

Let's talk about knowledge extraction. Have you learned it?

1. Introduction
Knowledge extraction usually refers to mining structured information from unstructured text, such as tags and phrases containing rich semantic information. This is widely used in the industry in scenarios such as content understanding and product understanding. By extracting valuable tags from user-generated text information, it is applied to content or products.
Knowledge extraction is usually accompanied by The classification of extracted tags or phrases is usually modeled as a named entity recognition task. A common named entity recognition task is to identify named entity components and classify the components into place names, person names, organization names, etc.; domain-related tag word extraction will Tag words are identified and divided into domain-defined categories, such as series (Air Force One, Sonic 9), brand (Nike, Li Ning), type (shoes, clothing, digital), style (INS style, retro style, Nordic style) )wait.
For the convenience of description, in the following, tags or phrases rich in information are collectively called tag words
2. Knowledge extraction classification
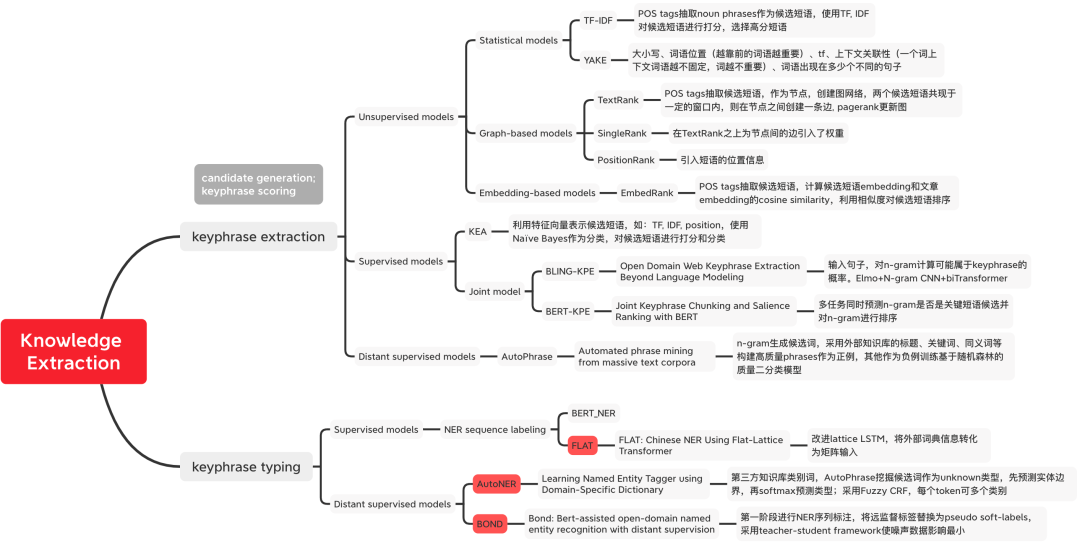 Figure 1 Classification of knowledge extraction methods
Figure 1 Classification of knowledge extraction methods
3. Tag word mining
Unsupervised method
Statistics-based method
- TF-IDF (Term Frequency-Inverse Document Frequency): Count the TF-IDF score of each word. The higher the score, the greater the amount of information contained.
Rewritten content: Calculation method: tfidf(t, d, D) = tf(t, d) * idf(t, D), where tf(t, d) = log (1 freq(t, d)), freq(t,d) represents the number of times candidate word t appears in the current document d, idf(t,D) = log(N/count(d∈D:t∈D) ) indicates how many documents the candidate word t appears in, and is used to indicate the rarity of a word. If a word only appears in one document, it means that the word is rare and has more information.
Specific business In this scenario, you can use external tools to conduct a first round of screening of candidate words, such as using part-of-speech tags to screen nouns.
- YAKE[1]: Five features are defined to capture keyword characteristics, which are heuristically combined to assign a score to each keyword. The lower the score, the more important the keyword is. 1) Capital letters: Term in capital letters (except for the beginning word of each sentence) is more important than Term in lowercase letters, corresponding to the number of bold words in Chinese; 2) Word position: each paragraph of text Some words at the beginning are more important than subsequent words; 3) Word frequency, counts the frequency of word occurrence; 4) Word context, used to measure the number of different words that appear under a fixed window size, one word The more different words co-occur, the lower the importance of the word; 5) The number of times a word appears in different sentences, a word appears in more sentences, the more important it is.
Graph-Based Model
- TextRank[2]: First perform word segmentation and part-of-speech on the text Annotate and filter out stop words, leaving only words with specified parts of speech to construct the graph. Each node is a word, and edges represent relationships between words, which are constructed by defining the co-occurrence of words within a moving window of a predetermined size. Use PageRank to update the weight of nodes until convergence; sort the node weights in reverse order to obtain the most important k words as candidate keywords; mark the candidate words in the original text, and if they form adjacent phrases, combine them into multiple Keyword phrases for phrases.
Representation-based methodEmbedding-Based Model
- EmbedRank[3]: Select candidate words through word segmentation and part-of-speech tagging, use pre-trained Doc2Vec and Sent2vec as vector representations of candidate words and documents, and calculate cosine similarity to rank candidate words. Similarly, KeyBERT[4] replaces the vector representation of EmbedRank with BERT.
Supervised method
- First screen candidate words and then use tag word classification: The classic model KEA[5] uses Naive Bayes as a classifier to score N-gram candidate words on four designed features.
- Joint training of candidate word screening and tag word recognition: BLING-KPE[6] takes the original sentence as input, uses CNN and Transformer to encode the N-gram phrase of the sentence, and calculates whether the phrase is a tag word Probability, whether the label word is manually labeled Label. BERT-KPE[7] Based on the idea of BLING-KPE, ELMO is replaced by BERT to better represent the vector of the sentence.
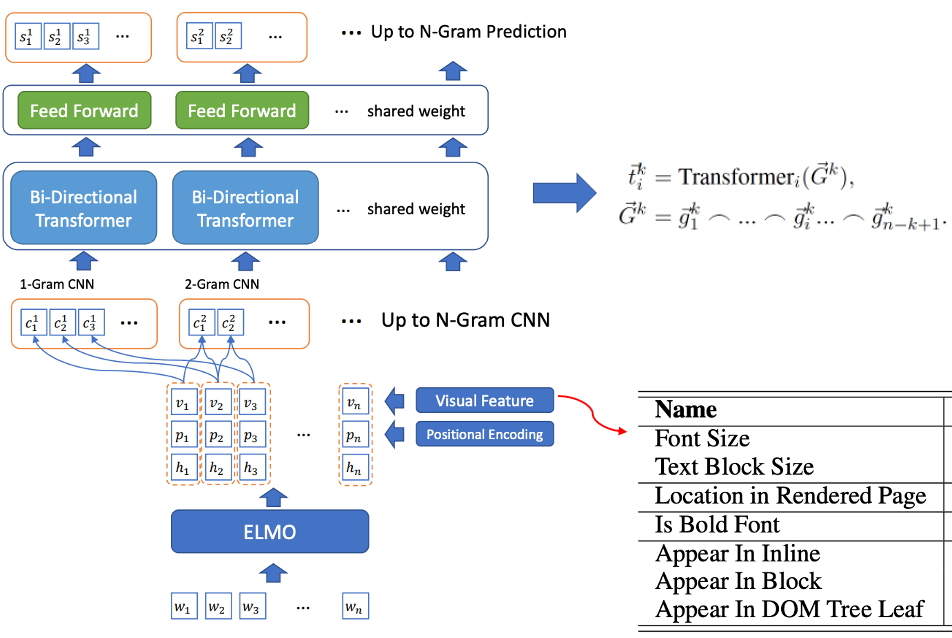 Figure 2 BLING-KPE model structure
Figure 2 BLING-KPE model structure
Far supervision method
AutoPhrase
In this article, we define high-quality phrases as those words with complete semantics, when the following four conditions are met at the same time
- Popularit: frequency of occurrence in the document High enough;
- Concordance: The frequency of Token collocation is much higher than that of other collocations after replacement, that is, the frequency of co-occurrence;
- Informativeness: informative and clear, such as "this "is" is a negative example with no information;
- Completeness: The phrase and its sub-phrases must have completeness.
AutoPhrase tag mining process is shown in Figure 3. First, we use part-of-speech tagging to screen high-frequency N-gram words as candidates. Then, we classify the candidate words through distant supervision. Finally, we use the above four conditions to filter out high-quality phrases (phrase quality re-estimation)
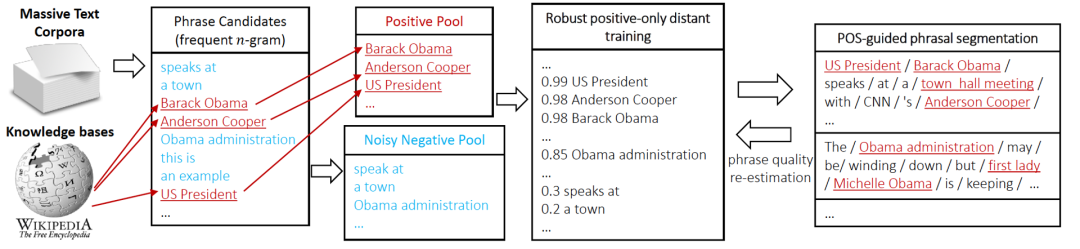 Figure 3 AutoPhrase tag mining process
Figure 3 AutoPhrase tag mining process
From external knowledge The library obtains high-quality phrases as Positive Pool, and other phrases as negative examples. According to the experimental statistics of the paper, there are 10% of high-quality phrases in the negative example pool because they are not classified into negative examples in the knowledge base, so the paper uses the following method: The random forest ensemble classifier shown in Figure 4 reduces the impact of noise on classification. In industry applications, classifier training can also use the two-classification method of inter-sentence relationship tasks based on the pre-training model BERT [13].
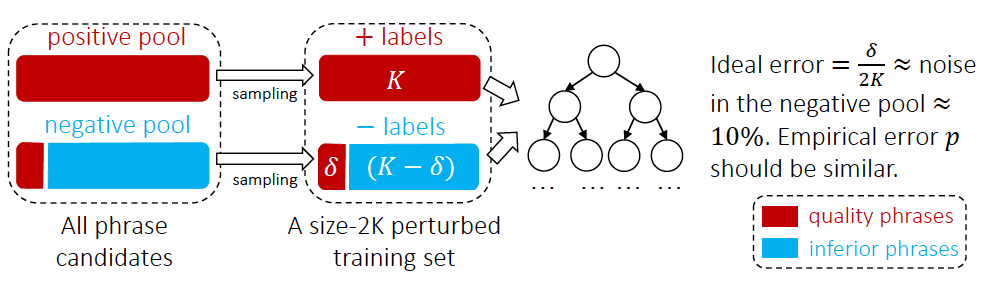 Figure 4 AutoPhrase tag word classification method
Figure 4 AutoPhrase tag word classification method
4. Tag word classification
Supervised method
NER sequence annotation model
Lattice LSTM[8] is the first work to introduce vocabulary information for Chinese NER tasks. Lattice is a directed acyclic graph. The beginning and end characters of the vocabulary determine the grid position. Through the vocabulary information (dictionary) When matching a sentence, a Lattice-like structure can be obtained, as shown in Figure 5(a). The Lattice LSTM structure fuses vocabulary information into the native LSTM, as shown in 5(b). For the current character, all external dictionary information ending with that character is fused. For example, "store" fuses "people and drug stores" and "Pharmacy" information. For each character, Lattice LSTM uses an attention mechanism to fuse a variable number of word units. Although Lattice-LSTM effectively improves the performance of NER tasks, the RNN structure cannot capture long-distance dependencies, and introducing lexical information is lossy. At the same time, the dynamic Lattice structure cannot fully perform GPU parallelism. The Flat[9] model has effectively improved These two questions. As shown in Figure 5(c), the Flat model captures long-distance dependencies through the Transformer structure, and designs a Position Encoding to integrate the Lattice structure. After splicing the words matched by characters into sentences, each character and word is Construct two Head Position Encoding and Tail Position Encoding, flatten the Lattice structure from a directed acyclic graph to a flat Flat-Lattice Transformer structure.
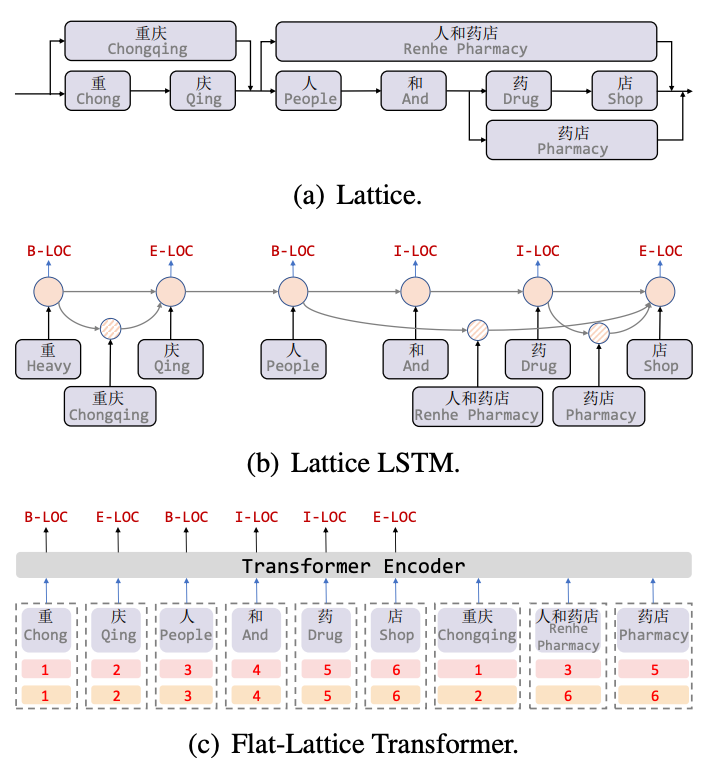 Figure 5 NER model introducing lexical information
Figure 5 NER model introducing lexical information
Far supervision method
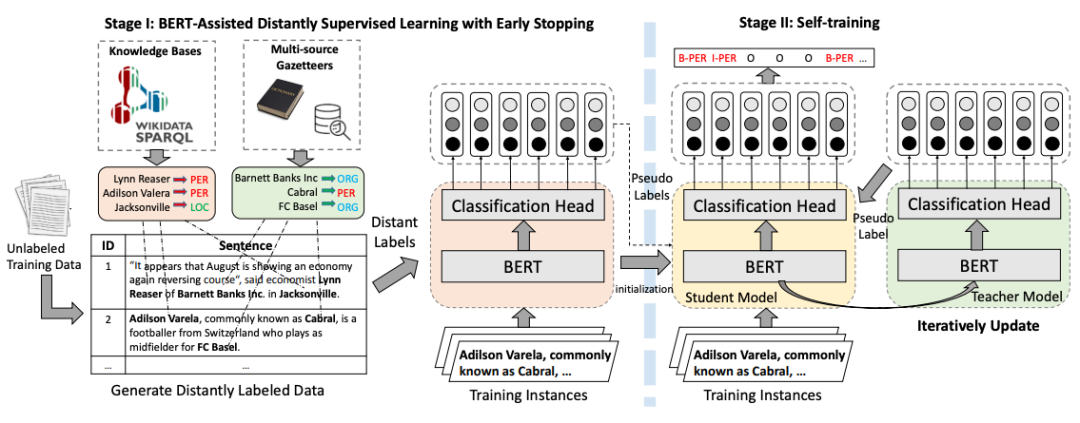
##AutoNERAutoNER[11] uses an external dictionary to construct training data for distant supervised entity recognition. It first performs entity boundary recognition (Entity Span Recognition), and then performs entity classification (Entity Classification). The construction of the external dictionary can directly use the external knowledge base, or use the AutoPhrase mining method to first conduct offline tag word mining, and then use the AutoNER model to incrementally update the tag words. Figure 6 AutoNER model structure diagram
Figure 6 AutoNER model structure diagram
 Picture
Picture
【2】Mihalcea R, Tarau P. Textrank: Bringing order into text[C]//Proceedings of the 2004 conference on empirical methods in natural language processing. 2004: 404-411.
【3 】Bennani-Smires K, Musat C, Hossmann A, et al. Simple unsupervised keyphrase extraction using sentence embeddings[J]. arXiv preprint arXiv:1801.04470, 2018.
【4】KeyBERT, https://github .com/MaartenGr/KeyBERT
【5】Witten I H, Paynter G W, Frank E, et al. KEA: Practical automatic keyphrase extraction[C]//Proceedings of the fourth ACM conference on Digital libraries. 1999: 254-255.
Translation content: [6] Xiong L, Hu C, Xiong C, et al. Open domain Web keyword extraction beyond language models[J]. arXiv preprint arXiv:1911.02671, 2019
[7] Sun, S., Xiong, C., Liu, Z., Liu, Z., & Bao, J. (2020). Joint Keyphrase Chunking and Salience Ranking with BERT. arXiv preprint arXiv:2004.13639.
The content that needs to be rewritten is: [8] Zhang Y, Yang J. Chinese named entity recognition using lattice LSTM[C]. ACL 2018
【9】Li X, Yan H, Qiu X, et al. FLAT: Chinese NER using flat-lattice transformer[C]. ACL 2020.
【10】Shang J , Liu J, Jiang M, et al. Automated phrase mining from massive text corpora[J]. IEEE Transactions on Knowledge and Data Engineering, 2018, 30(10): 1825-1837.
【11】 Shang J, Liu L, Ren X, et al. Learning named entity tagger using domain-specific dictionary[C]. EMNLP, 2018.
【12】Liang C, Yu Y, Jiang H, et al. Bond : Bert-assisted open-domain named entity recognition with distant supervision[C]//Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining. 2020: 1054-1064.
【13】Meituan Exploration and practice of NER technology in search, https://zhuanlan.zhihu.com/p/163256192
The above is the detailed content of Let's talk about knowledge extraction. Have you learned it?. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1381
1381
 52
52

 Let you learn about the shocking win10x system knowledge
Jul 14, 2023 am 11:29 AM
Let you learn about the shocking win10x system knowledge
Jul 14, 2023 am 11:29 AM
Recently, the latest image download of win10X system has been leaked on the Internet. Different from the common ISO, this image is in .ffu format and can currently only be used for Surface Pro7 experience. Although many friends can’t experience it, you can still read the relevant content of the evaluation and enjoy it. Let’s take a look at the latest evaluation of the win10x system! The latest evaluation of the win10x system 1. The biggest difference between Win10X and Win10 first appears after booting up. Buttons are placed in the center of the taskbar. In addition to pinned applications, the taskbar can also display recently launched applications, similar to Android and iOS phones. 2. Another thing is that the “Start” menu of the new system does not support file
 Genshin Impact Walnut Bucket Draw Suggestions
Mar 15, 2024 pm 05:07 PM
Genshin Impact Walnut Bucket Draw Suggestions
Mar 15, 2024 pm 05:07 PM
The pool behind Genshin Kurumi is Yidou. As a new rock element character, he is popular before he appears. Many female players are looking forward to it. So which one should I draw, Genshin Walnut or Idou? The editor below brings you some suggestions for how to draw Genshin Impact Walnuts, let’s take a look. Which one should I draw between Genshin Impact Walnut and Yidou? 1. Walnut is not weak in strength and does not eat holy relics. Yidou has only revealed a little bit about it so far, and I don’t know what the specific situation is. 2. Walnut will not have a substitute in the past six months. It is still a powerful fire C. It is enough to fight the ice water of the abyss. It can be called the strongest fire C. 3. One Dou is a large-sized maid, and it is relatively difficult to get a five-star zodiac sign, so it is not very cost-effective. 4. Yi Dou is basically bound to Albedo. Although its strength is not low, it has a certain training cost. It mainly depends on the player's own role, such as
 Let's talk about knowledge extraction. Have you learned it?
Nov 13, 2023 pm 08:13 PM
Let's talk about knowledge extraction. Have you learned it?
Nov 13, 2023 pm 08:13 PM
1. Introduction Knowledge extraction usually refers to mining structured information from unstructured text, such as tags and phrases containing rich semantic information. This is widely used in the industry in scenarios such as content understanding and product understanding. By extracting valuable tags from user-generated text information and applying them to content or products, knowledge extraction is usually accompanied by the classification of the extracted tags or phrases. , is usually modeled as a named entity recognition task. The general named entity recognition task is to identify named entity components and classify the components into place names, person names, organization names and other types; domain-related tag word extraction identifies and divides tag words into Field-defined categories, such as series (Air Force One, Sonic 9), brand (Nike, Li Ning), type (shoes, clothing, digital), style (
 Understanding Golang: essential knowledge for developers
Feb 23, 2024 am 10:51 AM
Understanding Golang: essential knowledge for developers
Feb 23, 2024 am 10:51 AM
Golang, also known as Go language, is an open source programming language developed by Google. Since its release in 2007, Golang has gradually emerged in the field of software development and has been favored by more and more developers. As a statically typed, compiled language, Golang has many advantages, such as efficient concurrent processing capabilities, concise syntax, and powerful tool support, making it have broad application prospects in cloud computing, big data processing, network programming, etc. . This article will introduce the basic concepts of Golang,
 How does a chatbot answer questions through a knowledge graph?
Apr 17, 2023 am 09:13 AM
How does a chatbot answer questions through a knowledge graph?
Apr 17, 2023 am 09:13 AM
Preface In 1950, Turing published the landmark paper "Computing Machinery and Intelligence" (Computing Machinery and Intelligence), proposing a famous judgment principle about robots - the Turing test, also known as the Turing judgment, which states that if the first If the three cannot distinguish the difference between the responses of humans and AI machines, it can be concluded that the machine has artificial intelligence. In 2008, the AI butler Jarvis in Marvel's "Iron Man" let people know how AI can accurately help humans (Tony) solve various matters thrown at them... Figure 1: AI butler Jarvis ( Picture source: Internet) In early 2023, Chat, a free chat robot that broke out in the technology world in a 2C way, became popular.
 Understanding Linux Server Security: Essential Knowledge and Skills
Sep 09, 2023 pm 02:55 PM
Understanding Linux Server Security: Essential Knowledge and Skills
Sep 09, 2023 pm 02:55 PM
Understanding Linux Server Security: Essential Knowledge and Skills With the continuous development of the Internet, Linux servers are increasingly used in various fields. However, since servers store a large amount of sensitive data, their security issues have also become the focus of attention. This article will introduce some essential Linux server security knowledge and skills to help you protect your server from attacks. Updating and Maintaining Operating Systems and Software Timely updating of operating systems and software is an important part of keeping your server secure. Because every operating system and software
 Learn more about jQuery sibling nodes
Feb 27, 2024 pm 06:51 PM
Learn more about jQuery sibling nodes
Feb 27, 2024 pm 06:51 PM
There is no doubt that jQuery is one of the most used JavaScript libraries in front-end development, providing a concise and powerful way to manipulate HTML documents. In jQuery, sibling nodes are elements that have the same parent element as the specified element. A deep understanding of jQuery sibling nodes is crucial for front-end developers. This article will introduce how to use jQuery to operate sibling nodes, and attach specific code examples. 1. To find sibling nodes in jQuery, we can pass
 Master the key knowledge and practical skills of HTML global attributes
Jan 06, 2024 am 08:40 AM
Master the key knowledge and practical skills of HTML global attributes
Jan 06, 2024 am 08:40 AM
Essential knowledge and practical skills for learning the global attributes of HTML HTML (HyperTextMarkupLanguage) is a markup language used to create the structure of web pages. When building web pages, we often need to use various tags and attributes to define the appearance and behavior of the page. Among all HTML attributes, global attributes are a very important type of attributes. They can be applied to all HTML tags, providing web developers with powerful flexibility and customization capabilities. Learning and using HTML
