
 Technology peripherals
AI
LeCun once again badmouthed autoregressive LLM: GPT-4's reasoning ability is very limited, as evidenced by two papers
Technology peripherals
AI
LeCun once again badmouthed autoregressive LLM: GPT-4's reasoning ability is very limited, as evidenced by two papers
LeCun once again badmouthed autoregressive LLM: GPT-4's reasoning ability is very limited, as evidenced by two papers

"Anyone who thinks that auto-regressive LLM is already approaching human-level AI, or that it simply needs to scale up to reach human-level AI, must read this. AR-LLM has very limited reasoning and planning capabilities , to solve this problem, it cannot be solved by making them larger and training with more data."
For a long time, Figure Yann LeCun, the winner of the Spirit Award, is a "questioner" of LLM, and the autoregressive model is the learning paradigm that the GPT series of LLM models rely on. He has publicly expressed his criticism of autoregression and LLM more than once, and has produced many golden sentences, such as:
"In five years from now, no one in their right mind will Will use autoregressive models."
"Auto-Regressive Generative Models suck!"
"LLM has a very superficial understanding of the world."
What made LeCun cry out again recently are two newly released papers:

"Can LLM really self-criticize (and iteratively improve) its solutions as the literature suggests? Two new papers from our group reason (https://arxiv. org/abs/2310.12397) and planning (https://arxiv.org/abs/2310.08118) missions to investigate (and challenge) these claims."
See Well, the theme of these two papers investigating the verification and self-criticism capabilities of GPT-4 has resonated with many people.
The authors of the paper stated that they also believe that LLM is a great "idea generator" (whether in language form or code form), but they cannot guarantee their own planning/reasoning capabilities. Therefore, they are best used in an LLM-Modulo environment (with either a reliable reasoner or a human expert in the loop). Self-criticism requires verification, and verification is a form of reasoning (so be surprised by all the claims about LLM's ability to self-criticize).
At the same time, there are also voices of doubt: "The reasoning ability of convolutional networks is more limited, but this does not prevent AlphaZero's work from appearing. It is all about the reasoning process and establishment (RL) feedback loop. I think model capabilities allow for extremely deep reasoning (e.g., research-level mathematics)."
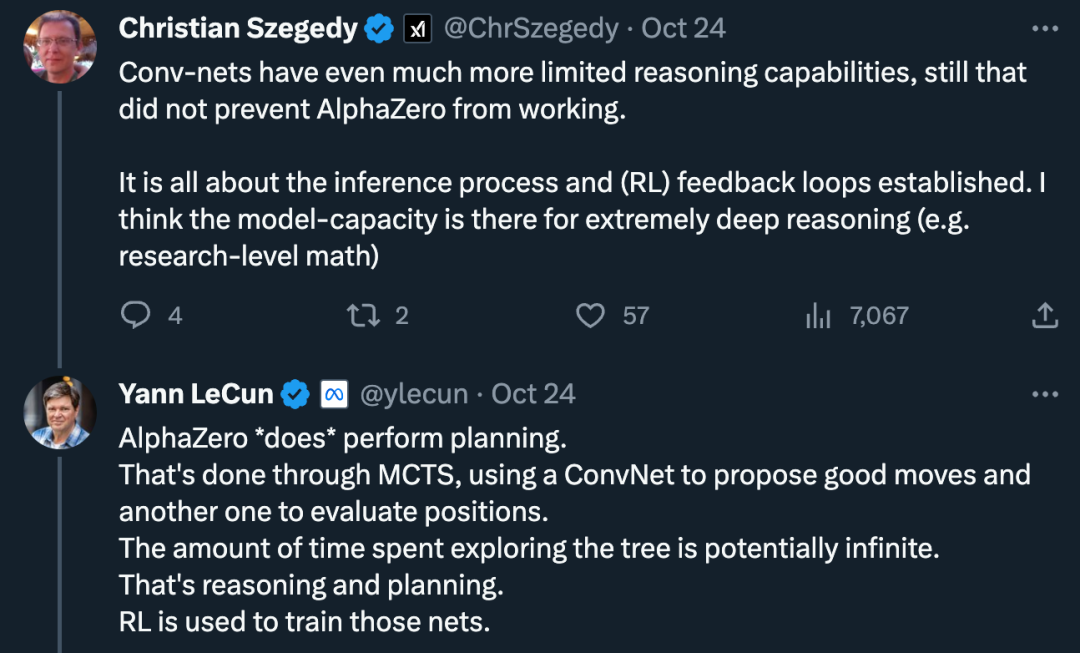
In this regard, LeCun's The idea is: "AlphaZero "really" executes the plan. This is done via a Monte Carlo tree search, using a convolutional network to come up with good actions and another convolutional network to evaluate the position. The time spent exploring the tree could be infinite, that's all reasoning and planning. "
In the future, the topic of whether autoregressive LLM has reasoning and planning capabilities may not be finalized.
Next, we can take a look at what these two new papers talk about.
Paper 1: GPT-4 Doesn't Know It's Wrong: An Analysis of Iterative Prompting for Reasoning Problems
The first paper raised questions among researchers about the self-criticism ability of state-of-the-art LLM, including GPT-4.

Paper address: https://arxiv.org/pdf/2310.12397.pdf
Connect Let's take a look at the introduction of the paper.
People have always had considerable disagreements about the reasoning capabilities of large language models (LLMs). Initially, researchers were optimistic that the reasoning capabilities of LLMs would automatically appear as the model scale expands. , however, as more failures emerged, expectations became less intense. Afterwards, researchers generally believed that LLM has the ability to self-criticize and improve LLM solutions in an iterative manner, and this view has been widely disseminated.
But is this really the case?
Researchers from Arizona State University examined the reasoning capabilities of LLM in a new study. Specifically, they focused on the effectiveness of iterative prompting in the graph coloring problem, one of the most famous NP-complete problems.
The study shows that (i) LLM is not good at solving graph coloring instances (ii) LLM is not good at validating solutions and is therefore ineffective in iterative mode. The results of this paper thus raise questions about the self-critical capabilities of state-of-the-art LLMs.
The paper gives some experimental results, for example, in direct mode, LLM is very bad at solving graph coloring instances. In addition, the study also found that LLM is not good at verifying the solution. Worse yet, the system fails to recognize the correct color and ends up with the wrong color.
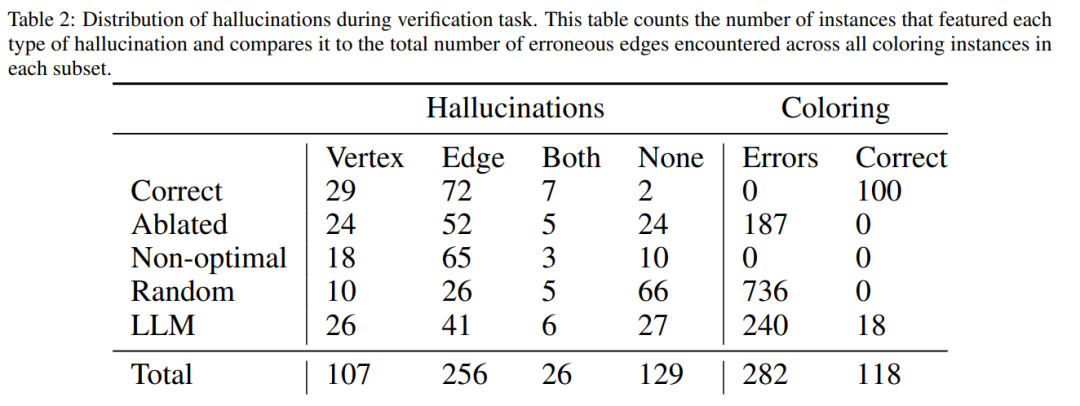
The following figure is an evaluation of the graph colorization problem. In this setting, GPT-4 can guess colors in an independent and self-critical mode. Outside of the self-critical loop there is an external voice validator.
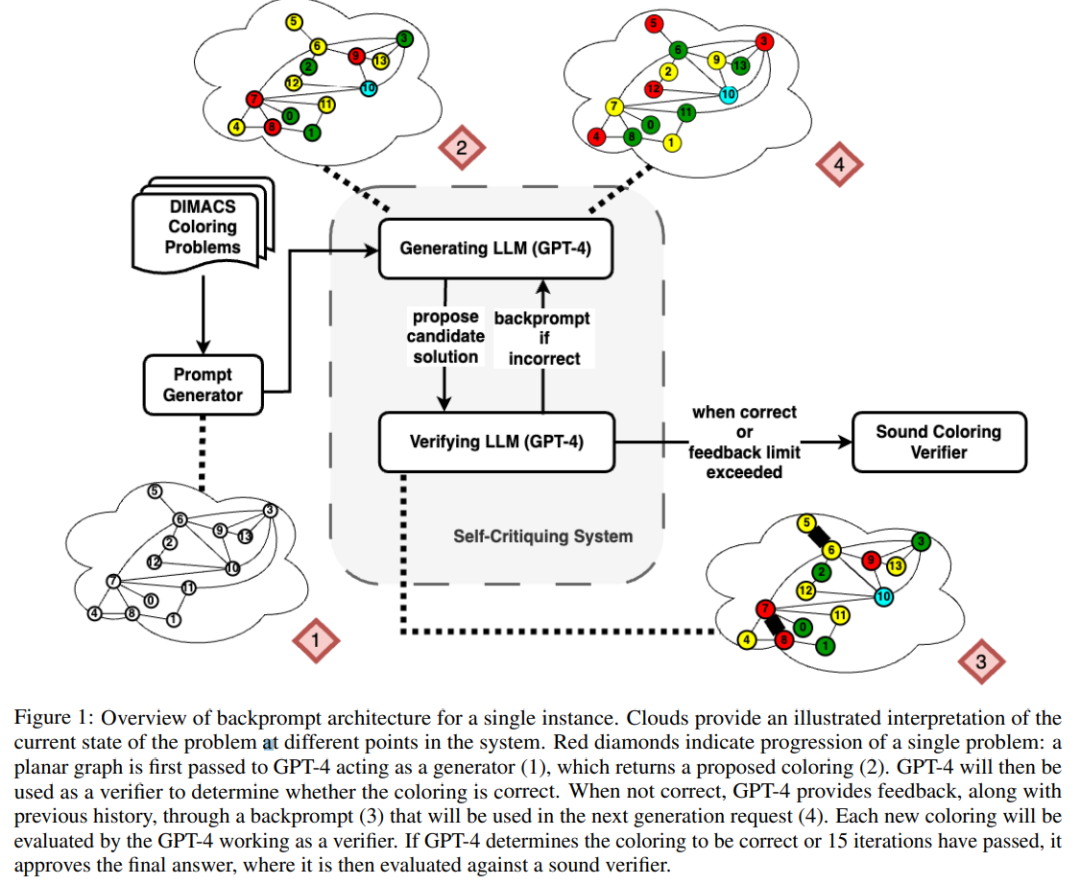
The results show that GPT4 is less than 20% accurate at guessing colors, and even more surprisingly, the self-criticism mode (image below) Column 2) has the lowest accuracy. This paper also examines the related question of whether GPT-4 would improve its solution if an external vocal verifier provided provably correct criticisms of the colors it guesses. In this case, reverse hinting can really improve performance.
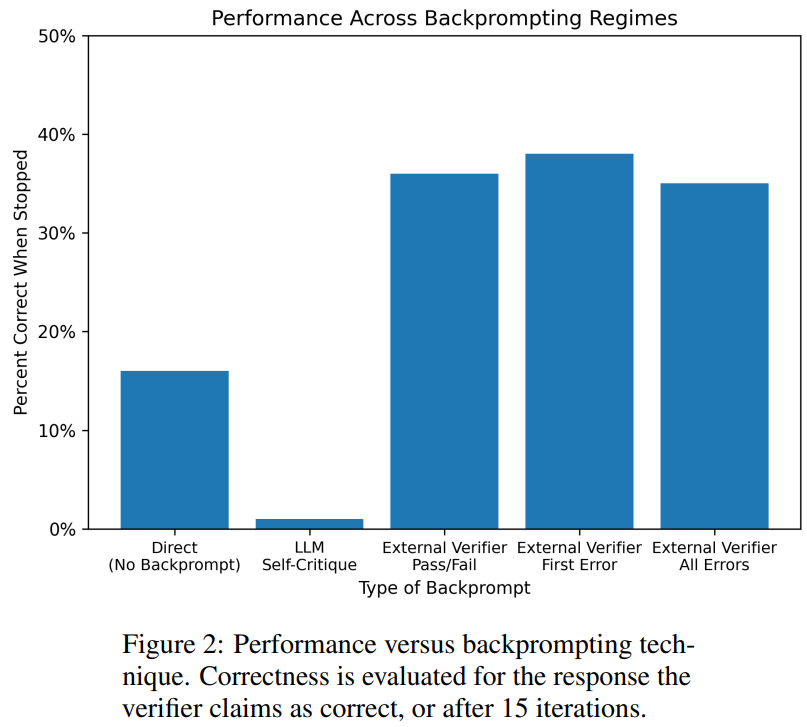
Even if GPT-4 accidentally guesses a valid color, its self-criticism may cause it to hallucinate that there is no violation .
Finally, the author gives a summary, regarding the problem of graph coloring:
- Self-criticism It actually hurts LLM performance because GPT-4 is terrible at verification;
- Feedback from external validators can really improve LLM performance.
Paper 2: Can Large Language Models Really Improve by Self-critiquing Their Own Plans?
In the paper "Can Large Language Models Really Improve by Self-critiquing Their Own Plans?", the research team explored the ability of LLM to self-verify/criticize in the context of planning.
This paper provides a systematic study of the ability of LLMs to critique their own outputs, particularly in the context of classical planning problems. While recent research has been optimistic about the self-critical potential of LLMs, especially in iterative settings, this study suggests a different perspective.

Paper address: https://arxiv.org/abs/2310.08118
Unexpected However, the results show that self-criticism degrades the performance of plan generation, especially compared to systems with external verifiers and LLM verifiers. LLM can produce a large number of error messages, thereby compromising the reliability of the system.
The researchers’ empirical evaluation on the classic AI planning domain Blocksworld highlights that the self-critical function of LLM is not effective in planning problems. The validator can generate a large number of errors, which is detrimental to the reliability of the entire system, especially in areas where the correctness of planning is critical.
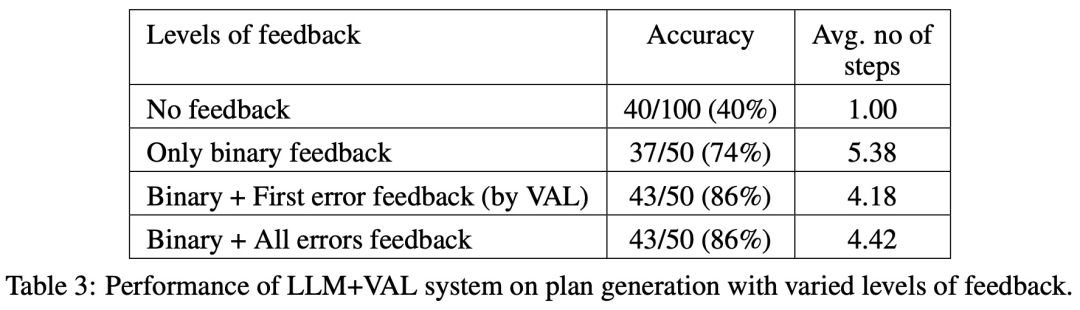
Interestingly, the nature of the feedback (binary or detailed feedback) has no significant impact on plan generation performance, suggesting that the core issue lies in the binary verification capabilities of LLM rather than the granularity of the feedback.
As shown in the figure below, the evaluation architecture of this study includes 2 LLMs - generator LLM and verifier LLM. For a given instance, the generator LLM is responsible for generating candidate plans, while the verifier LLM determines their correctness. If the plan is found to be incorrect, the validator provides feedback giving the reason for its error. This feedback is then transferred to the generator LLM, which prompts the generator LLM to generate new candidate plans. All experiments in this study used GPT-4 as the default LLM.
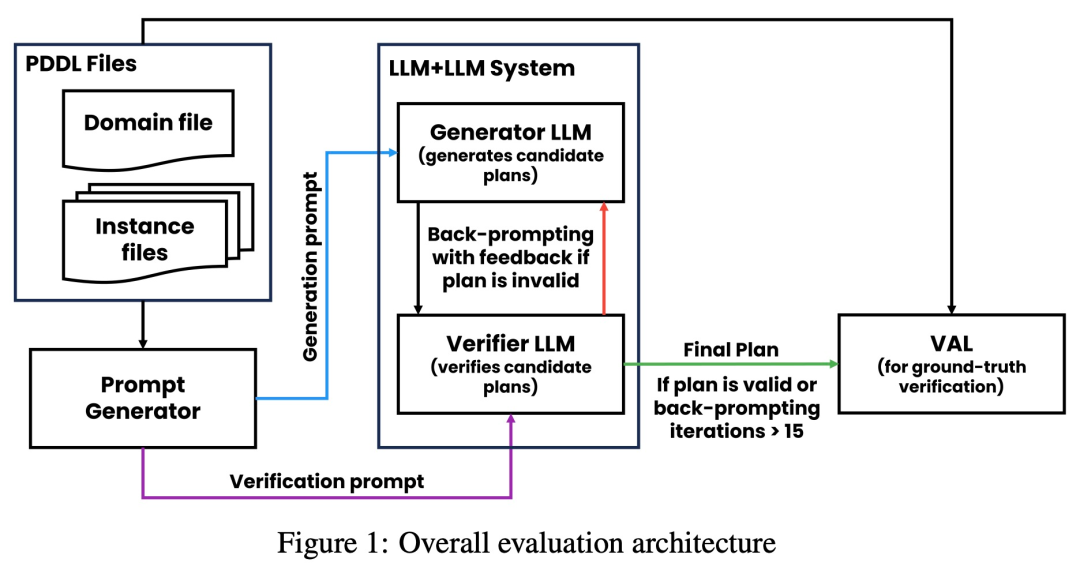
This study experiments and compares several plan generation methods on Blocksworld. Specifically, the study generated 100 random instances for evaluation of various methods. To provide a realistic assessment of the correctness of the final LLM planning, the study employs an external validator VAL.
As shown in Table 1, the LLM LLM backprompt method is slightly better than the non-backprompt method in terms of accuracy.
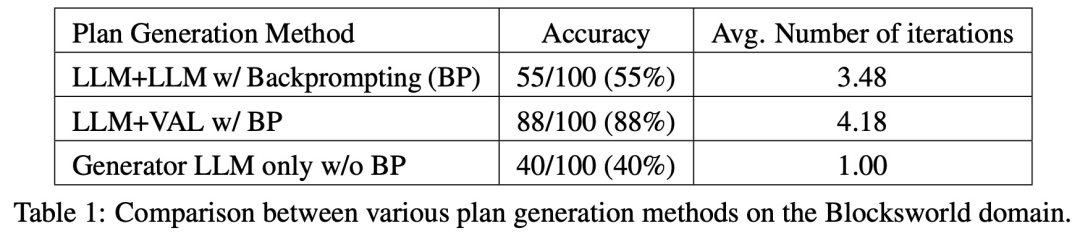
Out of 100 instances, the validator accurately identified 61 (61%).
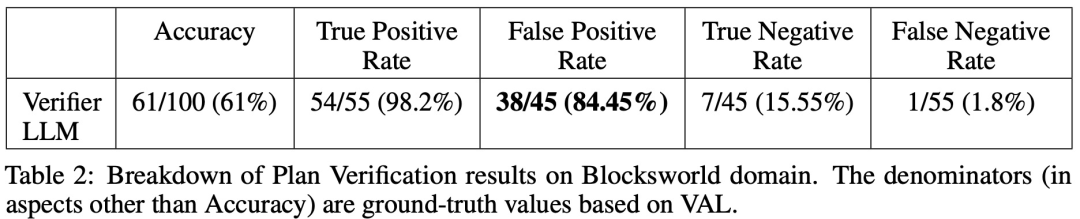
The table below shows the performance of LLM when receiving different levels of feedback, including no feedback.
The above is the detailed content of LeCun once again badmouthed autoregressive LLM: GPT-4's reasoning ability is very limited, as evidenced by two papers. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 How to define header files for vscode
Apr 15, 2025 pm 09:09 PM
How to define header files for vscode
Apr 15, 2025 pm 09:09 PM
How to define header files using Visual Studio Code? Create a header file and declare symbols in the header file using the .h or .hpp suffix name (such as classes, functions, variables) Compile the program using the #include directive to include the header file in the source file. The header file will be included and the declared symbols are available.
 Do you use c in visual studio code
Apr 15, 2025 pm 08:03 PM
Do you use c in visual studio code
Apr 15, 2025 pm 08:03 PM
Writing C in VS Code is not only feasible, but also efficient and elegant. The key is to install the excellent C/C extension, which provides functions such as code completion, syntax highlighting, and debugging. VS Code's debugging capabilities help you quickly locate bugs, while printf output is an old-fashioned but effective debugging method. In addition, when dynamic memory allocation, the return value should be checked and memory freed to prevent memory leaks, and debugging these issues is convenient in VS Code. Although VS Code cannot directly help with performance optimization, it provides a good development environment for easy analysis of code performance. Good programming habits, readability and maintainability are also crucial. Anyway, VS Code is
 Can vscode run kotlin
Apr 15, 2025 pm 06:57 PM
Can vscode run kotlin
Apr 15, 2025 pm 06:57 PM
Running Kotlin in VS Code requires the following environment configuration: Java Development Kit (JDK) and Kotlin compiler Kotlin-related plugins (such as Kotlin Language and Kotlin Extension for VS Code) create Kotlin files and run code for testing to ensure successful environment configuration
 Which one is better, vscode or visual studio
Apr 15, 2025 pm 08:36 PM
Which one is better, vscode or visual studio
Apr 15, 2025 pm 08:36 PM
Depending on the specific needs and project size, choose the most suitable IDE: large projects (especially C#, C) and complex debugging: Visual Studio, which provides powerful debugging capabilities and perfect support for large projects. Small projects, rapid prototyping, low configuration machines: VS Code, lightweight, fast startup speed, low resource utilization, and extremely high scalability. Ultimately, by trying and experiencing VS Code and Visual Studio, you can find the best solution for you. You can even consider using both for the best results.
 Can vscode be used for java
Apr 15, 2025 pm 08:33 PM
Can vscode be used for java
Apr 15, 2025 pm 08:33 PM
VS Code is absolutely competent for Java development, and its powerful expansion ecosystem provides comprehensive Java development capabilities, including code completion, debugging, version control and building tool integration. In addition, VS Code's lightweight, flexibility and cross-platformity make it better than bloated IDEs. After installing JDK and configuring JAVA_HOME, you can experience VS Code's Java development capabilities by installing "Java Extension Pack" and other extensions, including intelligent code completion, powerful debugging functions, construction tool support, etc. Despite possible compatibility issues or complex project configuration challenges, these issues can be addressed by reading extended documents or searching for solutions online, making the most of VS Code’s
 What does sublime renewal balm mean
Apr 16, 2025 am 08:00 AM
What does sublime renewal balm mean
Apr 16, 2025 am 08:00 AM
Sublime Text is a powerful customizable text editor with advantages and disadvantages. 1. Its powerful scalability allows users to customize editors through plug-ins, such as adding syntax highlighting and Git support; 2. Multiple selection and simultaneous editing functions improve efficiency, such as batch renaming variables; 3. The "Goto Anything" function can quickly jump to a specified line number, file or symbol; but it lacks built-in debugging functions and needs to be implemented by plug-ins, and plug-in management requires caution. Ultimately, the effectiveness of Sublime Text depends on the user's ability to effectively configure and manage it.
 How to beautify json with vscode
Apr 15, 2025 pm 05:06 PM
How to beautify json with vscode
Apr 15, 2025 pm 05:06 PM
Beautifying JSON data in VS Code can be achieved by using the Prettier extension to automatically format JSON files so that key-value pairs are arranged neatly and indented clearly. Configure Prettier formatting rules as needed, such as indentation size, line breaking method, etc. Use the JSON Schema Validator extension to verify the validity of JSON files to ensure data integrity and consistency.
 Can vscode run c
Apr 15, 2025 pm 08:24 PM
Can vscode run c
Apr 15, 2025 pm 08:24 PM
Of course! VS Code integrates IntelliSense, debugger and other functions through the "C/C" extension, so that it has the ability to compile and debug C. You also need to configure a compiler (such as g or clang) and a debugger (in launch.json) to write, run, and debug C code like you would with other IDEs.
