

From language models such as BERT, GPT and Flan-T5 to image models such as SAM and Stable Diffusion, Transformer is sweeping the world with rapid momentum, but people can't help but ask: Is Transformer the only choice?
A team of researchers from Stanford University and the State University of New York at Buffalo not only provides a negative answer to this question, but also proposes a new alternative technology: Monarch Mixer . Recently, the team published relevant papers and some checkpoint models and training codes on arXiv. By the way, this paper has been selected for NeurIPS 2023 and qualified for Oral Presentation.

Paper link: https://arxiv.org/abs/2310.12109
on GitHub The code address is: https://github.com/HazyResearch/m2
This method removes the high-cost attention and MLP in the Transformer and replaces it with the expressive Monarch matrix. This enables it to achieve better performance at lower cost in language and image experiments.
This is not the first time that Stanford University has proposed an alternative technology to Transformer. In June this year, another team from the school also proposed a technology called Backpack. Please refer to the Heart of Machine article "Stanford Training Transformer Alternative Model: 170 Million Parameters, Debiased, Controllable and Highly Interpretable." Of course, for these technologies to achieve real success, they need to be further tested by the research community and turned into practical and useful products in the hands of application developers
Let’s take a look at this paper An introduction to Monarch Mixer and some experimental results.
In the fields of natural language processing and computer vision, machine learning models can already handle longer sequences and higher dimensions. representation, thereby supporting longer context and higher quality. However, the time and space complexity of existing architectures exhibit a quadratic growth pattern in sequence length and/or model dimensions, which limits context length and increases scaling costs. For example, attention and MLP in Transformer scale quadratically with sequence length and model dimensionality.
In response to this problem, this research team from Stanford University and the State University of New York at Buffalo claims to have found a high-performance architecture whose complexity scales with sequence length and model dimension. The growth is sub-quadratic.
Their research is inspired by MLP-mixer and ConvMixer. These two studies observed that: Many machine learning models blend information along sequence and model dimensions as axes, and often use a single operator to operate on both axes
Looking for performance Strong, sub-quadratic, and hardware-efficient hybrid operators are difficult to implement. For example, MLP in MLP-mixer and convolutions in ConvMixer are both expressive, but they both scale quadratically with the input dimension. Some recent studies have proposed some sub-quadratic sequence hybrid methods. These methods use longer convolutions or state space models, and they all use FFT. However, the FLOP utilization of these models is very low and the model dimensionality is very low. It is still a second expansion. At the same time, there is some promising progress on sparse dense MLP layers without compromising quality, but some models may actually be slower than dense models due to lower hardware utilization.
Based on these inspirations, the research team proposed Monarch Mixer (M2), which uses an expressive sub-quadratic structured matrix: Monarch matrix
The Monarch matrix is a generalized Fast Fourier Transform (FFT) structure matrix. Research shows that it contains a variety of linear transformations, such as Hadamard transform, Toplitz matrix, AFDF matrix and convolution. These matrices can be parameterized by the product of block diagonal matrices. These parameters are called Monarch factors and are related to permutation interleaving.
They are calculated subquadratically: If the number of factors is set to p, then when the input length is N, the computational complexity is 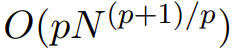 , so that the computational complexity can be located at O (N log N) when p = log N Between when p = 2.
, so that the computational complexity can be located at O (N log N) when p = log N Between when p = 2.
M2 uses a Monarch matrix to blend information along the sequence and model dimension axes. Not only is this approach easy to implement, it is also hardware efficient: Blocked diagonal Monarch factors can be computed efficiently using modern hardware that supports GEMM (Generalized Matrix Multiplication Algorithm).
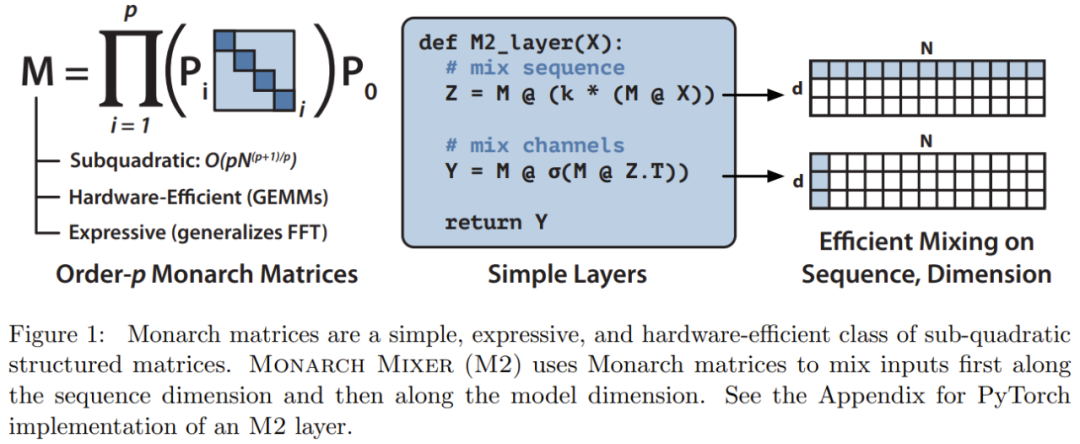
The research team implemented an M2 layer in less than 40 lines by writing code using PyTorch, and relied only on matrix multiplication, transpose, reshape and Element-wise product (see pseudocode in the middle of Figure 1). For an input size of 64k, these codes achieve a FLOP utilization of 25.6% on an A100 GPU. On newer architectures such as the RTX 4090, for the same size input, a simple CUDA implementation is able to achieve 41.4% FLOP utilization
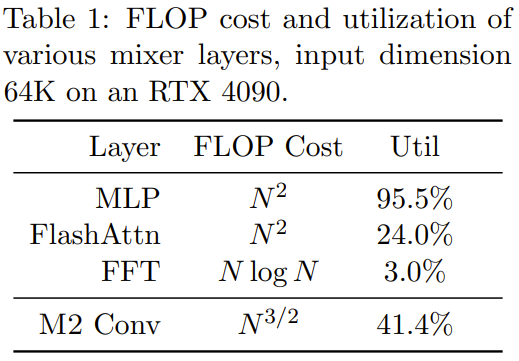
Related For more mathematical description and theoretical analysis of Monarch Mixer, please refer to the original paper.
The research team compared the two models, Monarch Mixer and Transformer, mainly focusing on Transformer's occupancy in three main tasks Dominance situations were studied. The three tasks are: BERT-style non-causal mask language modeling task, ViT-style image classification task and GPT-style causal language modeling task
In each task On the premise, the experimental results show that the newly proposed method can achieve a level comparable to Transformer without using attention and MLP. They also evaluated the speedup of the new method compared to the powerful Transformer baseline model in the BERT setting
Non-causal language modeling requires rewriting
For the need to rewrite tasks for non-causal language modeling, the team built an M2-based architecture: M2-BERT. M2-BERT can directly replace BERT-style language models, and BERT is a major application of the Transformer architecture. For the training of M2-BERT, masked language modeling on C4 is used, and the tokenizer is bert-base-uncased.
M2-BERT is based on the Transformer backbone, but the M2 layer replaces the attention layer and MLP, as shown in Figure 3
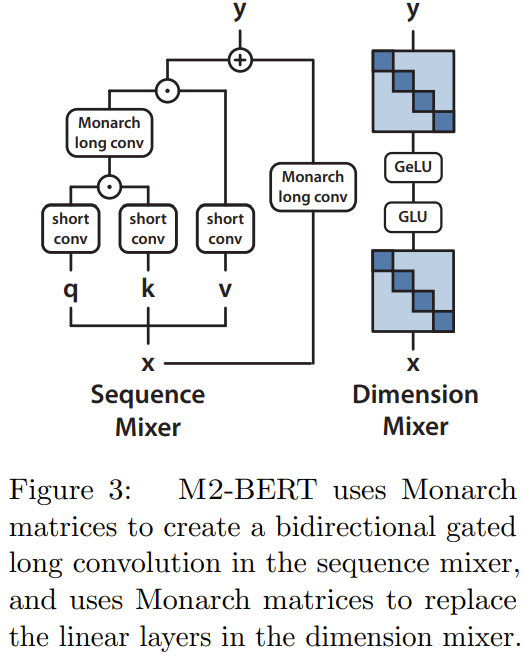
In the sequence mixer, attention is replaced by bidirectional gated convolution with residual convolution (see left side of Figure 3). To restore the convolution, the team set the Monarch matrix to a DFT and inverse DFT matrix. They also added depth-wise convolutions after the projection step.
In the dimension mixer, the two dense matrices of the MLP are replaced by the learned block diagonal matrices (the order of the Monarch matrix is 1, b=4)
The researcher conducted pre-training and obtained a total of 4 M2-BERT models: two of them are M2-BERT-base models with sizes of 80M and 110M respectively, and the other two are M2-BERT models with sizes of 80M and 110M respectively. The M2-BERT-large models are 260M and 341M respectively. These models are equivalent to BERT-base and BERT-large respectively
Table 3 shows the performance of the model equivalent to BERT-base, and Table 4 shows the performance equivalent to BERT-large performance of the model.
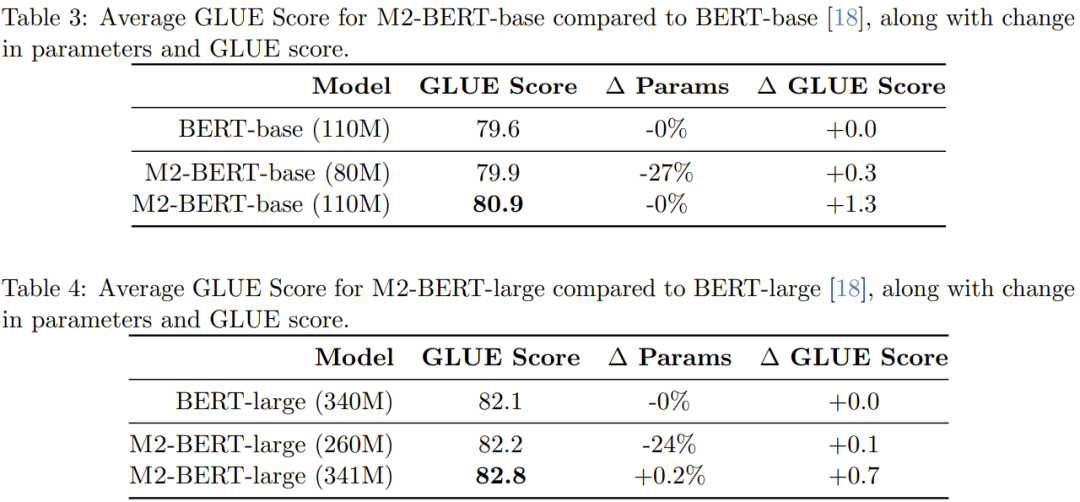
As can be seen from the table, on the GLUE benchmark, the performance of M2-BERT-base is comparable to BERT-base, while having fewer parameters 27%; when the number of parameters between the two is equal, M2-BERT-base outperforms BERT-base by 1.3 points. Similarly, M2-BERT-large, which has 24% fewer parameters, performs equally well as BERT-large, while with the same number of parameters, M2-BERT-large has a 0.7-point advantage.
Table 5 shows the forward throughput of models comparable to the BERT-base model. Reported is the number of tokens processed per millisecond on the A100-40GB GPU, which can reflect the inference time
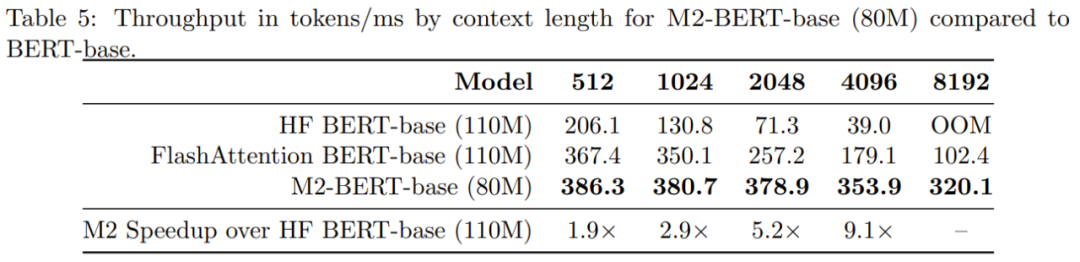
It can be seen that the throughput of M2-BERT-base even exceeds the highly optimized BERT model; compared to the standard HuggingFace implementation on a 4k sequence length, the throughput of M2-BERT-base can reach 9.1 times!
Table 6 gives the CPU inference time of M2-BERT-base (80M) and BERT-base - these results are implemented using PyTorch Running these two models directly gives the result
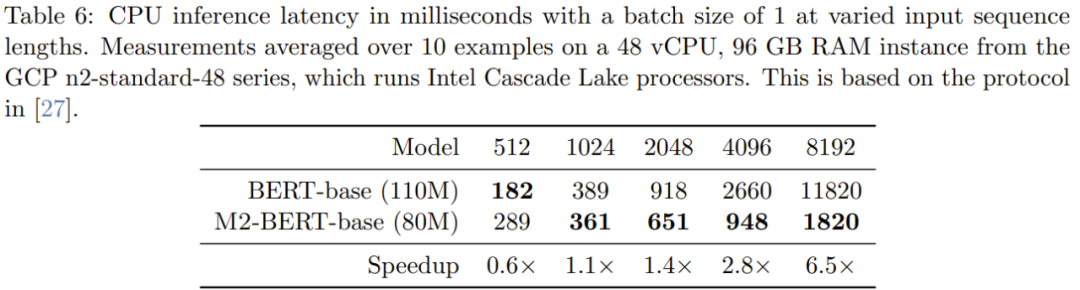
When the sequence is short, the impact of data locality still dominates the FLOP reduction, and operations such as filter generation (not found in BERT) are more expensive. When the sequence length exceeds 1K, the acceleration advantage of M2-BERT-base gradually increases. When the sequence length reaches 8K, the speed advantage can reach 6.5 times.
Image classification
In order to verify whether the advantages of the new method in the image field are the same as those in the language field, The team also evaluated the performance of M2 on image classification tasks, which was performed in terms of non-causal modeling
Table 7 presents Monarch Mixer, ViT-b, HyenaViT- b and ViT-b-Monarch (replacing the MLP module in standard ViT-b with a Monarch matrix) on ImageNet-1k.
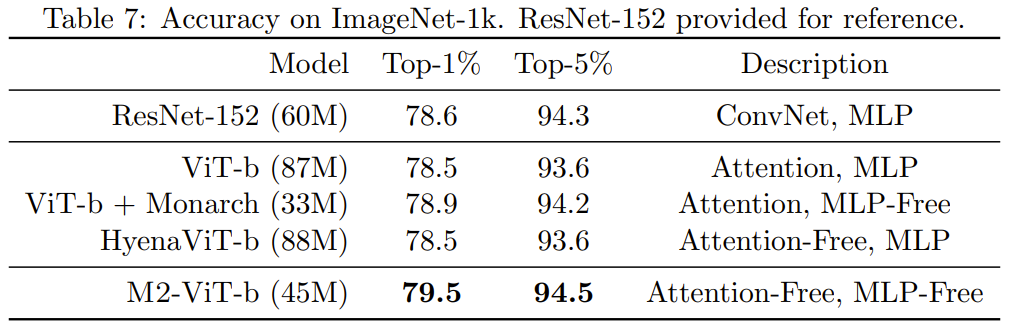
The advantage of Monarch Mixer is very obvious: it only requires half the number of parameters to surpass the original ViT-b model. Surprisingly, the Monarch Mixer with fewer parameters was even able to outperform ResNet-152, which was specifically designed for the ImageNet task
causal language modeling
GPT-style causal language modeling is an important application of Transformer. The team developed an M2-based architecture for causal language modeling, called M2-GPT
For the sequence mixer, M2-GPT uses a combination of convolutional filters from Hyena, Current state-of-the-art attention-free language models and cross-multiple parameter sharing from H3. They replaced the FFT in these architectures with causal parameterization and removed the MLP layer entirely. The resulting architecture is completely devoid of attention and completely devoid of MLP.
They pre-trained M2-GPT on PILE, a standard dataset for causal language modeling. The results are shown in Table 8.
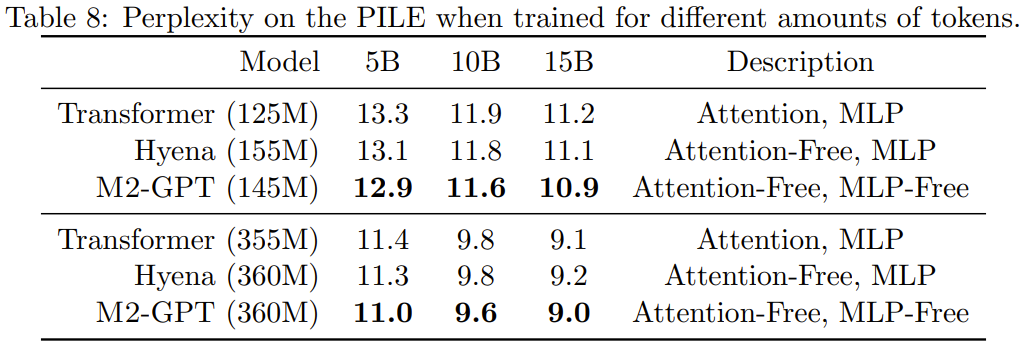
It can be seen that although the model based on the new architecture has no attention and MLP at all, it still wins in the pre-trained perplexity index. Through Transformer and Hyena. These results suggest that models that are very different from Transformer may also achieve excellent performance in causal language modeling.
Please refer to the original paper for more details
The above is the detailed content of Better than Transformer, BERT and GPT without Attention and MLPs are actually stronger.. For more information, please follow other related articles on the PHP Chinese website!
 Digital currency trading app
Digital currency trading app
 Apple store cannot connect
Apple store cannot connect
 How to solve the 0x0000006b blue screen
How to solve the 0x0000006b blue screen
 Detailed explanation of Symbol class in JS
Detailed explanation of Symbol class in JS
 Is Yiouoky a legal software?
Is Yiouoky a legal software?
 Detailed explanation of Linux fork function
Detailed explanation of Linux fork function
 Solution to gmail being blocked
Solution to gmail being blocked
 How to solve the problem that Apple cannot download more than 200 files
How to solve the problem that Apple cannot download more than 200 files
 The difference between scilab and matlab
The difference between scilab and matlab








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



