

Improve engineering efficiency - enhanced search generation (RAG)

With the advent of large-scale language models such as GPT-3, major breakthroughs have been made in the field of natural language processing (NLP). These language models have the ability to generate human-like text and have been widely used in various scenarios such as chatbots and translation

However, when it comes to specialization and customization When used in application scenarios, general-purpose large language models may be insufficient in terms of professional knowledge. Fine-tuning these models with specialized corpora is often expensive and time-consuming. "Retrieval Enhanced Generation" (RAG) provides a new technology solution for professional applications.
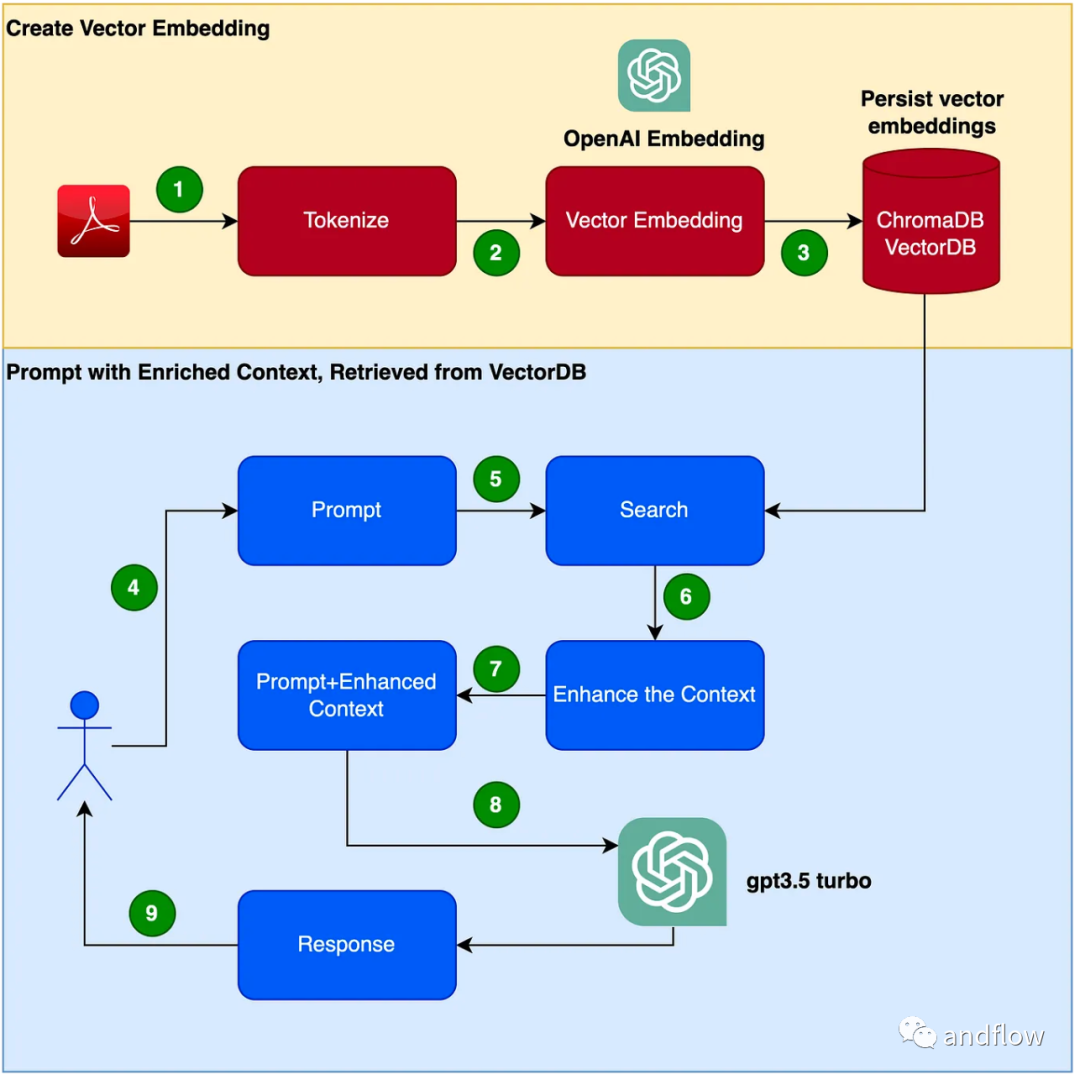
Below we mainly introduce how RAG works, and use a practical example to use the product manual as a professional corpus and use GPT-3.5 Turbo as a question and answer model to verify its effectiveness sex.
Case: Develop a chatbot that can answer questions related to a specific product. The enterprise has a unique user manual
RAG INTRODUCTION
RAG provides an effective solution for domain-specific questions and answers. It mainly converts industry knowledge into vectors for storage and retrieval, combines the retrieval results with user questions to form prompt information, and finally uses large models to generate appropriate answers. By combining the retrieval mechanism and language model, the responsiveness of the model is greatly enhanced
The steps to create a chatbot program are as follows:
- Read the PDF (user manual PDF file) and use chunk_size Tokenize 1000 tokens.
- Create vectors (you can use OpenAI EmbeddingsAPI to create vectors).
- Store vectors in the local vector library. We will use ChromaDB as the vector database (the vector database can also be replaced by Pinecone or other products).
- User issues prompt with query/question.
- Retrieve knowledge context data from the vector database based on the user's questions. This knowledge context data will be used in conjunction with the cue words in subsequent steps to enhance the cue words, often referred to as contextual enrichment.
- The prompt word containing the user question is passed to LLM along with enhanced contextual knowledge
- LLM answers based on this context.
Hands-on development
(1) Set up a Python virtual environment Set up a virtual environment to sandbox our Python to avoid any version or dependency conflicts. Execute the following command to create a new Python virtual environment.
需要重写的内容是:pip安装virtualenv,python3 -m venv ./venv,source venv/bin/activate
The content that needs to be rewritten is: (2) Generate OpenAI key
Using GPT requires an OpenAI key for access
The content that needs to be rewritten is: (3) Installation of dependent libraries
Various dependencies required by the installation program. Includes the following libraries:
- lanchain: A framework for developing LLM applications.
- chromaDB: This is VectorDB for persistent vector embeddings.
- unstructured: used to preprocess Word/PDF documents.
- tiktoken: Tokenizer framework
- pypdf: A framework for reading and processing PDF documents.
- openai: Access the OpenAI framework.
pip install langchainpip install unstructuredpip install pypdfpip install tiktokenpip install chromadbpip install openai
Create an environment variable to store the OpenAI key.
export OPENAI_API_KEY=<openai-key></openai-key>
(4) Convert the user manual PDF file into a vector and store it in ChromaDB
Import all the dependent libraries and functions that need to be used
import osimport openaiimport tiktokenimport chromadbfrom langchain.document_loaders import OnlinePDFLoader, UnstructuredPDFLoader, PyPDFLoaderfrom langchain.text_splitter import TokenTextSplitterfrom langchain.memory import ConversationBufferMemoryfrom langchain.embeddings.openai import OpenAIEmbeddingsfrom langchain.vectorstores import Chromafrom langchain.llms import OpenAIfrom langchain.chains import ConversationalRetrievalChain
Read PDF, tokenize document and split document.
loader = PyPDFLoader("Clarett.pdf")pdfData = loader.load()text_splitter = TokenTextSplitter(chunk_size=1000, chunk_overlap=0)splitData = text_splitter.split_documents(pdfData)Create a chroma collection and a local directory to store chroma data. Then, create a vector (embeddings) and store it in ChromaDB.
collection_name = "clarett_collection"local_directory = "clarett_vect_embedding"persist_directory = os.path.join(os.getcwd(), local_directory)openai_key=os.environ.get('OPENAI_API_KEY')embeddings = OpenAIEmbeddings(openai_api_key=openai_key)vectDB = Chroma.from_documents(splitData,embeddings,collection_name=collection_name,persist_directory=persist_directory)vectDB.persist()After executing this code, you should see a folder that has been created to store the vectors.
After storing the vector embedding in ChromaDB, you can use the ConversationalRetrievalChain API in LangChain to start a chat history component
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)chatQA = ConversationalRetrievalChain.from_llm(OpenAI(openai_api_key=openai_key, temperature=0, model_name="gpt-3.5-turbo"), vectDB.as_retriever(), memory=memory)
After initializing langchan, we You can use it to chat/Q A. In the code below, a question entered by the user is accepted, and after the user enters 'done', the question is passed to LLM to get the reply and print it out.
chat_history = []qry = ""while qry != 'done':qry = input('Question: ')if qry != exit:response = chatQA({"question": qry, "chat_history": chat_history})print(response["answer"])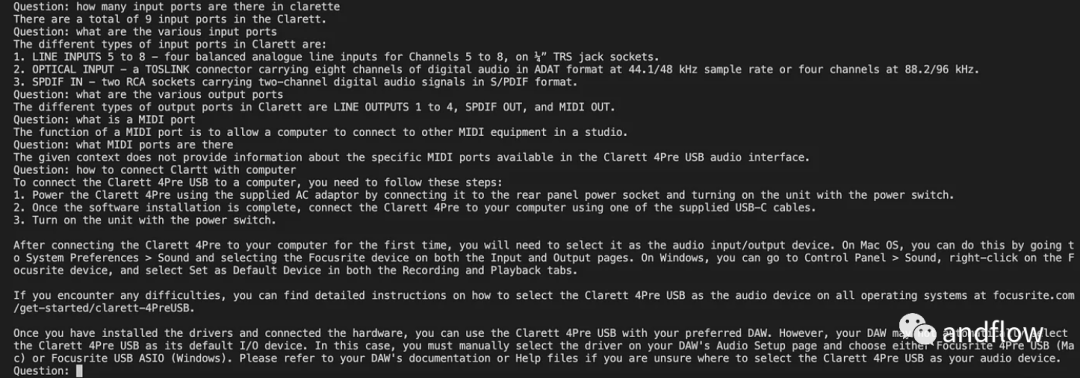

In short
RAG combines the advantages of language models such as GPT with the advantages of information retrieval. By utilizing specific knowledge context information to enhance the richness of prompt words, the language model is able to generate more accurate answers relevant to the knowledge context. RAG provides a more efficient and cost-effective solution than "fine-tuning", providing customizable interactive solutions for industry applications or enterprise applications
The above is the detailed content of Improve engineering efficiency - enhanced search generation (RAG). For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1359
1359
 52
52

 Context-augmented AI coding assistant using Rag and Sem-Rag
Jun 10, 2024 am 11:08 AM
Context-augmented AI coding assistant using Rag and Sem-Rag
Jun 10, 2024 am 11:08 AM
Improve developer productivity, efficiency, and accuracy by incorporating retrieval-enhanced generation and semantic memory into AI coding assistants. Translated from EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, author JanakiramMSV. While basic AI programming assistants are naturally helpful, they often fail to provide the most relevant and correct code suggestions because they rely on a general understanding of the software language and the most common patterns of writing software. The code generated by these coding assistants is suitable for solving the problems they are responsible for solving, but often does not conform to the coding standards, conventions and styles of the individual teams. This often results in suggestions that need to be modified or refined in order for the code to be accepted into the application
 GraphRAG enhanced for knowledge graph retrieval (implemented based on Neo4j code)
Jun 12, 2024 am 10:32 AM
GraphRAG enhanced for knowledge graph retrieval (implemented based on Neo4j code)
Jun 12, 2024 am 10:32 AM
Graph Retrieval Enhanced Generation (GraphRAG) is gradually becoming popular and has become a powerful complement to traditional vector search methods. This method takes advantage of the structural characteristics of graph databases to organize data in the form of nodes and relationships, thereby enhancing the depth and contextual relevance of retrieved information. Graphs have natural advantages in representing and storing diverse and interrelated information, and can easily capture complex relationships and properties between different data types. Vector databases are unable to handle this type of structured information, and they focus more on processing unstructured data represented by high-dimensional vectors. In RAG applications, combining structured graph data and unstructured text vector search allows us to enjoy the advantages of both at the same time, which is what this article will discuss. structure
 Utilizing knowledge graphs to enhance the capabilities of RAG models and mitigate false impressions of large models
Jan 14, 2024 pm 06:30 PM
Utilizing knowledge graphs to enhance the capabilities of RAG models and mitigate false impressions of large models
Jan 14, 2024 pm 06:30 PM
Hallucinations are a common problem when working with large language models (LLMs). Although LLM can generate smooth and coherent text, the information it generates is often inaccurate or inconsistent. In order to prevent LLM from hallucinations, external knowledge sources, such as databases or knowledge graphs, can be used to provide factual information. In this way, LLM can rely on these reliable data sources, resulting in more accurate and reliable text content. Vector Database and Knowledge Graph Vector Database A vector database is a set of high-dimensional vectors that represent entities or concepts. They can be used to measure the similarity or correlation between different entities or concepts, calculated through their vector representations. A vector database can tell you, based on vector distance, that "Paris" and "France" are closer than "Paris" and
 Understanding GraphRAG (1): Challenges of RAG
Apr 30, 2024 pm 07:10 PM
Understanding GraphRAG (1): Challenges of RAG
Apr 30, 2024 pm 07:10 PM
RAG (RiskAssessmentGrid) is a method that enhances existing large language models (LLM) with external knowledge sources to provide more contextually relevant answers. In RAG, the retrieval component obtains additional information, the response is based on a specific source, and then feeds this information into the LLM prompt so that the LLM's response is based on this information (enhancement phase). RAG is more economical compared to other techniques such as trimming. It also has the advantage of reducing hallucinations by providing additional context based on this information (augmentation stage) - your RAG becomes the workflow method for today's LLM tasks (such as recommendation, text extraction, sentiment analysis, etc.). If we break this idea down further, based on user intent, we typically look at
 Methods for building multimodal RAG systems: using CLIP and LLM
Jan 13, 2024 pm 10:24 PM
Methods for building multimodal RAG systems: using CLIP and LLM
Jan 13, 2024 pm 10:24 PM
We will discuss ways to build a retrieval-augmented generation (RAG) system using the open source LargeLanguageMulti-Modal. Our focus is to achieve this without relying on LangChain or LLlamaindex to avoid adding more framework dependencies. What is RAG In the field of artificial intelligence, the emergence of retrieval-augmented generation (RAG) technology has brought revolutionary improvements to large language models (LargeLanguageModels). The essence of RAG is to enhance artificial intelligence by allowing models to dynamically retrieve real-time information from external sources
 A deep dive into RAG and vector databases: the key to rapid, low-cost customization of large models
Nov 13, 2023 pm 03:29 PM
A deep dive into RAG and vector databases: the key to rapid, low-cost customization of large models
Nov 13, 2023 pm 03:29 PM
Today, in the field of artificial intelligence, a lot of attention is paid to large-scale models. However, factors such as high training costs and long training time have become key obstacles that restrict most companies from participating in the field of large-scale models. In this context, vector databases, with their unique advantages, have become a solution to the problem of low-cost and rapid customization of large models. The point is. Vector database is a technology specifically designed to store and process high-dimensional vector data. It uses efficient indexing and query algorithms to achieve rapid retrieval and analysis of massive data. In addition to such excellent performance, vector databases can also provide customized solutions for specific fields and tasks. Technology giants such as Tencent and Alibaba have invested in the research and development of vector databases, hoping to achieve breakthroughs in the field of large models. Many small and medium-sized companies also take advantage of
 In addition to RAG, there are five ways to eliminate the illusion of large models
Jun 10, 2024 pm 08:25 PM
In addition to RAG, there are five ways to eliminate the illusion of large models
Jun 10, 2024 pm 08:25 PM
Produced by 51CTO Technology Stack (WeChat ID: blog51cto) It is well known that LLM can produce hallucinations - that is, generate incorrect, misleading or meaningless information. Interestingly, some people, such as OpenAI CEO Sam Altman, view the imagination of AI as creativity, while others believe that imagination may help make new scientific discoveries. In most cases, however, it is crucial to provide the correct answer, and hallucinations are not a feature but a flaw. So, how to reduce the illusion of LLM? Long context? RAG? Fine-tuning? In fact, long-context LLMs are not foolproof, vector search RAGs are not satisfactory, and fine-tuning comes with its own challenges and limitations. Here are some that can be used
 A college student who used GPT-3 to write a paper was severely punished and refused to admit it! University papers are 'dead', ChatGPT may cause a major earthquake in the academic circle
Apr 11, 2023 pm 10:01 PM
A college student who used GPT-3 to write a paper was severely punished and refused to admit it! University papers are 'dead', ChatGPT may cause a major earthquake in the academic circle
Apr 11, 2023 pm 10:01 PM
After the birth of ChatGPT, it has continuously refreshed our understanding with its powerful text creation capabilities. What explosive changes will AI bring to university campuses? No one seems ready yet. Nature has issued an article, worrying that ChatGPT will become a tool for students to write papers. Article link: https://www.nature.com/articles/d41586-022-04397-7 Coincidentally, a Canadian writer Stephen Marche sadly called: The university thesis is dead! Writing a paper with AI is too easy. Suppose you are a professor of education and you have assigned a paper on learning styles for academic purposes. A student submitted an article to open
