

Currently, large language models (LLMs) have demonstrated amazing capabilities on inference tasks, especially when examples and intermediate steps are provided. However, prompt methods usually rely on implicit knowledge in LLM. When the implicit knowledge is wrong or inconsistent with the task, LLM may give wrong answers

Now, researchers from Google, Mila Institute and other research institutions have jointly explored a new method - letting LLM learn inference rules, and proposed a method called Hypotheses-to- Theories, HtT) a new framework. This new method not only improves multi-step reasoning, but also has the advantages of interpretability and transferability

paper Address: https://arxiv.org/abs/2310.07064
According to the experimental results on numerical reasoning and relational reasoning problems, the HtT method improves the existing prompting method. The accuracy increased by 11-27%. At the same time, the learned rules can also be transferred to different models or different forms of the same problem
In general Said that the HtT framework consists of two stages - the inductive stage and the deductive stage, which are similar to training and testing in traditional machine learning.
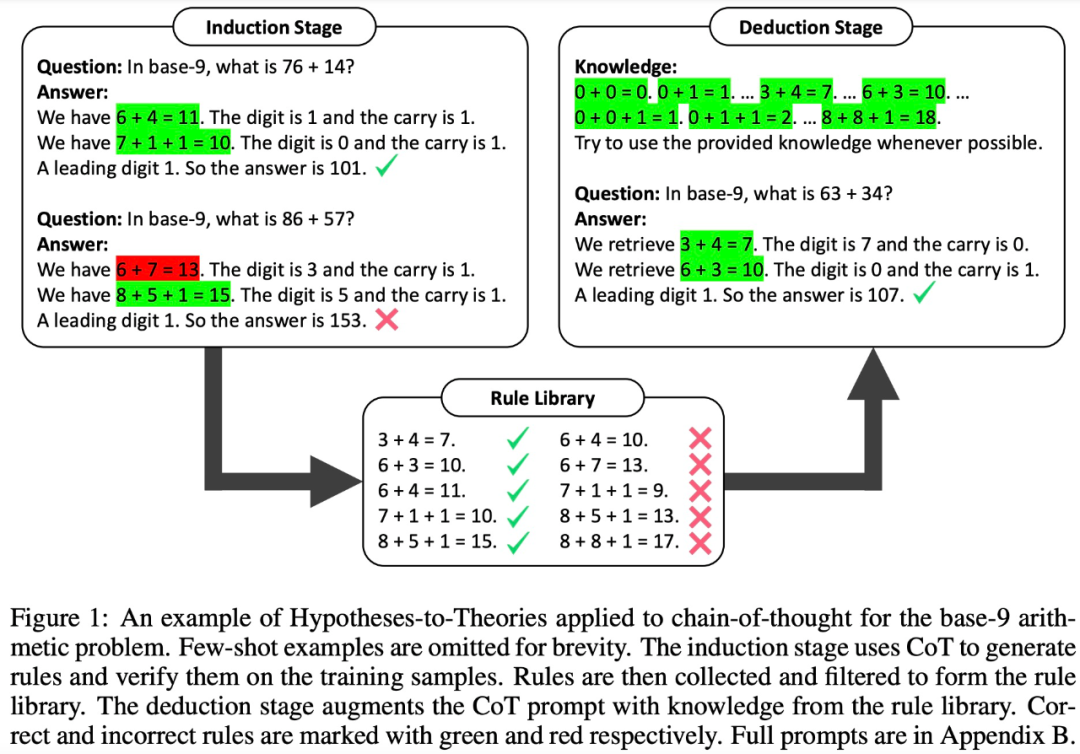
In the induction phase, LLM first needs to generate and verify a set of rules for training examples. This study uses CoT to declare rules and derive answers, evaluate the frequency and accuracy of rules, collect rules that often appear and lead to correct answers, and form a rule base
With good rules library, the next step is to study how to apply these rules to solve the problem. To this end, in the deduction phase, this study adds a rule base in prompt and requires LLM to retrieve rules from the rule base to perform deduction, converting implicit reasoning into explicit reasoning.
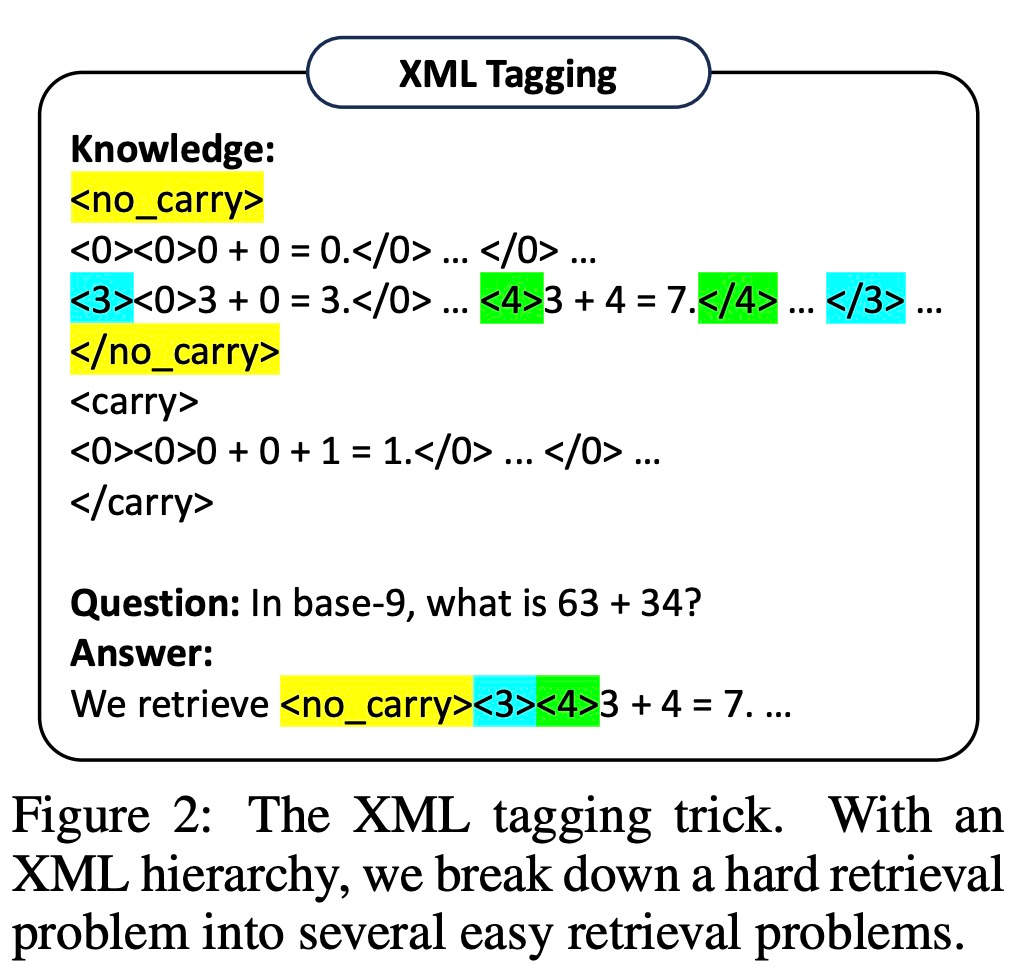
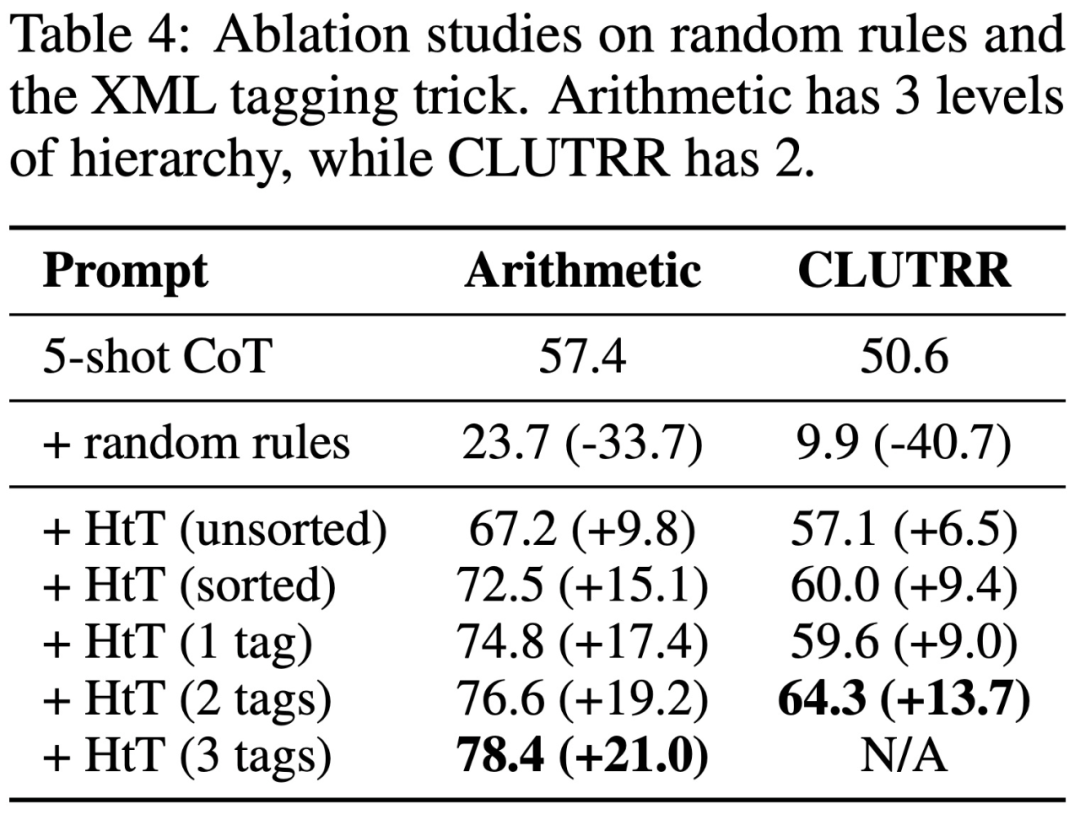
However, research has found that even very powerful LLMs (such as GPT-4) have difficulty retrieving the correct rules at every step. Therefore, this study developed XML markup techniques to enhance the contextual retrieval capabilities of LLM
To evaluate HtT, the study benchmarked two multi-step inference problems. Experimental results show that HtT improves the few-sample prompt method. The authors also performed extensive ablation studies to provide a more comprehensive understanding of HtT.
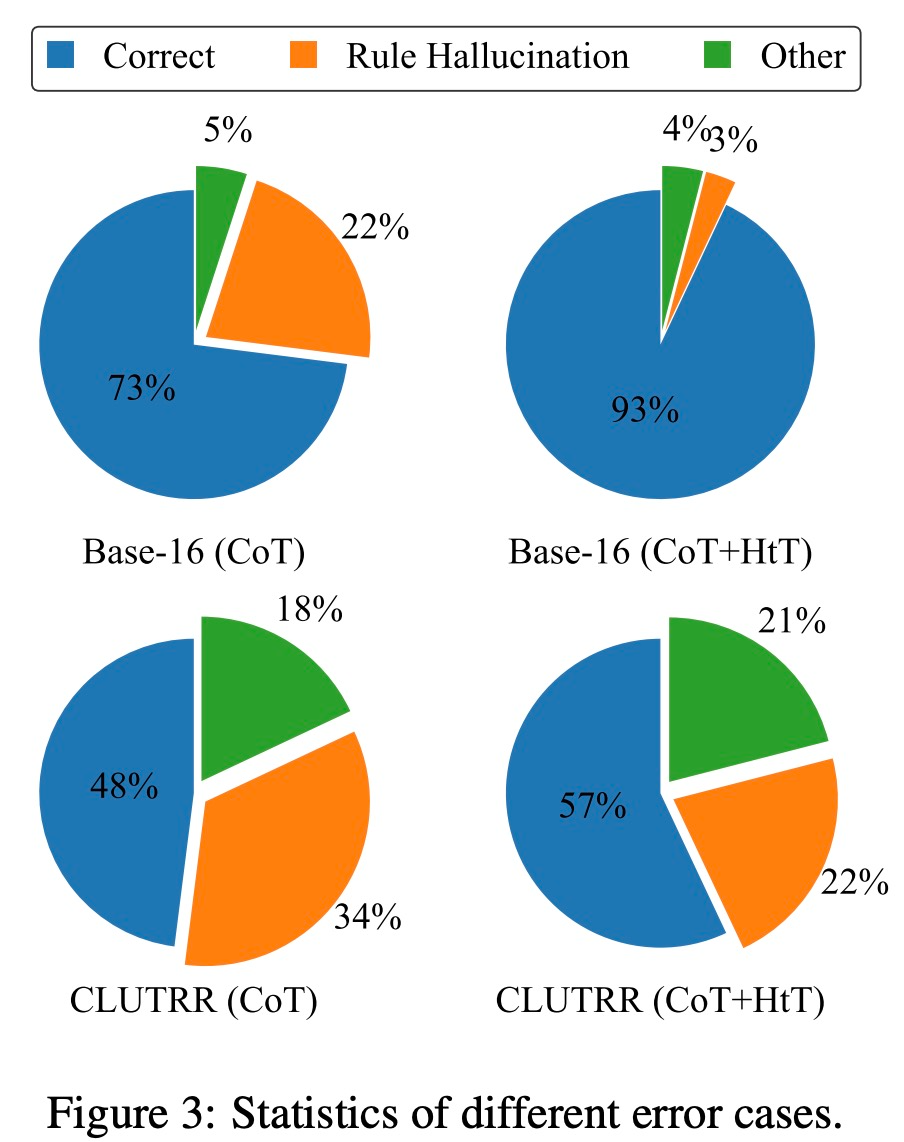
They evaluate new methods on numerical reasoning and relational reasoning problems. In numerical inference, they observed a 21.0% improvement in accuracy for GPT-4. In relational reasoning, GPT-4 achieved a 13.7% improvement in accuracy, and GPT-3.5 benefited even more, doubling the performance. The performance gain mainly comes from the reduction of rule illusion.
Specifically, Table 1 below shows the base-16, base-11 and base-9 in arithmetic Results on the dataset. Among all base systems, 0-shot CoT has the worst performance in both LLMs.
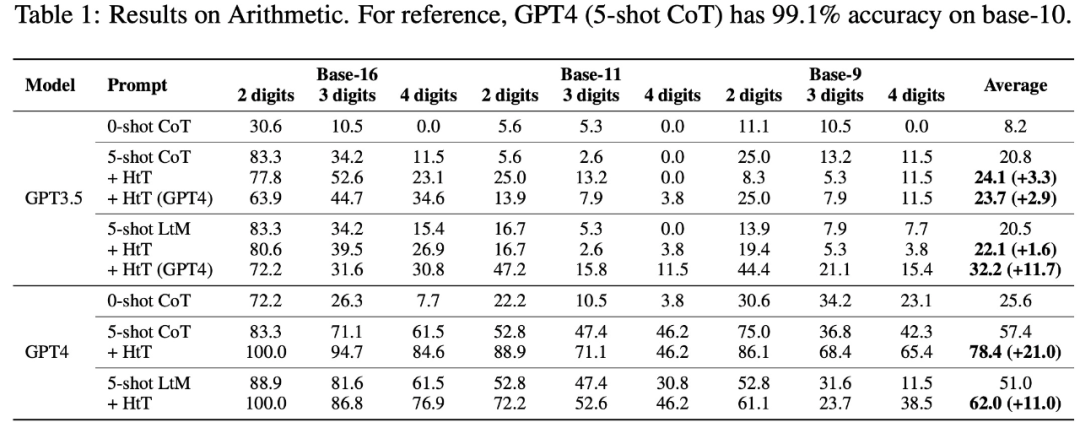
Table 2 presents the results comparing different methods on CLUTRR. It can be observed that 0-shot CoT has the worst performance in GPT3.5 and GPT4. For the few-shot prompting method, CoT and LtM perform similarly. In terms of average accuracy, HtT consistently outperforms the hinting methods for both models by 11.1-27.2%. It is worth noting that GPT3.5 is not bad at retrieving CLUTRR rules and benefits more from HtT than GPT4, probably because there are fewer rules in CLUTRR than in arithmetic.
It is worth mentioning that using the rules of GPT4, the CoT performance on GPT3.5 is improved by 27.2%, which is more than twice the CoT performance and close to the CoT performance on GPT4. Therefore, the authors believe that HtT can serve as a new form of knowledge distillation from strong LLM to weak LLM.
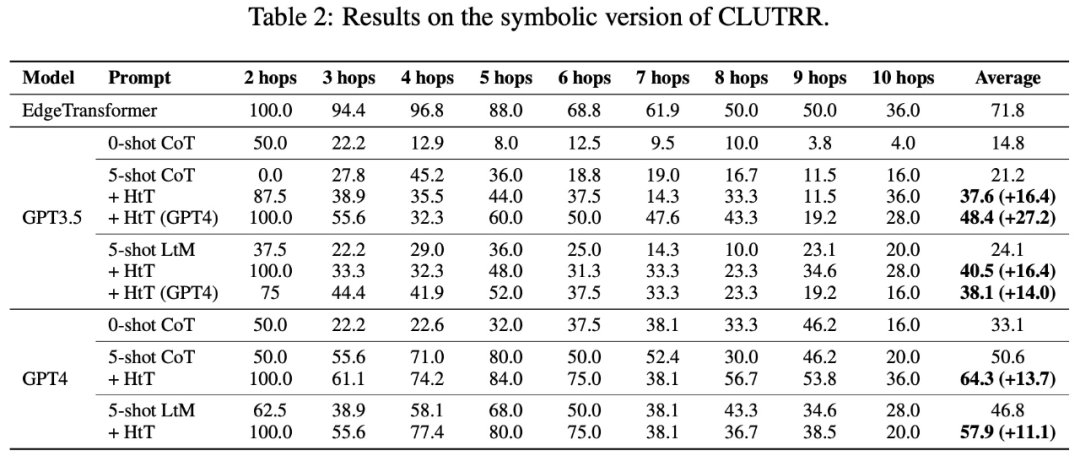
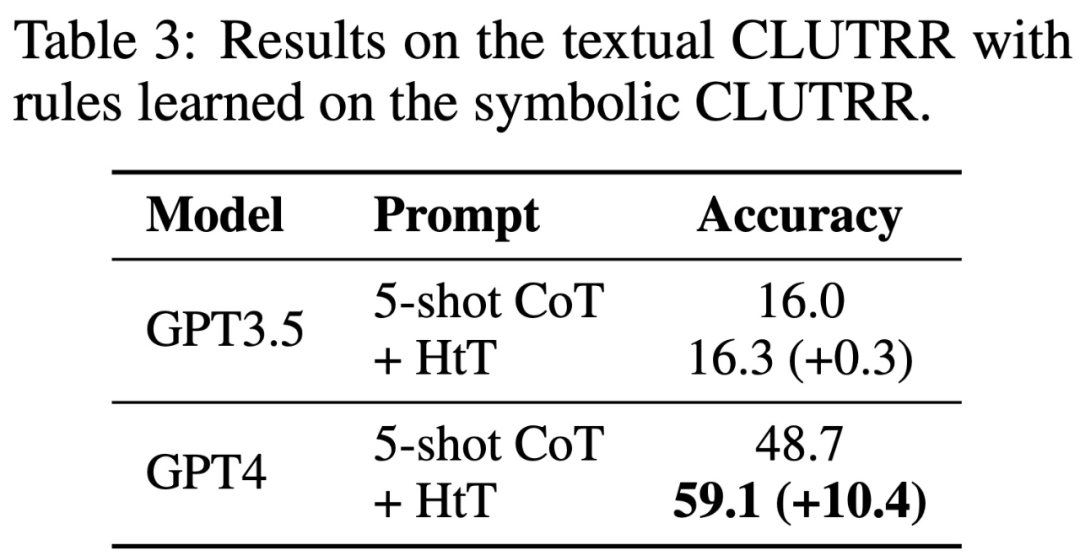
Table 3 shows that HtT significantly improves the performance of GPT-4 (text version). This improvement is not significant for GPT3.5, as it often produces errors other than rule illusion when processing text input.
The above is the detailed content of GPT-4 has improved its accuracy by 13.7% through DeepMind training, achieving better induction and deduction capabilities.. For more information, please follow other related articles on the PHP Chinese website!
 How to flash Xiaomi phone
How to flash Xiaomi phone
 How to center div in css
How to center div in css
 How to open rar file
How to open rar file
 Methods for reading and writing java dbf files
Methods for reading and writing java dbf files
 How to solve the problem that the msxml6.dll file is missing
How to solve the problem that the msxml6.dll file is missing
 Commonly used permutation and combination formulas
Commonly used permutation and combination formulas
 Virtual mobile phone number to receive verification code
Virtual mobile phone number to receive verification code
 dynamic photo album
dynamic photo album








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



