
 Technology peripherals
AI
Let large AI models ask questions autonomously: GPT-4 breaks down barriers to talking to humans and demonstrates higher levels of performance
Technology peripherals
AI
Let large AI models ask questions autonomously: GPT-4 breaks down barriers to talking to humans and demonstrates higher levels of performance
Let large AI models ask questions autonomously: GPT-4 breaks down barriers to talking to humans and demonstrates higher levels of performance

In the latest trends in the field of artificial intelligence, the quality of artificially generated prompts has a decisive impact on the response accuracy of large language models (LLM). OpenAI proposes that precise, detailed, and specific questions are critical to the performance of these large language models. However, can ordinary users ensure that their questions are clear enough for LLM?
The content that needs to be rewritten is: It is worth noting that there is a significant difference between humans' natural understanding in certain situations and machine interpretation. For example, the concept of "even months" obviously refers to months such as February and April to humans, but GPT-4 may misunderstand it as months with an even number of days. This not only reveals the limitations of artificial intelligence in understanding everyday context, but also prompts us to reflect on how to communicate with these large language models more effectively. With the continuous advancement of artificial intelligence technology, how to bridge the gap in language understanding between humans and machines is an important topic for future research
Regarding this matter, the University of California, Los Angeles (UCLA) )’s General Artificial Intelligence Laboratory, led by Professor Gu Quanquan, released a research report proposing an innovative solution to the ambiguity problem in problem understanding of large language models (such as GPT-4). This research was completed by doctoral students Deng Yihe, Zhang Weitong and Chen Zixiang

- ## Paper address: https://arxiv.org/pdf/2311.04205.pdf
- Project address: https://uclaml.github.io/Rephrase-and -Respond
The rewritten Chinese content is: The core of this solution is to let a large language model repeat and expand the questions asked to improve the answer accuracy. The study found that questions reformulated by GPT-4 became more detailed and the question format was clearer. This method of restatement and expansion significantly improves the model's answer accuracy. Experiments show that a well-rehearsed question increases the accuracy of the answer from 50% to nearly 100%. This performance improvement not only demonstrates the potential of large language models to improve themselves, but also provides a new perspective on how artificial intelligence can process and understand human language more effectively.
Method
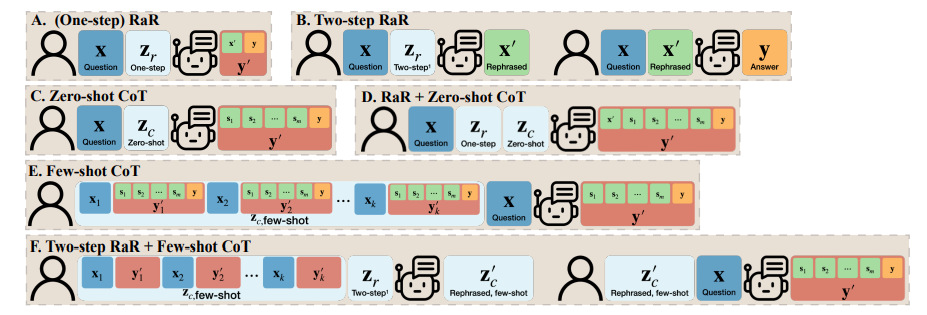
Based on the above findings, the researchers proposed a simple but effective prompt: "Rephrase and expand the question, and respond" (RaR for short). This prompt word directly improves the quality of LLM's answer to questions, demonstrating an important improvement in problem processing.

The research team also proposed a variant of RaR called "Two-step RaR" to take full advantage of things like GPT-4 The ability to restate the problem with a large model. This approach follows two steps: first, for a given question, a specialized Rephrasing LLM is used to generate a rephrasing question; second, the original question and the rephrased question are combined and used to prompt a Responding LLM for an answer.

Results
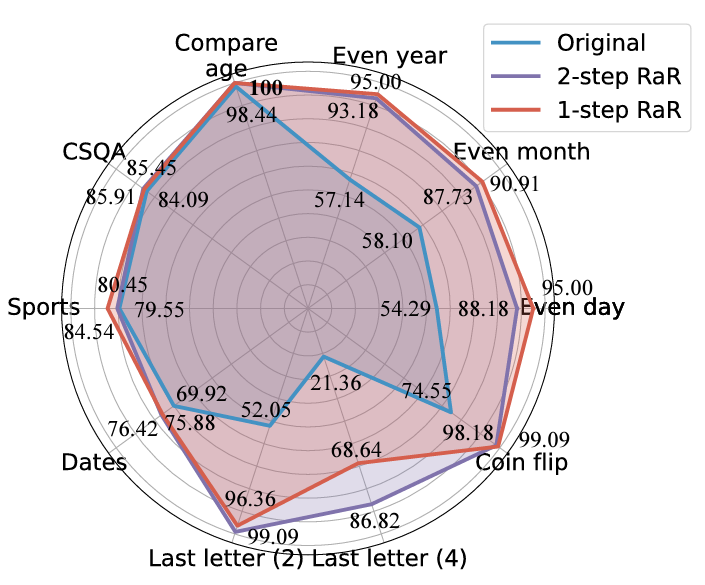
The researchers conducted different tasks Experimental,results show that either single-step RaR or two-step RaR,can effectively improve the answer accuracy of GPT4. Notably, RaR shows significant improvements on tasks that would otherwise be challenging for GPT-4, even approaching 100% accuracy in some cases. The research team summarized the following two key conclusions:
1. Restate and Extend (RaR) provides a plug-and-play black-box prompting method that can effectively improve LLM Performance on a variety of tasks.
2. When evaluating the performance of LLM on question-answering (QA) tasks, it is crucial to check the quality of the questions.
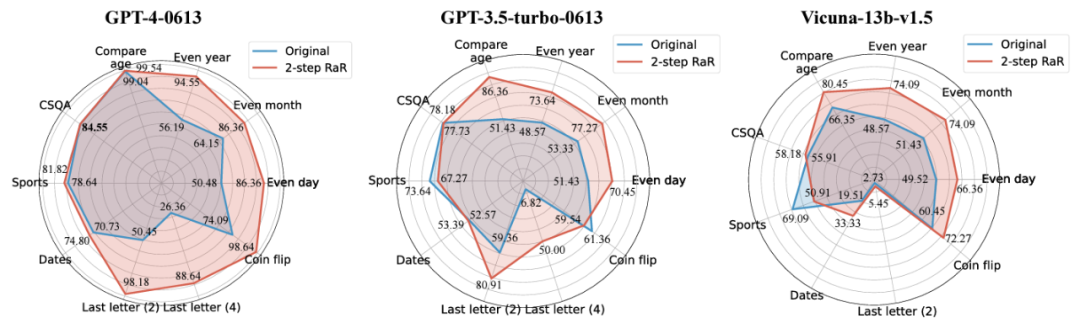
The researchers used the Two-step RaR method to conduct research to explore the performance of different models such as GPT-4, GPT-3.5 and Vicuna-13b-v.15. Experimental results show that for models with more complex architecture and stronger processing capabilities, such as GPT-4, the RaR method can significantly improve the accuracy and efficiency of processing problems. For simpler models, such as Vicuna, although the improvement is smaller, it still shows the effectiveness of the RaR strategy. Based on this, the researchers further examined the quality of questions after retelling different models. Restatement questions for smaller models can sometimes disrupt the intent of the question. And advanced models like GPT-4 provide rephrasing questions that match human intent and can enhance the answers of other models

The findings reveal an important phenomenon: there are differences in the quality and effectiveness of questions rehearsed by different levels of language models. Especially for advanced models like GPT-4, the problems it re-states not only provide themselves with a clearer understanding of the problem, but can also serve as an effective input to improve the performance of other smaller models.
Difference with Chain of Thought (CoT)
To understand the difference between RaR and Chain of Thought (CoT), researchers proposed Their mathematical formulation and illustrates how RaR differs mathematically from CoT and how they can be easily combined.
Before delving into how to enhance the model’s inference capabilities, this study points out that the quality of questions should be improved to ensure that the model’s inference capabilities can be properly assessed. . For example, in the "coin flip" problem, it was found that GPT-4 understood "flip" as a random tossing action, which was different from human intention. Even if "let's think step by step" is used to guide the model in reasoning, this misunderstanding will still persist during the inference process. Only after clarifying the question did the large language model answer the intended question

Further, the researchers noticed that in addition to the question text, The Q&A examples for the few-shot CoT are also written by humans. This raises the question: How do large language models (LLMs) react when these artificially constructed examples are flawed? This study provides an interesting example and finds that poor few-shot CoT examples can have a negative impact on LLM. Taking the "Final Letter Join" task as an example, the problem examples used previously showed positive effects in improving model performance. However, when the prompt logic changed, such as from finding the last letter to finding the first letter, GPT-4 gave the wrong answer. This phenomenon highlights the sensitivity of the model to artificial examples.

Researchers found that using RaR, GPT-4 can fix logical flaws in a given example, thereby improving the quality and performance of few-shot CoTs Robustness
Conclusion
Communication between humans and large language models (LLMs) can be misunderstood: problems that seem clear to humans, Other problems may be understood by large language models. The UCLA research team solved this problem by proposing RaR, a novel method that prompts LLM to restate and clarify the question before answering it
The effectiveness of RaR has been demonstrated in many Experimental evaluations performed on several benchmark datasets are confirmed. Further analysis results show that problem quality can be improved by restating the problem, and this improvement effect can be transferred between different models
For future prospects, it is expected to be similar to RaR Such methods will continue to be improved, and integration with other methods such as CoT will provide a more accurate and efficient way for the interaction between humans and large language models, ultimately expanding the boundaries of AI explanation and reasoning capabilities
The above is the detailed content of Let large AI models ask questions autonomously: GPT-4 breaks down barriers to talking to humans and demonstrates higher levels of performance. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 deepseek web version official entrance
Mar 12, 2025 pm 01:42 PM
deepseek web version official entrance
Mar 12, 2025 pm 01:42 PM
deepseek web version official entrance
 In-depth search deepseek official website entrance
Mar 12, 2025 pm 01:33 PM
In-depth search deepseek official website entrance
Mar 12, 2025 pm 01:33 PM
In-depth search deepseek official website entrance
 How to solve the problem of busy servers for deepseek
Mar 12, 2025 pm 01:39 PM
How to solve the problem of busy servers for deepseek
Mar 12, 2025 pm 01:39 PM
How to solve the problem of busy servers for deepseek
 Another national product from Baidu is connected to DeepSeek. Is it open or follow the trend?
Mar 12, 2025 pm 01:48 PM
Another national product from Baidu is connected to DeepSeek. Is it open or follow the trend?
Mar 12, 2025 pm 01:48 PM
Another national product from Baidu is connected to DeepSeek. Is it open or follow the trend?
 Top 10 recommended for crypto digital asset trading APP (2025 global ranking)
Mar 18, 2025 pm 12:15 PM
Top 10 recommended for crypto digital asset trading APP (2025 global ranking)
Mar 18, 2025 pm 12:15 PM
Top 10 recommended for crypto digital asset trading APP (2025 global ranking)
 Top 10 cryptocurrency trading platforms, top ten recommended currency trading platform apps
Mar 17, 2025 pm 06:03 PM
Top 10 cryptocurrency trading platforms, top ten recommended currency trading platform apps
Mar 17, 2025 pm 06:03 PM
Top 10 cryptocurrency trading platforms, top ten recommended currency trading platform apps
 Nubia Flip 2 is launched: Deeply integrating the DeepSeek big model, priced starting from 3,399 yuan
Mar 12, 2025 pm 01:21 PM
Nubia Flip 2 is launched: Deeply integrating the DeepSeek big model, priced starting from 3,399 yuan
Mar 12, 2025 pm 01:21 PM
Nubia Flip 2 is launched: Deeply integrating the DeepSeek big model, priced starting from 3,399 yuan
 What are the safe and reliable digital currency platforms?
Mar 17, 2025 pm 05:42 PM
What are the safe and reliable digital currency platforms?
Mar 17, 2025 pm 05:42 PM
What are the safe and reliable digital currency platforms?
