

While 4K image quality and 60-frame video can only be viewed by members on some APPs, AI researchers have achieved 4K level 3D dynamic synthesis video, and the picture is quite smooth.


#In real life, most of the videos we come into contact with are 2D. When watching this kind of video, we have no way to choose the viewing angle, such as walking among the actors or walking to a corner of the space. The emergence of VR and AR devices has made up for this shortcoming. The 3D videos they provide allow us to change our perspective and even move around at will, greatly improving the sense of immersion.
However, the synthesis of this kind of 3D dynamic scene has always been a difficulty, both in terms of image quality and smoothness.
Recently, researchers from Zhejiang University, Xiangyan Technology and Ant Group have challenged this problem. In a paper titled "4K4D: Real-Time 4D View Synthesis at 4K Resolution", they proposed a point cloud representation method called 4K4D, which greatly improves the rendering speed of high-resolution 3D dynamic scene synthesis. Specifically, using an RTX 4090 GPU, their method can render at 4K resolution at a frame rate of up to 80 FPS and at 1080p resolution at a frame rate of up to 400 FPS. Overall, it is more than 30 times faster than the previous method, and the rendering quality reaches SOTA.

The following is an introduction to the paper.

Dynamic view synthesis aims to reconstruct dynamic 3D scenes from captured video and create immersive virtual replays , which is a long-term research problem in computer vision and computer graphics. Key to the utility of this technology is its ability to render in real-time with high fidelity, allowing it to be used in VR/AR, sports broadcasts, and artistic performance capture. Traditional approaches represent dynamic 3D scenes as sequences of textured meshes and use complex hardware to reconstruct them. Therefore, they are usually restricted to controlled environments.
Recently, implicit neural representations have achieved great success in reconstructing dynamic 3D scenes from RGB videos via differentiable rendering. For example, "Neural 3d video synthesis from multi-view video" models the target scene as a dynamic radiation field, uses volume rendering to synthesize the image, and compares and optimizes it with the input image. Despite the impressive dynamic view synthesis results, existing methods often take seconds or even minutes to render an image at 1080p resolution due to expensive network evaluation.
Inspired by static view synthesis methods, some dynamic view synthesis methods improve rendering speed by reducing the cost or number of network evaluations. Through these strategies, MLP Maps is able to render foreground dynamic figures at 41.7 fps. However, rendering speed challenges remain, as the real-time performance of MLP Maps is only achievable when compositing images of moderate resolution (384×512). When rendering a 4K resolution image, it slowed down to just 1.3 FPS.
In this paper, researchers propose a new neural representation - 4K4D, for modeling and rendering dynamic 3D scenes. As shown in Figure 1, 4K4D significantly outperforms previous dynamic view synthesis methods in rendering speed while being competitive in rendering quality.

The authors stated that their core innovation lies in 4D point cloud representation and hybrid appearance model. Specifically, for dynamic scenes, they use a space carving algorithm to obtain a coarse point cloud sequence and model the position of each point as a learnable vector. They also introduced a 4D feature grid to assign feature vectors to each point and fed it into the MLP network to predict the radius, density, and spherical harmonics (SH) coefficients of the points. 4D feature meshes naturally apply spatial regularization on the point cloud, making the optimization more robust. Based on 4K4D, researchers developed a differentiable depth peeling algorithm that uses hardware rasterization to achieve unprecedented rendering speeds.
Researchers found that the SH model based on MLP is difficult to represent the appearance of dynamic scenes. To alleviate this problem, they also introduced an image mixture model to be combined with the SH model to represent the appearance of the scene. An important design is that they make the image blending network independent of viewing direction, so it can be pre-computed after training to improve rendering speed. As a double-edged sword, this strategy makes the image mixture model discrete along the viewing direction. This problem can be remedied using a continuous SH model. Compared with 3D Gaussian Splatting that only uses SH models, the hybrid appearance model proposed by the researchers fully utilizes the information captured by the input image, thereby effectively improving the rendering quality.
To verify the effectiveness of the new method, the researchers evaluated 4K4D on multiple widely used multi-view dynamic new view synthesis datasets, including NHR, ENeRF-Outdoo, DNA- Rendering and Neural3DV. Extensive experiments have shown that 4K4D is not only orders of magnitude faster in rendering speed, but also significantly better than SOTA technology in terms of rendering quality. Using an RTX 4090 GPU, the new method achieves 400 FPS on the DNA-Rendering dataset at 1080p resolution and 80 FPS on the ENeRF-Outdoor dataset at 4k resolution.
Given a multi-view video capturing a dynamic 3D scene, this paper aims to reconstruct the target scene and perform view synthesis in real-time. The model architecture diagram is shown in Figure 2:
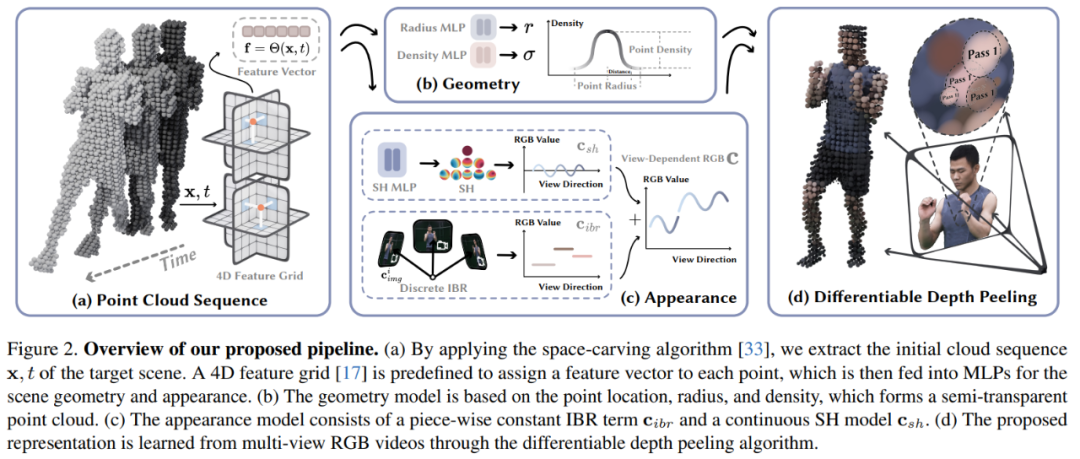
Then the article introduces the relevant knowledge of using point clouds to model dynamic scenes. They start from 4D embedding, The geometric model and appearance model are expanded from other angles.
4D Embedding: Given a coarse point cloud of a target scene, this paper uses neural networks and feature meshes to represent its dynamic geometry and appearance. Specifically, this article first defines six feature planes θ_xy, θ_xz, θ_yz, θ_tx, θ_ty and θ_tz, and uses the K-Planes strategy to use these six planes to model a 4D feature field Θ(x, t):
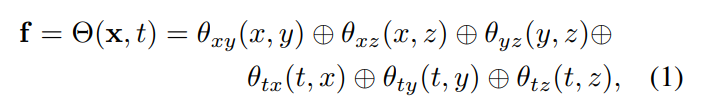
Geometric model: Based on coarse point clouds, the dynamic scene geometry is constructed by learning three attributes on each point ( entries), that is, position p ∈ R^3, radius r ∈ R and density σ ∈ R. Then with the help of these points, the volume density of the point x in space is calculated. The point position p is modeled as an optimizable vector. The radius r and density σ are predicted by feeding the feature vector f in Eq.(1) into the MLP network.
Appearance model: As shown in Figure 2c, this article uses image blending technology and spherical harmonic function (SH) model to build a hybrid appearance model, where the image blending technology represents the discrete view appearance c_ibr, The SH model represents a continuous view-dependent appearance c_sh. For the point x at the t-th frame, its color in the view direction d is:
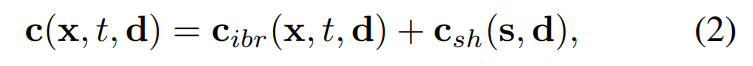
differentiable depth peeling
#The dynamic scene representation proposed in this article can be rendered into an image with the help of depth peeling algorithm.
The researchers developed a custom shader to implement the depth peeling algorithm consisting of K rendering passes. That is, for a specific pixel u, the researcher performed multi-step processing. Finally, after K renderings, the pixel u obtained a set of sorting points {x_k|k = 1, ..., K}.
Based on these points {x_k|k = 1, ..., K}, the color of pixel u in volume rendering is expressed as:
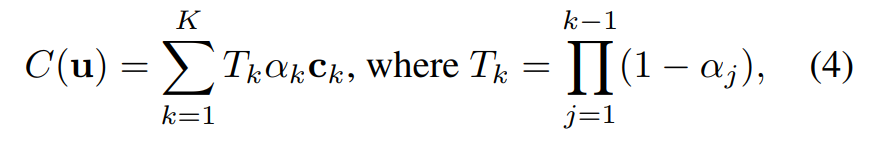
During the training process, given the rendered pixel color C (u), this paper compares it with the real pixel color C_gt (u) and uses the following loss function to optimize the model in an end-to-end manner:
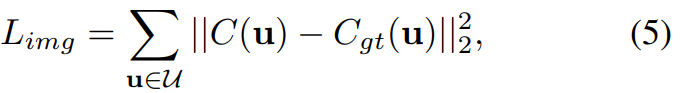
In addition, this article also applies perceptual loss:
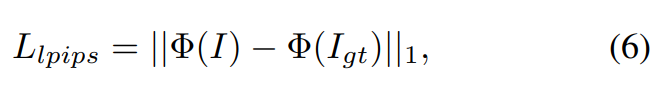
And mask loss:
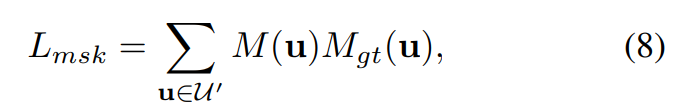
The final loss function is defined as:
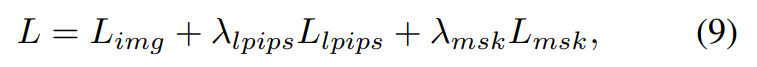
This paper evaluates the 4K4D method on DNA-Rendering, ENeRF-Outdoor, NHR and Neural3DV data sets.
The results on the DNA-Rendering data set are shown in Table 1. The results show that the 4K4D rendering speed is more than 30 times faster than ENeRF with SOTA performance, and the rendering quality is better .
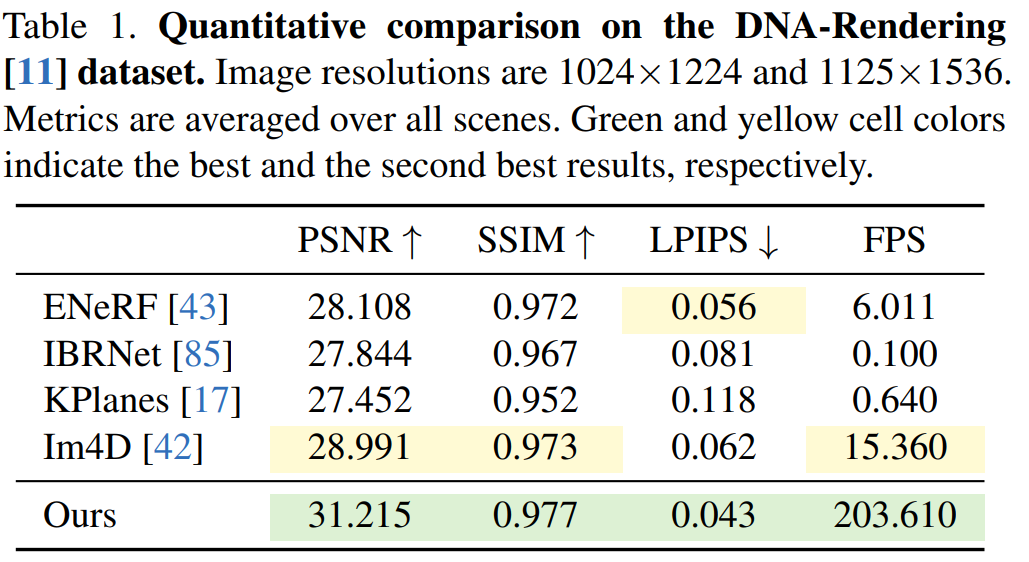
Qualitative results on the DNA-Rendering dataset are shown in Figure 5. KPlanes cannot handle the detailed appearance and geometry of 4D dynamic scenes. restoration, whereas other image-based methods produce high-quality appearances. However, these methods tend to produce blurry results around occlusions and edges, resulting in reduced visual quality, whereas 4K4D can produce higher-fidelity renderings at over 200 FPS.

Next, experiments show the qualitative and quantitative results of different methods on the ENeRFOutdoor dataset. As shown in Table 2, 4K4D still achieved significantly better results when rendering at over 140 FPS.
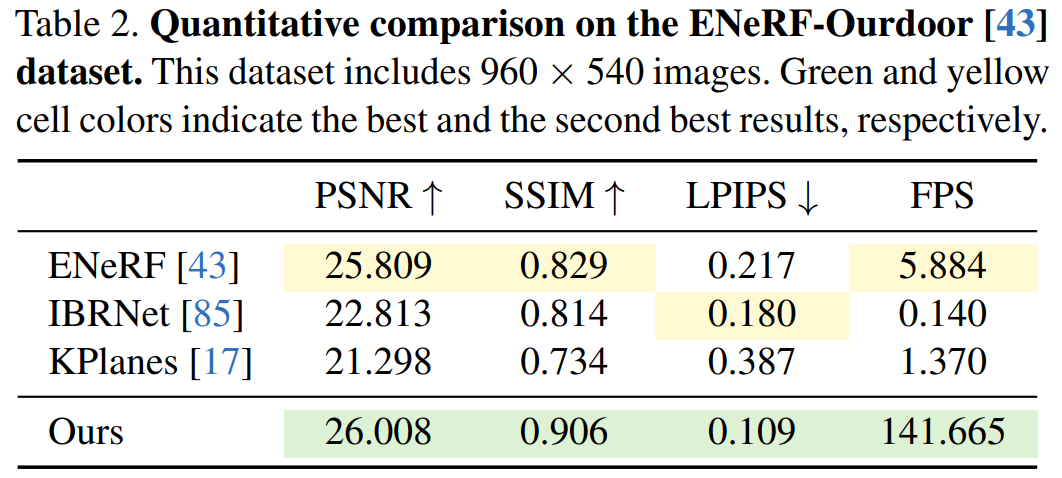
While other methods, such as ENeRF, produce blurry results; IBRNet's rendering results contain black artifacts around the edges of the image, as shown in Figure 3 display; K-Planse cannot reconstruct dynamic human bodies and different background areas.

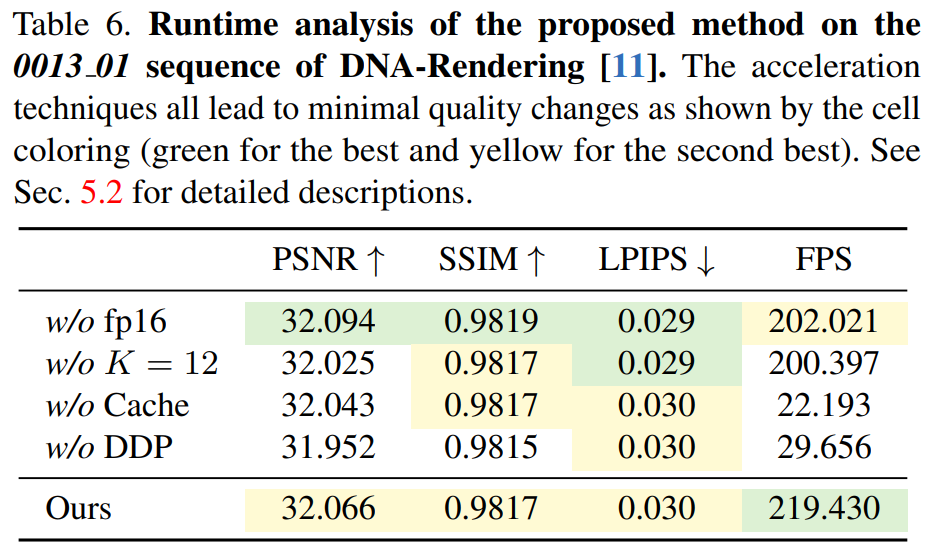
Table 6 demonstrates the effectiveness of the differentiable depth peeling algorithm, with 4K4D being more than 7 times faster than CUDA-based methods.
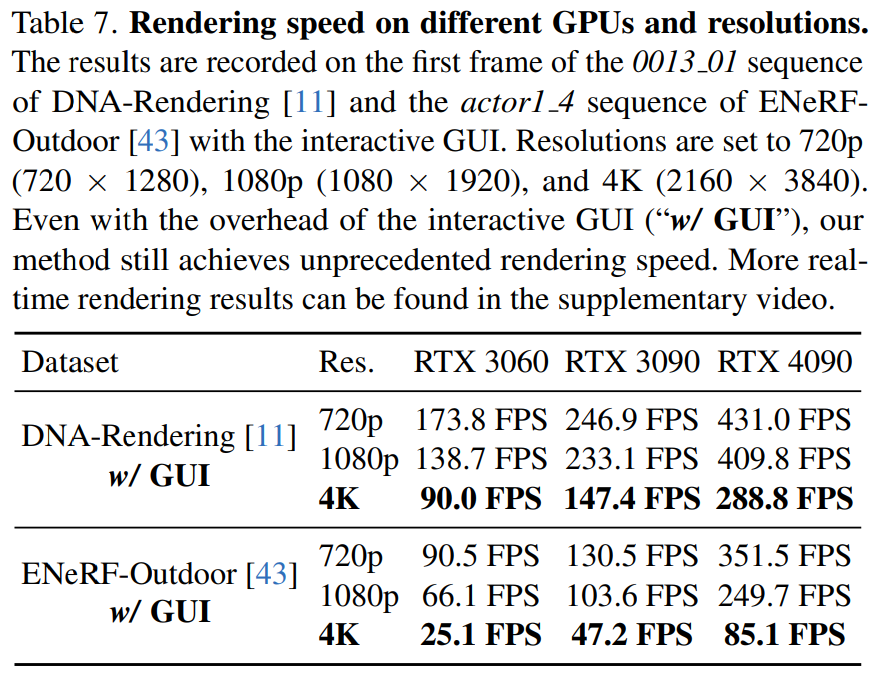
This article also reports 4K4D rendering speeds on different hardware (RTX 3060, 3090, and 4090) at different resolutions in Table 7.
Please see the original paper for more details.
The above is the detailed content of 4K quality 3D composite video no longer freezes in slideshows, and the new method increases rendering speed by more than 30 times. For more information, please follow other related articles on the PHP Chinese website!
 Mechanical energy conservation law formula
Mechanical energy conservation law formula
 what is dandelion
what is dandelion
 The function of intermediate relay
The function of intermediate relay
 How to pay with WeChat on Douyin
How to pay with WeChat on Douyin
 All uses of cloud servers
All uses of cloud servers
 How to apply for a business email
How to apply for a business email
 Can Douyin short videos be restored after being deleted?
Can Douyin short videos be restored after being deleted?
 formatter function usage
formatter function usage
 How to use months_between in SQL
How to use months_between in SQL








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



