

Recently, the video of "Taylor Swift Showing off Chinese" quickly became popular on major social media, and later similar videos such as "Guo Degang Showing off English" appeared. Many of these videos are produced by an artificial intelligence application called "HeyGen"
# However, judging from HeyGen's current popularity, I would like to use it to produce similar videos You may have to wait in line for a long time. Fortunately, this is not the only way to make it. Friends who understand technology can also look for other alternatives, such as speech-to-text model Whisper, text translation GPT, voice cloning to generate audio so-vits-svc, and generation of mouth shape video that matches the audio GeneFace dengdeng.
The rewritten content is: Among them, Whisper is an automatic speech recognition (ASR) model developed and open sourced by OpenAI, which is very easy to use. They trained Whisper on 680,000 hours of multilingual (98 languages) and multi-task supervised data collected from the web. OpenAI believes that using such a large and diverse data set can improve the model's ability to recognize accents, background noise, and technical terms. In addition to speech recognition, Whisper can also transcribe multiple languages and translate them into English. Currently, Whisper has many variants and has become a necessary component when building many AI applications
Recently, the HuggingFace team proposed a new variant-Distil-Whisper. This variant is a distilled version of the Whisper model. It is characterized by its small size, fast speed, and very high accuracy. It is very suitable for use in environments that require low latency or have limited resources. However, unlike the original Whisper model that can handle multiple languages, Distil-Whisper can only handle English

Paper link: https://arxiv .org/pdf/2311.00430.pdf
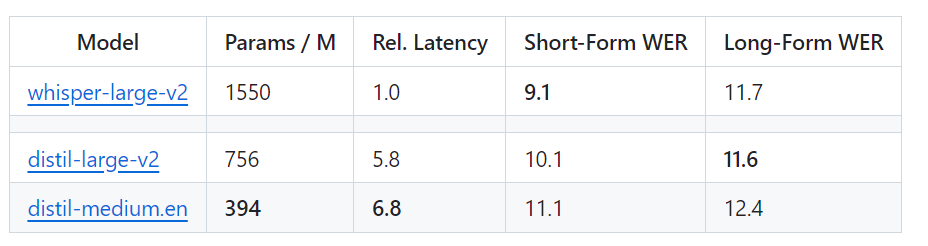
Specifically, Distil-Whisper has two versions, with parameter sizes of 756M (distil-large-v2) and 394M (distil- medium.en)
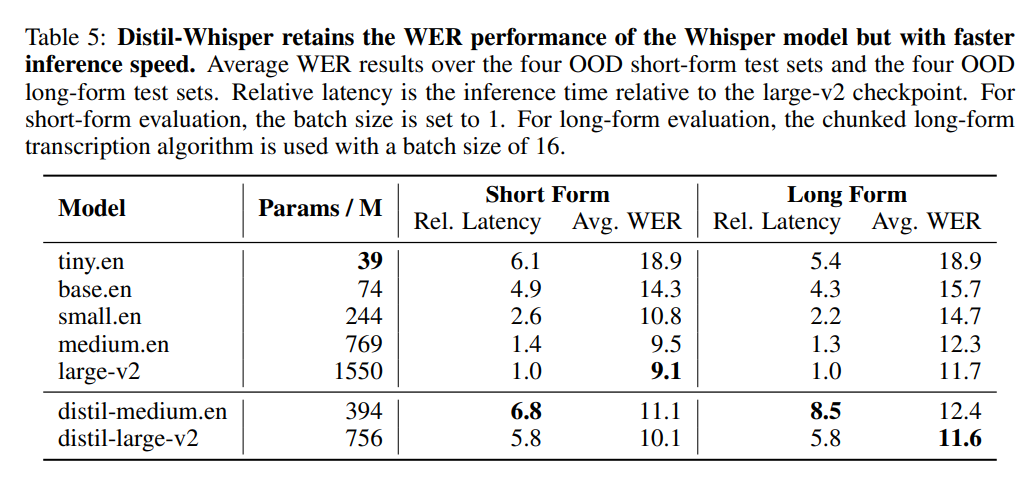
Compared with OpenAI's Whisper-large-v2, the 756M version of distil-large-v2 has more than half the parameters, but achieves 6 times acceleration , and the accuracy is very close to Whisper-large-v2. The difference in the Word Error Rate (WER) of short audio is within 1%, and it is even better than Whisper-large-v2 in long audio. This is because through careful data selection and filtering, Whisper's robustness is maintained and illusions are reduced.

The speed of the web version of Whisper is visually compared with that of Distil-Whisper. Image source: https://twitter.com/xenovacom/status/1720460890560975103
So, although it has only been released for two or three days, Distil-Whisper has already exceeded one thousand stars.
In addition, a test result shows that Distil-Whisper can be 2.5 times faster than Faster-Whisper when processing 150 minutes of audio
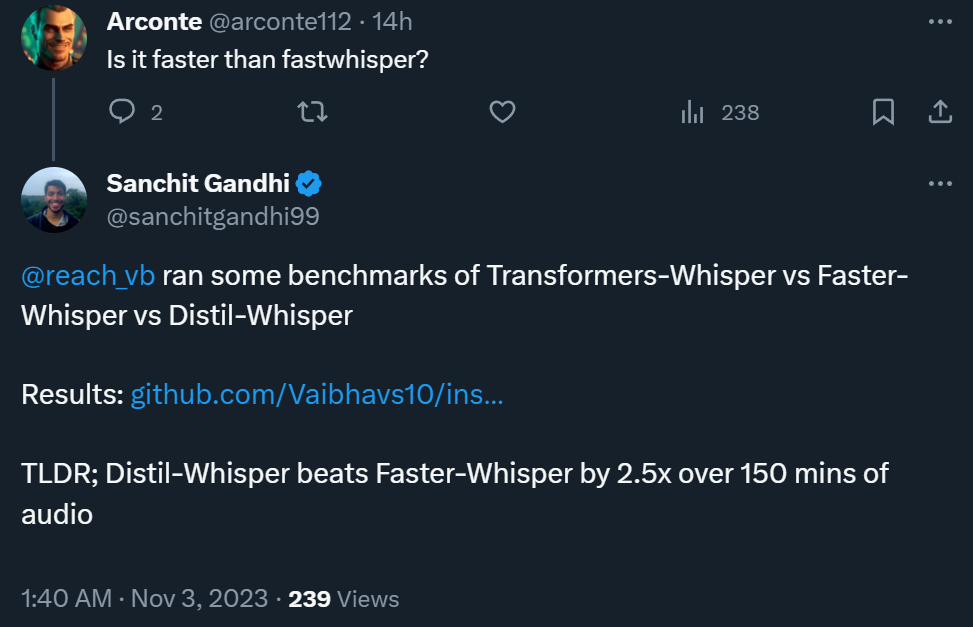
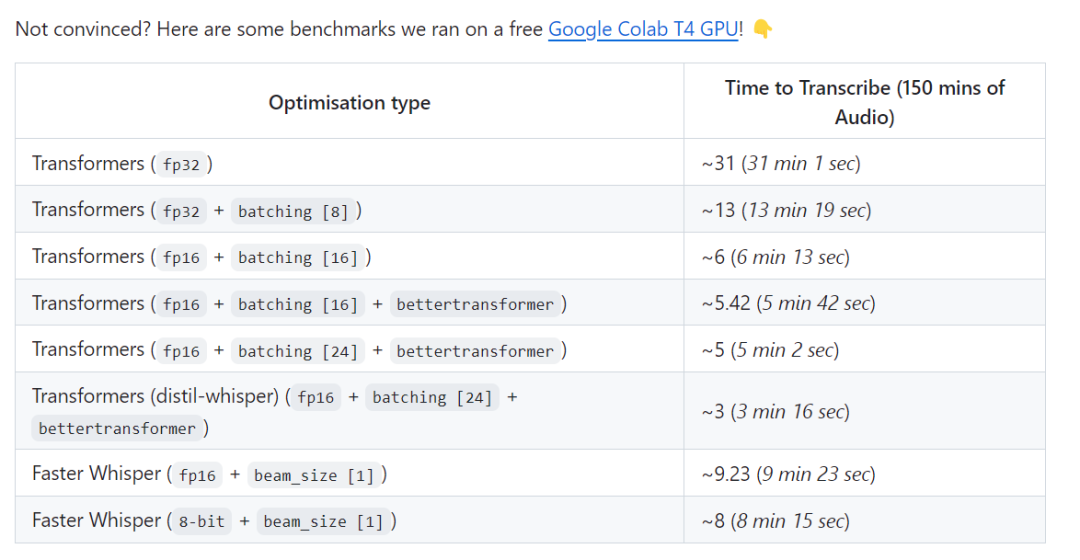
The test link is: https://github.com/Vaibhavs10/insanely-fast-whisper#insanely-fast-whisper
So, how is such a good result achieved? The authors of the paper stated that they used pseudo-labeling technology to build a large-scale open source data set, and then used this data set to compress the Whisper model into Distil-Whisper. They use a simple WER heuristic and only select the highest quality pseudo-labels for training
The following is a rewrite of the original content: The architecture of Distil-Whisper is shown in Figure 1 below. The researchers initialized the student model by copying the entire encoder from the teacher model and froze it during training. They copied the first and last decoder layers from OpenAI’s Whisper-medium.en and Whisper-large-v2 models, and obtained 2 decoder checkpoints after distillation, named distil-medium.en and The dimensional details of the model obtained by distil-large-v2
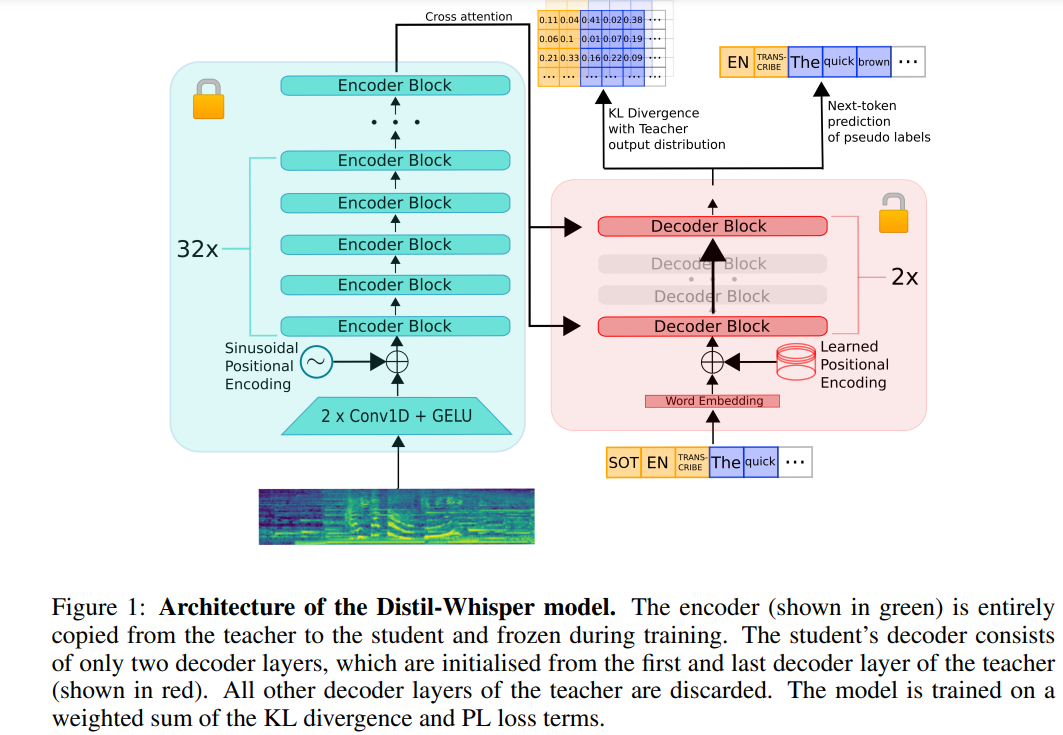
are shown in Table 3.
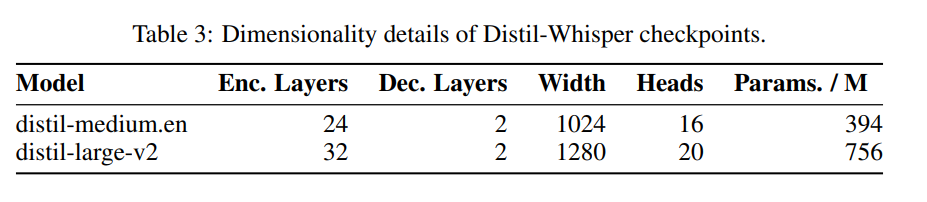
In terms of data, the model has been trained for 22,000 hours on 9 different open source datasets (see Table 2). Pseudo tags are generated by Whisper. It is worth noting that they used a WER filter and only tags with a WER score of more than 10% were retained. The author says this is key to maintaining performance!
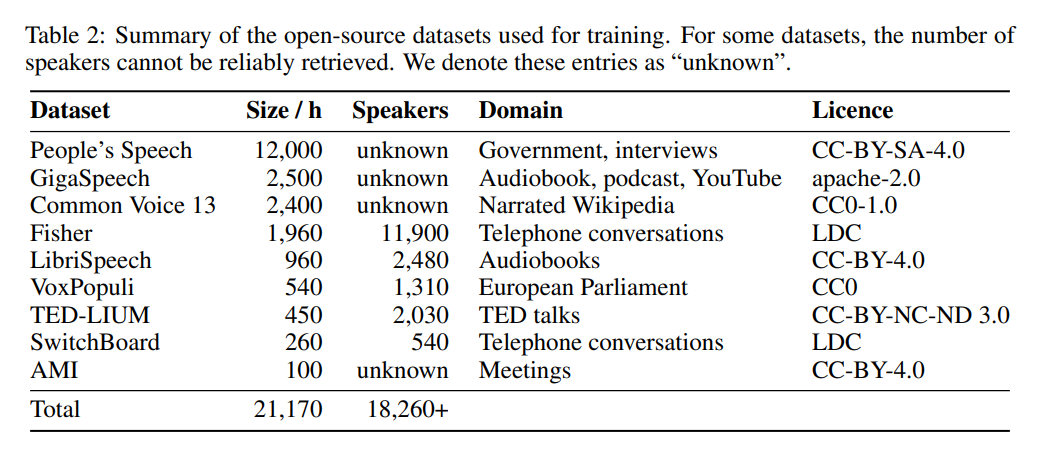
Table 5 below shows the main performance results of Distil-Whisper.
#According to the author, by freezing the operation of the encoder, Distil-Whisper performs very robustly against noise. As shown in the figure below, Distil-Whisper follows a similar robustness curve to Whisper under noisy conditions and performs better than other models such as Wav2vec2
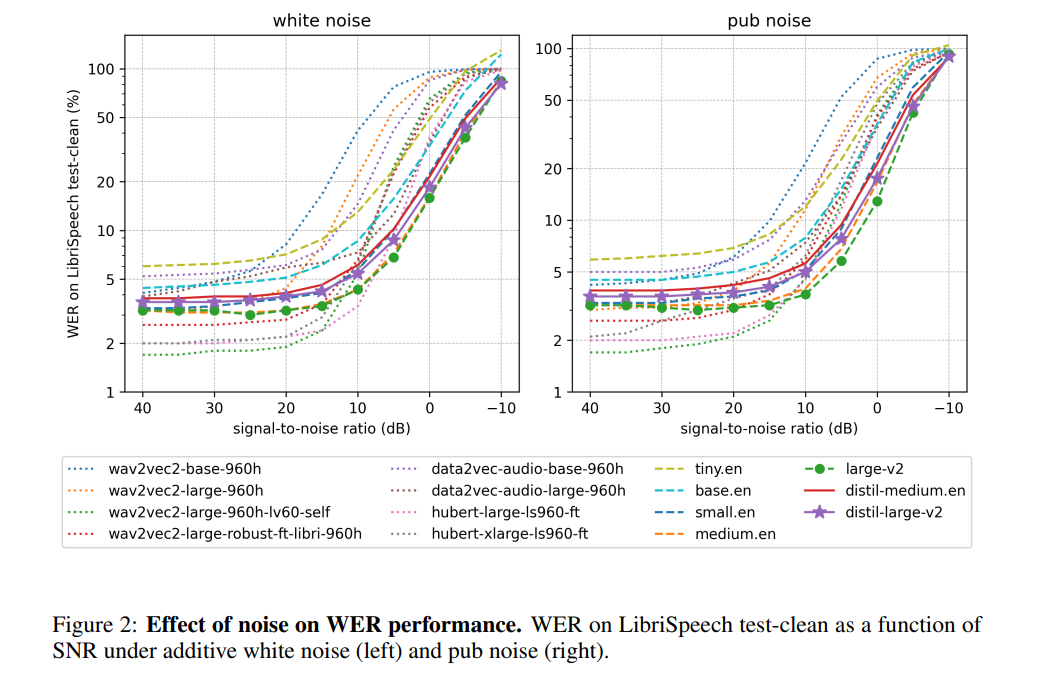
When processing relatively long audio files, compared with Whisper, Distil-Whisper effectively reduces hallucinations. According to the author, this is mainly due to WER filtering
By sharing the same encoder, Distil-Whisper can be paired with Whisper forSpeculative decoding(Speculative Decoding). This results in a 2x speedup with only an 8% increase in parameters while producing exactly the same output as Whisper.
Please see the original text for more details.
The above is the detailed content of After OpenAI's Whisper distillation, the speech recognition speed has been greatly improved: the number of stars exceeded 1,000 in two days. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



