

At present, although great research progress has been made in human whole body pose and shape estimation (EHPS, Expressive Human Pose and Shape estimation), the most advanced methods are still limited by the limitations of the training data set.
Recently, researchers from Nanyang Technological University's S-Lab, SenseTime, Shanghai Artificial Intelligence Laboratory, University of Tokyo and IDEA Research Institute proposed for the first time the estimation of human body posture and body shape. SMPLer-X, a large motion capture model of the mission. The study used up to 4.5 million instances from different data sources to train the model, achieving the best performance on 7 key lists
SMPLer-X can not only Capture body movements, and also output facial and hand movements, and estimate body shape

Paper link: https://arxiv.org/ abs/2309.17448
Project homepage: https://caizhongang.github.io/projects/SMPLer-X/
With rich data and huge models, SMPLer-X shows strong performance in various tests and rankings, and has excellent versatility even in unknown environments
In terms of data expansion, The researchers conducted a comprehensive evaluation and analysis of 32 3D human body data sets to provide a reference for model training
2. In terms of model scaling, use visual large models to study increasing model parameters The improvement effect of quantity on performance
3. Through fine-tuning strategies, SMPLer-X general large model can be transformed into a dedicated large model, allowing it to achieve further performance improvement.

In summary, SMPLer-X has explored data scaling and model scaling (see Figure 1), and has performed on 32 academic data Ranked on the set and trained on its 4.5 million instances simultaneously, it achieved the best performance on 7 key lists including AGORA, UBody, EgoBody and EHF
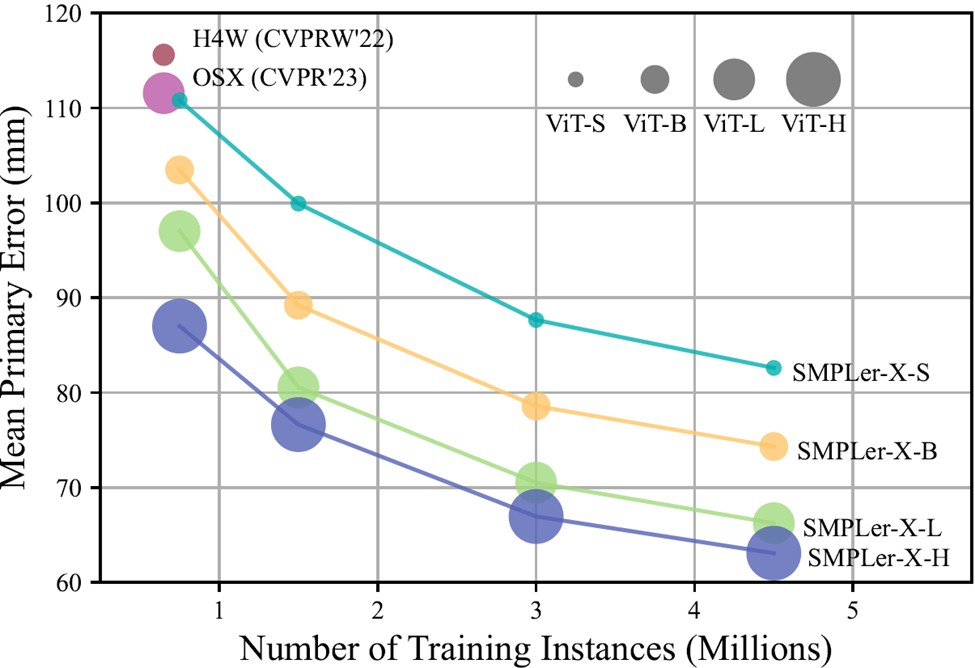
Figure 1 Increasing the amount of data and model parameters is effective in reducing the mean principal error (MPE) of the key lists (AGORA, UBody, EgoBody, 3DPW and EHF)
Conducting a generalization study on existing 3D human body datasets
Researchers conducted a generalization study on 32 academic datasets Ranking was performed: To measure the performance of each dataset, a model was trained using that dataset and the model was evaluated on five evaluation datasets: AGORA, UBody, EgoBody, 3DPW, and EHF.
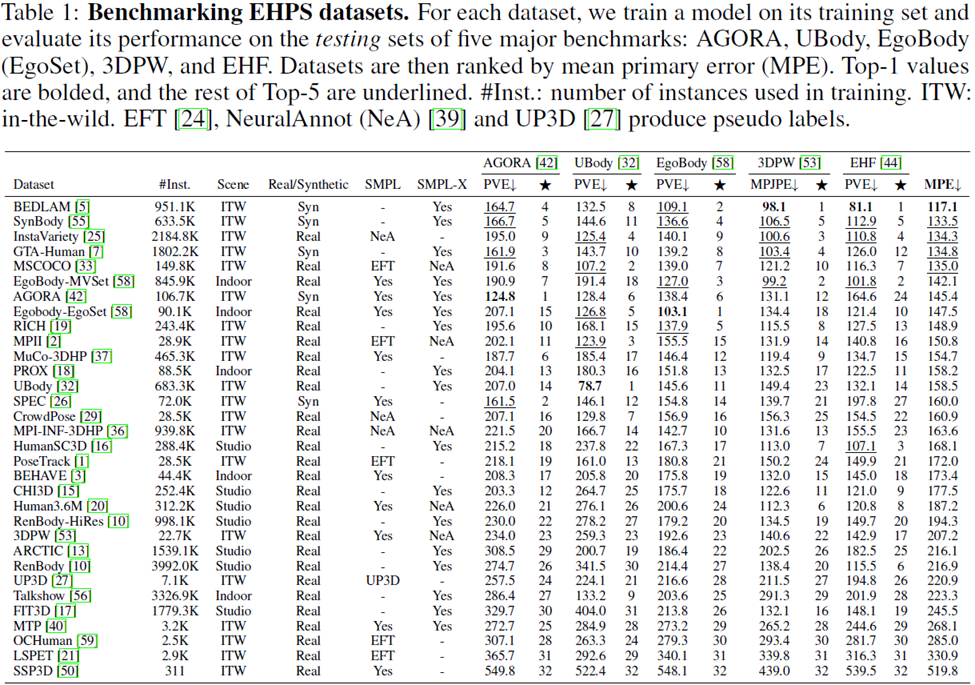
Mean Primary Error (MPE) is also calculated in the table to facilitate simple comparisons between various data sets.
Inspiration from studying the generalization of data sets
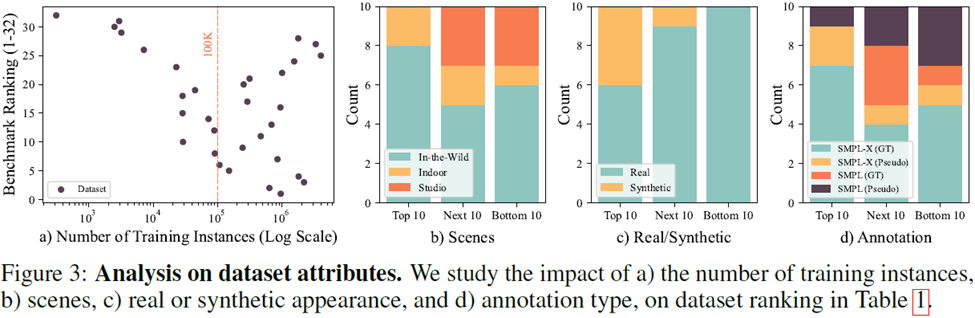
Passed From the analysis of a large number of data sets (see Figure 3), the following four conclusions can be drawn:
1. Regarding the data volume of a single data set, a data set of the order of 100,000 instances It can be used for model training to achieve higher cost performance;
2. Regarding the collection scenario of the data set, the In-the-wild data set has the best effect. If data can only be collected indoors, in order to improve the training effect, you need to avoid using data from a single scene
Regarding the collection of data sets, two of the top three data sets are generated data set. In recent years, generated data sets have demonstrated strong performance
Regarding the annotation of data sets, pseudo-labels also play a very important role in training
Today's state-of-the-art methods usually only use a few data sets (for example, MSCOCO, MPII and Human3.6M) for training, and this paper studies the use of More datasets
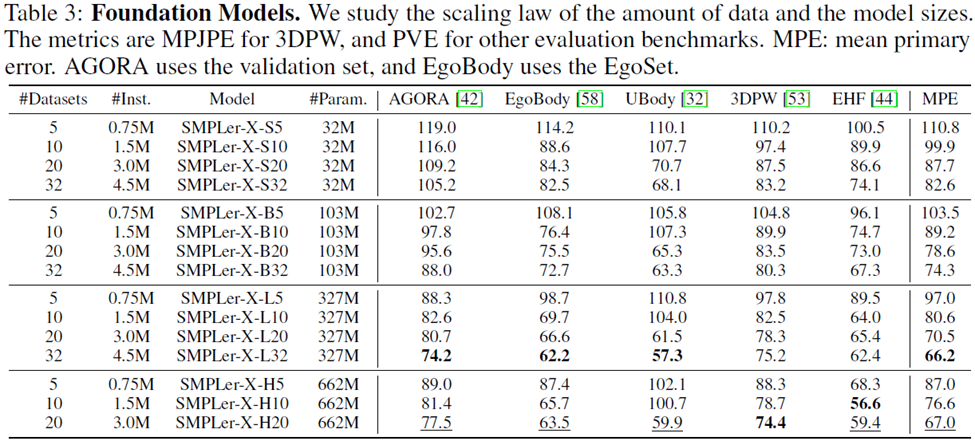
Considering that higher-ranked data sets are preferred, we used four different data sizes: 5, 10, 20 and 32 data sets as training sets, with a total size of 750,000, 1.5 million, 3 million and 4.5 million instances respectively
In addition, the researchers also demonstrated low-cost fine-tuning strategies to adapt general large models to specific Scenes.
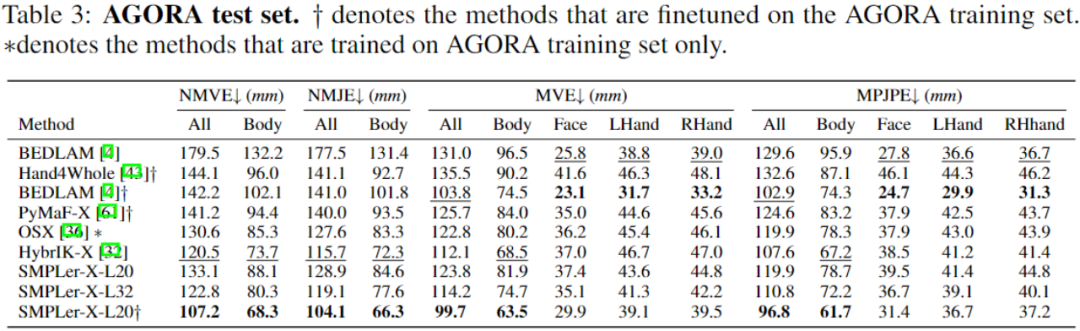
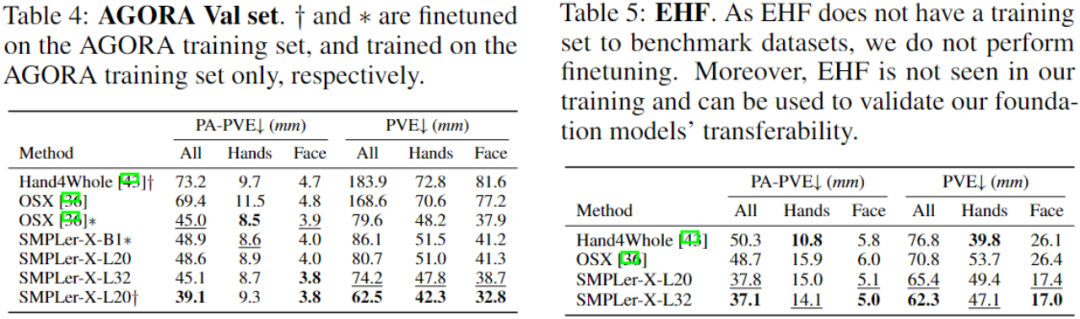
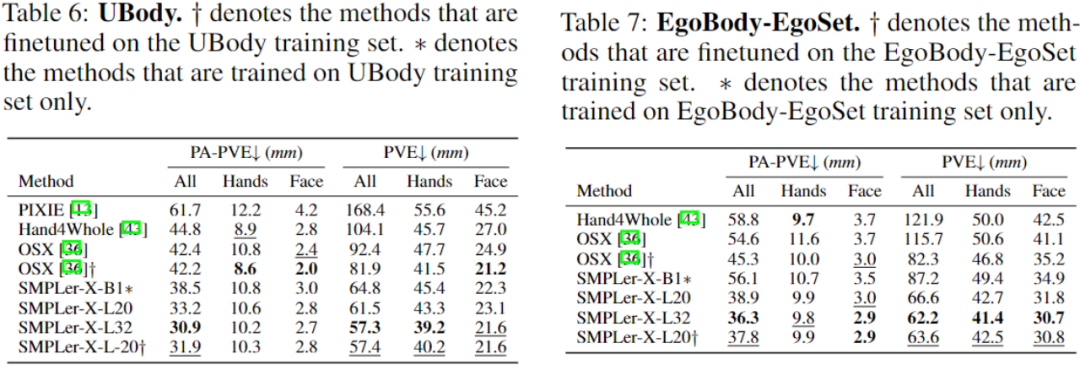
#The above table shows some of the main tests, such as AGORA Test set (Table 3), AGORA validation set (Table 4), EHF (Table 5), UBody (Table 6), EgoBody-EgoSet (Table 7).
In addition, the researchers also evaluated the generalization of the large motion capture model on two test sets, ARCTIC and DNA-Rendering
Researchers hope that SMPLer-X can bring inspiration beyond algorithm design and provide the academic community with a powerful full-body human motion capture large model.
The code and pre-trained model have been open sourced on the project homepage. Welcome to visit https://caizhongang.github.io/projects/SMPLer-X/ for more details
Result display


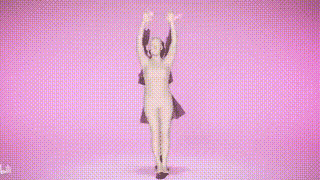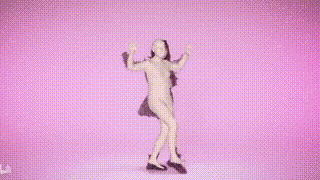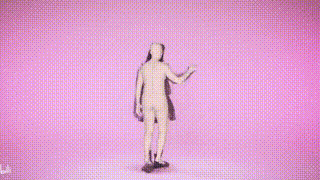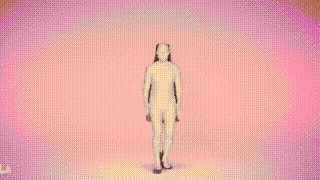



##
The above is the detailed content of SMPLer-X: Subverting the seven major lists, presenting the first human motion capture model!. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



