
 Technology peripherals
AI
The first multi-view autonomous driving scene video generation world model | DrivingDiffusion: New ideas for BEV data and simulation
Technology peripherals
AI
The first multi-view autonomous driving scene video generation world model | DrivingDiffusion: New ideas for BEV data and simulation
The first multi-view autonomous driving scene video generation world model | DrivingDiffusion: New ideas for BEV data and simulation

Some personal thoughts of the author
In the field of autonomous driving, with the development of BEV-based sub-tasks/end-to-end solutions, high-quality multi-view training data and the corresponding simulation scene construction are increasingly important. In response to the pain points of current tasks, "high quality" can be decoupled into three aspects:
- Long tail scenarios in different dimensions: such as vehicles at close range in obstacle data As well as precise heading angles during car cutting, as well as scenes with different curvatures in lane line data or ramps/merges/merges that are difficult to collect. These often rely on large amounts of data collection and complex data mining strategies, which are costly.
- 3D True Value - High Consistency of Images: Current BEV data acquisition is often affected by errors in sensor installation/calibration, high-precision maps and the reconstruction algorithm itself. This makes it difficult for us to ensure that each set of [3D true values-image-sensor parameters] in the data is accurate and consistent.
- Time series data based on satisfying the above conditions: Multi-view images of consecutive frames and corresponding true values, which are necessary for current perception/prediction/decision-making/end-to-end and other tasks Indispensable.
For simulation, video generation that meets the above conditions can be generated directly through layout, which is undoubtedly the most direct way to construct multi-agent sensor input. DrivingDiffusion solves the above problems from a new perspective.
What is DrivingDiffusion?
- DrivingDiffusion is a diffusion model framework for automatic driving scene generation, which implements layout controlled multi-view image/video generation and SOTA is implemented respectively.
- DrivingDiffusion-Future, as a self-driving world model, has the ability to predict future scene videos based on single frame images and influence the motion planning of the main vehicle/other vehicles based on language prompts.
What is the effect of DrivingDiffusion generation?
Students in need can first take a look at the project homepage: https://drivingdiffusion.github.io(1) DrivingDiffusion
Layout-controlled multi-view image generation
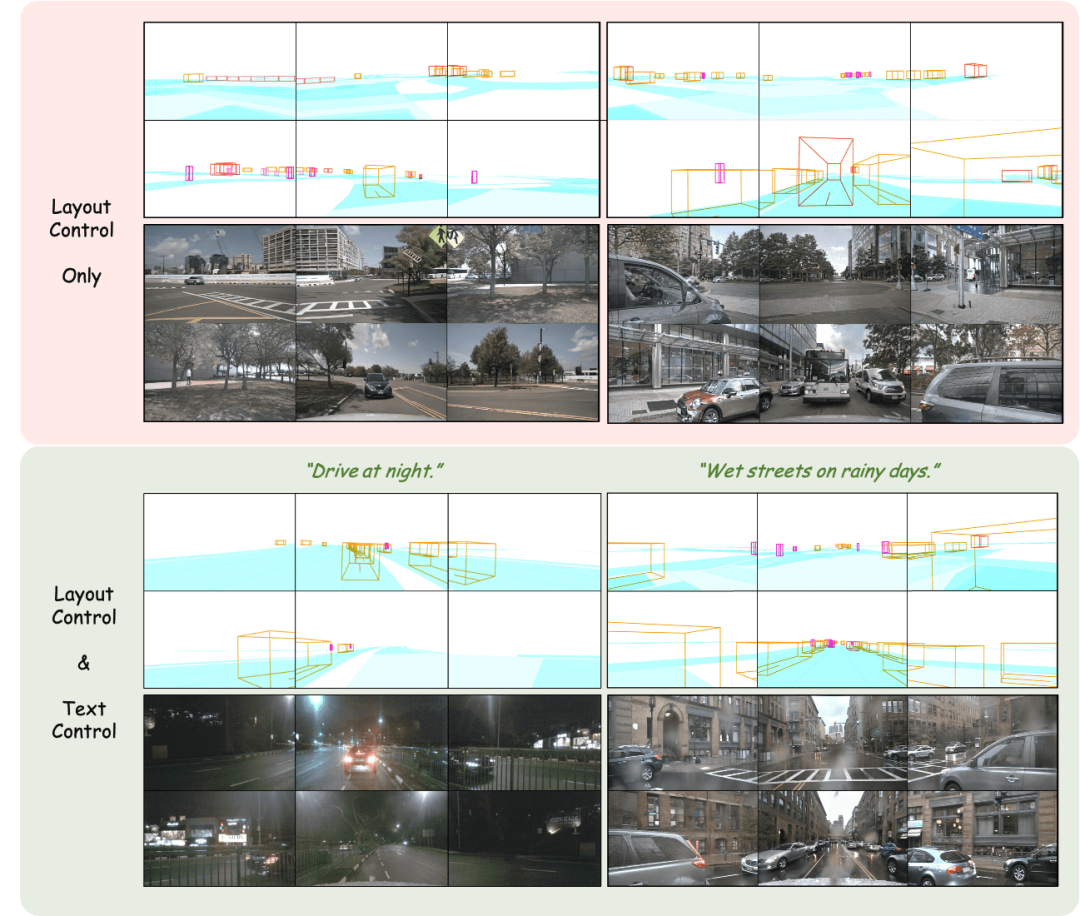
Adjust the layout: Precisely control the generated results

Layout controlled multi-view video generation
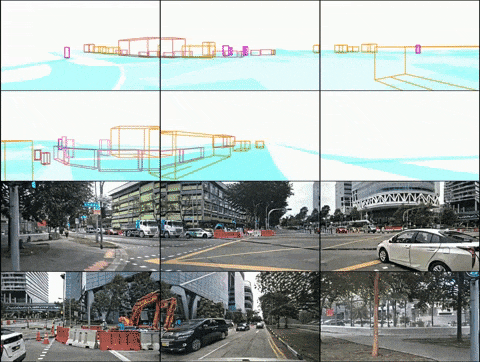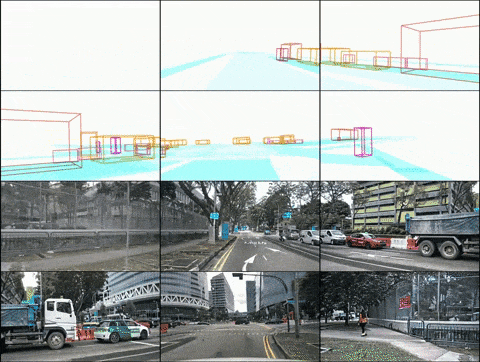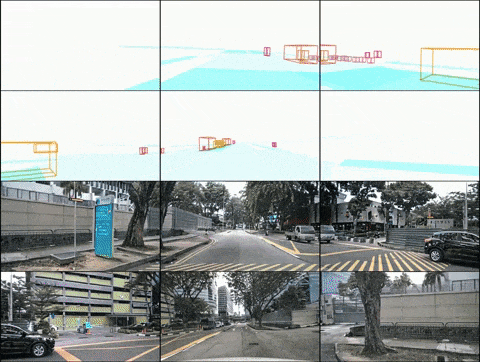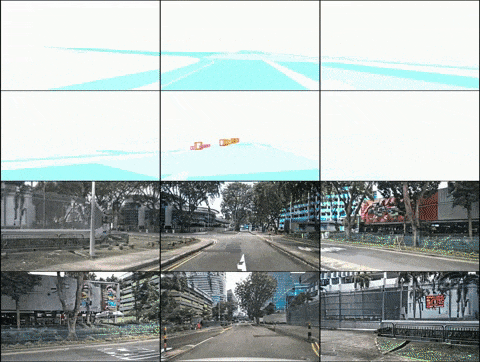

(2) DrivingDiffusion-Future
Generate subsequent frames based on the text description of the input frame

Generate subsequent frames directly based on the input frame

How does DrivingDiffusion solve the above problems?
DrivingDiffusion first artificially constructs all 3D true values (obstacles/road structures) in the scene. After projecting the true values into Layout images, this is used as model input to obtain the multi-camera perspective. Real images/videos. The reason why 3D true values (BEV views or encoded instances) are not used directly as model input, but parameters are used for post-projection input, is to eliminate systematic 3D-2D consistency errors. (In such a set of data, 3D true values and vehicle parameters are artificially constructed according to actual needs. The former brings the ability to construct rare scene data at will. , the latter eliminates the error of geometric consistency in traditional data production.)
There is still one question left at this time: whether the quality of the generated image/video can meet the usage requirements ? When it comes to constructing scenarios, everyone often thinks of using a simulation engine. However, there is a large domain gap between the data it generates and the real data. The generated results of GAN-based methods often have a certain bias from the distribution of actual real data. Diffusion Models are based on the characteristics of Markov chains that generate data by learning noise. The fidelity of the generated results is higher and is more suitable for use as a substitute for real data. DrivingDiffusion directly generatessequential multi-view views according to artificially constructed scenes and vehicle parameters, which can not only be used as a reference for downstream autonomous driving tasks Training data can also be used to build a simulation system for feedback on autonomous driving algorithms.
The "artificially constructed scene" here only contains obstacles and road structure information, but DrivingDiffusion's framework can easily introduce layout information such as signboards, traffic lights, construction areas, and even low-level occupation grid/depth map and other control modes.Overview of DrivingDiffusion method
There are several difficulties when generating multi-view videos:
- Relatively common For image generation, multi-view video generation adds two new dimensions:
- perspective and timing. How to design a framework that can generate long videos? How to maintain cross-view consistency and cross-frame consistency? From the perspective of autonomous driving tasks, instances in the scene are crucial. How to ensure the quality of generated instances?
DrivingDiffusion generates long video process
Single frame multi-view model: generate multi-view key frames,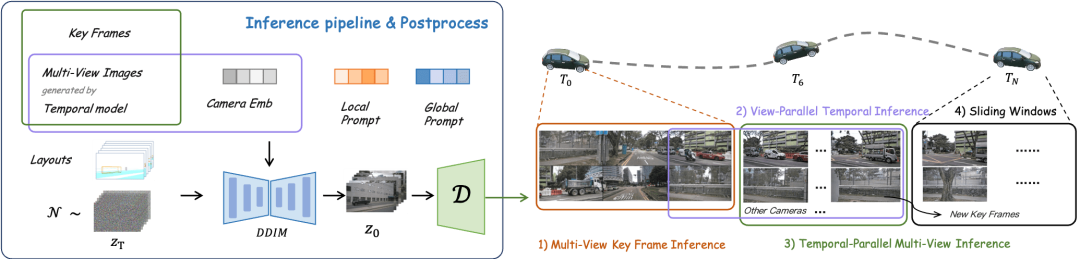 The single-view timing model with frames as additional control and multi-view sharing: perform timing expansion on each view in parallel,
The single-view timing model with frames as additional control and multi-view sharing: perform timing expansion on each view in parallel,
- A single-frame multi-view model with the generated results as additional control: fine-tune subsequent frames in parallel timing,
- Determine new keyframes and extend the video through a sliding window.
- Training framework for cross-view models and temporal models
- For multi-view models and sequential models, the extended dimensions of 3D-Unet are perspective and time respectively. Both have the same layout controller. The author believes that subsequent frames can obtain information in the scene from multi-view key frames and implicitly learn the associated information of different targets. Both use different consistency attention modules and the same Local Prompt module respectively.
- Layout encoding: Obstacle category/instance information and road structure segmentation layout are encoded into RGB images with different fixed encoding values, and the layout token is output after encoding.
- Key frame control: All timing expansion processes use the multi-view image of a certain key frame. This is based on the assumption that subsequent frames in a short timing sequence can obtain information from the key frame. All fine-tuning processes use the key frame and the multi-view image of a subsequent frame generated by it as additional controls, and output the multi-view image after optimizing the cross-view consistency of the frame.
- Optical flow prior based on a specific perspective: For the temporal model, only data from a certain perspective is sampled during training. In addition, the optical flow prior value of each pixel position under the perspective image that is calculated in advance is used, and is encoded as a camera ID token to perform interactive control of the hidden layer similar to time embedding in the diffusion process.
Consistency Module & Local Prompt
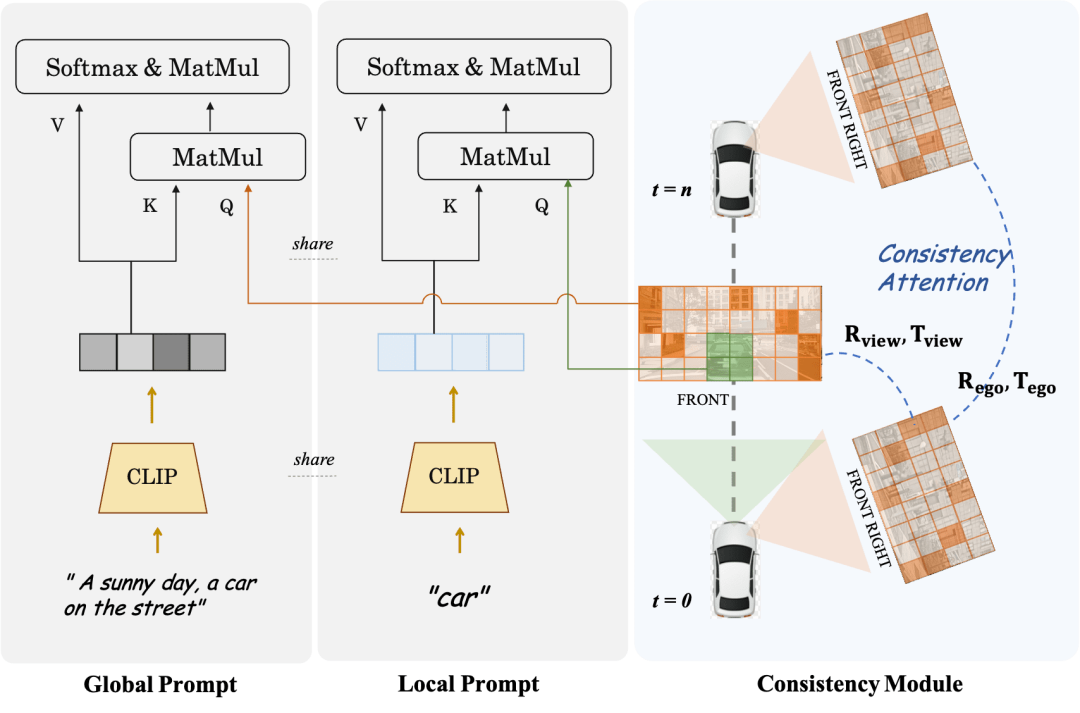
##Consistency Module is divided into two parts: Consistency attention mechanism and Consistency correlation loss.
The consistency attention mechanism focuses on the interaction between adjacent views and timing-related frames. Specifically, for cross-frame consistency, it only focuses on the information interaction between left and right adjacent views that overlap. For the timing model, each Frame only focuses on keyframes and the previous frame. This avoids the huge computational load caused by global interactions. The consistent correlation loss adds geometric constraints by pixel-level correlation and regression of pose, whose gradient is provided by a pre-trained pose regressor. The regressor adds a pose regression head based on LoFTR and is trained using the true pose values on the real data of the corresponding data set. For multi-view models and time series models, this module supervises the camera relative pose and main vehicle motion pose respectively.Local Prompt and Global Prompt cooperate to reuse the parameter semantics of CLIP and stable-diffusion-v1-4 to locally enhance specific category instance areas. As shown in the figure, based on the cross-attention mechanism of image tokens and global text description prompts, the author designs a local prompt for a certain category and uses the image token in the mask area of the category to query the local prompt. This process makes maximum use of the concept of text-guided image generation in the open domain in the original model parameters.
Overview of DrivingDiffusion-Future method
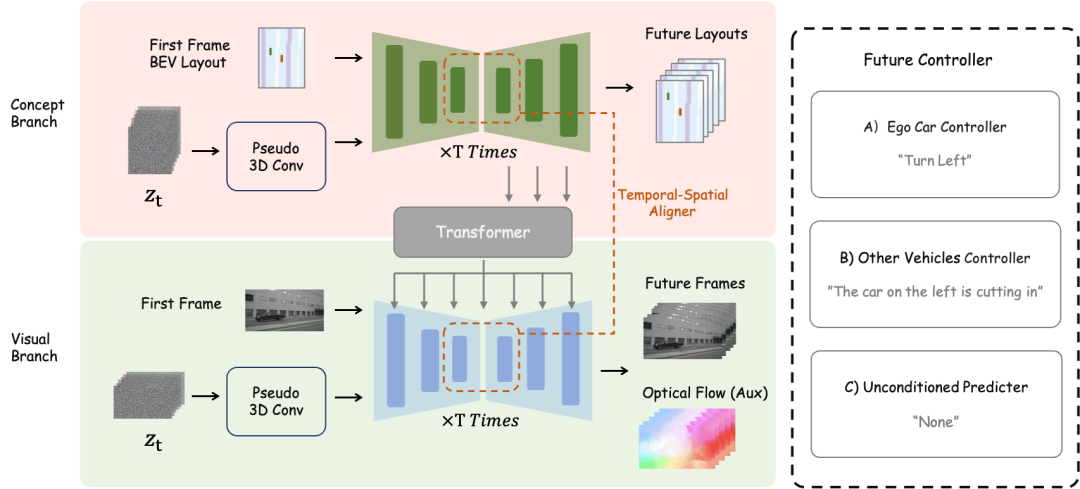
main vehicle control text description controller and other vehicle control/environment text description controller are decoupled.
Experimental Analysis
In order to evaluate the performance of the model, DrivingDiffusion uses frame-level Fréchet Inception Distance (FID) to evaluate the quality of the generated images, and accordingly uses FVD to evaluate the generated images. Video quality. All metrics are calculated on the nuScenes validation set. As shown in Table 1, compared with the image generation task BEVGen and the video generation task DriveDreamer in autonomous driving scenarios, DrivingDiffusion has greater advantages in performance indicators under different settings.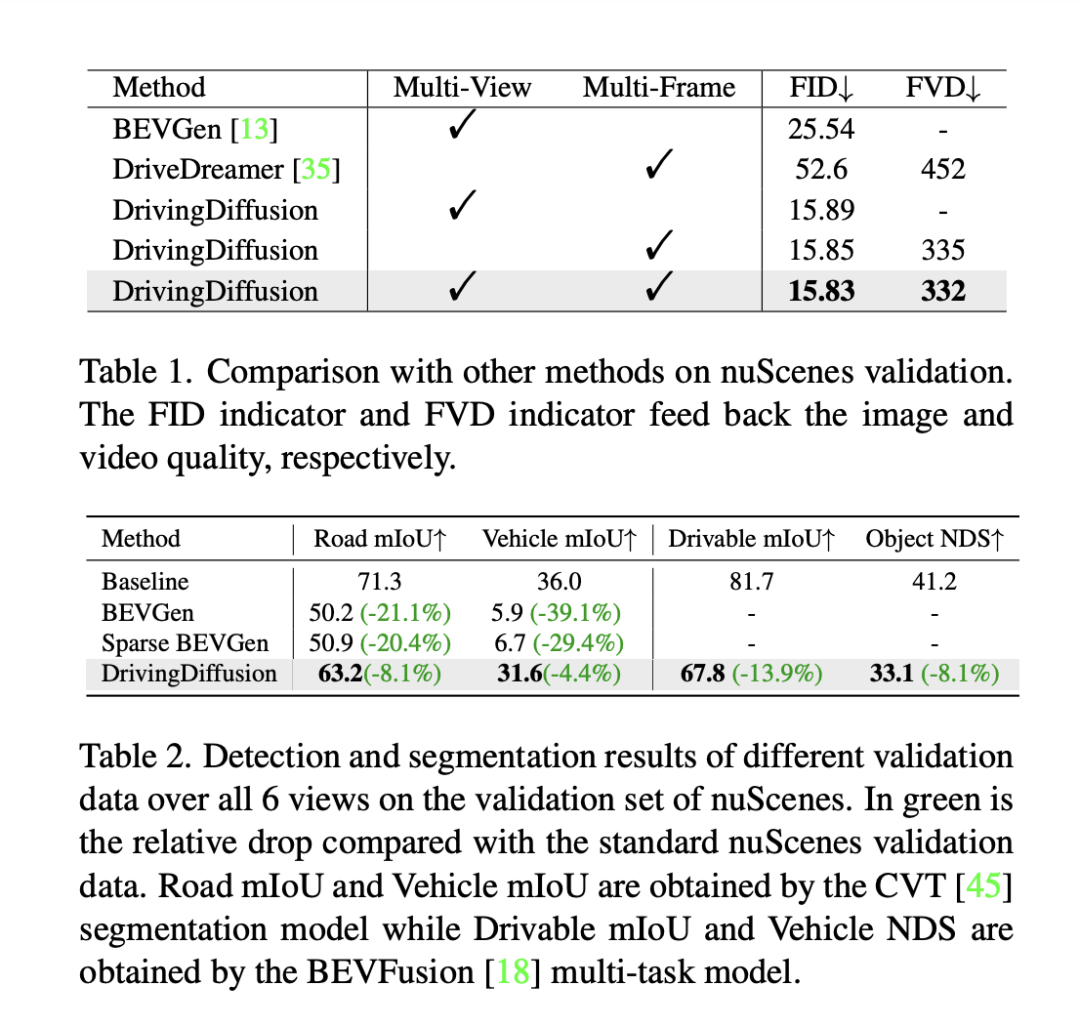
Although methods such as FID are often used to measure the quality of image synthesis, they do not fully feedback the design goals of the task, nor do they reflect the synthesis quality of different semantic categories. Since the task is dedicated to generating multi-view images consistent with 3D layouts, DrivingDiffuison proposes to use the BEV perceptual model metric to measure performance in terms of consistency: using the official models of CVT and BEVFusion as evaluators, using the same real 3D model as the nuScenes validation set Generate images conditionally on the layout, perform CVT and BevFusion inference on each set of generated images, and then compare the predicted results with the real results, including the average intersection over U (mIoU) score of the drivable area and the NDS of all object classes. The statistics are shown in Table 2. Experimental results show that the perception indicators of the synthetic data evaluation set are very close to those of the real evaluation set, which reflects the high consistency of the generated results and 3D true values and the high fidelity of the image quality.
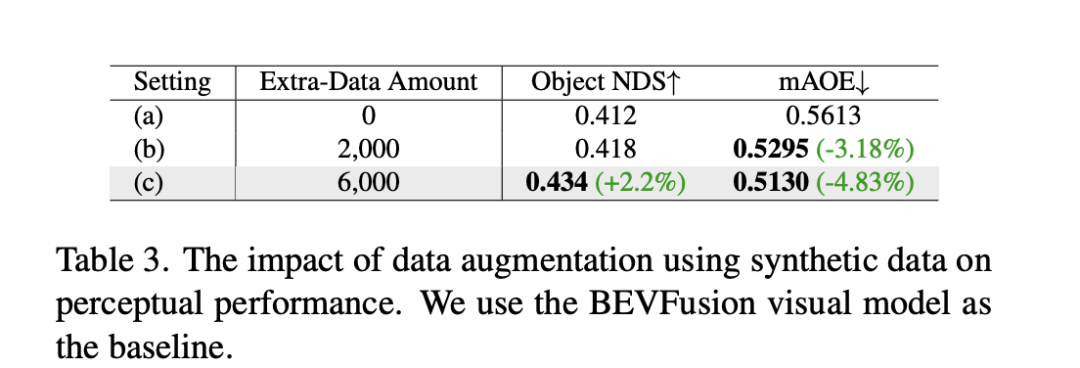
In addition to the above experiments, DrivingDiffusion has conducted experiments on adding synthetic data training to address the main problem it solves - improving the performance of autonomous driving downstream tasks. Table 3 demonstrates the performance improvements achieved by synthetic data augmentation in BEV perception tasks. In the original training data, there are problems with long-tail distributions, especially for small targets, close-range vehicles, and vehicle orientation angles. DrivingDiffusion focuses on generating additional data for these classes with limited samples to solve this problem. After adding 2000 frames of data focused on improving the distribution of obstacle orientation angles, NDS improved slightly, while mAOE dropped significantly from 0.5613 to 0.5295. After using 6000 frames of synthetic data that is more comprehensive and focused on rare scenes to assist training, a significant enhancement can be observed on the nuScenes validation set: NDS increased from 0.412 to 0.434, and mAOE decreased from 0.5613 to 0.5130. This demonstrates the significant improvement that data augmentation of synthetic data can bring to perception tasks. Users can make statistics on the distribution of each dimension in the data based on actual needs, and then supplement it with targeted synthetic data.
The significance and future work of DrivingDiffusion
DrivingDiffusion simultaneously realizes the ability to generate multi-view videos of autonomous driving scenes and predict the future, which is of great significance to autonomous driving tasks. Among them, layout and parameters are all artificially constructed and the conversion between 3D-2D is through projection rather than relying on learnable model parameters, which eliminates geometric errors in the previous process of obtaining data. , has strong practical value. At the same time, DrivingDiffuison is extremely scalable and supports new scene content layouts and additional controllers. It can also losslessly improve the generation quality through super-resolution and video frame insertion technology.
In autonomous driving simulation, there are more and more attempts at Nerf. However, in the task of street view generation, the separation of dynamic and static content, large-scale block reconstruction, decoupling appearance control of weather and other dimensions, etc., bring a huge amount of work. In addition, Nerf often needs to be carried out in a specific range of scenes. Only after training can it support new perspective synthesis tasks in subsequent simulations. DrivingDiffusion naturally contains a certain amount of general knowledge prior, including visual-text connections, conceptual understanding of visual content, etc. It can quickly create a scene according to needs just by constructing the layout. However, as mentioned above, the entire process is relatively complex, and the generation of long videos requires post-processing model fine-tuning and expansion. DrivingDiffusion will continue to explore the compression of perspective dimensions and time dimensions, as well as combine Nerf for new perspective generation and conversion, and continue to improve generation quality and scalability.
The above is the detailed content of The first multi-view autonomous driving scene video generation world model | DrivingDiffusion: New ideas for BEV data and simulation. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1377
1377
 52
52

 Why is Gaussian Splatting so popular in autonomous driving that NeRF is starting to be abandoned?
Jan 17, 2024 pm 02:57 PM
Why is Gaussian Splatting so popular in autonomous driving that NeRF is starting to be abandoned?
Jan 17, 2024 pm 02:57 PM
Written above & the author’s personal understanding Three-dimensional Gaussiansplatting (3DGS) is a transformative technology that has emerged in the fields of explicit radiation fields and computer graphics in recent years. This innovative method is characterized by the use of millions of 3D Gaussians, which is very different from the neural radiation field (NeRF) method, which mainly uses an implicit coordinate-based model to map spatial coordinates to pixel values. With its explicit scene representation and differentiable rendering algorithms, 3DGS not only guarantees real-time rendering capabilities, but also introduces an unprecedented level of control and scene editing. This positions 3DGS as a potential game-changer for next-generation 3D reconstruction and representation. To this end, we provide a systematic overview of the latest developments and concerns in the field of 3DGS for the first time.
 How to solve the long tail problem in autonomous driving scenarios?
Jun 02, 2024 pm 02:44 PM
How to solve the long tail problem in autonomous driving scenarios?
Jun 02, 2024 pm 02:44 PM
Yesterday during the interview, I was asked whether I had done any long-tail related questions, so I thought I would give a brief summary. The long-tail problem of autonomous driving refers to edge cases in autonomous vehicles, that is, possible scenarios with a low probability of occurrence. The perceived long-tail problem is one of the main reasons currently limiting the operational design domain of single-vehicle intelligent autonomous vehicles. The underlying architecture and most technical issues of autonomous driving have been solved, and the remaining 5% of long-tail problems have gradually become the key to restricting the development of autonomous driving. These problems include a variety of fragmented scenarios, extreme situations, and unpredictable human behavior. The "long tail" of edge scenarios in autonomous driving refers to edge cases in autonomous vehicles (AVs). Edge cases are possible scenarios with a low probability of occurrence. these rare events
 Choose camera or lidar? A recent review on achieving robust 3D object detection
Jan 26, 2024 am 11:18 AM
Choose camera or lidar? A recent review on achieving robust 3D object detection
Jan 26, 2024 am 11:18 AM
0.Written in front&& Personal understanding that autonomous driving systems rely on advanced perception, decision-making and control technologies, by using various sensors (such as cameras, lidar, radar, etc.) to perceive the surrounding environment, and using algorithms and models for real-time analysis and decision-making. This enables vehicles to recognize road signs, detect and track other vehicles, predict pedestrian behavior, etc., thereby safely operating and adapting to complex traffic environments. This technology is currently attracting widespread attention and is considered an important development area in the future of transportation. one. But what makes autonomous driving difficult is figuring out how to make the car understand what's going on around it. This requires that the three-dimensional object detection algorithm in the autonomous driving system can accurately perceive and describe objects in the surrounding environment, including their locations,
 The Stable Diffusion 3 paper is finally released, and the architectural details are revealed. Will it help to reproduce Sora?
Mar 06, 2024 pm 05:34 PM
The Stable Diffusion 3 paper is finally released, and the architectural details are revealed. Will it help to reproduce Sora?
Mar 06, 2024 pm 05:34 PM
StableDiffusion3’s paper is finally here! This model was released two weeks ago and uses the same DiT (DiffusionTransformer) architecture as Sora. It caused quite a stir once it was released. Compared with the previous version, the quality of the images generated by StableDiffusion3 has been significantly improved. It now supports multi-theme prompts, and the text writing effect has also been improved, and garbled characters no longer appear. StabilityAI pointed out that StableDiffusion3 is a series of models with parameter sizes ranging from 800M to 8B. This parameter range means that the model can be run directly on many portable devices, significantly reducing the use of AI
 This article is enough for you to read about autonomous driving and trajectory prediction!
Feb 28, 2024 pm 07:20 PM
This article is enough for you to read about autonomous driving and trajectory prediction!
Feb 28, 2024 pm 07:20 PM
Trajectory prediction plays an important role in autonomous driving. Autonomous driving trajectory prediction refers to predicting the future driving trajectory of the vehicle by analyzing various data during the vehicle's driving process. As the core module of autonomous driving, the quality of trajectory prediction is crucial to downstream planning control. The trajectory prediction task has a rich technology stack and requires familiarity with autonomous driving dynamic/static perception, high-precision maps, lane lines, neural network architecture (CNN&GNN&Transformer) skills, etc. It is very difficult to get started! Many fans hope to get started with trajectory prediction as soon as possible and avoid pitfalls. Today I will take stock of some common problems and introductory learning methods for trajectory prediction! Introductory related knowledge 1. Are the preview papers in order? A: Look at the survey first, p
 SIMPL: A simple and efficient multi-agent motion prediction benchmark for autonomous driving
Feb 20, 2024 am 11:48 AM
SIMPL: A simple and efficient multi-agent motion prediction benchmark for autonomous driving
Feb 20, 2024 am 11:48 AM
Original title: SIMPL: ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving Paper link: https://arxiv.org/pdf/2402.02519.pdf Code link: https://github.com/HKUST-Aerial-Robotics/SIMPL Author unit: Hong Kong University of Science and Technology DJI Paper idea: This paper proposes a simple and efficient motion prediction baseline (SIMPL) for autonomous vehicles. Compared with traditional agent-cent
 nuScenes' latest SOTA | SparseAD: Sparse query helps efficient end-to-end autonomous driving!
Apr 17, 2024 pm 06:22 PM
nuScenes' latest SOTA | SparseAD: Sparse query helps efficient end-to-end autonomous driving!
Apr 17, 2024 pm 06:22 PM
Written in front & starting point The end-to-end paradigm uses a unified framework to achieve multi-tasking in autonomous driving systems. Despite the simplicity and clarity of this paradigm, the performance of end-to-end autonomous driving methods on subtasks still lags far behind single-task methods. At the same time, the dense bird's-eye view (BEV) features widely used in previous end-to-end methods make it difficult to scale to more modalities or tasks. A sparse search-centric end-to-end autonomous driving paradigm (SparseAD) is proposed here, in which sparse search fully represents the entire driving scenario, including space, time, and tasks, without any dense BEV representation. Specifically, a unified sparse architecture is designed for task awareness including detection, tracking, and online mapping. In addition, heavy
 Let's talk about end-to-end and next-generation autonomous driving systems, as well as some misunderstandings about end-to-end autonomous driving?
Apr 15, 2024 pm 04:13 PM
Let's talk about end-to-end and next-generation autonomous driving systems, as well as some misunderstandings about end-to-end autonomous driving?
Apr 15, 2024 pm 04:13 PM
In the past month, due to some well-known reasons, I have had very intensive exchanges with various teachers and classmates in the industry. An inevitable topic in the exchange is naturally end-to-end and the popular Tesla FSDV12. I would like to take this opportunity to sort out some of my thoughts and opinions at this moment for your reference and discussion. How to define an end-to-end autonomous driving system, and what problems should be expected to be solved end-to-end? According to the most traditional definition, an end-to-end system refers to a system that inputs raw information from sensors and directly outputs variables of concern to the task. For example, in image recognition, CNN can be called end-to-end compared to the traditional feature extractor + classifier method. In autonomous driving tasks, input data from various sensors (camera/LiDAR
