
 Technology peripherals
AI
The innovative work of Chen Danqi's team: Obtain SOTA at 5% cost, setting off a craze for 'alpaca shearing'
Technology peripherals
AI
The innovative work of Chen Danqi's team: Obtain SOTA at 5% cost, setting off a craze for 'alpaca shearing'
The innovative work of Chen Danqi's team: Obtain SOTA at 5% cost, setting off a craze for 'alpaca shearing'

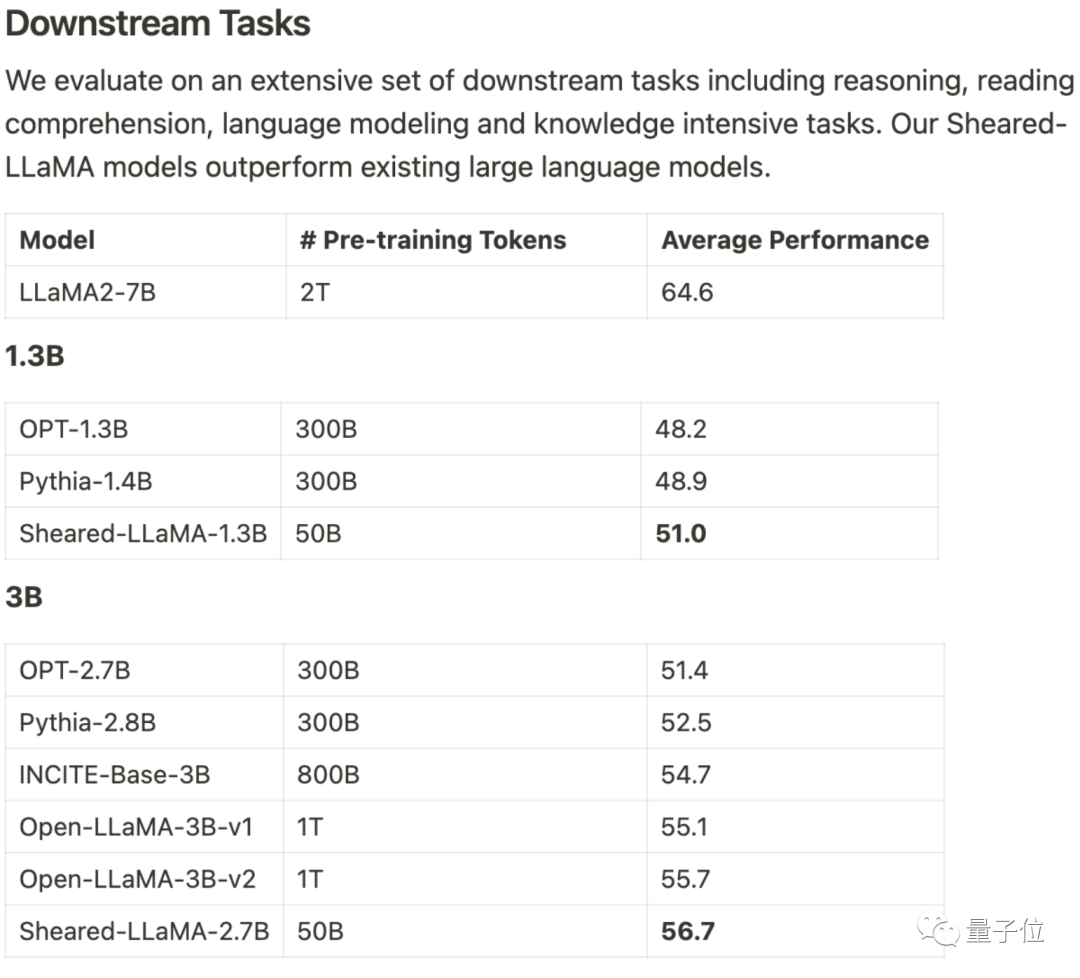
Only 3% of the calculation, 5% of the costobtained SOTA, dominating the 1B-3B scale of open source Large model.
This result comes from the Princeton Chen Danqi team, called LLM-ShearingLarge Model Pruning Method.

Based on the alpaca LLaMA 2 7B, the 1.3B and 3B pruned Sheared-LLama models are obtained through directional structured pruning.

To surpass the previous model of the same scale in terms of downstream task evaluation, it needs to be rewritten
Xia Mengzhou, the first author, said, "Much more cost-effective than pre-training from scratch."

The paper also gives an example of the pruned Sheared-LLaMA output, indicating that despite the scale of only 1.3B and 2.7B, it can already generate coherent and rich content. reply.
For the same task of "acting as a semiconductor industry analyst", the answer structure of version 2.7B is even clearer.

The team stated that although currently only Llama 2 7B version has been used for pruning experiments, the methodcan be extended to other model architectures, can also be expanded to any scale.
An additional benefit after pruning is that you can choose high-quality data sets for continued pre-training

Some developers said that in just 6 Months ago, almost everyone believed that models below 65B had no practical use
If this continues, I bet that 1B-3B models can also generate great value, if not now, then soon.

Treat pruning as constrained optimization
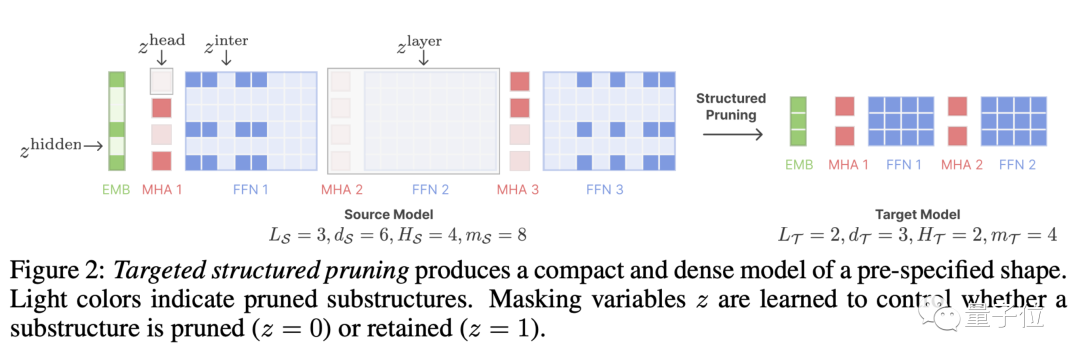
LLM-Shearing, specifically a directional structured pruning Branch, prune a large model to the specified target structure.
Previous pruning methods may cause model performance degradation because some structures will be deleted, affecting its expressive ability
By treating pruning as a constrained optimization problem, we propose a New methods. We search for subnetworks that match the specified structure by learning the pruning mask matrix, with the goal of maximizing performance
Next, continue with the pruned model Pre-training can restore the performance loss caused by pruning to a certain extent.
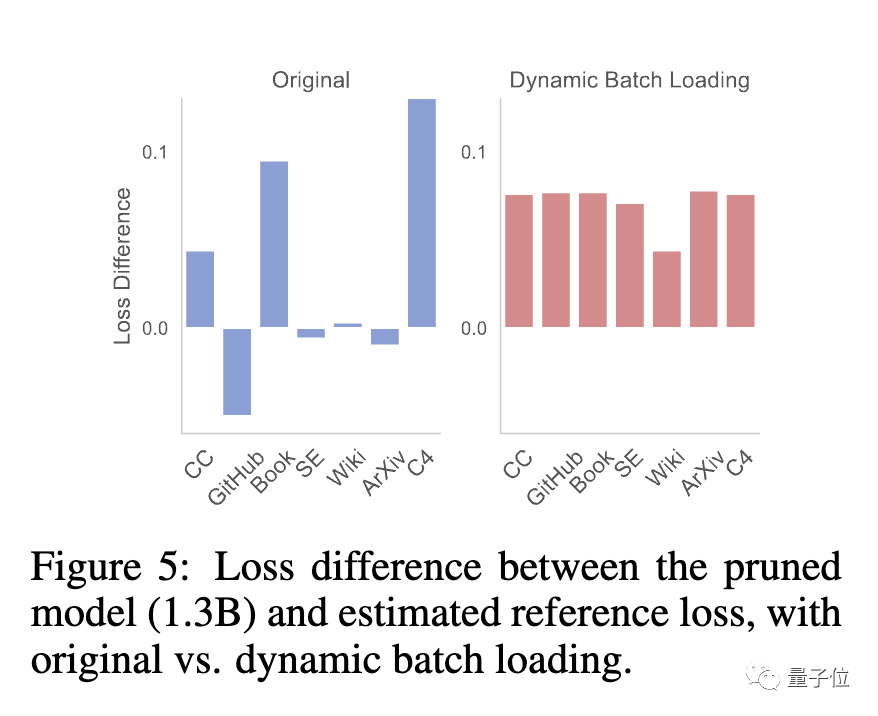
At this stage, the team found that the pruned model and the model trained from scratch had different loss reduction rates for different data sets, resulting in the problem of low data usage efficiency.
For this purpose, the team proposed Dynamic Batch Loading(Dynamic Batch Loading), which dynamically adjusts the data of each domain according to the model's loss reduction rate on different domain data. proportion to improve data usage efficiency.
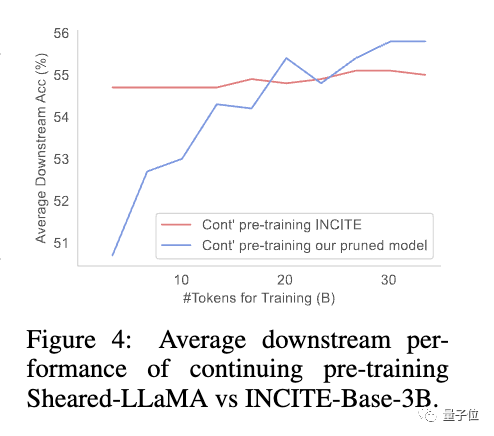
Research has found that although the pruned model has poor initial performance compared to a model of the same size trained from scratch, it can quickly improve through continuous pre-training and eventually surpass
This shows that pruning from a strong base model can provide better initialization conditions for continued pre-training.
will continue to be updated, let’s cut one by one
The authors of the paper are Princeton doctoral students Xia Mengzhou, Gao Tianyu, Tsinghua UniversityZhiyuan Zeng, Princeton Assistant Professor陈 Danqi.
Xia Mengzhou graduated from Fudan University with a bachelor's degree and CMU with a master's degree.
Gao Tianyu is an undergraduate who graduated from Tsinghua University. He won the Tsinghua Special Award in 2019
Both of them are students of Chen Danqi, and Chen Danqi is currently an assistant at Princeton University Professor and co-leader of the Princeton Natural Language Processing Group
Recently, on her personal homepage, Chen Danqi updated her research direction.
"This period is mainly focused on developing large-scale models. Research topics include:"
- How retrieval plays an important role in next-generation models to improve authenticity, adaptability, Interpretability and credibility.
- Low-cost training and deployment of large models, improved training methods, data management, model compression and downstream task adaptation optimization.
- Also interested in work that truly improves understanding of the capabilities and limitations of current large models, both empirically and theoretically.

Sheared-Llama has been made available on Hugging Face
The team said they will continue to update the open source Library
When more large models are released, cut them one by one and continue to release high-performance small models.

One More Thing
I have to say that the large model is too curly now.
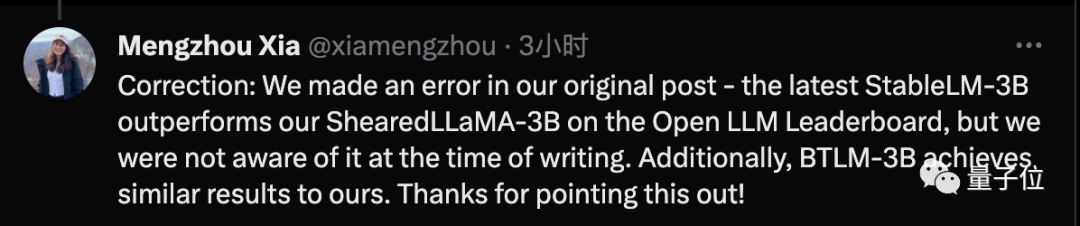
Mengzhou Xia just issued a correction, stating that he used SOTA technology when writing the paper, but after the paper was completed, it was surpassed by the latest Stable-LM-3B technology
Paper address: https://arxiv.org/abs/2310.06694
##Hugging Face: https://huggingface.co/princeton-nlp
Project homepage link: https://xiamengzhou.github.io/sheared-llama/
The above is the detailed content of The innovative work of Chen Danqi's team: Obtain SOTA at 5% cost, setting off a craze for 'alpaca shearing'. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 How to optimize the performance of debian readdir
Apr 13, 2025 am 08:48 AM
How to optimize the performance of debian readdir
Apr 13, 2025 am 08:48 AM
In Debian systems, readdir system calls are used to read directory contents. If its performance is not good, try the following optimization strategy: Simplify the number of directory files: Split large directories into multiple small directories as much as possible, reducing the number of items processed per readdir call. Enable directory content caching: build a cache mechanism, update the cache regularly or when directory content changes, and reduce frequent calls to readdir. Memory caches (such as Memcached or Redis) or local caches (such as files or databases) can be considered. Adopt efficient data structure: If you implement directory traversal by yourself, select more efficient data structures (such as hash tables instead of linear search) to store and access directory information
 How to set the Debian Apache log level
Apr 13, 2025 am 08:33 AM
How to set the Debian Apache log level
Apr 13, 2025 am 08:33 AM
This article describes how to adjust the logging level of the ApacheWeb server in the Debian system. By modifying the configuration file, you can control the verbose level of log information recorded by Apache. Method 1: Modify the main configuration file to locate the configuration file: The configuration file of Apache2.x is usually located in the /etc/apache2/ directory. The file name may be apache2.conf or httpd.conf, depending on your installation method. Edit configuration file: Open configuration file with root permissions using a text editor (such as nano): sudonano/etc/apache2/apache2.conf
 How to implement file sorting by debian readdir
Apr 13, 2025 am 09:06 AM
How to implement file sorting by debian readdir
Apr 13, 2025 am 09:06 AM
In Debian systems, the readdir function is used to read directory contents, but the order in which it returns is not predefined. To sort files in a directory, you need to read all files first, and then sort them using the qsort function. The following code demonstrates how to sort directory files using readdir and qsort in Debian system: #include#include#include#include#include//Custom comparison function, used for qsortintcompare(constvoid*a,constvoid*b){returnstrcmp(*(
 Debian mail server firewall configuration tips
Apr 13, 2025 am 11:42 AM
Debian mail server firewall configuration tips
Apr 13, 2025 am 11:42 AM
Configuring a Debian mail server's firewall is an important step in ensuring server security. The following are several commonly used firewall configuration methods, including the use of iptables and firewalld. Use iptables to configure firewall to install iptables (if not already installed): sudoapt-getupdatesudoapt-getinstalliptablesView current iptables rules: sudoiptables-L configuration
 How Debian OpenSSL prevents man-in-the-middle attacks
Apr 13, 2025 am 10:30 AM
How Debian OpenSSL prevents man-in-the-middle attacks
Apr 13, 2025 am 10:30 AM
In Debian systems, OpenSSL is an important library for encryption, decryption and certificate management. To prevent a man-in-the-middle attack (MITM), the following measures can be taken: Use HTTPS: Ensure that all network requests use the HTTPS protocol instead of HTTP. HTTPS uses TLS (Transport Layer Security Protocol) to encrypt communication data to ensure that the data is not stolen or tampered during transmission. Verify server certificate: Manually verify the server certificate on the client to ensure it is trustworthy. The server can be manually verified through the delegate method of URLSession
 How debian readdir integrates with other tools
Apr 13, 2025 am 09:42 AM
How debian readdir integrates with other tools
Apr 13, 2025 am 09:42 AM
The readdir function in the Debian system is a system call used to read directory contents and is often used in C programming. This article will explain how to integrate readdir with other tools to enhance its functionality. Method 1: Combining C language program and pipeline First, write a C program to call the readdir function and output the result: #include#include#include#includeintmain(intargc,char*argv[]){DIR*dir;structdirent*entry;if(argc!=2){
 How to do Debian Hadoop log management
Apr 13, 2025 am 10:45 AM
How to do Debian Hadoop log management
Apr 13, 2025 am 10:45 AM
Managing Hadoop logs on Debian, you can follow the following steps and best practices: Log Aggregation Enable log aggregation: Set yarn.log-aggregation-enable to true in the yarn-site.xml file to enable log aggregation. Configure log retention policy: Set yarn.log-aggregation.retain-seconds to define the retention time of the log, such as 172800 seconds (2 days). Specify log storage path: via yarn.n
 Debian mail server SSL certificate installation method
Apr 13, 2025 am 11:39 AM
Debian mail server SSL certificate installation method
Apr 13, 2025 am 11:39 AM
The steps to install an SSL certificate on the Debian mail server are as follows: 1. Install the OpenSSL toolkit First, make sure that the OpenSSL toolkit is already installed on your system. If not installed, you can use the following command to install: sudoapt-getupdatesudoapt-getinstallopenssl2. Generate private key and certificate request Next, use OpenSSL to generate a 2048-bit RSA private key and a certificate request (CSR): openss
