
 Technology peripherals
AI
Let the AI model become a GTA five-star player, the vision-based programmable intelligent agent Octopus is here
Technology peripherals
AI
Let the AI model become a GTA five-star player, the vision-based programmable intelligent agent Octopus is here
Let the AI model become a GTA five-star player, the vision-based programmable intelligent agent Octopus is here

Video games have become a simulated stage for the real world, showing endless possibilities. Take "Grand Theft Auto" (GTA) as an example. In the game, players can experience the colorful life in the virtual city of Los Santos from a first-person perspective. However, since human players can enjoy playing in Los Santos and complete tasks, can we also have an AI visual model to control the characters in GTA and become the "player" who performs tasks? Can AI players in GTA play the role of a five-star good citizen who obeys traffic rules, helps the police catch criminals, or even be a helpful passerby, helping homeless people find suitable housing?
Current visual-language models (VLMs) have made substantial progress in multi-modal perception and reasoning, but they are usually based on simpler visual question answering (VQA) or visual annotation (Caption) tasks . However, these task settings obviously cannot enable VLM to actually complete tasks in the real world. Because actual tasks not only require the understanding of visual information, but also require the model to have the ability to plan reasoning and provide feedback based on real-time updated environmental information. At the same time, the generated plan also needs to be able to manipulate entities in the environment to realistically complete the task
Although existing language models (LLMs) can perform task planning based on the provided information, they cannot understand visual input. This greatly limits the application scope of language models when performing specific real-world tasks, especially for some embodied intelligence tasks. Text-based input is often too complex or difficult to elaborate, which makes the language model unable to efficiently extract information from it to complete the task. At present, language models have been explored in program generation, but the exploration of generating structured, executable, and robust codes based on visual input has not yet been deeply explored.
In order to solve the problem of how to make large models embodied intelligence To solve the problem of creating autonomous and situation-aware systems that can accurately make plans and execute commands, scholars from Nanyang Technological University in Singapore, Tsinghua University, etc. proposed Octopus. Octopus is a vision-based programmable agent that aims to learn through visual input, understand the real world, and complete various practical tasks by generating executable code. By training on large amounts of data pairs of visual input and executable code, Octopus learned how to control video game characters to complete game tasks or complete complex household activities.

Paper link: https://arxiv.org/abs/2310.08588
Project web page: https://choiszt.github.io/Octopus/
Open source code link: https://github.com/dongyh20/Octopus
The content that needs to be rewritten is: data collection and training Rewritten content: Data collection and training
In order to train a visual-language model that can complete embodied intelligence tasks, the researchers also developed OctoVerse, which contains two simulation systems for Provide training data and test environment for Octopus training. These two simulation environments provide available training and testing scenarios for the embodied intelligence of VLM, and put forward higher requirements for the model's reasoning and task planning capabilities. The details are as follows:
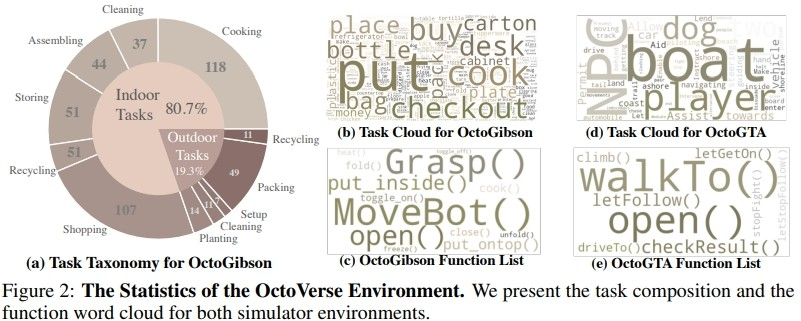
1. OctoGibson: Developed based on OmniGibson developed by Stanford University, it includes a total of 476 housework activities that are consistent with real life. The entire simulation environment includes 16 different categories of home scenarios, covering 155 instances of actual home environments. The model can manipulate a large number of interactive objects present in it to complete the final task.
2. OctoGTA: Developed based on the "Grand Theft Auto" (GTA) game, a total of 20 tasks were constructed and generalized into five different scenarios. Players are set at a fixed location through pre-set programs, and items and NPCs necessary to complete the mission are provided to ensure that the mission can proceed smoothly.
The figure below shows the task classification of OctoGibson and some statistical results of OctoGibson and OctoGTA.
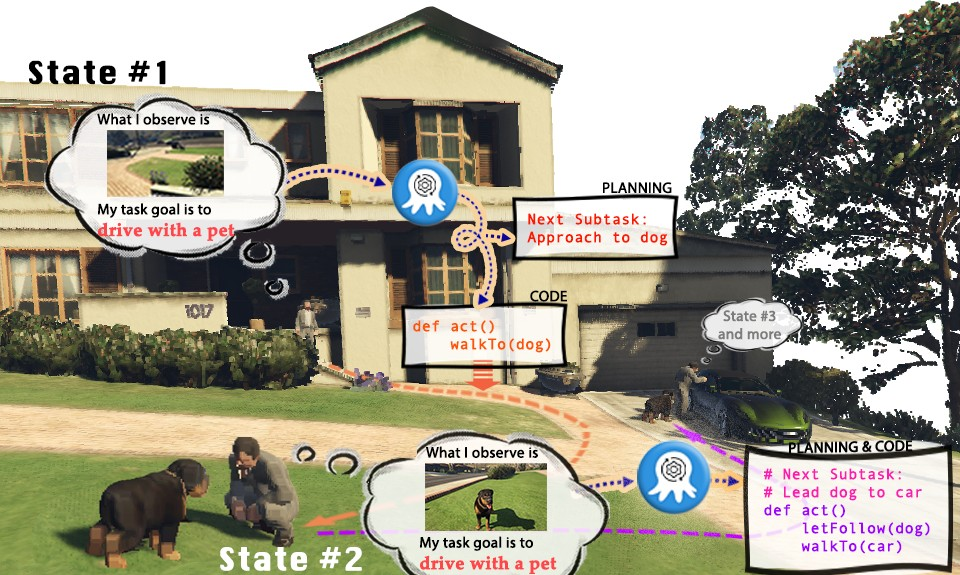
In order to efficiently collect training data in the two built simulation environments, the researchers established a complete data collection system. By introducing GPT-4 as the task executor, researchers use pre-implemented functions to convert visual input obtained from the simulation environment into textual information and provide it to GPT-4. After GPT-4 returns the task plan and executable code of the current step, it executes the code in the simulation environment and determines whether the task of the current step is completed. If successful, continue to collect visual input for the next step; if failed, return to the starting position of the previous step and collect data again
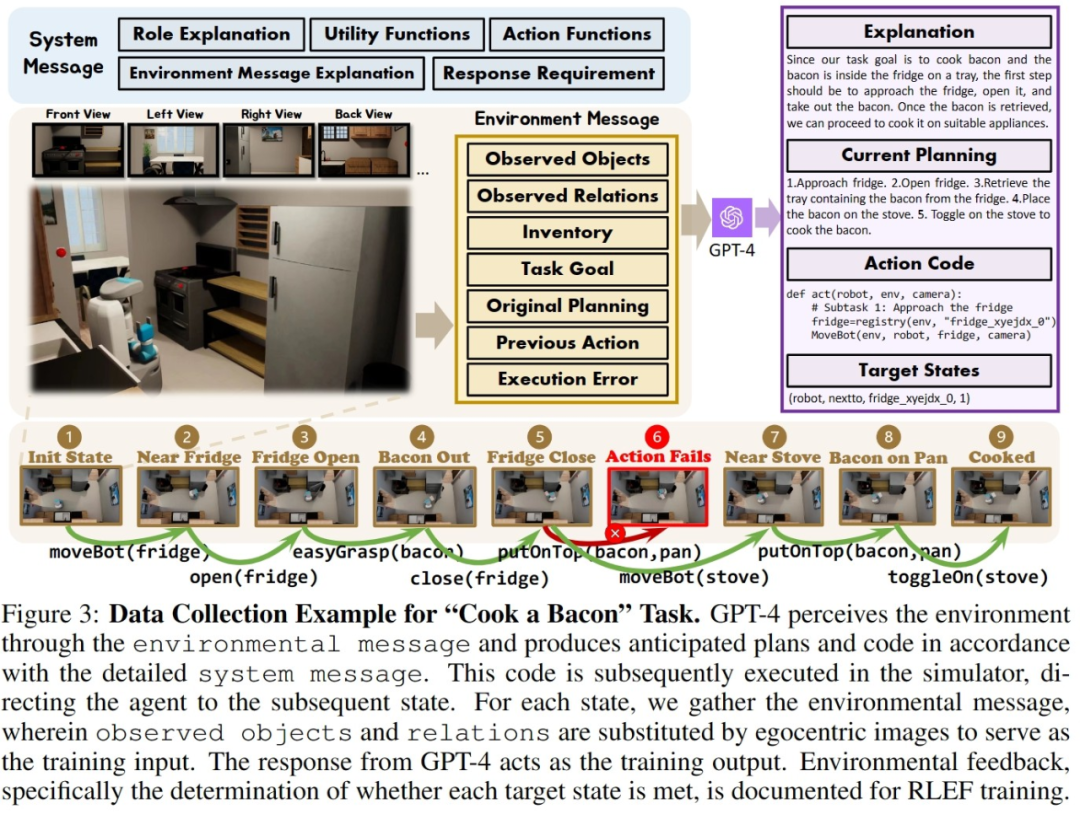
The above figure takes the Cook a Bacon task in the OctoGibson environment as an example to show the complete process of collecting data. It should be pointed out that during the process of collecting data, the researchers not only recorded the visual information during task execution, the executable code returned by GPT-4, etc., but also recorded the success of each sub-task, which will be used as follow-up Reinforcement learning is introduced to build the basis for a more efficient VLM. Although GPT-4 is powerful, it is not impeccable. Errors can manifest in a variety of ways, including syntax errors and physics challenges in the simulator. For example, as shown in Figure 3, between states #5 and #6, the action "put bacon on the pan" failed because the distance between the bacon held by the agent and the pan was too far. Such setbacks reset the task to its previous state. If a task is not completed after 10 steps, it is considered unsuccessful, we will terminate the task due to budget issues, and the data pairs of all subtasks of this task will be considered failed.
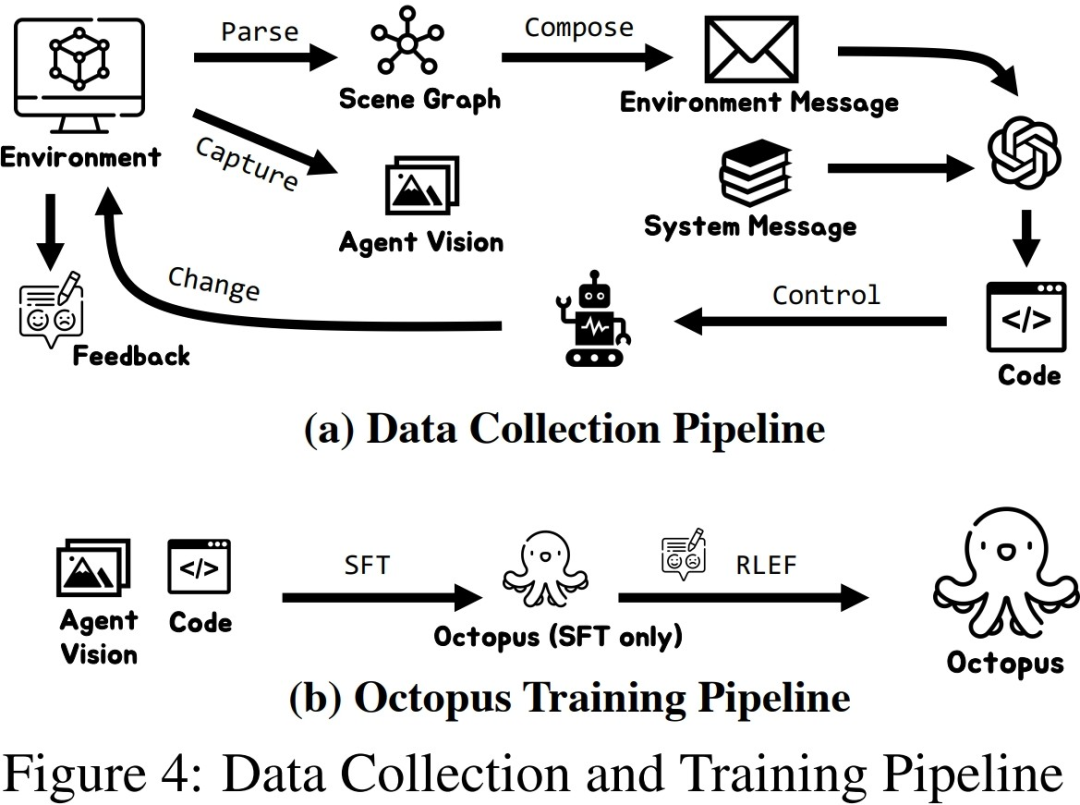
After the researchers collected a certain scale of training data, they used the data to train an intelligent visual-language model Octopus. The figure below shows the complete data collection and training process. In the first stage, by using the collected data for supervised fine-tuning, the researchers built a VLM model that can receive visual information as input and output in a fixed format. At this stage, the model is able to map visual input information into mission plans and executable code. In the second stage, the researchers introduced RLEF
, which uses reinforcement learning of environmental feedback to further enhance VLM's task planning capabilities by using the success of previously collected subtasks as reward signals to improve the success of the overall task. Rate
Experimental results
The researchers tested the current mainstream VLM and LLM in the built OctoGibson environment. The following table shows the main experimental results. For different test models, Vision Model lists the visual models used by different models. For LLM, researchers process visual information into text as the input of LLM. Among them, O represents providing information about interactive objects in the scene, R represents providing information about the relative relationships of objects in the scene, and GT represents using real and accurate information without introducing additional visual models for detection.
For all test tasks, the researchers reported the complete test integration power, and further divided it into four categories, respectively recording the completion of new tasks in scenarios that exist in the training set, and those that do not exist in the training set. The generalization ability to complete new tasks in different scenarios, as well as the generalization ability for simple following tasks and complex reasoning tasks. For each category of statistics, the researchers reported two evaluation indicators, the first of which is the task completion rate to measure the success rate of the model in completing embodied intelligence tasks; the second is the task planning accuracy, which is used to measure the success rate of the model in completing embodied intelligence tasks. Reflects the model's ability to perform task planning.
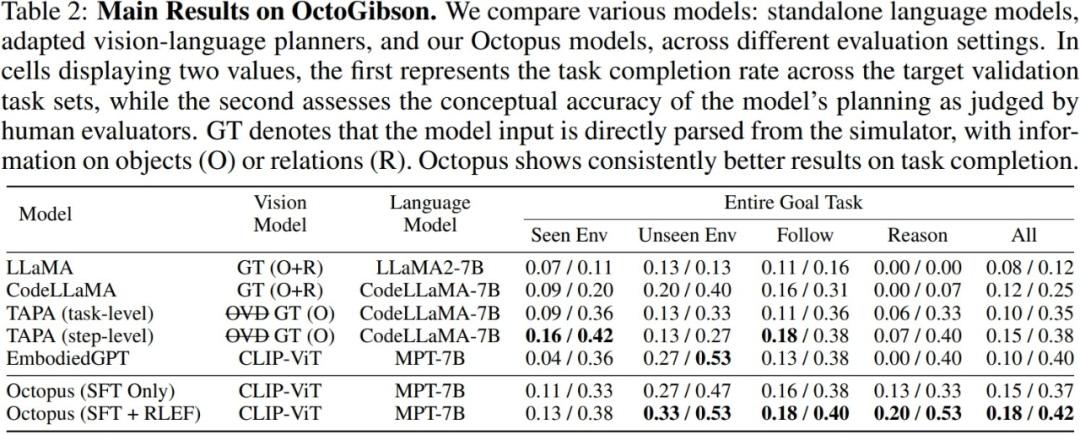
In addition, the researchers also demonstrated examples of the responses of different models to visual data collected in the OctoGibson simulation environment. The figure below shows the response after using three models of TAPA CodeLLaMA, Octopus and GPT-4V to generate visual input in OctoGibson. It can be seen that compared with the Octopus model and TAPA CodeLLaMA that only undergo supervised fine-tuning, the task planning of the Octopus model trained by RLEF is more reasonable. Even the more vague mission command "find a large bottle" provides a more complete plan. These performances further illustrate the effectiveness of the RLEF training strategy in improving the model's task planning capabilities and reasoning capabilities

Overall, the existing models performed well in the simulation environment There is still a lot of room for improvement in actual task completion and task planning capabilities. The researchers summarized some key findings:
1.CodeLLaMA can improve the model's code generation capabilities, but it cannot improve the task planning capabilities.
The researchers pointed out that the experimental results show that CodeLLaMA can significantly improve the code generation capability of the model. Compared with traditional LLM, using CodeLLaMA can obtain better and more executable code. However, although some models use CodeLLaMA to generate code, the overall mission success rate is still limited by mission planning capabilities. For models with weak task planning capabilities, although the generated code is more executable, the final task success rate is still lower. Looking back at Octopus, although CodeLLaMA is not used and the code executability is slightly reduced, due to its powerful task planning capabilities, the overall task success rate is still better than other models
When faced with a large amount of text information When input, LLM processing becomes relatively difficult
During the actual testing process, the researchers compared the experimental results of TAPA and CodeLLaMA and came to the conclusion that it is difficult for the language model to handle long text input well. Researchers follow the TAPA method and use real object information for task planning, while CodeLLaMA uses objects and the relative positional relationships between objects in order to provide more complete information. However, during the experiment, the researchers found that due to the large amount of redundant information in the environment, when the environment is more complex, the text input increases significantly, and it is difficult for LLM to extract valuable clues from the large amount of redundant information, thus reducing the Mission success rate. This also reflects the limitations of LLM, that is, if text information is used to represent complex scenes, a large amount of redundant and worthless input information will be generated.
3.Octopus shows good task generalization ability.
Octopus has strong task generalization capabilities, which can be known from experimental results. In new scenarios that did not appear in the training set, Octopus outperformed existing models in both task completion success rate and task planning success rate. This also shows that the visual-language model has inherent advantages in the same category of tasks, and its generalization performance is better than the traditional LLM
4.RLEF can enhance the task planning ability of the model.
The researchers provide a performance comparison of two models in the experimental results: one is the model that has undergone the first stage of supervised fine-tuning, and the other is the model that has been trained with RLEF. It can be seen from the results that after RLEF training, the overall success rate and planning ability of the model are significantly improved on tasks that require strong reasoning and task planning capabilities. Compared with existing VLM training strategies, RLEF is more efficient. The example plot shows that the model trained with RLEF improves in task planning. When faced with complex tasks, the model can learn to explore the environment; in addition, the model is more in line with the actual requirements of the simulation environment in terms of task planning (for example, the model needs to move to the object to be interacted before it can start interacting), thus reducing the task Risk of planning failure
Discussion
The content that needs to be rewritten is: melting test
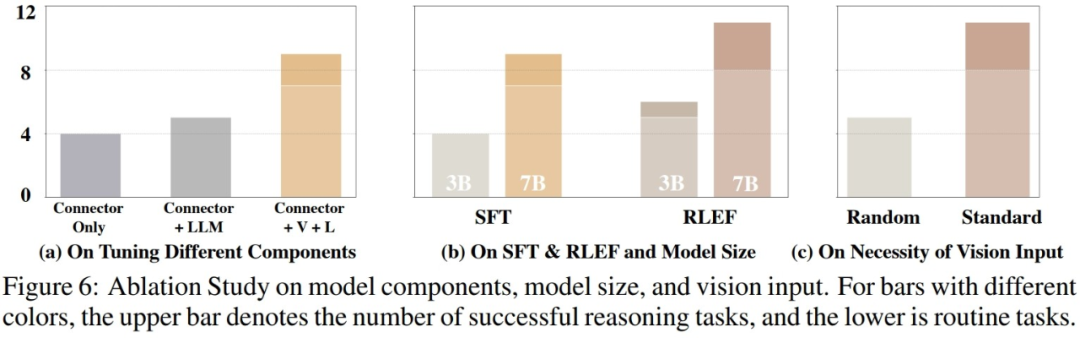
In testing the actual capabilities of the model After the evaluation, the researchers further explored possible factors affecting model performance. As shown in the figure below, the researchers conducted experiments from three aspects
The content that needs to be rewritten is: 1. The proportion of training parameters
The researchers conducted comparative experiments and compared training-only Performance of concatenated layers of visual and language models, training concatenated layers and language models, and fully trained models. The results show that as the training parameters increase, the performance of the model gradually improves. This shows that the number of training parameters is critical to whether the model can complete the task in some fixed scenarios
2. Model size
The researchers compared the smaller 3B parameter model with the baseline Performance difference of 7B model in two training stages. The comparison results show that when the overall parameter amount of the model is larger, the performance of the model will also be significantly improved. In future research in the field of VLM, how to select appropriate model training parameters to ensure that the model has the ability to complete the corresponding tasks while also ensuring the lightweight and fast inference speed of the model will be a very critical issue
What needs to be rewritten is: 3. Continuity of visual input. Rewritten content: 3. Coherence of visual input
In order to study the impact of different visual inputs on actual VLM performance, the researchers conducted experiments. During the test, the model rotates sequentially in the simulation environment and collects first-view images and two bird's-eye views, and then inputs these visual images into the VLM in sequence. In experiments, when researchers randomly disrupt the order of visual images and then input them into VLM, the performance of VLM suffers a greater loss. On the one hand, this illustrates the importance of complete and structured visual information to VLM. On the other hand, it also reflects that VLM needs to rely on the intrinsic connection between visual images when responding to visual input. Once this connection is destroyed, it will greatly Affects the performance of VLM
GPT-4
In addition, the researchers also tested GPT-4 and GPT-4V in the simulation environment The performance has been tested and statistically analyzed.
What needs to be rewritten is: 1. GPT-4
For GPT-4, during the test process, the researcher provides exactly the same text information as input when using it to collect training data. In the test task, GPT-4 can complete half of the tasks. On the one hand, this shows that the existing VLM still has a lot of room for improvement in performance compared to language models such as GPT-4; on the other hand, it also shows that even if It is a language model with strong performance such as GPT-4. When faced with embodied intelligence tasks, its task planning capabilities and task execution capabilities still need to be further improved.
The content that needs to be rewritten is: 2. GPT-4V
Since GPT-4V has just released an API that can be called directly, researchers have not had time to try it yet, but researchers have also manually tested some examples to demonstrate the performance of GPT-4V. Through some examples, researchers believe that GPT-4V has strong zero-sample generalization capabilities for tasks in the simulation environment, and can also generate corresponding executable code based on visual input, but it is slightly inferior to some task planning. The model is fine-tuned on the data collected in the simulation environment.
Summary
The researchers pointed out some limitations of the current work:
The current Octopus model does not perform well when handling complex tasks. When faced with complex tasks, Octopus often makes wrong plans and relies heavily on feedback information from the environment, making it difficult to complete the entire task
2. The Octopus model is only trained in the simulation environment, but how to use it Migrating to the real world will face a series of problems. For example, in the real environment, it will be difficult for the model to obtain more accurate relative position information of objects, and it will become more difficult to build an understanding of the scene by objects.
3. Currently, the visual input of octopus is discrete static pictures, and it will be a future challenge for it to be able to process continuous videos. Continuous videos can further improve the performance of the model in completing tasks, but how to efficiently process and understand continuous visual input will become the key to improving VLM performance
The above is the detailed content of Let the AI model become a GTA five-star player, the vision-based programmable intelligent agent Octopus is here. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1382
1382
 52
52

 The author of ControlNet has another hit! The whole process of generating a painting from a picture, earning 1.4k stars in two days
Jul 17, 2024 am 01:56 AM
The author of ControlNet has another hit! The whole process of generating a painting from a picture, earning 1.4k stars in two days
Jul 17, 2024 am 01:56 AM
It is also a Tusheng video, but PaintsUndo has taken a different route. ControlNet author LvminZhang started to live again! This time I aim at the field of painting. The new project PaintsUndo has received 1.4kstar (still rising crazily) not long after it was launched. Project address: https://github.com/lllyasviel/Paints-UNDO Through this project, the user inputs a static image, and PaintsUndo can automatically help you generate a video of the entire painting process, from line draft to finished product. follow. During the drawing process, the line changes are amazing. The final video result is very similar to the original image: Let’s take a look at a complete drawing.
 Topping the list of open source AI software engineers, UIUC's agent-less solution easily solves SWE-bench real programming problems
Jul 17, 2024 pm 10:02 PM
Topping the list of open source AI software engineers, UIUC's agent-less solution easily solves SWE-bench real programming problems
Jul 17, 2024 pm 10:02 PM
The AIxiv column is a column where this site publishes academic and technical content. In the past few years, the AIxiv column of this site has received more than 2,000 reports, covering top laboratories from major universities and companies around the world, effectively promoting academic exchanges and dissemination. If you have excellent work that you want to share, please feel free to contribute or contact us for reporting. Submission email: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com The authors of this paper are all from the team of teacher Zhang Lingming at the University of Illinois at Urbana-Champaign (UIUC), including: Steven Code repair; Deng Yinlin, fourth-year doctoral student, researcher
 Posthumous work of the OpenAI Super Alignment Team: Two large models play a game, and the output becomes more understandable
Jul 19, 2024 am 01:29 AM
Posthumous work of the OpenAI Super Alignment Team: Two large models play a game, and the output becomes more understandable
Jul 19, 2024 am 01:29 AM
If the answer given by the AI model is incomprehensible at all, would you dare to use it? As machine learning systems are used in more important areas, it becomes increasingly important to demonstrate why we can trust their output, and when not to trust them. One possible way to gain trust in the output of a complex system is to require the system to produce an interpretation of its output that is readable to a human or another trusted system, that is, fully understandable to the point that any possible errors can be found. For example, to build trust in the judicial system, we require courts to provide clear and readable written opinions that explain and support their decisions. For large language models, we can also adopt a similar approach. However, when taking this approach, ensure that the language model generates
 From RLHF to DPO to TDPO, large model alignment algorithms are already 'token-level'
Jun 24, 2024 pm 03:04 PM
From RLHF to DPO to TDPO, large model alignment algorithms are already 'token-level'
Jun 24, 2024 pm 03:04 PM
The AIxiv column is a column where this site publishes academic and technical content. In the past few years, the AIxiv column of this site has received more than 2,000 reports, covering top laboratories from major universities and companies around the world, effectively promoting academic exchanges and dissemination. If you have excellent work that you want to share, please feel free to contribute or contact us for reporting. Submission email: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com In the development process of artificial intelligence, the control and guidance of large language models (LLM) has always been one of the core challenges, aiming to ensure that these models are both powerful and safe serve human society. Early efforts focused on reinforcement learning methods through human feedback (RL
 arXiv papers can be posted as 'barrage', Stanford alphaXiv discussion platform is online, LeCun likes it
Aug 01, 2024 pm 05:18 PM
arXiv papers can be posted as 'barrage', Stanford alphaXiv discussion platform is online, LeCun likes it
Aug 01, 2024 pm 05:18 PM
cheers! What is it like when a paper discussion is down to words? Recently, students at Stanford University created alphaXiv, an open discussion forum for arXiv papers that allows questions and comments to be posted directly on any arXiv paper. Website link: https://alphaxiv.org/ In fact, there is no need to visit this website specifically. Just change arXiv in any URL to alphaXiv to directly open the corresponding paper on the alphaXiv forum: you can accurately locate the paragraphs in the paper, Sentence: In the discussion area on the right, users can post questions to ask the author about the ideas and details of the paper. For example, they can also comment on the content of the paper, such as: "Given to
 A significant breakthrough in the Riemann Hypothesis! Tao Zhexuan strongly recommends new papers from MIT and Oxford, and the 37-year-old Fields Medal winner participated
Aug 05, 2024 pm 03:32 PM
A significant breakthrough in the Riemann Hypothesis! Tao Zhexuan strongly recommends new papers from MIT and Oxford, and the 37-year-old Fields Medal winner participated
Aug 05, 2024 pm 03:32 PM
Recently, the Riemann Hypothesis, known as one of the seven major problems of the millennium, has achieved a new breakthrough. The Riemann Hypothesis is a very important unsolved problem in mathematics, related to the precise properties of the distribution of prime numbers (primes are those numbers that are only divisible by 1 and themselves, and they play a fundamental role in number theory). In today's mathematical literature, there are more than a thousand mathematical propositions based on the establishment of the Riemann Hypothesis (or its generalized form). In other words, once the Riemann Hypothesis and its generalized form are proven, these more than a thousand propositions will be established as theorems, which will have a profound impact on the field of mathematics; and if the Riemann Hypothesis is proven wrong, then among these propositions part of it will also lose its effectiveness. New breakthrough comes from MIT mathematics professor Larry Guth and Oxford University
 Axiomatic training allows LLM to learn causal reasoning: the 67 million parameter model is comparable to the trillion parameter level GPT-4
Jul 17, 2024 am 10:14 AM
Axiomatic training allows LLM to learn causal reasoning: the 67 million parameter model is comparable to the trillion parameter level GPT-4
Jul 17, 2024 am 10:14 AM
Show the causal chain to LLM and it learns the axioms. AI is already helping mathematicians and scientists conduct research. For example, the famous mathematician Terence Tao has repeatedly shared his research and exploration experience with the help of AI tools such as GPT. For AI to compete in these fields, strong and reliable causal reasoning capabilities are essential. The research to be introduced in this article found that a Transformer model trained on the demonstration of the causal transitivity axiom on small graphs can generalize to the transitive axiom on large graphs. In other words, if the Transformer learns to perform simple causal reasoning, it may be used for more complex causal reasoning. The axiomatic training framework proposed by the team is a new paradigm for learning causal reasoning based on passive data, with only demonstrations
 The first Mamba-based MLLM is here! Model weights, training code, etc. have all been open source
Jul 17, 2024 am 02:46 AM
The first Mamba-based MLLM is here! Model weights, training code, etc. have all been open source
Jul 17, 2024 am 02:46 AM
The AIxiv column is a column where this site publishes academic and technical content. In the past few years, the AIxiv column of this site has received more than 2,000 reports, covering top laboratories from major universities and companies around the world, effectively promoting academic exchanges and dissemination. If you have excellent work that you want to share, please feel free to contribute or contact us for reporting. Submission email: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com. Introduction In recent years, the application of multimodal large language models (MLLM) in various fields has achieved remarkable success. However, as the basic model for many downstream tasks, current MLLM consists of the well-known Transformer network, which
