
 Technology peripherals
AI
Excellent Practice of 3D Reconstruction of Intelligent Driving on the Cloud
Technology peripherals
AI
Excellent Practice of 3D Reconstruction of Intelligent Driving on the Cloud
Excellent Practice of 3D Reconstruction of Intelligent Driving on the Cloud


The continuous development of intelligent driving technology is changing our travel methods and transportation systems. As one of the key technologies, 3D reconstruction plays an important role in intelligent driving systems. In addition to the perception and reconstruction algorithms of the car itself, the implementation and development of autonomous driving technology requires the support of huge cloud reconstruction capabilities. The Volcano Engine Multimedia Laboratory uses industry-leading self-developed 3D reconstruction technology, combined with powerful cloud platform resources and capabilities, to help The implementation and application of related technologies in scenarios such as large-scale reconstruction, automatic annotation, and realistic simulation on the cloud.
This article focuses on the principles and practices of the Volcano Engine Multimedia Laboratory's 3D reconstruction technology in dynamic and static scenes, as well as in combination with advanced light field reconstruction technology, to help everyone better understand and understand how intelligent 3D reconstruction on the cloud works. Serving the field of intelligent driving and assisting the development of the industry.
1. Technical challenges and difficulties
Driving scene reconstruction requires point cloud-level three-dimensional reconstruction of the road environment. Compared with traditional three-dimensional reconstruction technology application scenarios, driving scene reconstruction technology has the following Difficulty:
- The environmental factors during vehicle operation are complex and uncontrollable. Different weather, lighting, vehicle speed, road conditions, etc. will affect the data collected by the vehicle sensors, which will affect the reconstruction technology. Stickiness brings challenges.
- Feature degradation and texture loss often occur in road scenes. For example, the camera obtains image information without rich visual features, or the lidar obtains scene structure information with high similarity. At the same time, the road surface is used as One of the key elements in reconstruction is the single color and lack of sufficient texture information, which puts higher requirements on reconstruction technology.
- There are a large number of vehicle-mounted sensors. Common ones include cameras, lidar, millimeter wave radar, inertial navigation, GPS positioning system, wheel speedometer, etc. How to fuse data from multiple sensors to obtain more accurate reconstruction? As a result, reconstruction techniques are challenged.
- The existence of dynamic objects such as moving vehicles, non-motorized vehicles, and pedestrians on the road will bring challenges to traditional reconstruction algorithms. How to eliminate dynamic objects will cause interference to static scene reconstruction, and at the same time, the position and size of dynamic objects will be affected. , Estimating the speed is also one of the difficulties of the project.
2. Introduction to Driving Scene Reconstruction Technology
The reconstruction algorithm in the field of autonomous driving usually adopts a technical route based on lidar and cameras, supplemented by GPS and inertial navigation. LiDAR can directly obtain high-precision ranging information and quickly obtain scene structure. Through pre-lidar-camera joint calibration, the image obtained by the camera can give color, semantics and other information to the laser point cloud. At the same time, GPS and inertial navigation can assist in positioning and reduce drift caused by feature degradation during the reconstruction process. However, due to the high price of multi-line lidar, it is usually used in engineering vehicles and is difficult to be used on a large scale in mass-produced vehicles.
In this regard, the Volcano Engine Multimedia Laboratory has independently developed a set of purely visual driving scene reconstruction technologies, including static scene reconstruction, dynamic object reconstruction and neural radiation field reconstruction technology, which can distinguish dynamic and static objects in the scene. , restore the dense point cloud of the static scene, and highlight key elements such as road surfaces, signs, and traffic lights; it can effectively estimate the position, size, orientation, and speed of moving objects in the scene for subsequent 4D annotation; it can On the basis of static scene reconstruction, the neural radiation field is used to reconstruct and reproduce the scene to achieve free perspective roaming, which can be used for scene editing and simulation rendering. This technical solution does not rely on lidar and can achieve decimeter-level relative errors, achieving reconstruction effects close to lidar with minimal hardware cost.
2.1 Static scene reconstruction technology: eliminate dynamic interference and restore static scenes
Visual reconstruction technology is based on multi-view geometry and requires the scene or object to be reconstructed to have inter-frame consistency , that is, they are in a static state in different image frames, so dynamic objects need to be eliminated during the reconstruction process. According to the importance of different elements in the scene, irrelevant point clouds need to be removed from the dense point cloud, while some key element point clouds are retained. Therefore, the image needs to be semantically segmented in advance. In this regard, Volcano Engine The multimedia laboratory combines AI technology and the basic principles of multi-view geometry to build an advanced A robust, accurate and complete visual reconstruction algorithm framework. The reconstruction process includes three key steps : image preprocessing, sparse reconstruction and dense reconstruction .
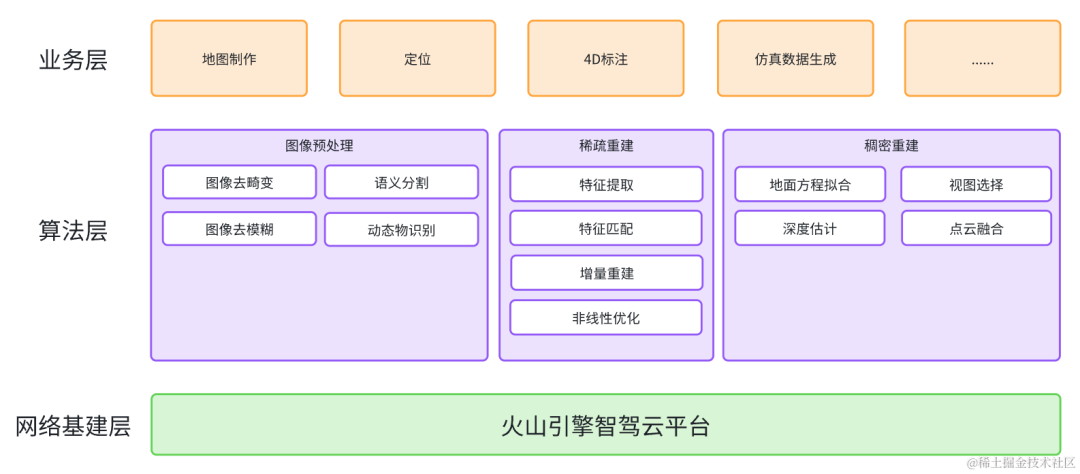
The vehicle-mounted camera is in motion during shooting. Due to the exposure time, serious motion blur will appear in the collected images as the vehicle speed increases. In addition, in order to save bandwidth and storage space, the image will be irreversibly lossy compressed during the transmission process, causing further degradation of image quality. To this end, the Volcano Engine Multimedia Laboratory uses an end-to-end neural network to deblur the image, which can improve image quality while suppressing motion blur. The comparison before and after deblurring is shown in the figure below.

Before deblurring (left) After deblurring (right)
In order to distinguish dynamic objects, the Volcano Engine Multimedia Laboratory Dynamic object recognition technology based on optical flow is used to obtain pixel-level dynamic object masks. In the subsequent static scene reconstruction process, feature points falling on the dynamic object area will be eliminated, and only static scenes and objects will be retained.

Optical flow (left) Moving object (right)
During the sparse reconstruction process, the camera's position, orientation and For scene point clouds, the SLAM algorithm (Simultaneous localization and mapping) and the SFM algorithm (Structure from Motion, referred to as SfM) are commonly used. The SFM algorithm can achieve higher reconstruction accuracy without requiring real-time performance. However, the traditional SFM algorithm usually treats each camera as an independent camera, while multiple cameras are usually arranged in different directions on the vehicle, and the relative positions between these cameras are actually fixed (ignoring the vehicle). subtle changes caused by vibration). If the relative position constraints between cameras are ignored, the calculated pose error of each camera will be relatively large. In addition, when occlusion is severe, the pose of individual cameras will be difficult to calculate. In this regard, the Volcano Engine Multimedia Laboratory self-developed an SFM algorithm based on the entire camera group, which can use the prior relative pose constraints between cameras to calculate the pose of the camera group as a whole, and also uses GPS plus inertial navigation. Fusion of positioning results to constrain the center position of the camera group can effectively improve the success rate and accuracy of pose estimation, improve point cloud inconsistencies between different cameras, and reduce point cloud layering.


Traditional SFM (left) Camera group SFM (right)
Due to the color of the ground Single and missing texture, it is difficult for traditional visual reconstruction to restore the complete ground. However, there are key elements on the ground such as lane lines, arrows, text/logos, etc. Therefore, the Volcano Engine Multimedia Laboratory uses quadratic surfaces to fit the ground to assist Perform depth estimation and point cloud fusion of ground areas. Compared with plane fitting, quadratic surface is more suitable for actual road scenes, because the actual road surface is often not an ideal plane. The following is a comparison of the effects of using plane equations and quadratic surface equations to fit the ground.

Plane equation (left) Quadratic surface equation (right)
Treat the laser point cloud as a true value, and The visual reconstruction results are superimposed with this to intuitively measure the accuracy of the reconstructed point cloud. As can be seen from the figure below, the fit between the reconstructed point cloud and the true point cloud is very high. After measurement, the relative error of the reconstruction result is about 15cm.

Volcano Engine Multimedia Laboratory reconstruction results (color) and ground truth point cloud (white)
The following is Volcano Engine Multimedia Comparison of the effects of the laboratory visual reconstruction algorithm and a mainstream commercial reconstruction software. It can be seen that compared with commercial software, the self-developed algorithm of the Volcano Engine Multimedia Laboratory has a better and more complete reconstruction effect. The street signs, traffic lights, telephone poles, as well as lane lines and arrows on the road in the scene have a very high degree of restoration. However, the reconstructed point cloud of commercial software is very sparse, and the road surface is missing in large areas.

A certain mainstream commercial software (left) Volcano Engine Multimedia Laboratory algorithm (right)
2.2 Dynamic reconstruction technology:
It is very difficult to 3D annotate objects on images. Point clouds are needed. When the vehicle only has a visual sensor, it can obtain the target object in the scene. Complete point clouds are difficult. Especially for dynamic objects, dense point clouds cannot be obtained using traditional 3D reconstruction techniques. In order to provide the expression of moving objects and serve 4D annotation, 3D bounding box (hereinafter referred to as 3D Bbox) is used to represent dynamic objects, and the 3D Bbox posture, size, and speed of dynamic objects in the scene at each moment are obtained through self-developed dynamic reconstruction algorithms. etc., thereby complementing the dynamic object reconstruction capability.
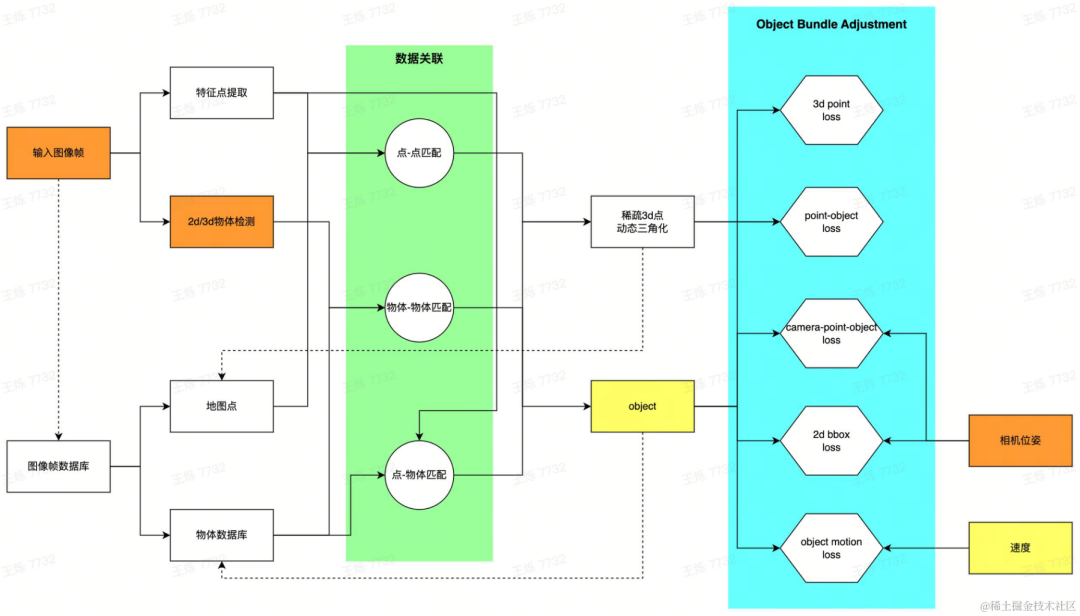
Dynamic reconstruction pipeline
For each frame of image collected by the vehicle, first extract the dynamic target in the scene and generate a 3d bbox The initial proposal provides two methods: using 2D target detection and estimating the corresponding 3D bbox through the camera pose; directly using 3D target detection. The two methods can be flexibly selected for different data. 2D detection has good generalization, and 3D detection can obtain better initial values. At the same time, feature points inside the dynamic area of the image are extracted. After obtaining the initial 3D bbox proposal and feature points of a single frame image, establish data correlation between multiple frames: establish object matching through a self-developed multi-target tracking algorithm, and match image features through feature matching technology. After obtaining the matching relationship, the image frames with common view relationships are created as local maps, and an optimization problem is constructed to solve the globally consistent target bbox estimation. Specifically, through feature point matching and dynamic triangulation technology, dynamic 3D points are restored; vehicle motion is modeled, and observations between objects, 3D points, and cameras are jointly optimized to obtain the optimal estimated dynamic object 3D bbox.

2d generates 3d (second from left) 3d target detection example
2.3 NeRF Reconstruction: photorealistic rendering, free perspective
Use neural network for implicit reconstruction, use differentiable rendering model, from existing views Learn how to render images from a new perspective for photorealistic image rendering: Neural Radiation Field (NeRF) technology. At the same time, implicit reconstruction has the characteristics of being editable and querying continuous space, and can be used for tasks such as automatic annotation and simulation data construction in autonomous driving scenarios. Scene reconstruction using NeRF technology is extremely valuable.
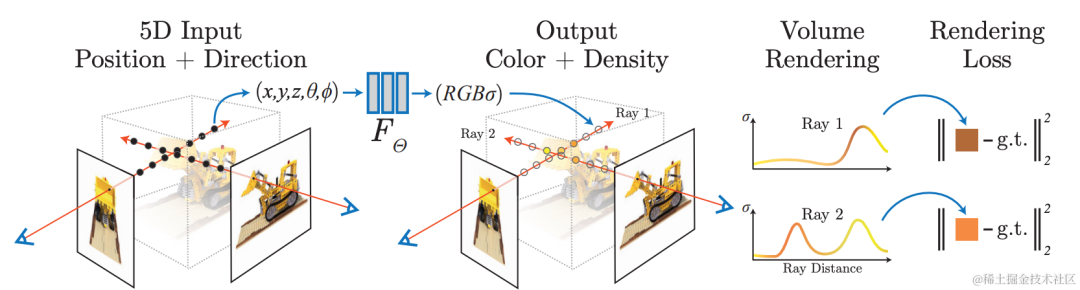
The Volcano Engine Multimedia Laboratory combines neural radiation field technology and large scene modeling technology. In specific practice, the data is first processed. Dynamic objects in the scene will cause artifacts in the NeRF reconstruction. With the help of self-developed dynamic and static segmentation, shadow detection and other algorithms, the areas in the scene that are inconsistent with the geometry are extracted and a mask is generated. At the same time, the video inpainting algorithm is used to repair the removed areas. With the help of self-developed 3D reconstruction capabilities, high-precision geometric reconstruction of the scene is performed, including camera parameter estimation and sparse and dense point cloud generation. In addition, the scenario is split to reduce single training resource consumption, and distributed training and maintenance can be performed. During the neural radiation field training process, for large outdoor borderless scenes, the team used some optimization strategies to improve the new perspective generation effect in this scene, such as improving the reconstruction accuracy by simultaneously optimizing poses during training, and based on the level of hash coding. Expression improves model training speed, appearance coding is used to improve the appearance consistency of scenes collected at different times, and mvs dense depth information is used to improve geometric accuracy. The team cooperated with HaoMo Zhixing to complete single-channel acquisition and multi-channel merged NeRF reconstruction. The relevant results were released on Haomo AI Day.

Dynamic object/shadow culling, filling
The above is the detailed content of Excellent Practice of 3D Reconstruction of Intelligent Driving on the Cloud. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 Cloud computing giant launches legal battle: Amazon sues Nokia for patent infringement
Jul 31, 2024 pm 12:47 PM
Cloud computing giant launches legal battle: Amazon sues Nokia for patent infringement
Jul 31, 2024 pm 12:47 PM
According to news from this site on July 31, technology giant Amazon sued Finnish telecommunications company Nokia in the federal court of Delaware on Tuesday, accusing it of infringing on more than a dozen Amazon patents related to cloud computing technology. 1. Amazon stated in the lawsuit that Nokia abused Amazon Cloud Computing Service (AWS) related technologies, including cloud computing infrastructure, security and performance technologies, to enhance its own cloud service products. Amazon launched AWS in 2006 and its groundbreaking cloud computing technology had been developed since the early 2000s, the complaint said. "Amazon is a pioneer in cloud computing, and now Nokia is using Amazon's patented cloud computing innovations without permission," the complaint reads. Amazon asks court for injunction to block
 Supporting NOA for unpictured cities, the Great Wall Wei brand Blue Mountain Smart Driving Edition is expected to be officially released in June
May 09, 2024 pm 09:10 PM
Supporting NOA for unpictured cities, the Great Wall Wei brand Blue Mountain Smart Driving Edition is expected to be officially released in June
May 09, 2024 pm 09:10 PM
According to reports on May 9, 2024, at this year’s Beijing International Auto Show, Wei Brand, a subsidiary of Great Wall Motors, launched a new model - the Blue Mountain Smart Driving Edition, which attracted the attention of many visitors. According to "Knowing Car Emperor's Vision", this highly anticipated new car is expected to officially land on the market in June this year. The design of the Blue Mountain Smart Driving Edition continues to follow the classic appearance of the Blue Mountain DHT-PHEV on sale, but it has been significantly upgraded in terms of intelligent driving perception. The most eye-catching thing is that a watchtower-style lidar is installed on the roof. At the same time, the vehicle is also equipped with 3 millimeter wave radars and 12 ultrasonic radars, as well as 11 high-definition visual perception cameras, for a total of 27 Assisted driving sensors greatly enhance the vehicle's environmental perception capabilities. according to
 The new Volkswagen Magotan B9 is about to be launched, with comprehensive upgrades to lead the new trend of intelligent driving
May 09, 2024 pm 05:50 PM
The new Volkswagen Magotan B9 is about to be launched, with comprehensive upgrades to lead the new trend of intelligent driving
May 09, 2024 pm 05:50 PM
According to news on May 9, 2007, since entering the Chinese market in 2007, the Volkswagen Magotan has sold more than 2 million cars in China by leveraging its exquisite craftsmanship and comprehensive performance derived from German prototypes, and has won the recognition of consumers. . Recently, the highly anticipated new generation of Volkswagen Magotan (B9 Magotan) will officially debut in June, bringing an all-round upgrade and innovation. The new Magotan has undergone drastic reforms in both exterior design and interior layout. The most significant change is that the new model adopts DJI’s cutting-edge intelligent driving technology, which significantly improves the intelligence level of autonomous driving and assisted driving. In terms of appearance design, the new Magotan’s more slender headlight design, combined with through-type light strips and illuminated LOGO, creates a wider visual effect on the front of the car.
 C++ Cloud Computing Best Practices: Deployment, Management, and Scalability Considerations
Jun 01, 2024 pm 05:51 PM
C++ Cloud Computing Best Practices: Deployment, Management, and Scalability Considerations
Jun 01, 2024 pm 05:51 PM
To achieve effective deployment of C++ cloud applications, best practices include: containerized deployment, using containers such as Docker. Use CI/CD to automate the release process. Use version control to manage code changes. Implement logging and monitoring to track application health. Use automatic scaling to optimize resource utilization. Manage application infrastructure with cloud management services. Use horizontal scaling and vertical scaling to adjust application capacity based on demand.
 Application alternatives of Golang technology in the field of cloud computing
May 09, 2024 pm 03:36 PM
Application alternatives of Golang technology in the field of cloud computing
May 09, 2024 pm 03:36 PM
Golang cloud computing alternatives include: Node.js (lightweight, event-driven), Python (ease of use, data science capabilities), Java (stable, high performance), and Rust (safety, concurrency). Choosing the most appropriate alternative depends on application requirements, ecosystem, team skills, and scalability.
 As demand grows in the artificial intelligence era, AWS, Microsoft, and Google continue to invest in cloud computing
May 06, 2024 pm 04:22 PM
As demand grows in the artificial intelligence era, AWS, Microsoft, and Google continue to invest in cloud computing
May 06, 2024 pm 04:22 PM
The growth of the three cloud computing giants shows no sign of slowing down until 2024, with Amazon, Microsoft, and Google all generating more revenue in cloud computing than ever before. All three cloud vendors have recently reported earnings, continuing their multi-year strategy of consistent revenue growth. On April 25, both Google and Microsoft announced their results. In the first quarter of Alphabet’s fiscal year 2024, Google Cloud’s revenue was US$9.57 billion, a year-on-year increase of 28%. Microsoft's cloud revenue was $35.1 billion, a year-over-year increase of 23%. On April 30, Amazon Web Services (AWS) reported revenue of US$25 billion, a year-on-year increase of 17%, ranking among the three giants. Cloud computing providers have a lot to be happy about, with the growth rates of the three market leaders over the past
 Drive smartly with trends, cross boundaries and get out of the circle! 2024 ChinaJoy Smart Travel Exhibition Area, Generation Z's Car Buying Guide!
May 07, 2024 pm 09:58 PM
Drive smartly with trends, cross boundaries and get out of the circle! 2024 ChinaJoy Smart Travel Exhibition Area, Generation Z's Car Buying Guide!
May 07, 2024 pm 09:58 PM
With the continuous advancement of technology, the performance of smart cars is getting better and better, and innovative functions are becoming increasingly rich, attracting the attention of more and more young consumers, and young people have also shown a high degree of acceptance and curiosity about new technologies. Heart. The 21st ChinaJoy in 2024 will be held at the Shanghai New International Expo Center from July 26 to July 29. The DreamCar in the hearts of Generation Z may appear here. Youth, the new label of smart cars: smart driving, technological gameplay, fresh design, and personalized needs. For young people, differentiation is more likely to make them excited than driving experience. And this differentiation has a negative impact on traditional cars that have been developed for many years. This is an important issue for corporate brands. As the market continues to mature and develop, many years of development have
 Integration of PHP REST API and cloud computing platform
Jun 04, 2024 pm 03:52 PM
Integration of PHP REST API and cloud computing platform
Jun 04, 2024 pm 03:52 PM
The advantages of integrating PHPRESTAPI with the cloud computing platform: scalability, reliability, and elasticity. Steps: 1. Create a GCP project and service account. 2. Install the GoogleAPIPHP library. 3. Initialize the GCP client library. 4. Develop REST API endpoints. Best practices: use caching, handle errors, limit request rates, use HTTPS. Practical case: Upload files to Google Cloud Storage using Cloud Storage client library.
