

Rewritten content as: Machine Heart Report
Editors: Du Wei, Xiaozhou
GPT-4 and robots have created new sparks.

In the field of robotics, implementing universal robotic strategies requires a large amount of data, and collecting this data in the real world is time-consuming and laborious. Although simulation provides an economical solution for generating different volumes of data at the scene and instance levels, increasing task diversity in simulated environments still faces challenges due to the large amount of manpower required (especially for complex tasks). This results in typical artificial simulation benchmarks typically containing only tens to hundreds of tasks.
How to solve it? In recent years, large language models have continued to make significant progress in natural language processing and code generation for various tasks. Likewise, LLM has been applied to multiple aspects of robotics, including user interfaces, task and motion planning, robot log summary, cost and reward design, revealing strong capabilities in both physics-based and code generation tasks.
In a recent study, researchers from MIT CSAIL, Shanghai Jiao Tong University and other institutions further explored whether LLM can be used to create diverse simulation tasks and further explore their capabilities.
Specifically, the researchers proposed an LLM-based framework, GenSim, which provides an automated mechanism for designing and verifying task asset arrangements and task progress. More importantly, the generated tasks exhibit great diversity, promoting task-level generalization of robot strategies. Furthermore, conceptually, with GenSim, the reasoning and encoding capabilities of LLM are refined into language-visual-action strategies through intermediate synthesis of simulated data.

What needs to be rewritten is: Paper link:
https://arxiv.org/pdf/2310.01361.pdf
The GenSim framework consists of the following three parts:
At the same time, the framework operates through two different modes. Among them, in the goal-oriented setting, the user has a specific task or wishes to design a task course. At this time, GenSim adopts a top-down approach, taking the expected tasks as input and iteratively generating related tasks to achieve the expected goals. In an exploratory environment, if there is a lack of prior knowledge of the target task, GenSim gradually explores content beyond the existing tasks and establishes a basic strategy that is independent of the task.
In Figure 1 below, the researcher initialized a task library containing 10 manually planned tasks, used GenSim to extend it and generate more than 100 tasks.

The researchers also proposed several customized metrics to progressively measure the quality of generated simulation tasks, and evaluated several LLMs in goal-oriented and exploratory settings. For the task library generated by GPT-4, they performed supervised fine-tuning on LLMs such as GPT-3.5 and Code-Llama, further improving the task generation performance of LLM. At the same time, the achievability of tasks is quantitatively measured through strategy training, and task statistics of different attributes and code comparisons between different models are provided.
Not only that, the researchers also trained multi-task robot strategies. Compared with models trained only on human planning tasks, these strategies generalized well on all generation tasks and improved zero-shot generalization. chemical performance. Joint training with the GPT-4 generation task can improve generalization performance by 50% and transfer approximately 40% of zero-shot tasks to new tasks in simulations.
Finally, the researchers also considered simulation-to-real transfer, showing that pre-training on different simulation tasks can improve real-world generalization ability by 25%.
In summary, policies trained on different LLM-generated tasks achieve better task-level generalization to new tasks, highlighting the potential of extending simulated tasks through LLM to train base policies.
Tenstorrent AI Product Management Director Shubham Saboo gave this research high praise. He said that this is a breakthrough research on GPT-4 combined with robots, using LLM such as GPT-4 to generate a series of simulated robots on autopilot. tasks, making zero-shot learning and real-world adaptation of robots a reality.

Method introduction
As shown in Figure 2 below, the GenSim framework generates simulation environments, tasks and demonstrations through program synthesis. The GenSim pipeline starts from the task creator and the prompt chain runs in two modes, goal-directed mode and exploratory mode, depending on the target task. The task library in GenSim is an in-memory component used to store previously generated high-quality tasks. The tasks stored in the task library can be used for multi-task policy training or fine-tuning LLM.
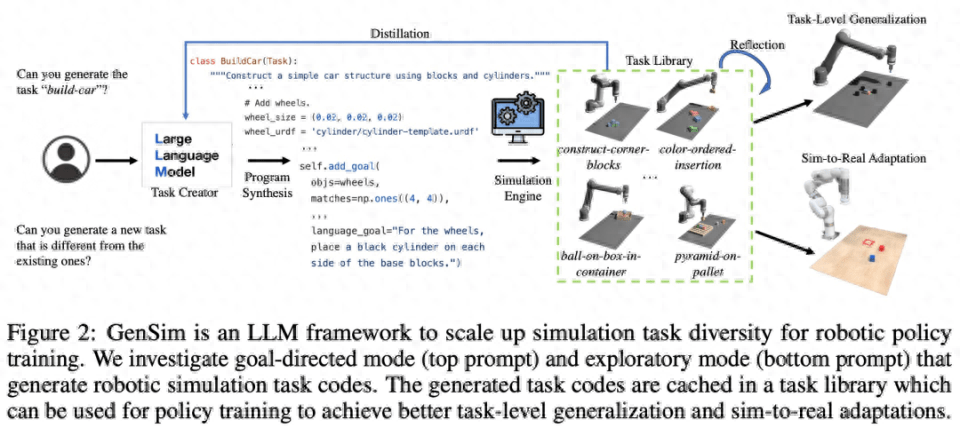
Task Creator
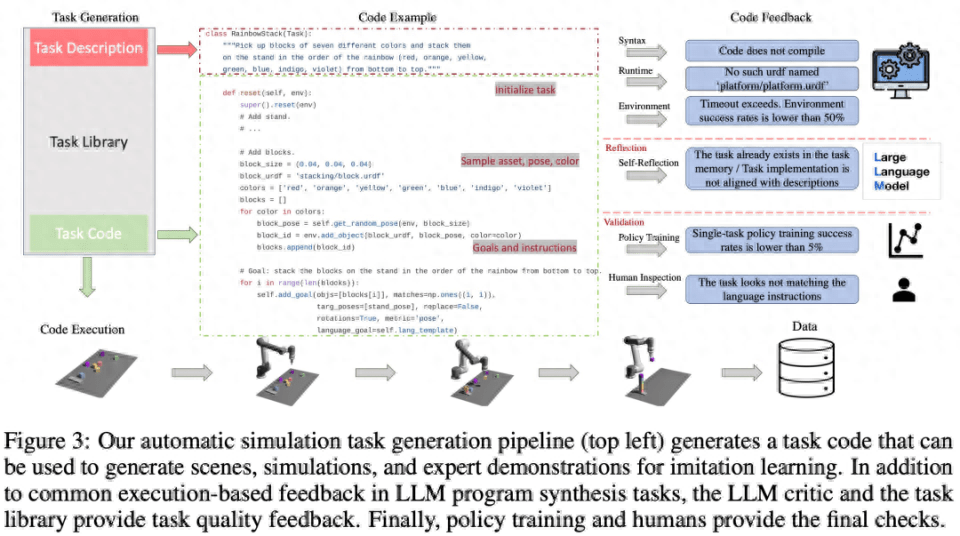
As shown in Figure 3 below, the language chain will first generate the task description, and then generate the related implementation. The task description includes the task name, resources, and task summary. This study uses a few-sample prompt in the pipeline to generate code.
Task Library
The task library in the GenSim framework stores tasks generated by the task creator to generate better new tasks and train multi-task strategies. The task library is initialized based on tasks from manually created benchmarks.
The task library provides the task creator with the previous task description as a condition for the description generation phase, provides the previous code for the code generation phase, and prompts the task creator to select a reference task from the task library as the basis for writing a new task Sample. After task implementation is complete and all tests have passed, LLM is prompted to "reflect" on the new task and task library and form a comprehensive decision on whether the newly generated task should be added to the library.
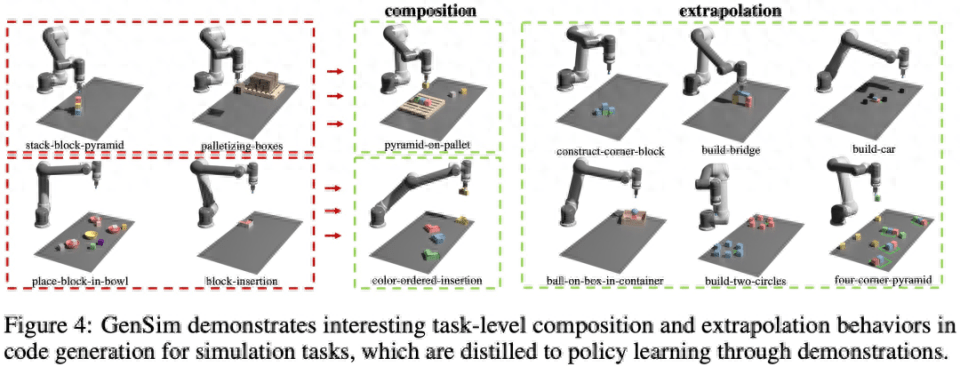
As shown in Figure 4 below, the study also observed that GenSim exhibits interesting task-level combination and extrapolation behavior:
LLM Supervised Multi-Task Strategy
After generating the tasks, this study uses these task implementations to generate demonstration data and train operational policies, using a dual-stream transmission network architecture similar to Shridhar et al. (2022).
As shown in Figure 5 below, this study regards the program as an effective representation of the task and related demonstration data (Figure 5). It is possible to define the embedding space between tasks, and its distance index is sensitive to various factors from perception (such as Object pose and shape) are more robust.

In order to rewrite the content, the language of the original text needs to be rewritten into Chinese, and the original sentence does not need to appear
This study validates the GenSim framework through experiments and addresses the following specific questions: (1) How effective is LLM in designing and implementing simulation tasks? Can GenSim improve the performance of LLM in task generation? (2) Can training on tasks generated by LLM improve policy generalization ability? Would policy training benefit more if given more generation tasks? (3) Is pre-training on LLM-generated simulation tasks beneficial to real-world robot policy deployment?
Evaluate the generalization ability of LLM robot simulation tasks
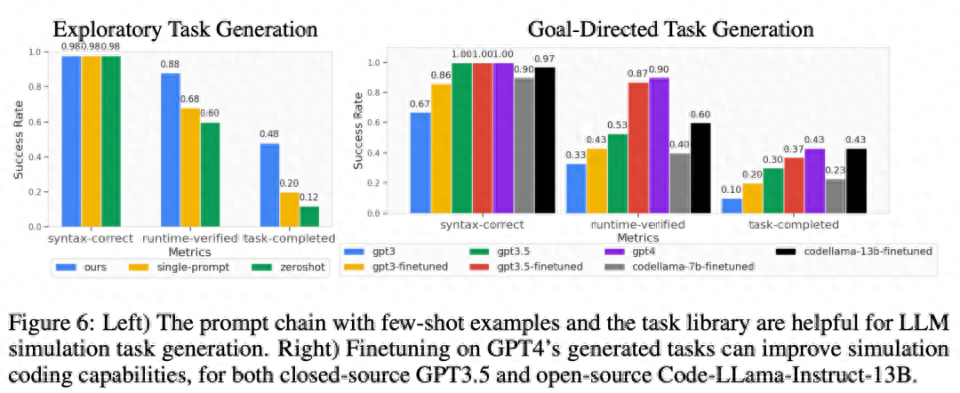
As shown in Figure 6 below, for exploration mode and goal-oriented mode task generation, the two-stage prompt chain of few samples and task library can effectively improve the success rate of code generation.
Task level generalization
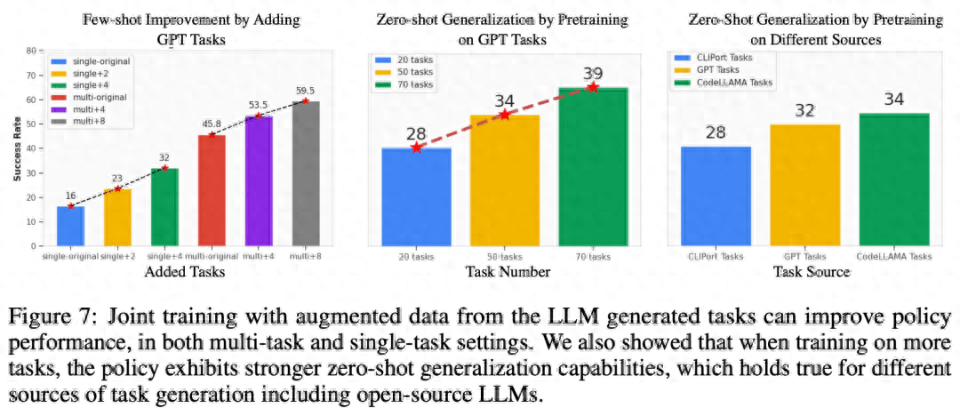
Few-sample strategy optimization for related tasks. As can be observed from the left side of Figure 7 below, jointly training the tasks generated by LLM can improve the policy performance on the original CLIPort task by more than 50%, especially in low data situations (such as 5 demos).
Zero-shot policy generalization to unseen tasks. As can be seen in Figure 7, by pre-training on more tasks generated by LLM, our model can better generalize to tasks in the original Ravens benchmark. In the middle right of Figure 7, the researchers also pre-trained on 5 tasks on different task sources, including manually written tasks, closed-source LLM, and open-source fine-tuned LLM, and observed similar zero-shot task-level generalization.
Adapting pre-trained models to the real world
Researchers transferred the strategies trained in the simulation environment to the real environment. The results are shown in Table 1 below. The model pre-trained on 70 GPT-4 generated tasks conducted 10 experiments on 9 tasks and achieved an average success rate of 68.8%, which is better than pre-training on the CLIPort task only. Compared with the baseline model, it has improved by more than 25%, and compared with the model pre-trained on only 50 tasks, it has improved by 15%.
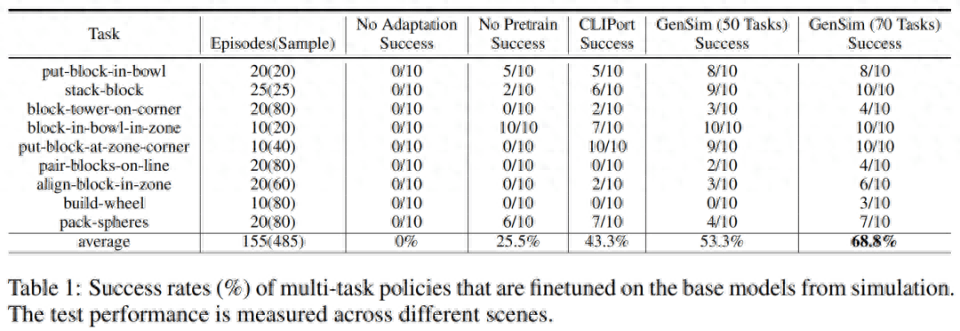
The researchers also observed that pre-training on different simulation tasks improved the robustness of long-term complex tasks. For example, GPT-4 pre-trained models show more robust performance on real-world build-wheel tasks.

Ablation experiment
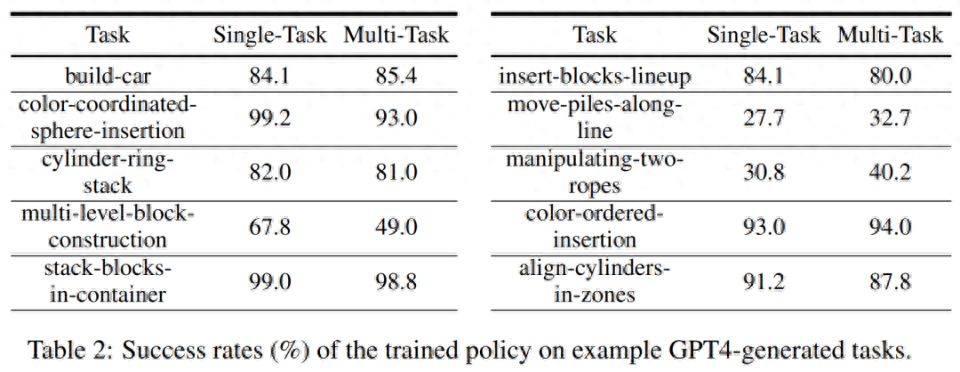
Simulation training success rate. In Table 2 below, the researchers demonstrate the success rates of single-task and multi-task policy training on a subset of generated tasks with 200 demos. For policy training on GPT-4 generation tasks, its average task success rate is 75.8% for single tasks and 74.1% for multi-tasks.
Generate task statistics. In Figure 9 (a) below, the researcher shows the task statistics of different features of the 120 tasks generated by LLM. There is an interesting balance between the colors, assets, actions, and number of instances generated by the LLM model. For example, the generated code contains a lot of scenes with more than 7 object instances, as well as a lot of pick-and-place primitive actions and assets like blocks.
In the comparison of code generation, the researcher qualitatively evaluated the failure cases in the top-down experiments of GPT-4 and Code Llama in Figure 9(b) below

For more technical details, please refer to the original paper.
The above is the detailed content of Language, robot breaking, MIT and others use GPT-4 to generate simulation tasks and migrate them to the real world. For more information, please follow other related articles on the PHP Chinese website!
 How to view stored procedures in MySQL
How to view stored procedures in MySQL
 parentnode usage
parentnode usage
 Solution to the problem of downloading software and installing it in win11
Solution to the problem of downloading software and installing it in win11
 Is HONOR Huawei?
Is HONOR Huawei?
 Computer software systems include
Computer software systems include
 Solution to slow access speed when renting a US server
Solution to slow access speed when renting a US server
 The main reason why computers use binary
The main reason why computers use binary
 How to center the web page in dreamweaver
How to center the web page in dreamweaver
 okx trading platform official website entrance
okx trading platform official website entrance








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



