
 Technology peripherals
AI
Microsoft launches 'Learn from Mistakes' model training method, claiming to 'imitate the human learning process and improve AI reasoning capabilities'
Technology peripherals
AI
Microsoft launches 'Learn from Mistakes' model training method, claiming to 'imitate the human learning process and improve AI reasoning capabilities'
Microsoft launches 'Learn from Mistakes' model training method, claiming to 'imitate the human learning process and improve AI reasoning capabilities'

Microsoft Research Asia, in conjunction with Peking University, Xi'an Jiaotong University and other universities, recently proposed an artificial intelligence training method called "Learning from Mistakes (LeMA)". This method claims to be able to improve the reasoning ability of artificial intelligence by imitating the human learning process
At present, large language models such as OpenAI GPT-4 and Google aLM-2 are widely used in natural language. It has good performance in processing (NLP) tasks and chain-of-thought (CoT) reasoning mathematical puzzle tasks.
But open source large models such as LLaMA-2 and Baichuan-2 need to be strengthened when dealing with related issues. In order to improve the thinking chain reasoning capabilities of these large open source language models, the research team proposed the LeMA method. This method mainly imitates the human learning process and improves the model's reasoning ability by "learning from mistakes".
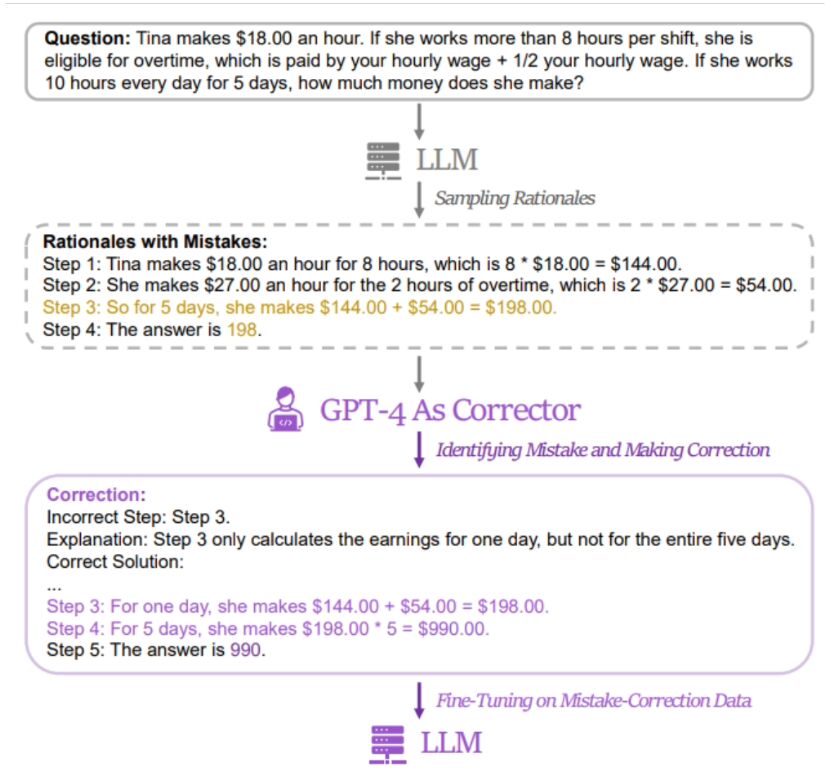
researcher’s method is to use a pair of "wrong answers" and "corrected answers" Correct answer" data to fine-tune the relevant model. In order to obtain relevant data, the researchers collected the wrong answers and reasoning processes of 5 different large language models (including LLaMA and GPT series), and then used GPT-4 as a "revisor" to provide corrected answers.
It is reported that the revised correct answer contains three types of information, namely the error fragments in the original reasoning process, the reasons for the error in the original reasoning process, and how to modify the original method to obtain the correct answer. The researchers used GSM8K and MATH to test the effect of the LeMa training method on 5 open source large models. The results show that in the improved LLaMA-2-70B model, the accuracy rates of GSM8K are 83.5% and 81.4% respectively, while the accuracy rates of MATH are 25.0% and 23.6% respectivelyCurrently, researchers have LeMA related information is public on GitHub. Interested friends canclick here to jump.
The above is the detailed content of Microsoft launches 'Learn from Mistakes' model training method, claiming to 'imitate the human learning process and improve AI reasoning capabilities'. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1377
1377
 52
52

 Step-by-step guide to using Groq Llama 3 70B locally
Jun 10, 2024 am 09:16 AM
Step-by-step guide to using Groq Llama 3 70B locally
Jun 10, 2024 am 09:16 AM
Translator | Bugatti Review | Chonglou This article describes how to use the GroqLPU inference engine to generate ultra-fast responses in JanAI and VSCode. Everyone is working on building better large language models (LLMs), such as Groq focusing on the infrastructure side of AI. Rapid response from these large models is key to ensuring that these large models respond more quickly. This tutorial will introduce the GroqLPU parsing engine and how to access it locally on your laptop using the API and JanAI. This article will also integrate it into VSCode to help us generate code, refactor code, enter documentation and generate test units. This article will create our own artificial intelligence programming assistant for free. Introduction to GroqLPU inference engine Groq
 The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Imagine an artificial intelligence model that not only has the ability to surpass traditional computing, but also achieves more efficient performance at a lower cost. This is not science fiction, DeepSeek-V2[1], the world’s most powerful open source MoE model is here. DeepSeek-V2 is a powerful mixture of experts (MoE) language model with the characteristics of economical training and efficient inference. It consists of 236B parameters, 21B of which are used to activate each marker. Compared with DeepSeek67B, DeepSeek-V2 has stronger performance, while saving 42.5% of training costs, reducing KV cache by 93.3%, and increasing the maximum generation throughput to 5.76 times. DeepSeek is a company exploring general artificial intelligence
 Seven Cool GenAI & LLM Technical Interview Questions
Jun 07, 2024 am 10:06 AM
Seven Cool GenAI & LLM Technical Interview Questions
Jun 07, 2024 am 10:06 AM
To learn more about AIGC, please visit: 51CTOAI.x Community https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou is different from the traditional question bank that can be seen everywhere on the Internet. These questions It requires thinking outside the box. Large Language Models (LLMs) are increasingly important in the fields of data science, generative artificial intelligence (GenAI), and artificial intelligence. These complex algorithms enhance human skills and drive efficiency and innovation in many industries, becoming the key for companies to remain competitive. LLM has a wide range of applications. It can be used in fields such as natural language processing, text generation, speech recognition and recommendation systems. By learning from large amounts of data, LLM is able to generate text
 Large models are also very powerful in time series prediction! The Chinese team activates new capabilities of LLM and achieves SOTA beyond traditional models
Apr 11, 2024 am 09:43 AM
Large models are also very powerful in time series prediction! The Chinese team activates new capabilities of LLM and achieves SOTA beyond traditional models
Apr 11, 2024 am 09:43 AM
The potential of large language models is stimulated - high-precision time series prediction can be achieved without training large language models, surpassing all traditional time series models. Monash University, Ant and IBM Research jointly developed a general framework that successfully promoted the ability of large language models to process sequence data across modalities. The framework has become an important technological innovation. Time series prediction is beneficial to decision-making in typical complex systems such as cities, energy, transportation, and remote sensing. Since then, large models are expected to revolutionize time series/spatiotemporal data mining. The general large language model reprogramming framework research team proposed a general framework to easily use large language models for general time series prediction without any training. Two key technologies are mainly proposed: timing input reprogramming; prompt prefixing. Time-
 The second generation Ameca is here! He can communicate with the audience fluently, his facial expressions are more realistic, and he can speak dozens of languages.
Mar 04, 2024 am 09:10 AM
The second generation Ameca is here! He can communicate with the audience fluently, his facial expressions are more realistic, and he can speak dozens of languages.
Mar 04, 2024 am 09:10 AM
The humanoid robot Ameca has been upgraded to the second generation! Recently, at the World Mobile Communications Conference MWC2024, the world's most advanced robot Ameca appeared again. Around the venue, Ameca attracted a large number of spectators. With the blessing of GPT-4, Ameca can respond to various problems in real time. "Let's have a dance." When asked if she had emotions, Ameca responded with a series of facial expressions that looked very lifelike. Just a few days ago, EngineeredArts, the British robotics company behind Ameca, just demonstrated the team’s latest development results. In the video, the robot Ameca has visual capabilities and can see and describe the entire room and specific objects. The most amazing thing is that she can also
 750,000 rounds of one-on-one battle between large models, GPT-4 won the championship, and Llama 3 ranked fifth
Apr 23, 2024 pm 03:28 PM
750,000 rounds of one-on-one battle between large models, GPT-4 won the championship, and Llama 3 ranked fifth
Apr 23, 2024 pm 03:28 PM
Regarding Llama3, new test results have been released - the large model evaluation community LMSYS released a large model ranking list. Llama3 ranked fifth, and tied for first place with GPT-4 in the English category. The picture is different from other benchmarks. This list is based on one-on-one battles between models, and the evaluators from all over the network make their own propositions and scores. In the end, Llama3 ranked fifth on the list, followed by three different versions of GPT-4 and Claude3 Super Cup Opus. In the English single list, Llama3 overtook Claude and tied with GPT-4. Regarding this result, Meta’s chief scientist LeCun was very happy and forwarded the tweet and
 The world's most powerful model changed hands overnight, marking the end of the GPT-4 era! Claude 3 sniped GPT-5 in advance, and read a 10,000-word paper in 3 seconds. His understanding is close to that of humans.
Mar 06, 2024 pm 12:58 PM
The world's most powerful model changed hands overnight, marking the end of the GPT-4 era! Claude 3 sniped GPT-5 in advance, and read a 10,000-word paper in 3 seconds. His understanding is close to that of humans.
Mar 06, 2024 pm 12:58 PM
The volume is crazy, the volume is crazy, and the big model has changed again. Just now, the world's most powerful AI model changed hands overnight, and GPT-4 was pulled from the altar. Anthropic released the latest Claude3 series of models. One sentence evaluation: It really crushes GPT-4! In terms of multi-modal and language ability indicators, Claude3 wins. In Anthropic’s words, the Claude3 series models have set new industry benchmarks in reasoning, mathematics, coding, multi-language understanding and vision! Anthropic is a startup company formed by employees who "defected" from OpenAI due to different security concepts. Their products have repeatedly hit OpenAI hard. This time, Claude3 even had a big surgery.
 Deploy large language models locally in OpenHarmony
Jun 07, 2024 am 10:02 AM
Deploy large language models locally in OpenHarmony
Jun 07, 2024 am 10:02 AM
This article will open source the results of "Local Deployment of Large Language Models in OpenHarmony" demonstrated at the 2nd OpenHarmony Technology Conference. Open source address: https://gitee.com/openharmony-sig/tpc_c_cplusplus/blob/master/thirdparty/InferLLM/docs/ hap_integrate.md. The implementation ideas and steps are to transplant the lightweight LLM model inference framework InferLLM to the OpenHarmony standard system, and compile a binary product that can run on OpenHarmony. InferLLM is a simple and efficient L
