
 Technology peripherals
AI
In deep learning scientific research, how to efficiently manage code and experiments?
Technology peripherals
AI
In deep learning scientific research, how to efficiently manage code and experiments?
In deep learning scientific research, how to efficiently manage code and experiments?

Answer 1
Author: Ye Xiaofei
Link: https://www.zhihu.com/question/269707221/answer/2281374258
I used to When Mercedes-Benz was launched in North America, there was a period of time in order to test different structures and parameters. We could train more than a hundred different models in a week. To this end, I combined the practices of the company’s seniors and my own thoughts and summary I developed a set of efficient code experiment management methods and successfully helped the project to be implemented. Now I am sharing it with you here.
Use Yaml files to configure training parameters
I know that many open source repos like to use input argparse to transmit a lot of training and model-related parameters, which is actually very inefficient. On the one hand, it will be troublesome to manually enter a large number of parameters every time you train. If you directly change the default values and then go to the code to change them, it will waste a lot of time. Here I recommend that you directly use a Yaml file to control all model and training-related parameters, and link the naming of the Yaml with the model name and timestamp , as is the case with the famous 3D point cloud detection library OpenPCDet Made as shown in this link below.
github.com/open-mmlab/OpenPCDet/blob/master/tools/cfgs/kitti_models/pointrcnn.yaml
I cut off part of the yaml file from the link given above, as follows As shown in the figure, this configuration file covers how to preprocess point clouds, the types of classification, as well as various parameters of the backbone, the selection of optimizer and loss (not shown in the figure, please see the link above for complete information). In other words, Basically all the factors that can affect your model are included in this file, and in the code, you only need to use a simple yaml.load() to put these All parameters are read into a dict. More importantly, this configuration file can be saved to the same folder as your checkpoint, so that you can use it directly for breakpoint training, finetune or direct testing. You can also use it for testing. It is very convenient to match the results with the corresponding parameters.

Code modularization is very important
Some researchers like to over-couple the entire system when writing code, such as loss function and model When written together, this will often lead to an impact on the whole body. If you change a small piece, the entire subsequent interface will also change. Therefore, if the code is well modularized, it can save you a lot of time. General deep learning code can basically be divided into several large blocks (taking pytorch as an example): I/O module, preprocessing module, visualization module, model body (if a large model contains sub-models, a new class should be added), loss functions, post-processing, and concatenated in a training or test script. Another benefit of code modularization is that it facilitates you to define different parameters in yaml for easy reading. In addition, the importlib library is used in many mature codes. It allows you not to determine which model or sub-model to use during training in the code, but can be directly defined in yaml.
How to use Tensorboard and tqdm
I basically use these two libraries every time. Tensorboard can track the changes in the loss curve of your training very well, making it easier for you to judge whether the model is still converging and overfitting. If you are doing image related work, you can also put some visualization results on it. Many times, you only need to look at the convergence status of tensorboard to basically know how your model is doing. Is it necessary to spend time testing and finetune separately? Tqdm can help you track your training progress intuitively, making it easier for you to make early stops. .
Make full use of Github
Whether you are working on a collaborative development with multiple people or a solo project, I strongly recommend using Github (the company may use bitbucket, more or less) to record your code. For details, please refer to my answer:
As a graduate student, what scientific research tools do you think are useful?
https://www.zhihu.com/question/484596211/answer/2163122684
Record the experimental results
I usually save a general excel to record the experimental results, first The column is the yaml path corresponding to the model, the second column is the model training epoches, and the third column is the log of the test results. I usually automate this process. As long as the total excel path is given in the test script, it can be easily done using pandas. Get it done.
Answer 2
Author: Jason
Link: https://www.zhihu.com/question/269707221/answer/470576066
git management code has nothing to do with deep learning or scientific research. You must use version management tools when writing code. I personally feel that it is a matter of choice whether to use GitHub or not. After all, it is impossible for all the code in the company to be linked to external Git.
Let’s talk about a few things you need to pay attention to when writing code:
1. Try to use the config file to pass in the test parameters, and try to save the config with the same name as the log file.
On the one hand, passing in external parameters can avoid too many version modifications on git due to parameters. Since DL is not easy to debug, sometimes it is inevitable to use git to do code comparison;
On the other hand, after testing thousands of versions, I believe you will not know which model has which parameters. Good habits are very effective. In addition, try to provide default values for newly added parameters to facilitate calling the old version of the config file.
2. Try to decouple different models
In the same project, good reusability is a very good programming habit, but in the rapidly developing DL coding , assuming that the project is task-driven, this may sometimes become a hindrance, so try to extract some reusable functions, and try to decouple different models into different files related to the model structure, but it will It will be more convenient for future updates. Otherwise, some seemingly beautiful designs will become useless after a few months.
3. While satisfying a certain degree of stability, regularly follow up on new versions of the framework
There is often an embarrassing situation. From the beginning to the end of a project, the framework has been updated several versions, and the new version There are some coveted features, but unfortunately some APIs have changed. Therefore, you can try to keep the framework version stable within the project. Try to consider the pros and cons of different versions before starting the project. Sometimes proper learning is necessary.
In addition, have a tolerant heart towards different frameworks.
4. A training session takes a long time. Don’t blindly start running experiments after coding. Personal experience provides debug mode to experiment with small data. More logs are a good choice.
5. Record the changes in model update performance, because you may need to go back and start again at any time.
Author: OpenMMLab
Link: https://www.zhihu.com/question/269707221/answer/2480772257
Source: Zhihu
Copyright belongs to the author. For commercial reprinting, please contact the author for authorization. For non-commercial reprinting, please indicate the source.
Hello, the questioner, the previous answer mentioned the use of Tensorboard, Weights&Biases, MLFlow, Neptune and other tools to manage experimental data. However, as more and more wheels are built for experimental management tools, the cost of learning the tools is getting higher and higher. How should we choose?
MMCV can satisfy all your fantasies, and you can switch tools by modifying the configuration file.
github.com/open-mmlab/mmcv
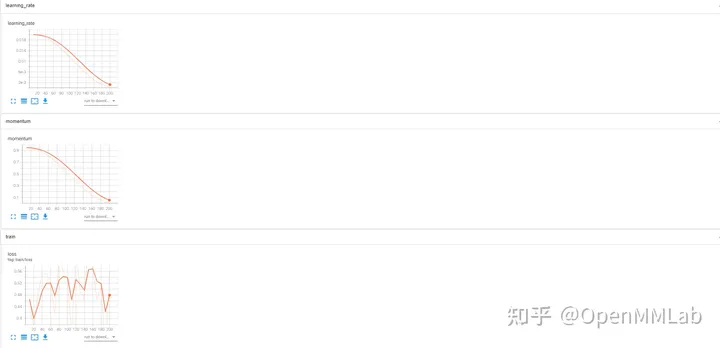
Tensorboard records experimental data:
Configuration file:
log_config = dict( interval=1, hooks=[ dict(type='TextLoggerHook'), dict(type='TensorboardLoggerHook') ])
TensorBoard data Visualization effect
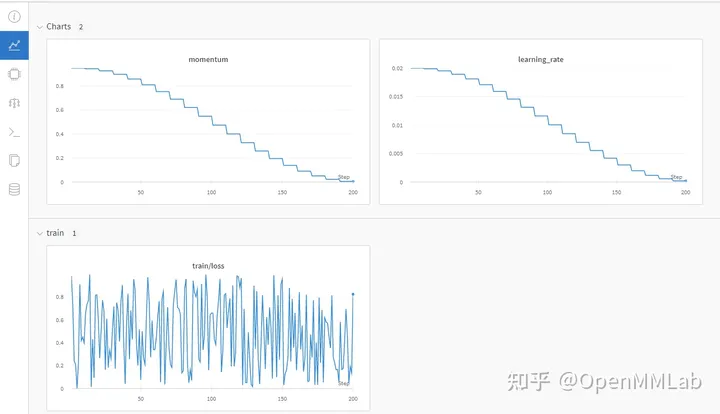
WandB recording experimental data
Configuration file
log_config = dict( interval=1, hooks=[ dict(type='TextLoggerHook'), dict(type='WandbLoggerHook') ])
Wandb data visualization effect
(You need to log in to wandb with python api in advance)
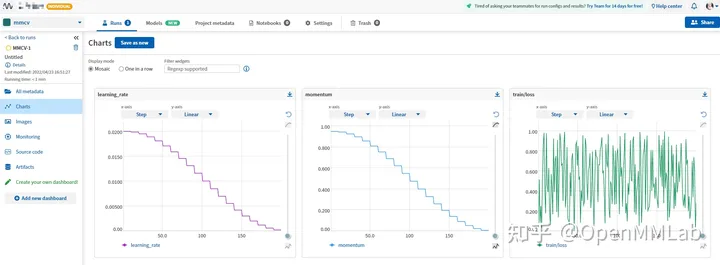
Neptume records experimental data
Configuration file
log_config = dict( interval=1, hooks=[ dict(type='TextLoggerHook'), dict(type='NeptuneLoggerHook', init_kwargs=dict(project='Your Neptume account/mmcv')) ])
Neptume Visualization
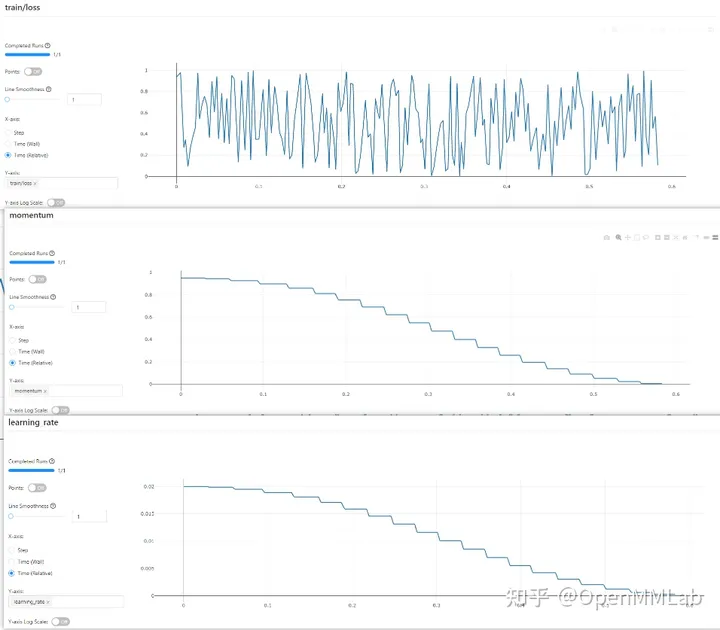
mlflow records experimental data
Configuration file
log_config = dict( interval=1, hooks=[ dict(type='TextLoggerHook'), dict(type='MlflowLoggerHook') ])
MLFlow Visualization
dvclive records experimental data
Configuration file
log_config = dict( interval=1, hooks=[ dict(type='TextLoggerHook'), dict(type='DvcliveLoggerHook') ])
Generated html file
The above only uses the most basic functions of various experimental management tools. We can further modify the configuration file to unlock more postures.
Having MMCV is equivalent to having all the experimental management tools. If you were a tf boy before, you can choose the classic nostalgic style of TensorBoard; if you want to record all experimental data and experimental environment, you might as well try Wandb (Weights & Biases) or Neptume; if your device cannot be connected to the Internet, you can choose mlflow to Experimental data is saved locally, and there is always a tool suitable for you.
In addition, MMCV also has its own log management system, that is TextLoggerHook ! It will save all the information generated during the training process, such as device environment, data set, model initialization method, loss, metric and other information generated during training, to the local xxx.log file. You can review previous experimental data without using any tools.
Still wondering which experiment management tool to use? Still worried about the learning cost of various tools? Hurry up and get on board MMCV, and experience various tools painlessly with just a few lines of configuration files.
github.com/open-mmlab/mmcv
The above is the detailed content of In deep learning scientific research, how to efficiently manage code and experiments?. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1387
1387
 52
52

 How to solve the long tail problem in autonomous driving scenarios?
Jun 02, 2024 pm 02:44 PM
How to solve the long tail problem in autonomous driving scenarios?
Jun 02, 2024 pm 02:44 PM
Yesterday during the interview, I was asked whether I had done any long-tail related questions, so I thought I would give a brief summary. The long-tail problem of autonomous driving refers to edge cases in autonomous vehicles, that is, possible scenarios with a low probability of occurrence. The perceived long-tail problem is one of the main reasons currently limiting the operational design domain of single-vehicle intelligent autonomous vehicles. The underlying architecture and most technical issues of autonomous driving have been solved, and the remaining 5% of long-tail problems have gradually become the key to restricting the development of autonomous driving. These problems include a variety of fragmented scenarios, extreme situations, and unpredictable human behavior. The "long tail" of edge scenarios in autonomous driving refers to edge cases in autonomous vehicles (AVs). Edge cases are possible scenarios with a low probability of occurrence. these rare events
 Beyond ORB-SLAM3! SL-SLAM: Low light, severe jitter and weak texture scenes are all handled
May 30, 2024 am 09:35 AM
Beyond ORB-SLAM3! SL-SLAM: Low light, severe jitter and weak texture scenes are all handled
May 30, 2024 am 09:35 AM
Written previously, today we discuss how deep learning technology can improve the performance of vision-based SLAM (simultaneous localization and mapping) in complex environments. By combining deep feature extraction and depth matching methods, here we introduce a versatile hybrid visual SLAM system designed to improve adaptation in challenging scenarios such as low-light conditions, dynamic lighting, weakly textured areas, and severe jitter. sex. Our system supports multiple modes, including extended monocular, stereo, monocular-inertial, and stereo-inertial configurations. In addition, it also analyzes how to combine visual SLAM with deep learning methods to inspire other research. Through extensive experiments on public datasets and self-sampled data, we demonstrate the superiority of SL-SLAM in terms of positioning accuracy and tracking robustness.
 Choose camera or lidar? A recent review on achieving robust 3D object detection
Jan 26, 2024 am 11:18 AM
Choose camera or lidar? A recent review on achieving robust 3D object detection
Jan 26, 2024 am 11:18 AM
0.Written in front&& Personal understanding that autonomous driving systems rely on advanced perception, decision-making and control technologies, by using various sensors (such as cameras, lidar, radar, etc.) to perceive the surrounding environment, and using algorithms and models for real-time analysis and decision-making. This enables vehicles to recognize road signs, detect and track other vehicles, predict pedestrian behavior, etc., thereby safely operating and adapting to complex traffic environments. This technology is currently attracting widespread attention and is considered an important development area in the future of transportation. one. But what makes autonomous driving difficult is figuring out how to make the car understand what's going on around it. This requires that the three-dimensional object detection algorithm in the autonomous driving system can accurately perceive and describe objects in the surrounding environment, including their locations,
 This article is enough for you to read about autonomous driving and trajectory prediction!
Feb 28, 2024 pm 07:20 PM
This article is enough for you to read about autonomous driving and trajectory prediction!
Feb 28, 2024 pm 07:20 PM
Trajectory prediction plays an important role in autonomous driving. Autonomous driving trajectory prediction refers to predicting the future driving trajectory of the vehicle by analyzing various data during the vehicle's driving process. As the core module of autonomous driving, the quality of trajectory prediction is crucial to downstream planning control. The trajectory prediction task has a rich technology stack and requires familiarity with autonomous driving dynamic/static perception, high-precision maps, lane lines, neural network architecture (CNN&GNN&Transformer) skills, etc. It is very difficult to get started! Many fans hope to get started with trajectory prediction as soon as possible and avoid pitfalls. Today I will take stock of some common problems and introductory learning methods for trajectory prediction! Introductory related knowledge 1. Are the preview papers in order? A: Look at the survey first, p
 Let's talk about end-to-end and next-generation autonomous driving systems, as well as some misunderstandings about end-to-end autonomous driving?
Apr 15, 2024 pm 04:13 PM
Let's talk about end-to-end and next-generation autonomous driving systems, as well as some misunderstandings about end-to-end autonomous driving?
Apr 15, 2024 pm 04:13 PM
In the past month, due to some well-known reasons, I have had very intensive exchanges with various teachers and classmates in the industry. An inevitable topic in the exchange is naturally end-to-end and the popular Tesla FSDV12. I would like to take this opportunity to sort out some of my thoughts and opinions at this moment for your reference and discussion. How to define an end-to-end autonomous driving system, and what problems should be expected to be solved end-to-end? According to the most traditional definition, an end-to-end system refers to a system that inputs raw information from sensors and directly outputs variables of concern to the task. For example, in image recognition, CNN can be called end-to-end compared to the traditional feature extractor + classifier method. In autonomous driving tasks, input data from various sensors (camera/LiDAR
 SIMPL: A simple and efficient multi-agent motion prediction benchmark for autonomous driving
Feb 20, 2024 am 11:48 AM
SIMPL: A simple and efficient multi-agent motion prediction benchmark for autonomous driving
Feb 20, 2024 am 11:48 AM
Original title: SIMPL: ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving Paper link: https://arxiv.org/pdf/2402.02519.pdf Code link: https://github.com/HKUST-Aerial-Robotics/SIMPL Author unit: Hong Kong University of Science and Technology DJI Paper idea: This paper proposes a simple and efficient motion prediction baseline (SIMPL) for autonomous vehicles. Compared with traditional agent-cent
 FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
Target detection is a relatively mature problem in autonomous driving systems, among which pedestrian detection is one of the earliest algorithms to be deployed. Very comprehensive research has been carried out in most papers. However, distance perception using fisheye cameras for surround view is relatively less studied. Due to large radial distortion, standard bounding box representation is difficult to implement in fisheye cameras. To alleviate the above description, we explore extended bounding box, ellipse, and general polygon designs into polar/angular representations and define an instance segmentation mIOU metric to analyze these representations. The proposed model fisheyeDetNet with polygonal shape outperforms other models and simultaneously achieves 49.5% mAP on the Valeo fisheye camera dataset for autonomous driving
 nuScenes' latest SOTA | SparseAD: Sparse query helps efficient end-to-end autonomous driving!
Apr 17, 2024 pm 06:22 PM
nuScenes' latest SOTA | SparseAD: Sparse query helps efficient end-to-end autonomous driving!
Apr 17, 2024 pm 06:22 PM
Written in front & starting point The end-to-end paradigm uses a unified framework to achieve multi-tasking in autonomous driving systems. Despite the simplicity and clarity of this paradigm, the performance of end-to-end autonomous driving methods on subtasks still lags far behind single-task methods. At the same time, the dense bird's-eye view (BEV) features widely used in previous end-to-end methods make it difficult to scale to more modalities or tasks. A sparse search-centric end-to-end autonomous driving paradigm (SparseAD) is proposed here, in which sparse search fully represents the entire driving scenario, including space, time, and tasks, without any dense BEV representation. Specifically, a unified sparse architecture is designed for task awareness including detection, tracking, and online mapping. In addition, heavy
