

This article is reprinted with the authorization of the Heart of Autonomous Driving public account. For reprinting, please contact the source of the original text
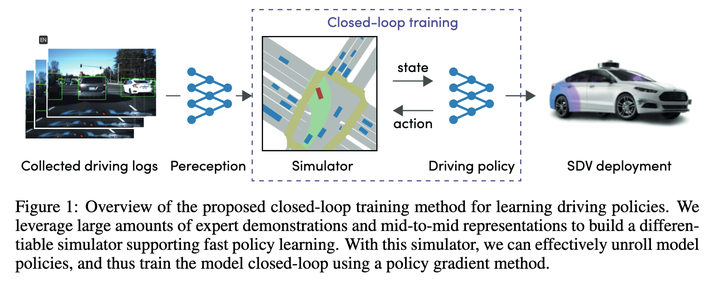
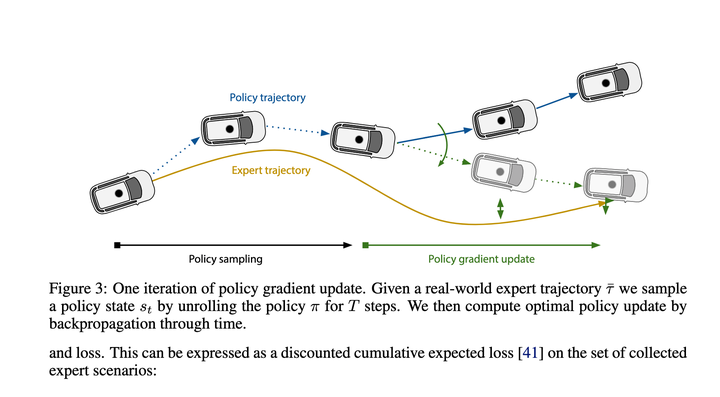 ## After a rough look, the main purpose is to use Policy Gradients to learn the mapping function of State->Recent Action. With this mapping function, the entire execution trajectory can be deduced step by step. In the end, the loss is to let this The trajectory given by the deduction is as close as possible to the expert trajectory.
## After a rough look, the main purpose is to use Policy Gradients to learn the mapping function of State->Recent Action. With this mapping function, the entire execution trajectory can be deduced step by step. In the end, the loss is to let this The trajectory given by the deduction is as close as possible to the expert trajectory.
The effect should be pretty good at the time, so it can become the baseline for new algorithms.
2. Nanyang Technological University Program 1 Conditional Predictive Behavior Planning with Inverse Reinforcement Learning 2023.04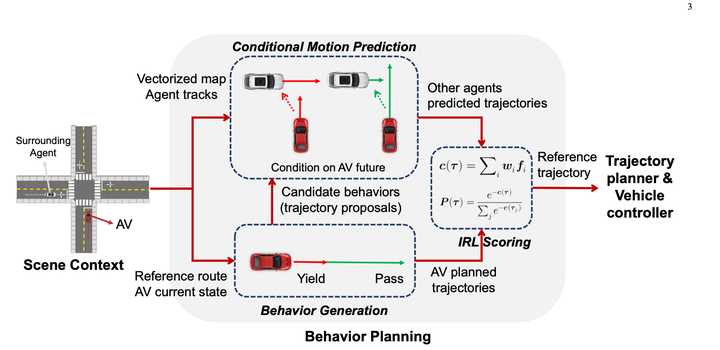 First use rules to enumerate many This behavior generated 10 to 30 trajectories. (Prediction results not used)
First use rules to enumerate many This behavior generated 10 to 30 trajectories. (Prediction results not used)
The Conditional Joint Prediction model looks like this:
 The basically great thing about this method is that it uses Conditional Joint Prediction to achieve good interactivity. The prediction gives the algorithm a certain gaming ability.
The basically great thing about this method is that it uses Conditional Joint Prediction to achieve good interactivity. The prediction gives the algorithm a certain gaming ability.
However, because there is one more dimension, after the number of subsequent expansions is too large, the solution space will still be large and the calculation amount will be too large. The method written in the current paper is to randomly discard the nodes after there are too many. Some nodes are added to ensure that the amount of calculation is controllable (it feels like it means that after too many nodes, it may be n levels later, and the impact may be smaller)
The main contribution of this article is to pass a continuous solution space through this tree shape The sampling rule transforms a Markov decision process, which is then solved using dp.
4. The latest joint plan of Nanyang Technological University and NVIDIA in October 2023: DTPP: Differentiable Joint Conditional Prediction and Cost Evaluation for Tree Policy Planning in Autonomous Driving1. Conditional Prediction ensures a certain gaming effect
2. It is derivable and can pass back the entire gradient so that prediction and IRL can be trained together. It is also a necessary condition for being able to build an end-to-end autonomous driving3. Tree Policy Planning, which may have certain interactive deduction capabilities
After reading it carefully, I found that this article is very informative and the method Very clever.
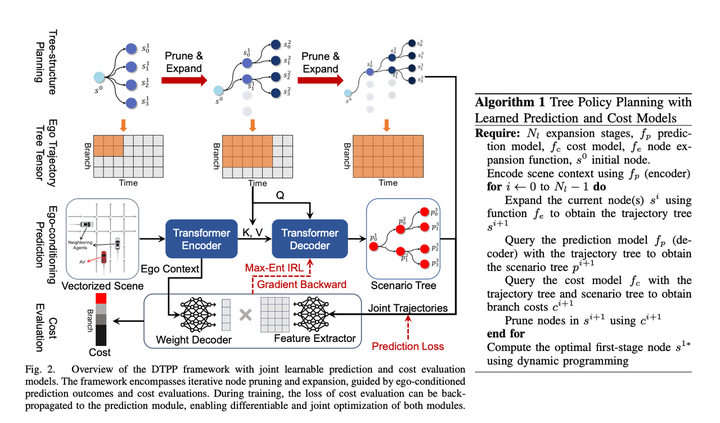 After combining and improving NVIDIA’s TPP and Nanyang Polytechnic’s Conditional Predictive Behavior Planning with Inverse Reinforcement Learning, we successfully solved the problem of poor candidate trajectories in the previous Nanyang Polytechnic paper. Question
After combining and improving NVIDIA’s TPP and Nanyang Polytechnic’s Conditional Predictive Behavior Planning with Inverse Reinforcement Learning, we successfully solved the problem of poor candidate trajectories in the previous Nanyang Polytechnic paper. Question
The main modules of the paper plan include:
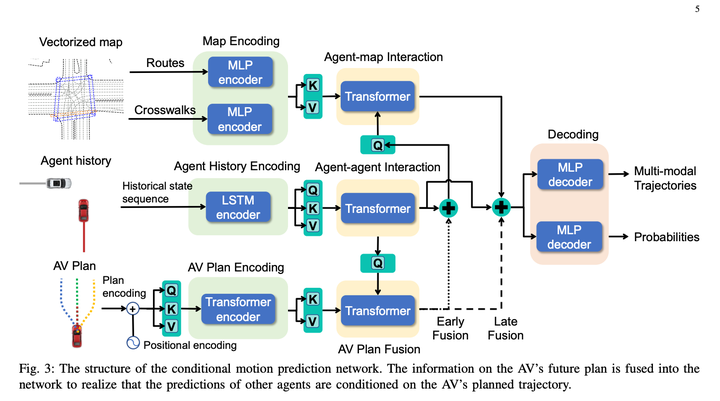
1. Conditional Prediction module, input a main vehicle historical trajectory prompt trajectory and obstacle vehicle historical trajectory, and give the predicted trajectory of the main vehicle approaching the prompt trajectory and The predicted trajectory of the obstacle vehicle is consistent with the behavior of the host vehicle.
2. The scoring module can score a main vehicle obstacle vehicle trajectory to see whether the trajectory resembles the behavior of an expert. The learning method is IRL.3. Tree Policy Search module, used to generate a bunch of candidate trajectories
Use the Tree Search algorithm to explore the feasible solution of the main vehicle. Each step in the exploration process takes the explored trajectory as input, uses the Conditional Prediction algorithm to generate the predicted trajectories of the main vehicle and the obstacle vehicle, and calls the scoring module to evaluate the trajectory. The pros and cons will affect the direction of the next search for expansion nodes. Through this method, you can generate some main vehicle trajectories that are different from other solutions, and consider the interaction with the obstacle vehicle when generating trajectories
Traditional IRL manually creates a lot of features. For example, in order to make the model differentiable, in this article, we directly use the ego context MLP of prediction to generate a Weight array (such as relative s, l and ttc) of a bunch of obstacles in the trajectory time dimension ( size = 1 * C), which implicitly represents the environmental information around the host vehicle, and then uses MLP to directly convert the multi-modal prediction results corresponding to the host vehicle trajectory into a Feature array (size = C * N, N refers to the candidate number of trajectories), and then the two matrices are multiplied to obtain the final trajectory score. Then IRL let the experts score the highest points. Personally, I feel that this may be for calculation efficiency, making the decoder as simple as possible, but there is still a certain loss of main vehicle information. If you do not pay attention to calculation efficiency, you can use some more complex networks to connect Ego Context and Predicted Trajectories, and the effect level should be better. good? Or if you give up differentiability, you can still consider adding manually set features, which should also improve the model effect.
In terms of time, this solution uses a method of re-encoding once and lightweight decoding multiple times, successfully reducing computing delays. The article points out that the delay can be compressed to 98 milliseconds
It belongs to the SOTA ranks among learning based planners, and the closed-loop effect is close to nuplan's No. 1 Rule Based scheme PDM mentioned in the previous article.
After looking at it, I feel that this paradigm is a pretty good idea. You can adjust the specific process yourself:

need to be rewritten The content is: Original link: https://mp.weixin.qq.com/s/ZJtMU3zGciot1g5BoCe9Ow
The above is the detailed content of A review of end-to-end planning methods for autonomous driving. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



