

IT House News on October 13, Google announced in a blog post published today (local time) that users who use its own generative AI products will be protected by the official. This move is intended to alleviate people’s concerns about generative AI. Concerns about potential infringement risks.
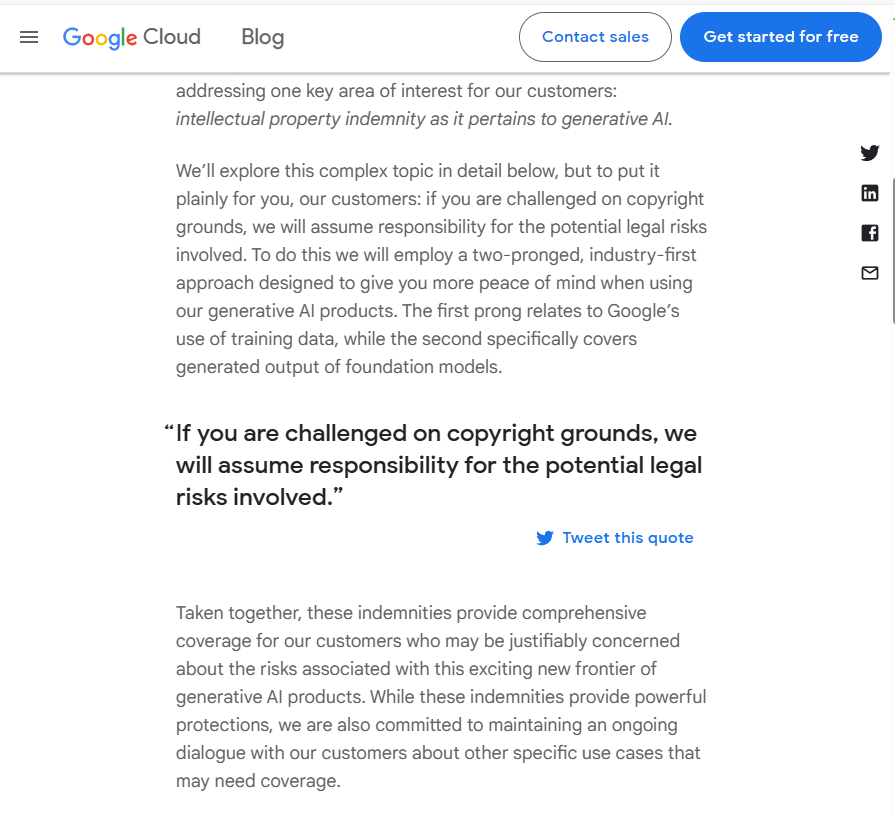
If you are challenged due to copyright issues, we will bear potential legal risks.
According to reports, a total of 7 Google products are protected:
In this blog post, there is no mention of Google’s Bard chatbot. Google said it would follow a "two-pronged, industry-leading" approach to intellectual property compensation, covering the results of its training data and underlying model creation.
Simply put, if someone is sued for using copyrighted material in Google’s training data, Google will be legally responsible. Of course, this statement does not apply in cases where users knowingly create or use generated content to infringe the rights of others.
However, Google was hit with a class-action lawsuit in July this year, accused of stealing user data to train its generative AI products without the user’s knowledge or consent. IT House previously reported that the lawsuit claimed that Google "secretly stole everything created and shared by hundreds of millions of Americans on the Internet."
The lawsuit states: “Google must understand that it does not own the Internet, nor does it own our creative works, our expressions of personality, the photos of our families and children, or anything else we share online. And stuff that belongs to us. 'Publicly available' never means free to use for any purpose."
Google said in a statement to Reuters at the time that the allegations in the lawsuit were "baseless".
The above is the detailed content of Google promises to protect users of its generative AI products from copyright claims. For more information, please follow other related articles on the PHP Chinese website!
 Mechanical energy conservation law formula
Mechanical energy conservation law formula
 what is dandelion
what is dandelion
 The function of intermediate relay
The function of intermediate relay
 How to pay with WeChat on Douyin
How to pay with WeChat on Douyin
 All uses of cloud servers
All uses of cloud servers
 How to apply for a business email
How to apply for a business email
 Can Douyin short videos be restored after being deleted?
Can Douyin short videos be restored after being deleted?
 formatter function usage
formatter function usage
 How to use months_between in SQL
How to use months_between in SQL








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



