
 Technology peripherals
AI
Yuncong Technology's large-scale model breaks the world record on benchmark COCO, significantly reducing the cost of AI application
Technology peripherals
AI
Yuncong Technology's large-scale model breaks the world record on benchmark COCO, significantly reducing the cost of AI application
Yuncong Technology's large-scale model breaks the world record on benchmark COCO, significantly reducing the cost of AI application

Recently, Yuncong Technology's large-scale model has made important progress again in the field of vision. The target detector based on the basic large-scale model of vision has achieved great results on the famous benchmark COCO data set in the detection field from Microsoft Research (MSR) and Shanghai Artificial Intelligence Laboratory. , Zhiyuan Artificial Intelligence Research Institute and many other well-known companies and research institutions stood out and set new world records.


The average accuracy (hereinafter referred to as mAP, mean Average Precision) of Yuncong Technology's large model on the COCO test set reached 0.662, ranking first on the list (see the figure below). On the validation set, the single-scale achieved mAP of 0.656, and the mAP after multi-scale TTA reached 0.662, both reaching world-leading levels.
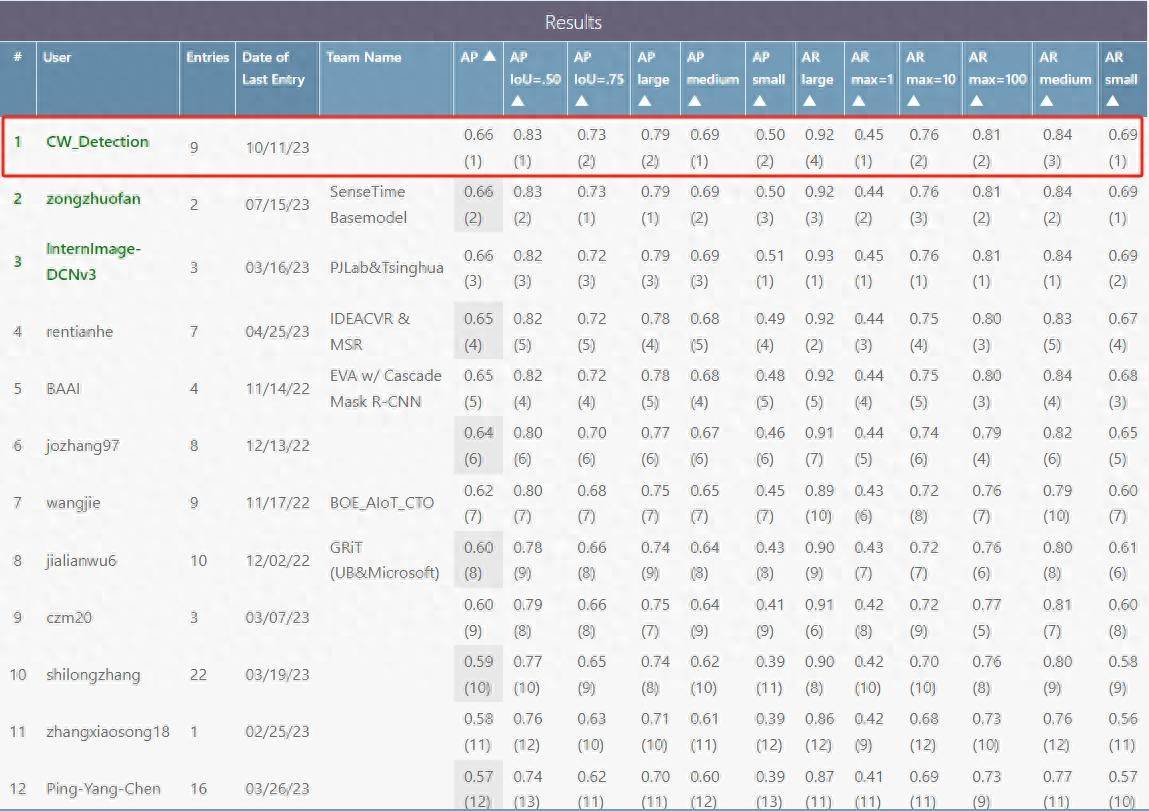
Big data combined with self-supervised learning to create visual core technology
Big data self-supervised pre-training represented by GPT has made remarkable breakthroughs in the field of natural language understanding (NLP). In the visual field, basic model training combining big data with self-supervised learning has also made important progress.
On the one hand, a wide range of visual data helps the model learn common basic features. YunCong Vision's large-scale basic model uses more than 2 billion data, including a large number of unlabeled data sets and multi-modal image and text data sets. The richness and diversity of the data sets enable the model to extract robust features, greatly reducing the complexity of downstream tasks. Development costs.
On the other hand, self-supervised learning does not require manual annotation, making it possible to train visual models with massive unlabeled data. Yuncong has made many improvements to the self-supervised learning algorithm, making it more suitable for fine-grained tasks such as detection and segmentation, as evidenced by its good results on the COCO detection task.
Open target detection and zero-time learning detection capabilities significantly reduce R&D costs
Thanks to the excellent performance of the visual basic model, Yuncong Rongrong's large model can be trained based on large-scale image and text multi-modal data to support zero-shot learning (hereinafter referred to as zero-shot) detection of thousands of categories of targets, covering energy, transportation , manufacturing and other industries.
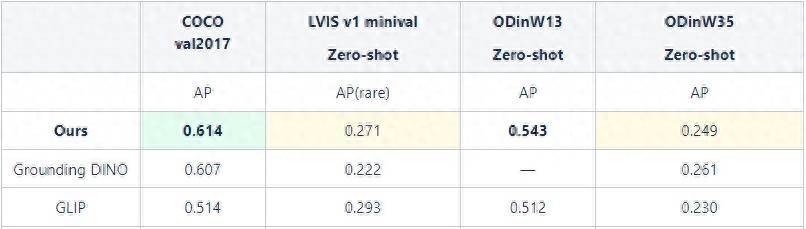 Performance of the zero-shot capability of the large model on different data sets
Performance of the zero-shot capability of the large model on different data sets
Zero-shot can imitate the human reasoning process and use past knowledge to reason about the specific form of new objects in the computer, thus giving the computer the ability to recognize new things.
How to understand zero-shot? Suppose we know the morphological characteristics of donkeys and horses, and also know that tigers and hyenas are striped animals, and pandas and penguins are black and white animals. We define zebras as equids with black and white stripes. Without looking at any photos of zebras, just relying on inference, we can find zebras among all the animals in the zoo.
Yuncong Vision's large-scale basic model shows strong generalization performance, greatly reducing the data dependence and development costs required for downstream tasks. At the same time, zero-shot greatly improves training and development efficiency, making wide application and rapid deployment a possible.
The above is the detailed content of Yuncong Technology's large-scale model breaks the world record on benchmark COCO, significantly reducing the cost of AI application. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 I Tried Vibe Coding with Cursor AI and It's Amazing!
Mar 20, 2025 pm 03:34 PM
I Tried Vibe Coding with Cursor AI and It's Amazing!
Mar 20, 2025 pm 03:34 PM
Vibe coding is reshaping the world of software development by letting us create applications using natural language instead of endless lines of code. Inspired by visionaries like Andrej Karpathy, this innovative approach lets dev
 Top 5 GenAI Launches of February 2025: GPT-4.5, Grok-3 & More!
Mar 22, 2025 am 10:58 AM
Top 5 GenAI Launches of February 2025: GPT-4.5, Grok-3 & More!
Mar 22, 2025 am 10:58 AM
February 2025 has been yet another game-changing month for generative AI, bringing us some of the most anticipated model upgrades and groundbreaking new features. From xAI’s Grok 3 and Anthropic’s Claude 3.7 Sonnet, to OpenAI’s G
 How to Use YOLO v12 for Object Detection?
Mar 22, 2025 am 11:07 AM
How to Use YOLO v12 for Object Detection?
Mar 22, 2025 am 11:07 AM
YOLO (You Only Look Once) has been a leading real-time object detection framework, with each iteration improving upon the previous versions. The latest version YOLO v12 introduces advancements that significantly enhance accuracy
 Best AI Art Generators (Free & Paid) for Creative Projects
Apr 02, 2025 pm 06:10 PM
Best AI Art Generators (Free & Paid) for Creative Projects
Apr 02, 2025 pm 06:10 PM
The article reviews top AI art generators, discussing their features, suitability for creative projects, and value. It highlights Midjourney as the best value for professionals and recommends DALL-E 2 for high-quality, customizable art.
 Is ChatGPT 4 O available?
Mar 28, 2025 pm 05:29 PM
Is ChatGPT 4 O available?
Mar 28, 2025 pm 05:29 PM
ChatGPT 4 is currently available and widely used, demonstrating significant improvements in understanding context and generating coherent responses compared to its predecessors like ChatGPT 3.5. Future developments may include more personalized interactions and real-time data processing capabilities, further enhancing its potential for various applications.
 Best AI Chatbots Compared (ChatGPT, Gemini, Claude & More)
Apr 02, 2025 pm 06:09 PM
Best AI Chatbots Compared (ChatGPT, Gemini, Claude & More)
Apr 02, 2025 pm 06:09 PM
The article compares top AI chatbots like ChatGPT, Gemini, and Claude, focusing on their unique features, customization options, and performance in natural language processing and reliability.
 How to Use Mistral OCR for Your Next RAG Model
Mar 21, 2025 am 11:11 AM
How to Use Mistral OCR for Your Next RAG Model
Mar 21, 2025 am 11:11 AM
Mistral OCR: Revolutionizing Retrieval-Augmented Generation with Multimodal Document Understanding Retrieval-Augmented Generation (RAG) systems have significantly advanced AI capabilities, enabling access to vast data stores for more informed respons
 Top AI Writing Assistants to Boost Your Content Creation
Apr 02, 2025 pm 06:11 PM
Top AI Writing Assistants to Boost Your Content Creation
Apr 02, 2025 pm 06:11 PM
The article discusses top AI writing assistants like Grammarly, Jasper, Copy.ai, Writesonic, and Rytr, focusing on their unique features for content creation. It argues that Jasper excels in SEO optimization, while AI tools help maintain tone consist
