
 Technology peripherals
AI
High-precision and low-cost 3D face reconstruction solution for games, interpretation of Tencent AI Lab ICCV 2023 paper
Technology peripherals
AI
High-precision and low-cost 3D face reconstruction solution for games, interpretation of Tencent AI Lab ICCV 2023 paper
High-precision and low-cost 3D face reconstruction solution for games, interpretation of Tencent AI Lab ICCV 2023 paper

3D face reconstruction is a key technology widely used in game film and television production, digital people, AR/VR, face recognition and editing and other fields. Its goal is to obtain high-quality images from a single or multiple images. 3D face model. With the help of complex shooting systems in studios, currently mature solutions in the industry can achieve reconstruction effects with pore-level accuracy that are comparable to real people [2]. However, their production costs are high and their cycle times are long, and they are generally only used in S-level film and television or game projects.
In recent years, interactive gameplay based on low-cost face reconstruction technology (such as game character face pinching gameplay, AR/VR virtual image generation, etc.) has been welcomed by the market. Users only need to input pictures that can be obtained daily, such as single or multiple pictures taken by mobile phones, to quickly obtain a 3D model. However, the imaging quality of the existing methods is uncontrollable, the accuracy of the reconstruction results is low, and it is unable to express the details of the face [3-4]. How to obtain high-fidelity 3D faces at low cost is still an unsolved problem.
The first step in face reconstruction is to define the face expression method. However, the existing mainstream face parameterized models have limited expression capabilities. Even with more constraint information, such as multi-view images, the reconstruction accuracy is difficult. promote. Therefore, Tencent AI Lab proposed an improved Adaptive Skinning Model (hereinafter referred to as ASM) as a parametric face model, which uses face priors and uses a Gaussian mixture model to express face masking. Pi weights greatly reduce the number of parameters so that they can be solved automatically.
Tests show that ASM method uses only a small number of parameters without the need for training, which significantly improves the expression ability of faces and the accuracy of multi-view face reconstruction, innovating the SOTA level. The relevant paper has been accepted by ICCV-2023. The following is a detailed explanation of the paper.
Paper title: ASM: Adaptive Skinning Model for High-Quality 3D Face Modeling

Research Challenge: Low-cost, high-precision 3D face reconstruction problem
Getting more informative 3D images from 2D images The model is an underdetermined problem with infinite solutions. In order to make it solvable, researchers introduce face priors into reconstruction, which reduces the difficulty of solving and expresses the 3D shape of the face with fewer parameters, that is, a parametric face model. Most of the current parametric face models are based on the 3D Morphable Model (3DMM) and its improved version. 3DMM is a parametric face model first proposed by Blanz and Vetter in 1999 [5]. The article assumes that a face can be obtained through a linear or non-linear combination of multiple different faces. It builds a face base library by collecting hundreds of high-precision 3D models of real faces, and then combines parameterized faces to express new features. Face model. Subsequent research optimized 3DMM by collecting more diverse real face models [6, 7] and improving dimensionality reduction methods [8, 9]. However, the 3DMM face-like model has high robustness but insufficient expressive ability. Although it can stably generate face models with average accuracy when the input image is blurred or occluded, when multiple high-quality images are used as input, 3DMM has limited expression ability and cannot utilize more input information. Therefore, limits the reconstruction accuracy. This limitation stems from two aspects. First, the limitations of the method itself. Second, the method relies on the collection of face model data. Not only is the cost of data acquisition high, but also it is difficult to apply in practical applications due to the sensitivity of face data. Extensive reuse.ASM method: Redesign the skeleton-skinned model
In order to solve the problem of insufficient expression ability of the existing 3DMM face model, this article introduces the " Skeleton-Skinned Model" as a baseline facial expression. Skeleton-skinned models are a common facial modeling method used to express the face shapes and expressions of game characters in the process of game and animation production. It is connected to the Mesh vertices on the human face through virtual bone points. The skin weight determines the influence weight of the bones on the Mesh vertices. When used, you only need to control the movement of the bones to indirectly control the movement of the Mesh vertices. Normally, the skeleton-skin model requires animators to perform precise bone placement and skin weight drawing, which has the characteristics of high production threshold and long production cycle. However, the shapes of bones and muscles of different people in real human faces are quite different. A set of fixed skeleton-skinning system is difficult to express the various face shapes in reality. For this reason, this article uses the existing skeleton-skinning system On the basis of further design, the adaptive bone-skinning model ASM is proposed, which is based on Gaussian mixture skinning weights (GMM Skinning Weights) and dynamic bone binding system (Dynamic Bone Binding)to further improve the bone-skinning Expressive ability and flexibility, adaptively generate a unique skeleton-skin model for each target face to express richer facial details.
In order to improve the expressive ability of the skeleton-skin model for modeling different faces, ASM has made a new design for the modeling method of the skeleton-skin model.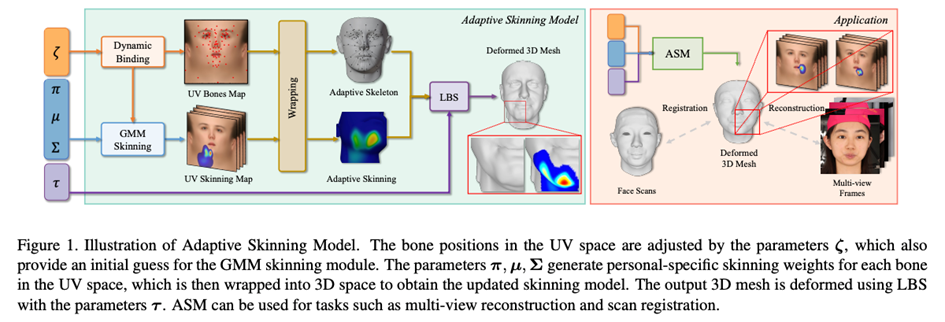
# Skinning (LBS) algorithm controls the deformation of Mesh vertices by controlling the movement (rotation, translation, scaling) of bones. Traditional bone-skinning consists of two parts, namely the skin weight matrix and bone binding. ASM parameters these two parts separately to achieve an adaptive bone-skinning model. Next, we will introduce the parametric modeling methods of skin weight matrix and bone binding respectively.
## Formula 1: LBS formula of traditional skeleton-skinned model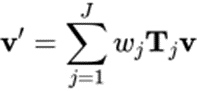
Formula 2: ASM’s LBS formula
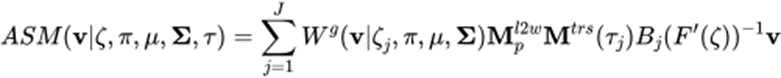
Gaussian Mixed Skinning Weights (GMM Skinning Weights)The skin weight matrix is an mxn-dimensional matrix, where m is the number of bones and n is the number of vertices on the Mesh. This matrix is used to store the influence coefficient of each bone on each Mesh vertex. Generally speaking, the skin weight matrix is highly sparse. For example, in Unity, each Mesh vertex will only be affected by up to 4 bones. Except for these 4 bones, the influence coefficient of the other bones on the vertex is 0. In the traditional bone-skinned model, the skin weights are drawn by the animator, and once the skin weights are obtained, they will no longer change when used. In recent years, some work [1] has tried to combine a large amount of data with neural network learning to automatically generate skinning weights. However, such a solution has two problems. First, training the neural network requires a large amount of data. If it is a 3D face or skinning Weight data is more difficult to obtain; secondly, there is serious parameter redundancy in using neural network to model skin weights.
Is there a skin weight modeling method that can fully express the skin weight of the entire face using a small number of parameters without training?By observing common skinning weights, we can find the following properties: 1. The skinning weight is locally smooth; 2. The farther the Mesh vertex is from the current bone position, the corresponding skinning coefficient is usually smaller. ; And this property is very consistent with the Gaussian Mixture Model (GMM). Therefore, this article proposes Gaussian Mixed Skinning Weights (GMM Skinning Weights) to model the skinning weight matrix as a Gaussian mixture function based on a certain distance function between vertices and bones, so that a set of GMM coefficients can be used to express the skinning weights of specific bones. distributed. In order to further compress the parameters of the skin weight, we transfer the entire face Mesh from the three-dimensional space to the UV space, so that we only need to use the two-dimensional GMM and use the UV distance from the vertex to the bone to calculate the current bone's masking of a specific vertex. Skin weight coefficient.
Dynamic Bone Binding
Parametric modeling of skin weights not only allows us to express the skin weight matrix with a small number of parameters, but also It makes it possible for us to adjust the bone binding position at run-time. Therefore, this article proposes the method of dynamic bone binding (Dynamic Bone Binding). Same as the skin weight, this article models the binding position of the bone as a coordinate point on the UV space, and can move arbitrarily in the UV space. For the vertices of the face Mesh, the vertices can be mapped to a fixed coordinate in the UV space simply through the predefined UV mapping relationship. But the bones are not predefined in UV space, so for this we need to transfer the bound bones from three-dimensional space to UV space. This step in this article is implemented by interpolating the coordinates of the bones and surrounding vertices. We apply the calculated interpolation coefficients to the UV coordinates of the vertices to obtain the UV coordinates of the bones. The same goes for the other way around. When we need to transfer bone coordinates from UV space to three-dimensional space, we also calculate the interpolation coefficient between the UV coordinates of the current bone and the UV coordinates of adjacent vertices, and apply the interpolation coefficient to the same vertex in three-dimensional space. On the three-dimensional coordinates, the three-dimensional space coordinates of the corresponding bones can be interpolated.
Through this modeling method, we unify the binding positions of the bones and the skin weight coefficients into a set of coefficients in the UV space. When using ASM, we convert the deformation of the face Mesh vertices into a combination of the offset coefficient of the bone binding position in the UV space, the Gaussian mixture skinning coefficient in the UV space, and the bone motion coefficient, Greatly improves the expressive ability of the skeleton-skinned model, enabling the generation of richer facial details.

## to The facial expression ability and multi-view reconstruction accuracy reach SOTA level
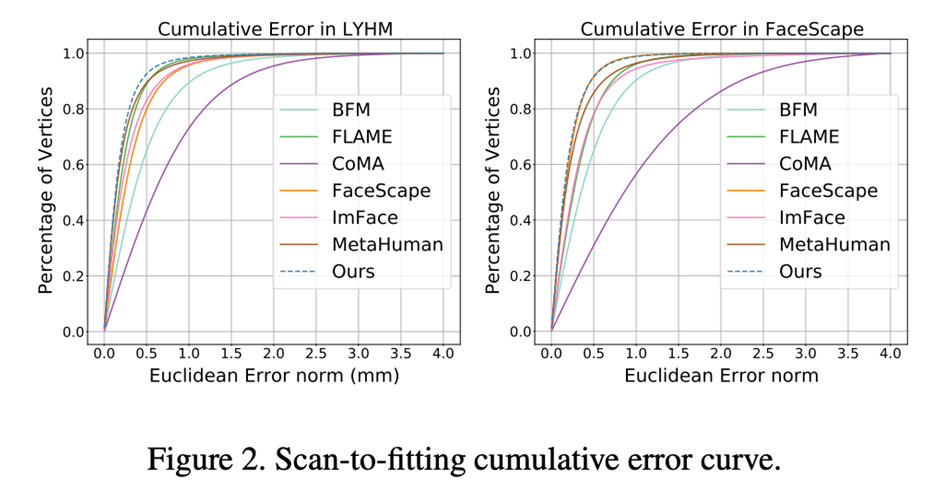
Compare the expressive ability of different parametric face modelsWe use parametric face model registration The method of high-precision face scanning model (Registration) combines ASM with traditional 3DMM based on PCA method (BFM [6], FLAME [7], FaceScape [10]), 3DMM based on neural network dimensionality reduction method (CoMA [ 8], ImFace [9]) and the industry's leading bone-skinned model (MetaHuman) were compared. The results indicate that ASM's expression ability has reached SOTA level on both LYHM and FaceScape data sets.
## Table 2: Registration accuracy of LYHM and FaceScape
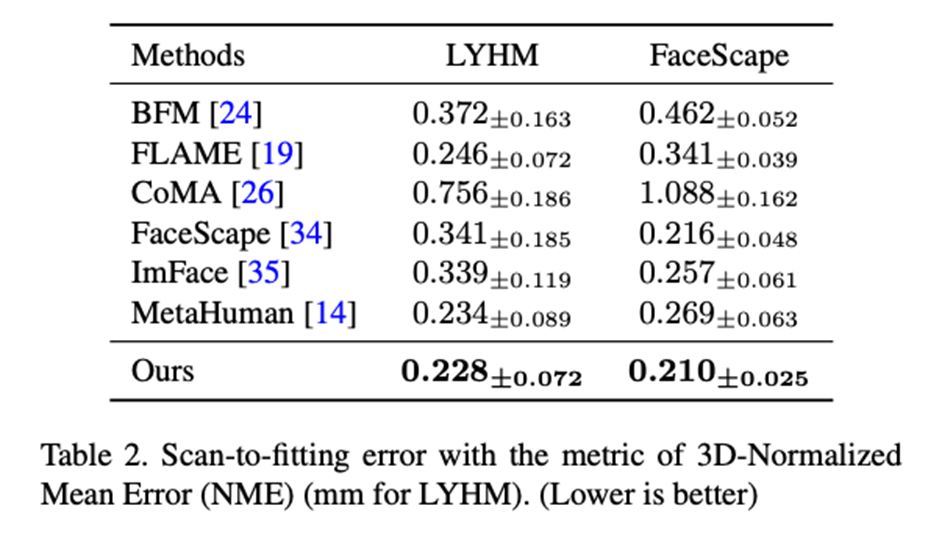
Figure 2: Error distribution of registration accuracy on LYHM and FaceScape
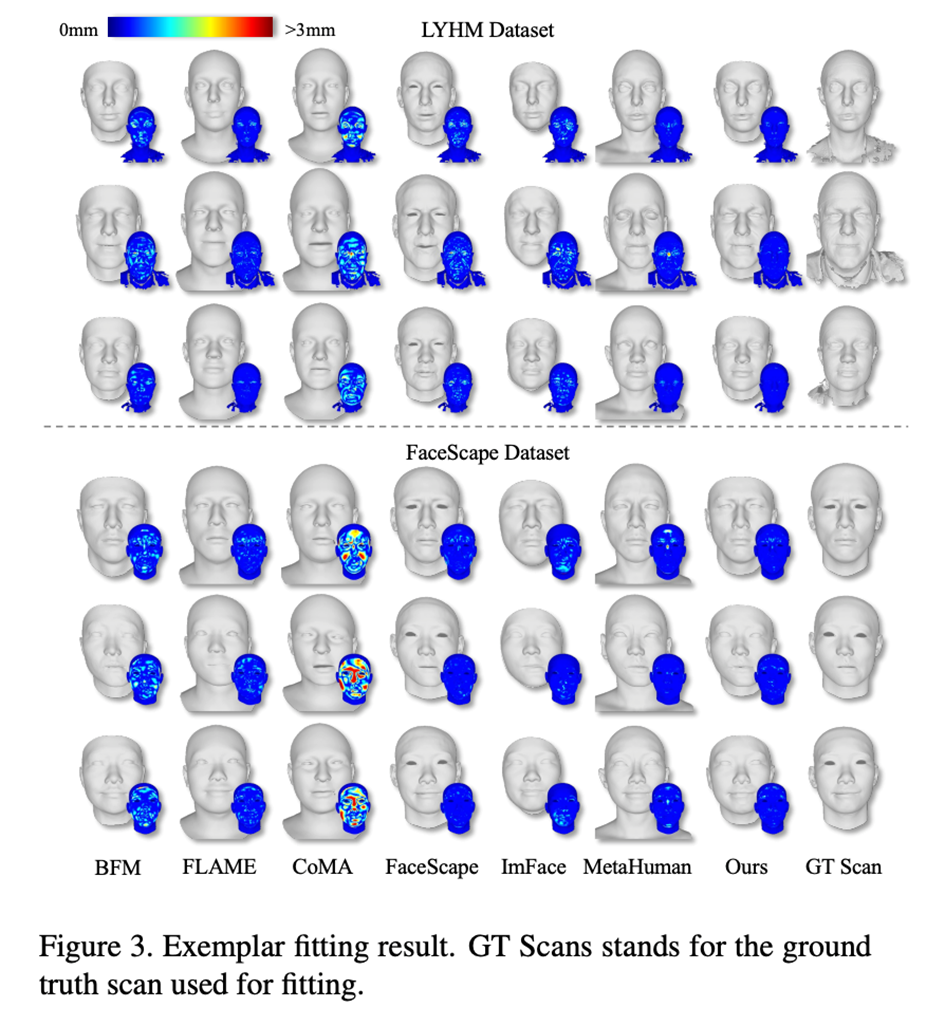
# Figure 3: LYHM Visualization results and error heat map of registration on FaceScape
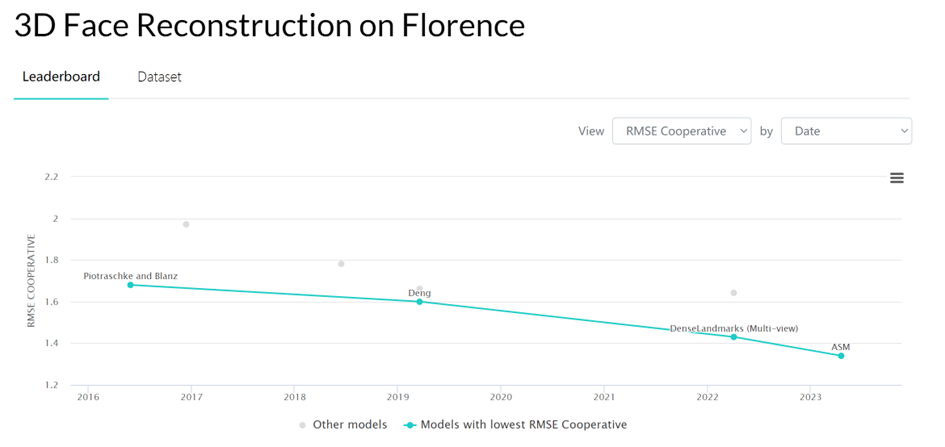
We used the data of Florence MICC This set tested the performance of ASM on multi-view face reconstruction tasks, and the reconstruction accuracy on the Coop (indoor close-range camera, people with no expressions) test set reached the SOTA level.
# 图 4: 3D face reconstruction results on the Florence Micc data set The impact of the number of pictures on the reconstruction results in the multi-view reconstruction task was tested on the FaceScape data set. The results show that when the number of pictures is around 5, ASM can achieve the highest reconstruction accuracy compared to other facial expression methods.
## to
##This research has taken an important step towards solving the industry problem of obtaining high-fidelity human faces at low cost. The new parametric face model we propose significantly enhances the ability of facial expression and raises the upper limit of accuracy of multi-view face reconstruction to a new level. This method can be used in many fields such as 3D character modeling in game production, automatic face pinching gameplay, and avatar generation in AR/VR.
After the facial expression ability has been significantly improved, how to construct stronger consistency constraints from multi-view images to further improve the accuracy of reconstruction results has become a new bottleneck and new challenge in the current field of face reconstruction. This will also be our future research direction.
References
[1] Noranart Vesdapunt, Mitch Rundle, HsiangTao Wu, and Baoyuan Wang. Jnr: Joint-based neural rig representation for compact 3d face modeling. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XVIII 16, pages 389–405. Springer, 2020.
[2] Thabo Beeler, Bernd Bickel, Paul Beardsley, Bob Sumner, and Markus Gross. High-quality single-shot capture of facial geometry. In ACM SIGGRAPH 2010 papers, pages 1–9. 2010.
[3] Yu Deng, Jiaolong Yang, Sicheng Xu, Dong Chen, Yunde Jia, and Xin Tong. Accurate 3d face reconstruction with weakly-supervised learning: From single image to image set. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, pages 0–0, 2019.
[4] Yao Feng, Haiwen Feng, Michael J Black, and Timo Bolkart. Learning an animatable detailed 3d face model from in-the-wild images. ACM Transactions on Graphics (ToG), 40 (4):1–13, 2021.
[5] Volker Blanz and Thomas Vetter. A morphable model for the synthesis of 3d faces. In Proceedings of the 26th annual conference on Computer graphics and interactive techniques, pages 187–194, 1999.
[6] Pascal Paysan, Reinhard Knothe, Brian Amberg, Sami Romdhani, and Thomas Vetter. A 3d face model for pose and illumination invariant face recognition. In 2009 sixth IEEE international conference on advanced video and signal based surveillance, pages 296–301. Ieee, 2009.
[7] Tianye Li, Timo Bolkart, Michael J Black, Hao Li, and Javier Romero. Learning a model of facial shape and expression from 4d scans. ACM Trans. Graph., 36 (6):194–1, 2017.
[8] Anurag Ranjan, Timo Bolkart, Soubhik Sanyal, and Michael J Black. Generating 3d faces using convolutional mesh autoencoders. In Proceedings of the European conference on computer vision (ECCV), pages 704–720, 2018.
[9] Mingwu Zheng, Hongyu Yang, Di Huang, and Liming Chen. Imface: A nonlinear 3d morphable face model with implicit neural representations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20343–20352, 2022.
[10] Haotian Yang, Hao Zhu, Yanru Wang, Mingkai Huang, Qiu Shen, Ruigang Yang, and Xun Cao. Facescape: a large-scale high quality 3d face dataset and detailed riggable 3d face prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 601–610, 2020.
The above is the detailed content of High-precision and low-cost 3D face reconstruction solution for games, interpretation of Tencent AI Lab ICCV 2023 paper. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 The author of ControlNet has another hit! The whole process of generating a painting from a picture, earning 1.4k stars in two days
Jul 17, 2024 am 01:56 AM
The author of ControlNet has another hit! The whole process of generating a painting from a picture, earning 1.4k stars in two days
Jul 17, 2024 am 01:56 AM
It is also a Tusheng video, but PaintsUndo has taken a different route. ControlNet author LvminZhang started to live again! This time I aim at the field of painting. The new project PaintsUndo has received 1.4kstar (still rising crazily) not long after it was launched. Project address: https://github.com/lllyasviel/Paints-UNDO Through this project, the user inputs a static image, and PaintsUndo can automatically help you generate a video of the entire painting process, from line draft to finished product. follow. During the drawing process, the line changes are amazing. The final video result is very similar to the original image: Let’s take a look at a complete drawing.
 From RLHF to DPO to TDPO, large model alignment algorithms are already 'token-level'
Jun 24, 2024 pm 03:04 PM
From RLHF to DPO to TDPO, large model alignment algorithms are already 'token-level'
Jun 24, 2024 pm 03:04 PM
The AIxiv column is a column where this site publishes academic and technical content. In the past few years, the AIxiv column of this site has received more than 2,000 reports, covering top laboratories from major universities and companies around the world, effectively promoting academic exchanges and dissemination. If you have excellent work that you want to share, please feel free to contribute or contact us for reporting. Submission email: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com In the development process of artificial intelligence, the control and guidance of large language models (LLM) has always been one of the core challenges, aiming to ensure that these models are both powerful and safe serve human society. Early efforts focused on reinforcement learning methods through human feedback (RL
 Topping the list of open source AI software engineers, UIUC's agent-less solution easily solves SWE-bench real programming problems
Jul 17, 2024 pm 10:02 PM
Topping the list of open source AI software engineers, UIUC's agent-less solution easily solves SWE-bench real programming problems
Jul 17, 2024 pm 10:02 PM
The AIxiv column is a column where this site publishes academic and technical content. In the past few years, the AIxiv column of this site has received more than 2,000 reports, covering top laboratories from major universities and companies around the world, effectively promoting academic exchanges and dissemination. If you have excellent work that you want to share, please feel free to contribute or contact us for reporting. Submission email: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com The authors of this paper are all from the team of teacher Zhang Lingming at the University of Illinois at Urbana-Champaign (UIUC), including: Steven Code repair; Deng Yinlin, fourth-year doctoral student, researcher
 Posthumous work of the OpenAI Super Alignment Team: Two large models play a game, and the output becomes more understandable
Jul 19, 2024 am 01:29 AM
Posthumous work of the OpenAI Super Alignment Team: Two large models play a game, and the output becomes more understandable
Jul 19, 2024 am 01:29 AM
If the answer given by the AI model is incomprehensible at all, would you dare to use it? As machine learning systems are used in more important areas, it becomes increasingly important to demonstrate why we can trust their output, and when not to trust them. One possible way to gain trust in the output of a complex system is to require the system to produce an interpretation of its output that is readable to a human or another trusted system, that is, fully understandable to the point that any possible errors can be found. For example, to build trust in the judicial system, we require courts to provide clear and readable written opinions that explain and support their decisions. For large language models, we can also adopt a similar approach. However, when taking this approach, ensure that the language model generates
 arXiv papers can be posted as 'barrage', Stanford alphaXiv discussion platform is online, LeCun likes it
Aug 01, 2024 pm 05:18 PM
arXiv papers can be posted as 'barrage', Stanford alphaXiv discussion platform is online, LeCun likes it
Aug 01, 2024 pm 05:18 PM
cheers! What is it like when a paper discussion is down to words? Recently, students at Stanford University created alphaXiv, an open discussion forum for arXiv papers that allows questions and comments to be posted directly on any arXiv paper. Website link: https://alphaxiv.org/ In fact, there is no need to visit this website specifically. Just change arXiv in any URL to alphaXiv to directly open the corresponding paper on the alphaXiv forum: you can accurately locate the paragraphs in the paper, Sentence: In the discussion area on the right, users can post questions to ask the author about the ideas and details of the paper. For example, they can also comment on the content of the paper, such as: "Given to
 Axiomatic training allows LLM to learn causal reasoning: the 67 million parameter model is comparable to the trillion parameter level GPT-4
Jul 17, 2024 am 10:14 AM
Axiomatic training allows LLM to learn causal reasoning: the 67 million parameter model is comparable to the trillion parameter level GPT-4
Jul 17, 2024 am 10:14 AM
Show the causal chain to LLM and it learns the axioms. AI is already helping mathematicians and scientists conduct research. For example, the famous mathematician Terence Tao has repeatedly shared his research and exploration experience with the help of AI tools such as GPT. For AI to compete in these fields, strong and reliable causal reasoning capabilities are essential. The research to be introduced in this article found that a Transformer model trained on the demonstration of the causal transitivity axiom on small graphs can generalize to the transitive axiom on large graphs. In other words, if the Transformer learns to perform simple causal reasoning, it may be used for more complex causal reasoning. The axiomatic training framework proposed by the team is a new paradigm for learning causal reasoning based on passive data, with only demonstrations
 A significant breakthrough in the Riemann Hypothesis! Tao Zhexuan strongly recommends new papers from MIT and Oxford, and the 37-year-old Fields Medal winner participated
Aug 05, 2024 pm 03:32 PM
A significant breakthrough in the Riemann Hypothesis! Tao Zhexuan strongly recommends new papers from MIT and Oxford, and the 37-year-old Fields Medal winner participated
Aug 05, 2024 pm 03:32 PM
Recently, the Riemann Hypothesis, known as one of the seven major problems of the millennium, has achieved a new breakthrough. The Riemann Hypothesis is a very important unsolved problem in mathematics, related to the precise properties of the distribution of prime numbers (primes are those numbers that are only divisible by 1 and themselves, and they play a fundamental role in number theory). In today's mathematical literature, there are more than a thousand mathematical propositions based on the establishment of the Riemann Hypothesis (or its generalized form). In other words, once the Riemann Hypothesis and its generalized form are proven, these more than a thousand propositions will be established as theorems, which will have a profound impact on the field of mathematics; and if the Riemann Hypothesis is proven wrong, then among these propositions part of it will also lose its effectiveness. New breakthrough comes from MIT mathematics professor Larry Guth and Oxford University
 The first Mamba-based MLLM is here! Model weights, training code, etc. have all been open source
Jul 17, 2024 am 02:46 AM
The first Mamba-based MLLM is here! Model weights, training code, etc. have all been open source
Jul 17, 2024 am 02:46 AM
The AIxiv column is a column where this site publishes academic and technical content. In the past few years, the AIxiv column of this site has received more than 2,000 reports, covering top laboratories from major universities and companies around the world, effectively promoting academic exchanges and dissemination. If you have excellent work that you want to share, please feel free to contribute or contact us for reporting. Submission email: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com. Introduction In recent years, the application of multimodal large language models (MLLM) in various fields has achieved remarkable success. However, as the basic model for many downstream tasks, current MLLM consists of the well-known Transformer network, which
