Tsinghua KEG released and directly open sourced the multi-modal large model-CogVLM-17B in the Moda community. It is reported that CogVLM is a powerful open source visual language model that uses the visual expert module to deeply integrate language coding and visual coding, and has achieved SOTA performance on 14 authoritative cross-modal benchmarks.
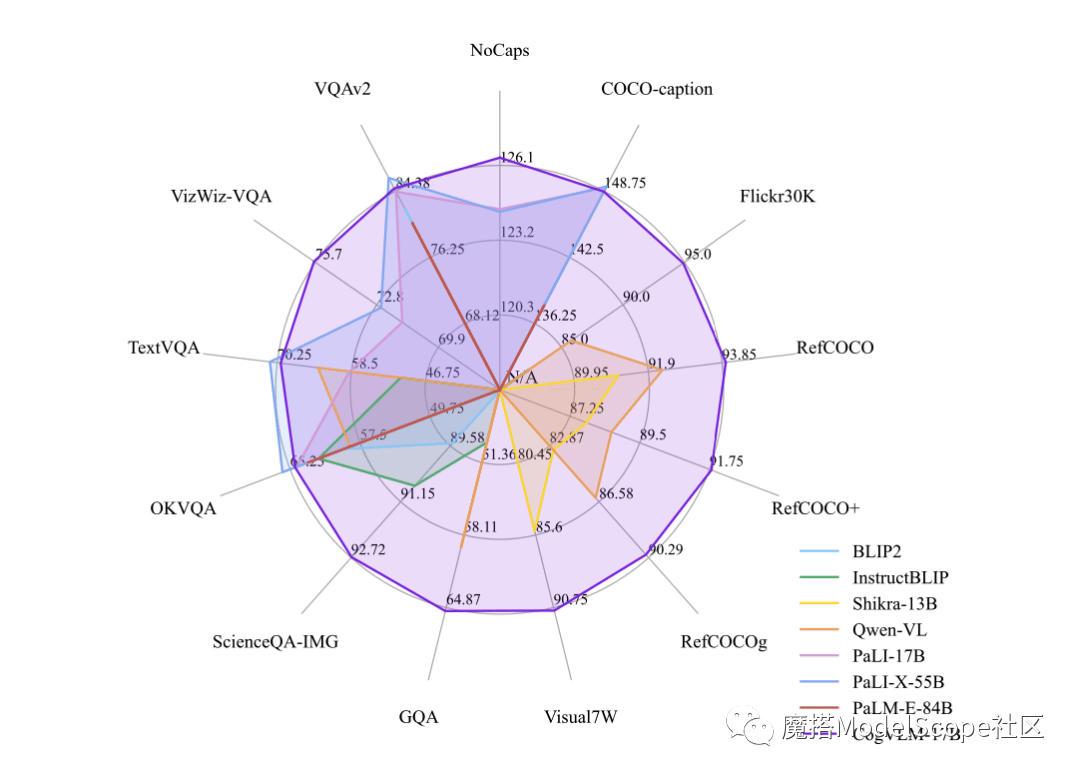
CogVLM-17B is currently the model with the first comprehensive performance on the multi-modal authoritative academic list, and has achieved the most advanced or second place results on 14 data sets. The effect of CogVLM depends on the idea of "visual priority", that is, giving visual understanding a higher priority in multi-modal models. It uses a 5B parameter visual encoder and a 6B parameter visual expert module, with a total of 11B parameters to model image features, even more than the 7B parameters of text
The above is the detailed content of Zhipu AI cooperated with Tsinghua KEG to release an open source multi-modal large model called CogVLM-17B. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 I Tried Vibe Coding with Cursor AI and It's Amazing!
Mar 20, 2025 pm 03:34 PM
I Tried Vibe Coding with Cursor AI and It's Amazing!
Mar 20, 2025 pm 03:34 PM
Vibe coding is reshaping the world of software development by letting us create applications using natural language instead of endless lines of code. Inspired by visionaries like Andrej Karpathy, this innovative approach lets dev
 Top 5 GenAI Launches of February 2025: GPT-4.5, Grok-3 & More!
Mar 22, 2025 am 10:58 AM
Top 5 GenAI Launches of February 2025: GPT-4.5, Grok-3 & More!
Mar 22, 2025 am 10:58 AM
February 2025 has been yet another game-changing month for generative AI, bringing us some of the most anticipated model upgrades and groundbreaking new features. From xAI’s Grok 3 and Anthropic’s Claude 3.7 Sonnet, to OpenAI’s G
 How to Use YOLO v12 for Object Detection?
Mar 22, 2025 am 11:07 AM
How to Use YOLO v12 for Object Detection?
Mar 22, 2025 am 11:07 AM
YOLO (You Only Look Once) has been a leading real-time object detection framework, with each iteration improving upon the previous versions. The latest version YOLO v12 introduces advancements that significantly enhance accuracy
 Best AI Art Generators (Free & Paid) for Creative Projects
Apr 02, 2025 pm 06:10 PM
Best AI Art Generators (Free & Paid) for Creative Projects
Apr 02, 2025 pm 06:10 PM
The article reviews top AI art generators, discussing their features, suitability for creative projects, and value. It highlights Midjourney as the best value for professionals and recommends DALL-E 2 for high-quality, customizable art.
 Is ChatGPT 4 O available?
Mar 28, 2025 pm 05:29 PM
Is ChatGPT 4 O available?
Mar 28, 2025 pm 05:29 PM
ChatGPT 4 is currently available and widely used, demonstrating significant improvements in understanding context and generating coherent responses compared to its predecessors like ChatGPT 3.5. Future developments may include more personalized interactions and real-time data processing capabilities, further enhancing its potential for various applications.
 Best AI Chatbots Compared (ChatGPT, Gemini, Claude & More)
Apr 02, 2025 pm 06:09 PM
Best AI Chatbots Compared (ChatGPT, Gemini, Claude & More)
Apr 02, 2025 pm 06:09 PM
The article compares top AI chatbots like ChatGPT, Gemini, and Claude, focusing on their unique features, customization options, and performance in natural language processing and reliability.
 How to Use Mistral OCR for Your Next RAG Model
Mar 21, 2025 am 11:11 AM
How to Use Mistral OCR for Your Next RAG Model
Mar 21, 2025 am 11:11 AM
Mistral OCR: Revolutionizing Retrieval-Augmented Generation with Multimodal Document Understanding Retrieval-Augmented Generation (RAG) systems have significantly advanced AI capabilities, enabling access to vast data stores for more informed respons
 Top AI Writing Assistants to Boost Your Content Creation
Apr 02, 2025 pm 06:11 PM
Top AI Writing Assistants to Boost Your Content Creation
Apr 02, 2025 pm 06:11 PM
The article discusses top AI writing assistants like Grammarly, Jasper, Copy.ai, Writesonic, and Rytr, focusing on their unique features for content creation. It argues that Jasper excels in SEO optimization, while AI tools help maintain tone consist
