
 Technology peripherals
AI
Video diffusion model in the AIGC era, Fudan and other teams released the first review in the field
Technology peripherals
AI
Video diffusion model in the AIGC era, Fudan and other teams released the first review in the field
Video diffusion model in the AIGC era, Fudan and other teams released the first review in the field
Oct 23, 2023 pm 02:13 PMAI-generated content has become one of the hottest topics in the current field of artificial intelligence and represents the cutting-edge technology in this field. In recent years, with the release of new technologies such as Stable Diffusion, DALL-E3, and ControlNet, the field of AI image generation and editing has achieved stunning visual effects, and has received widespread attention and discussion in both academia and industry. Most of these methods are based on diffusion models, which is the key to their ability to achieve powerful controllable generation, photorealistic generation, and diversity.
However, compared with simple static images, videos have richer semantic information and dynamic changes. Video can show the dynamic evolution of physical objects, so the needs and challenges in the field of video generation and editing are more complex. Although in this field, research on video generation has been facing difficulties due to limitations of annotated data and computing resources, some representative research work, such as Make-A-Video, Imagen Video and Gen-2 methods, have already begun. Gradually take over the dominant position.
These research works lead the development direction of video generation and editing technology. Research data shows that since 2022, research work on diffusion models on video tasks has shown explosive growth. This trend not only reflects the popularity of video diffusion models in academia and industry, but also highlights the urgent need for researchers in this field to continue to make breakthroughs and innovations in video generation technology.
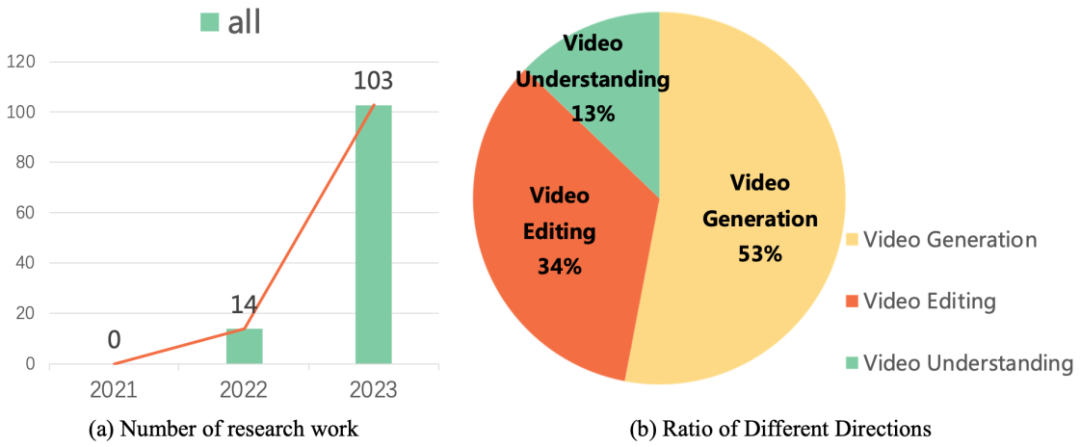
Recently, the Vision and Learning Laboratory of Fudan University, together with academic institutions such as Microsoft and Huawei, released the first This review of the work of diffusion models on video tasks systematically summarizes the academic cutting-edge results of diffusion models in video generation, video editing, and video understanding.

- ## Paper link: https://arxiv.org/abs/2310.10647
- Homepage link: https://github.com/ChenHsing/Awesome-Video-Diffusion-Models
Video Generation
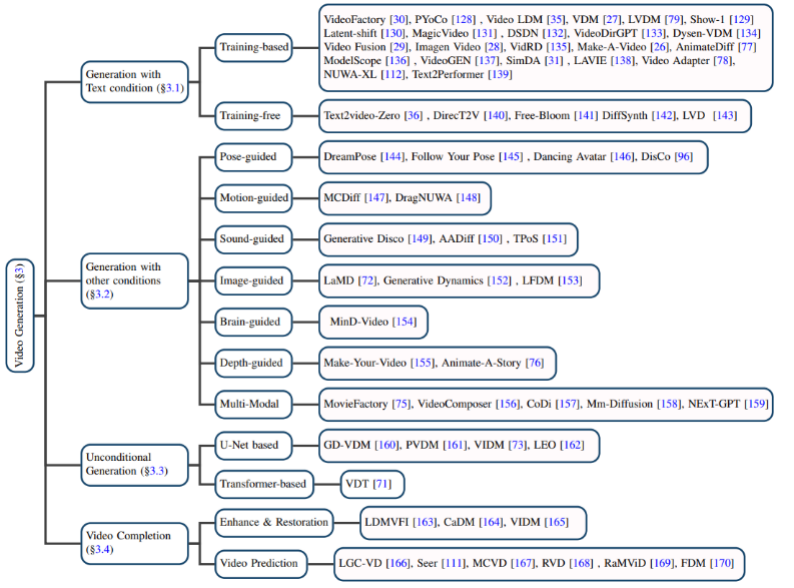
Text-based video generation: Video generation with natural language as input is the most popular in the field of video generation. One of the important tasks. The author first reviews the research results in this field before the diffusion model was proposed, and then introduces training-based and training-free text-video generation models respectively.

Christmas tree holiday celebration winter snow animation.
Video generation based on other conditions : Video generation work in subdivided fields. The author classifies them based on the following conditions: pose (pose-guided), action (motion-guided), sound (sound-guided), image (image-guided), depth map (depth-guided), etc.


#Unconditional video generation: This task refers to video generation without input conditions in a specific field. The author mainly divides the model architecture into U-Net-based and Transformer-based generation models.
Video completion: Mainly includes video enhancement and restoration, video prediction and other tasks.
Data set: The data set used in the video generation task can be divided into the following two categories:
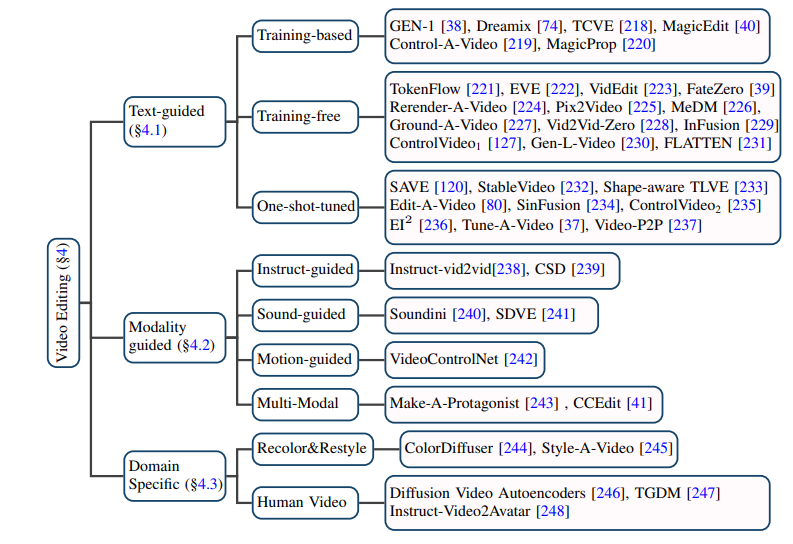
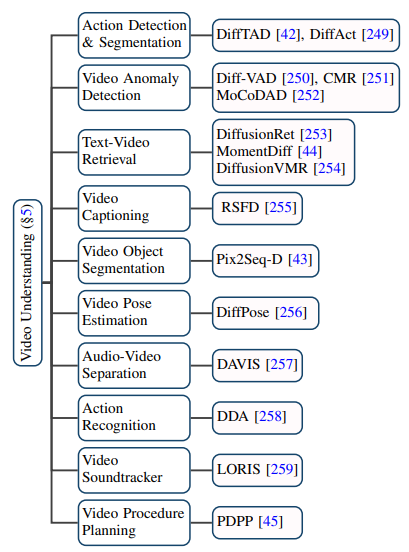
1.Caption-level: Each video has corresponding text description information. The most representative one is the WebVid10M data set.2.Category-level: Videos only have classification labels but no text description information. UCF-101 is currently the most commonly used data set for tasks such as video generation and video prediction. Comparison of evaluation indicators and results: The evaluation indicators generated by video are mainly divided into quality-level evaluation indicators and quantitative-level evaluation indicators. The evaluation indicators at the quality level are mainly based on manual subjective scoring, while the evaluation indicators at the quantitative level can be divided into: 1. Evaluation indicators at the image level: The video is composed of a series of It is composed of image frames, so the image level evaluation method basically refers to the evaluation index of the T2I model. 2. Video-level evaluation indicators: Compared with image-level evaluation indicators, which are more biased toward frame-by-frame measurement, video-level evaluation indicators can measure the temporal coherence of the generated video, etc. aspect. In addition, the author also made a horizontal comparison of the evaluation indicators of the aforementioned generative models on the benchmark data set. Through combing through many studies, the author discovered the core goals of the video editing task It lies in the realization: 1. Fidelity: The corresponding frames of the edited video should be consistent in content with the original video. 2. Alignment: The edited video needs to be aligned with the input conditions. 3. High quality: The edited video should be coherent and of high quality. Text-based video editing: Considering the limited scale of existing text-video data, most text-based video editing tasks currently tend to Use the pre-trained T2I model to solve problems such as the coherence and semantic inconsistency of video frames. The author further subdivides such tasks into training-based, training-free and one-shot tuned methods, and summarizes them respectively. # Video editing based on other conditions: With large models With the advent of the times, in addition to the most direct video editing based on natural language information, video editing based on instructions, sounds, actions, multi-modalities, etc. is receiving more and more attention. The author has also conducted corresponding work. Classification and sorting. Video editing in specific niche areas: Some work focuses on the need for special customization of video editing tasks in specific areas, such as video coloring , portrait video editing, etc. The application of diffusion model in the video field goes far beyond traditional video generation and Editing tasks, it also shows great potential in video understanding tasks. By tracking cutting-edge papers, the author summarized 10 existing application scenarios such as video temporal segmentation, video anomaly detection, video object segmentation, text video retrieval, and action recognition. This review comprehensively and meticulously summarizes the latest research on the AIGC era diffusion model on video tasks. According to the research objects and Technical characteristics, more than a hundred cutting-edge works are classified and summarized, and these models are compared on some classic benchmarks. In addition, the diffusion model also has some new research directions and challenges in the field of video tasks, such as: 1. Large-scale text-video data set collection: the successful separation of T2I models Without opening hundreds of millions of high-quality text-image data sets, the T2V model also requires a large amount of watermark-free, high-resolution text-video data as support. 2. Efficient training and inference: Video data is huge compared to image data, and the computing power required in the training and inference stages has also increased exponentially. Efficient training and inference algorithms can greatly reduce costs. . 3. Reliable benchmarks and evaluation indicators: The existing evaluation indicators in the video field often measure the difference in distribution between the generated video and the original video, but fail to fully measure the distribution of the generated video. quality. At the same time, user testing is still one of the important evaluation methods. Considering that it requires a lot of manpower and is highly subjective, there is an urgent need for more objective and comprehensive evaluation indicators. 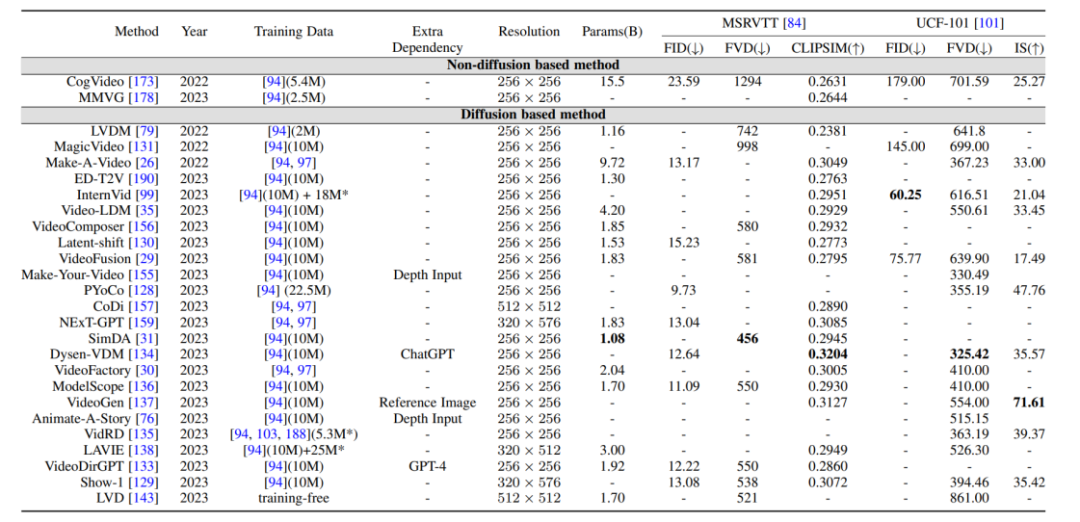
Video Editing


Video understanding
Future and Summary
The above is the detailed content of Video diffusion model in the AIGC era, Fudan and other teams released the first review in the field. For more information, please follow other related articles on the PHP Chinese website!

Hot Article

Hot tools Tags

Hot Article

Hot Article Tags

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 Open source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!
Apr 03, 2024 pm 12:04 PM
Open source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!
Apr 03, 2024 pm 12:04 PM
Open source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!
 The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
 KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
KAN, which replaces MLP, has been extended to convolution by open source projects
 The vitality of super intelligence awakens! But with the arrival of self-updating AI, mothers no longer have to worry about data bottlenecks
Apr 29, 2024 pm 06:55 PM
The vitality of super intelligence awakens! But with the arrival of self-updating AI, mothers no longer have to worry about data bottlenecks
Apr 29, 2024 pm 06:55 PM
The vitality of super intelligence awakens! But with the arrival of self-updating AI, mothers no longer have to worry about data bottlenecks
 Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
 AI subverts mathematical research! Fields Medal winner and Chinese-American mathematician led 11 top-ranked papers | Liked by Terence Tao
Apr 09, 2024 am 11:52 AM
AI subverts mathematical research! Fields Medal winner and Chinese-American mathematician led 11 top-ranked papers | Liked by Terence Tao
Apr 09, 2024 am 11:52 AM
AI subverts mathematical research! Fields Medal winner and Chinese-American mathematician led 11 top-ranked papers | Liked by Terence Tao
 Kuaishou version of Sora 'Ke Ling' is open for testing: generates over 120s video, understands physics better, and can accurately model complex movements
Jun 11, 2024 am 09:51 AM
Kuaishou version of Sora 'Ke Ling' is open for testing: generates over 120s video, understands physics better, and can accurately model complex movements
Jun 11, 2024 am 09:51 AM
Kuaishou version of Sora 'Ke Ling' is open for testing: generates over 120s video, understands physics better, and can accurately model complex movements
 The U.S. Air Force showcases its first AI fighter jet with high profile! The minister personally conducted the test drive without interfering during the whole process, and 100,000 lines of code were tested for 21 times.
May 07, 2024 pm 05:00 PM
The U.S. Air Force showcases its first AI fighter jet with high profile! The minister personally conducted the test drive without interfering during the whole process, and 100,000 lines of code were tested for 21 times.
May 07, 2024 pm 05:00 PM
The U.S. Air Force showcases its first AI fighter jet with high profile! The minister personally conducted the test drive without interfering during the whole process, and 100,000 lines of code were tested for 21 times.
