
 Technology peripherals
AI
With GPT-4, the robot has learned how to spin a pen and plate walnuts.
Technology peripherals
AI
With GPT-4, the robot has learned how to spin a pen and plate walnuts.
With GPT-4, the robot has learned how to spin a pen and plate walnuts.

In terms of learning, GPT-4 is a great student. After digesting a large amount of human data, it has mastered various knowledge and can even inspire mathematician Terence Tao during chats.
At the same time, it has also become an excellent teacher, and it not only teaches book knowledge, but also teaches the robot to turn pens.

The robot, called Eureka, is the result of research from Nvidia, the University of Pennsylvania, Caltech, and the University of Texas at Austin. This research combines research on large language models and reinforcement learning: GPT-4 is used to refine the reward function, and reinforcement learning is used to train robot controllers.
With the ability to write code in GPT-4, Eureka has excellent reward function design capabilities. Its independently generated rewards are better than those of human experts in 83% of tasks. This ability allows robots to complete many tasks that were not easy to complete before, such as turning pens, opening drawers and cabinets, throwing and catching balls, dribbling, and operating scissors. However, this is all done in a virtual environment for the time being.



#In addition, Eureka also implements a new type of in -context RLHF, which is able to incorporate natural language feedback from human operators to guide and align reward functions. It can provide powerful auxiliary functions for robot engineers and help engineers design complex motion behaviors. Jim Fan, a senior AI scientist at NVIDIA and one of the authors of the paper, likened this research to "Voyager (the outer galaxy space probe developed and built by the United States) in physics simulator API space."

It is worth mentioning that this research is completely open source, the open source address is as follows:

- Paper link: https://arxiv.org/pdf/2310.12931.pdf
- Project link: https://eureka-research.github.io/
- Code link: https://github.com/eureka-research/Eureka
Paper Overview
Large language models (LLM) excel in high-level semantic planning for robotic tasks (such as Google SayCan, RT-2 robots), but whether they can be used to learn complex low-level manipulation tasks, such as turning a pen, remains an open question. Existing attempts require extensive domain expertise to construct task prompts or learn only simple skills, falling far short of human-level flexibility.

Google’s RT-2 robot.
On the other hand, reinforcement learning (RL) has achieved impressive results in flexibility and many other aspects (such as OpenAI’s Rubik’s Cube-playing robot hand), but requires human design The engineer carefully constructs the reward function to accurately codify and provide the learning signal for the desired behavior. Since many real-world reinforcement learning tasks only provide sparse rewards that are difficult to use for learning, reward shaping is needed in practice to provide progressive learning signals. Despite its importance, the reward function is notoriously difficult to design. A recent survey found that 92% of reinforcement learning researchers and practitioners surveyed said they engaged in manual trial and error when designing rewards, and 89% said the rewards they designed were suboptimal and led to unintended consequences. Behavior.
Given that reward design is so important, we can’t help but ask, is it possible to develop a general reward programming algorithm using state-of-the-art coding LLM (such as GPT-4)? These LLMs have excellent performance in code writing, zero-shot generation, and in-context learning, and have greatly improved the performance of programming agents. Ideally, such reward design algorithms should have human-level reward generation capabilities, be scalable to a wide range of tasks, automate the tedious trial-and-error process without human supervision, while being compatible with human supervision to ensure safety. sex and consistency.
This paper proposes a reward design algorithm EUREKA (full name is Evolution-driven Universal REward Kit for Agent) driven by LLM. This algorithm has achieved the following achievements:
#1. The performance of reward design has reached human level in 29 different open source RL environments, including 10 different robot forms ( Quadruped robots, quadrotor robots, biped robots, manipulators, and several dexterous hands, see Figure 1. Without any task-specific prompts or reward templates, EUREKA’s autonomously generated rewards outperformed humans in 83% of tasks Expert rewards and achieved an average normalized improvement of 52%.

2. Solve the dexterity that was previously unachievable through manual reward engineering Operational tasks. Take the pen-turning problem as an example, in which a hand with five fingers needs to quickly rotate a pen according to a preset rotation configuration and rotate as many cycles as possible. By combining EUREKA with the course Combined with learning, the researcher demonstrated the operation of rapid pen rotation for the first time on a simulated anthropomorphic "Shadow Hand" (see the bottom of Figure 1).
3. Reinforcement learning based on human feedback (RLHF) provides a new gradient-free context learning method that can generate more efficient and human-aligned reward functions based on various forms of human input. The paper shows that EUREKA can generate from existing human reward functions Benefit and improve. Similarly, the researchers also demonstrated EUREKA's ability to use human text feedback to assist in the design of reward functions, which helps capture subtle human preferences.
With Unlike previous L2R work that used LLM to assist reward design, EUREKA has no specific task prompts, reward templates, and a small number of examples. In experiments, EUREKA performed significantly better than L2R, thanks to its ability to generate and improve free-form, expressive capabilities Strong reward program.
EUREKA’s generality benefits from three key algorithm design choices: environment as context, evolutionary search, and reward reflection.
First, by taking the environment source code as context, EUREKA can generate executable reward functions from zero samples in the backbone encoding LLM (GPT-4). Then, EUREKA iteratively Proposing batches of reward candidates and refining the most promising rewards within the LLM context window greatly improves the quality of rewards. This in-context improvement is achieved through reward reflection, which is a reward based on policy training statistics Quality text summary, enabling automatic and targeted reward editing.
Figure 3 shows an example of EUREKA’s zero-sample reward, as well as various improvements accumulated during the optimization process. In order to ensure that EUREKA can Extending its reward search to its maximum potential, EUREKA uses GPU-accelerated distributed reinforcement learning on IsaacGym to evaluate intermediate rewards, which provides up to three orders of magnitude improvements in policy learning speed, making EUREKA a broadly applicable algorithm that Naturally expands as the amount of calculation increases.

as shown in picture 2. The researchers are committed to open-sourcing all prompts, environments, and generated reward functions to facilitate further research on LLM-based reward design.

Method introduction
EUREKA can independently write the reward algorithm, specifically How to achieve this, let’s see below.
EUREKA consists of three algorithmic components: 1) using the environment as context, thereby supporting zero-shot generation of executable rewards; 2) evolutionary search, iteratively proposing and refining reward candidates; 3 ) rewards reflection and supports fine-grained reward improvements.
Environment as context
This article recommends directly providing the original environment code as context. With only minimal instructions, EUREKA can generate rewards in different environments with zero samples. An example of EUREKA output is shown in Figure 3. EUREKA expertly combines existing observation variables (e.g., fingertip position) in the provided environment code and produces a valid reward code - all without any environment-specific hint engineering or reward templates.
However, the generated reward may not always be executable on the first try, and even if it is executable, it may be sub-optimal. This raises a question, that is, how to effectively overcome the suboptimality of single-sample reward generation?

Evolutionary Search
Then, the paper introduces how evolutionary search is Solving problems such as the sub-optimal solutions mentioned above. They are refined in such a way that in each iteration, EUREKA samples several independent outputs of the LLM (line 5 in Algorithm 1). Since each iteration (generations) is independently and identically distributed, as the number of samples increases, the probability of errors in all reward functions in the iteration decreases exponentially.


##Bonus Reflection
To provide more complex and targeted reward analysis, this paper proposes building automated feedback to summarize policy training dynamics in text. Specifically, given that the EUREKA reward function requires individual components in the reward program (such as the reward components in Figure 3), we track the scalar values of all reward components at intermediate policy checkpoints throughout the training process.
Although it is very simple to build this kind of reward reflection process, due to the dependencies of the reward optimization algorithm, this way of building it is very important. That is, whether the reward function is efficient is affected by the specific choice of RL algorithm, and the same reward can behave very differently even under the same optimizer given differences in hyperparameters. By detailing how RL algorithms optimize individual reward components, reward reflection enables EUREKA to produce more targeted reward edits and synthesize reward functions that better synergize with fixed RL algorithms.

Experiment
The experimental part conducts a comprehensive evaluation of Eureka, including the ability to generate reward functions , the ability to solve new tasks and the ability to integrate various human inputs.
The experimental environment includes 10 different robots and 29 tasks, among which these 29 tasks are implemented by the IsaacGym simulator. Experiments were conducted using 9 original environments from IsaacGym (Isaac), covering a variety of robot morphologies from quadrupeds, bipeds, quadcopters, manipulators, and dexterous hands of robots. In addition to this, the paper ensures depth of evaluation by including 20 tasks from the Dexterity benchmark.

Eureka can generate superhuman level reward functions. Across 29 tasks, the reward function given by Eureka performed better than the reward written by experts on 83% of the tasks, with an average improvement of 52%. In particular, Eureka achieves greater gains in the high-dimensional Dexterity benchmark environment.

Eureka is able to evolve reward searches so that rewards continue to improve over time. By combining large-scale reward search and detailed reward reflection feedback, Eureka gradually produces better rewards, eventually surpassing human levels.
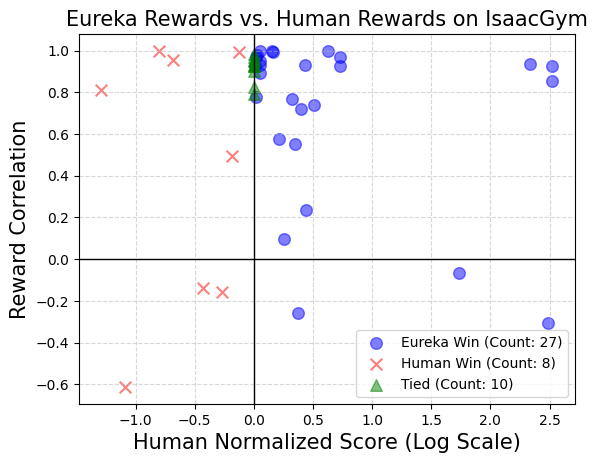
Eureka also generates novel rewards. This paper evaluates the novelty of Eureka rewards by computing the correlation between Eureka rewards and human rewards on all Isaac tasks. As shown in the figure, Eureka mainly generates weakly correlated reward functions, which outperform human reward functions. Additionally, we observe that the more difficult the task, the less relevant the Eureka reward is. In some cases, Eureka rewards were even negatively correlated with human rewards, yet significantly outperformed them.

#To realize that the robot's dexterous hand can continuously turn the pen, the operating program needs to have as many cycles as possible. This paper addresses this task by (1) instructing Eureka to generate a reward function used to redirect pens to random target configurations, and then (2) using Eureka rewards to fine-tune this pre-trained policy to achieve the desired pen sequence-rotation configuration. . As shown in the figure, the Eureka spinner quickly adapted to the strategy and successfully rotated for many cycles in succession. In contrast, neither pre-trained nor learned-from-scratch policies can complete a single epoch of rotation.
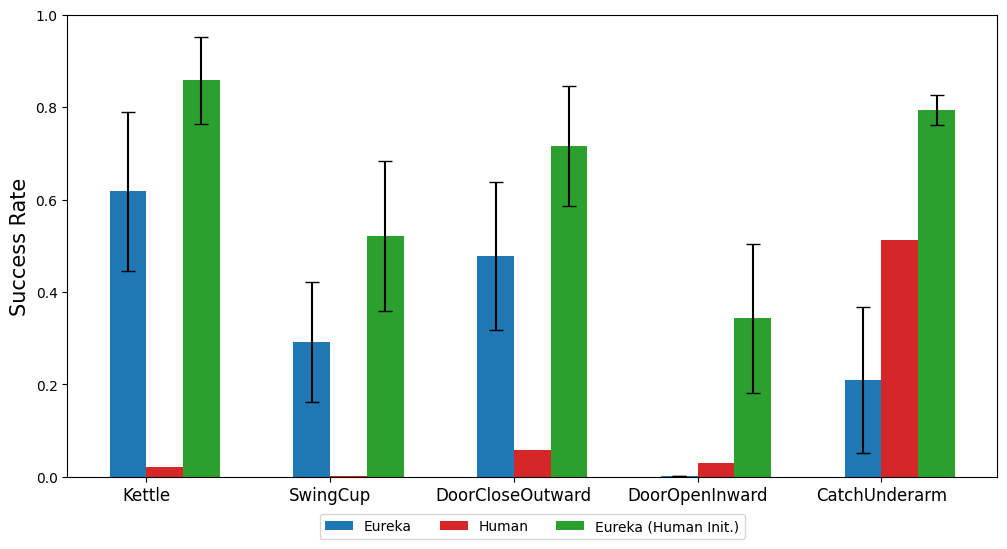
This paper also investigates whether it is advantageous for Eureka to start with a human reward function initialization. As shown, Eureka improves and benefits from human rewards regardless of their quality.

Eureka also implements RLHF, which can combine human feedback to modify rewards, thereby gradually guiding the agent to complete safer and more human-friendly tasks. Behavior. The example shows how Eureka teaches a humanoid robot to run upright with some human feedback that replaces the previous automatic reward reflection.

Humanoid robot learns running gait through Eureka.
For more information, please refer to the original paper.
The above is the detailed content of With GPT-4, the robot has learned how to spin a pen and plate walnuts.. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 How to check CentOS HDFS configuration
Apr 14, 2025 pm 07:21 PM
How to check CentOS HDFS configuration
Apr 14, 2025 pm 07:21 PM
Complete Guide to Checking HDFS Configuration in CentOS Systems This article will guide you how to effectively check the configuration and running status of HDFS on CentOS systems. The following steps will help you fully understand the setup and operation of HDFS. Verify Hadoop environment variable: First, make sure the Hadoop environment variable is set correctly. In the terminal, execute the following command to verify that Hadoop is installed and configured correctly: hadoopversion Check HDFS configuration file: The core configuration file of HDFS is located in the /etc/hadoop/conf/ directory, where core-site.xml and hdfs-site.xml are crucial. use
 Centos shutdown command line
Apr 14, 2025 pm 09:12 PM
Centos shutdown command line
Apr 14, 2025 pm 09:12 PM
The CentOS shutdown command is shutdown, and the syntax is shutdown [Options] Time [Information]. Options include: -h Stop the system immediately; -P Turn off the power after shutdown; -r restart; -t Waiting time. Times can be specified as immediate (now), minutes ( minutes), or a specific time (hh:mm). Added information can be displayed in system messages.
 What are the backup methods for GitLab on CentOS
Apr 14, 2025 pm 05:33 PM
What are the backup methods for GitLab on CentOS
Apr 14, 2025 pm 05:33 PM
Backup and Recovery Policy of GitLab under CentOS System In order to ensure data security and recoverability, GitLab on CentOS provides a variety of backup methods. This article will introduce several common backup methods, configuration parameters and recovery processes in detail to help you establish a complete GitLab backup and recovery strategy. 1. Manual backup Use the gitlab-rakegitlab:backup:create command to execute manual backup. This command backs up key information such as GitLab repository, database, users, user groups, keys, and permissions. The default backup file is stored in the /var/opt/gitlab/backups directory. You can modify /etc/gitlab
 Centos install mysql
Apr 14, 2025 pm 08:09 PM
Centos install mysql
Apr 14, 2025 pm 08:09 PM
Installing MySQL on CentOS involves the following steps: Adding the appropriate MySQL yum source. Execute the yum install mysql-server command to install the MySQL server. Use the mysql_secure_installation command to make security settings, such as setting the root user password. Customize the MySQL configuration file as needed. Tune MySQL parameters and optimize databases for performance.
 How to operate distributed training of PyTorch on CentOS
Apr 14, 2025 pm 06:36 PM
How to operate distributed training of PyTorch on CentOS
Apr 14, 2025 pm 06:36 PM
PyTorch distributed training on CentOS system requires the following steps: PyTorch installation: The premise is that Python and pip are installed in CentOS system. Depending on your CUDA version, get the appropriate installation command from the PyTorch official website. For CPU-only training, you can use the following command: pipinstalltorchtorchvisiontorchaudio If you need GPU support, make sure that the corresponding version of CUDA and cuDNN are installed and use the corresponding PyTorch version for installation. Distributed environment configuration: Distributed training usually requires multiple machines or single-machine multiple GPUs. Place
 Detailed explanation of docker principle
Apr 14, 2025 pm 11:57 PM
Detailed explanation of docker principle
Apr 14, 2025 pm 11:57 PM
Docker uses Linux kernel features to provide an efficient and isolated application running environment. Its working principle is as follows: 1. The mirror is used as a read-only template, which contains everything you need to run the application; 2. The Union File System (UnionFS) stacks multiple file systems, only storing the differences, saving space and speeding up; 3. The daemon manages the mirrors and containers, and the client uses them for interaction; 4. Namespaces and cgroups implement container isolation and resource limitations; 5. Multiple network modes support container interconnection. Only by understanding these core concepts can you better utilize Docker.
 How to view GitLab logs under CentOS
Apr 14, 2025 pm 06:18 PM
How to view GitLab logs under CentOS
Apr 14, 2025 pm 06:18 PM
A complete guide to viewing GitLab logs under CentOS system This article will guide you how to view various GitLab logs in CentOS system, including main logs, exception logs, and other related logs. Please note that the log file path may vary depending on the GitLab version and installation method. If the following path does not exist, please check the GitLab installation directory and configuration files. 1. View the main GitLab log Use the following command to view the main log file of the GitLabRails application: Command: sudocat/var/log/gitlab/gitlab-rails/production.log This command will display product
 How is the GPU support for PyTorch on CentOS
Apr 14, 2025 pm 06:48 PM
How is the GPU support for PyTorch on CentOS
Apr 14, 2025 pm 06:48 PM
Enable PyTorch GPU acceleration on CentOS system requires the installation of CUDA, cuDNN and GPU versions of PyTorch. The following steps will guide you through the process: CUDA and cuDNN installation determine CUDA version compatibility: Use the nvidia-smi command to view the CUDA version supported by your NVIDIA graphics card. For example, your MX450 graphics card may support CUDA11.1 or higher. Download and install CUDAToolkit: Visit the official website of NVIDIACUDAToolkit and download and install the corresponding version according to the highest CUDA version supported by your graphics card. Install cuDNN library:
