
 Technology peripherals
AI
Profit prediction is no longer difficult, scikit-learn linear regression method allows you to get twice the result with half the effort
Technology peripherals
AI
Profit prediction is no longer difficult, scikit-learn linear regression method allows you to get twice the result with half the effort
Profit prediction is no longer difficult, scikit-learn linear regression method allows you to get twice the result with half the effort

1. Introduction
Generative artificial intelligence is undoubtedly a game-changing technology, but for most business problems, traditional machine learning models such as regression and classification are still the first choice.
Rewritten content: Imagine how investors such as private equity or venture capital can leverage machine learning. To answer this question, you first need to understand what data investors care about and how it is used. Decisions about investing in companies are based not only on quantifiable data, such as expenses, growth, and cash burn rates, but also on qualitative data such as founder records, customer feedback, and product experience.
This article will introduce the basics of linear regression Knowledge, the complete code can be found here.
The content that needs to be rewritten is: [Code]: https://github.com/RoyiHD/linear-regression
2. Project settings
This article will use Jupyter Notebook for this project. First import some libraries.
Import library
# 绘制图表import matplotlib.pyplot as plt# 数据管理和处理from pandas import DataFrame# 绘制热力图import seaborn as sns# 分析from sklearn.metrics import r2_score# 用于训练和测试的数据管理from sklearn.model_selection import train_test_split# 导入线性模型from sklearn.linear_model import LinearRegression# 代码注释from typing import List
3. Data
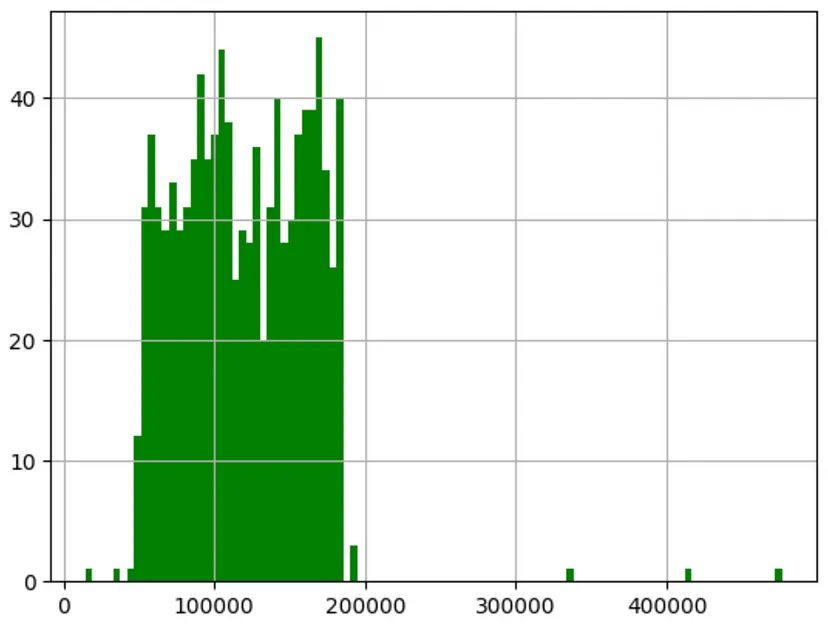
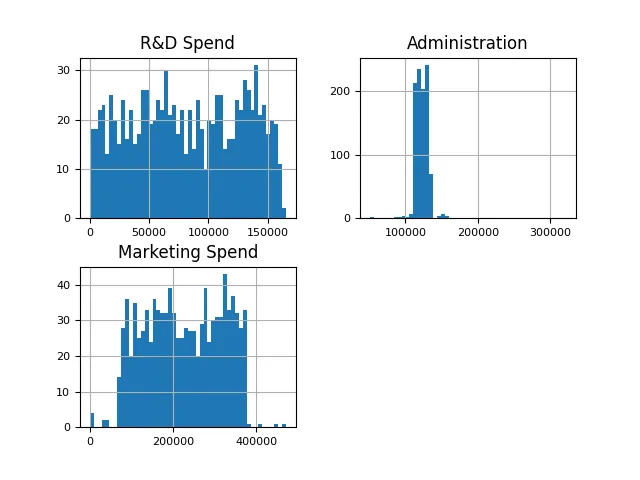
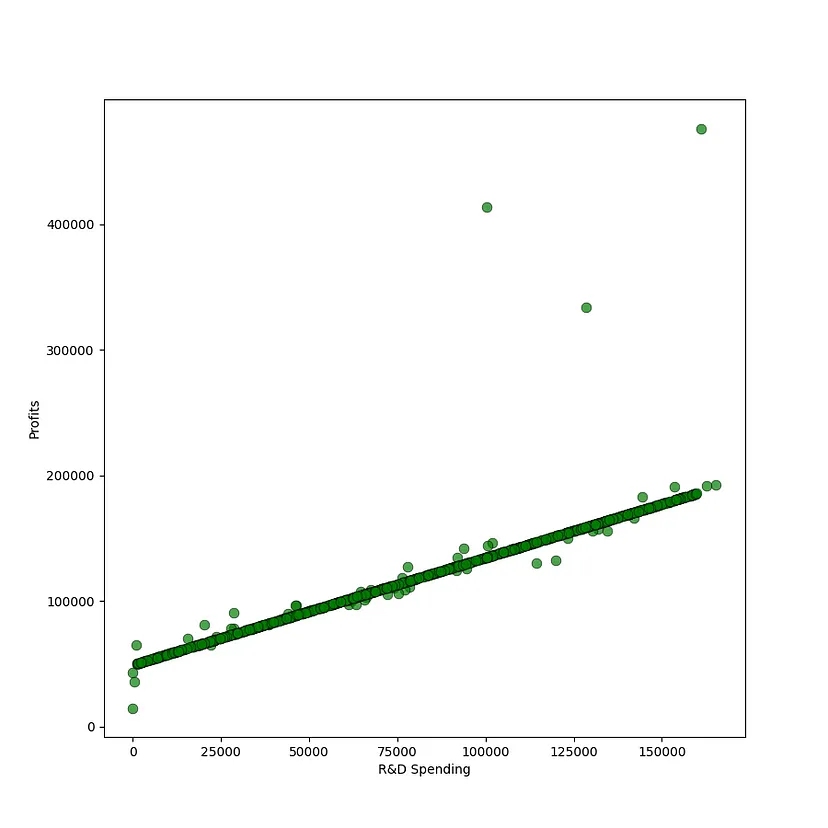
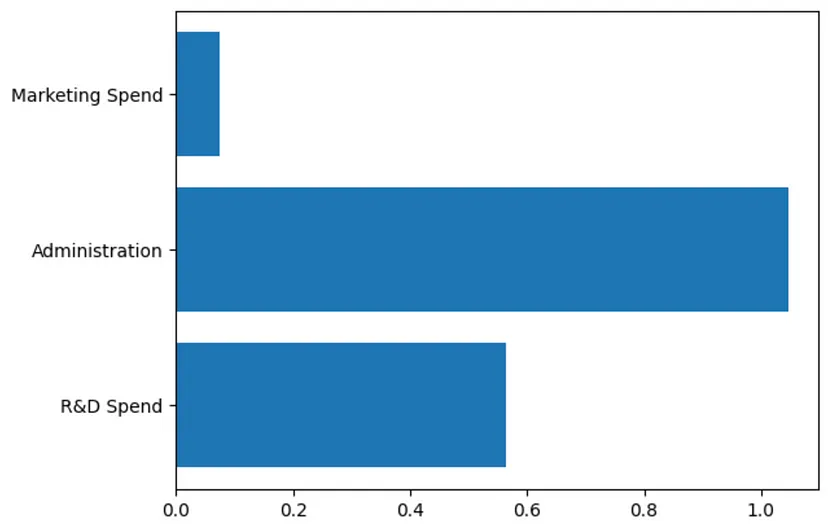
In order to simplify the problem, this article will use regional data. The data represents the company's expense categories and profits. You can see some examples of different data points. This article hopes to use spending data to train a linear regression model and predict profits.
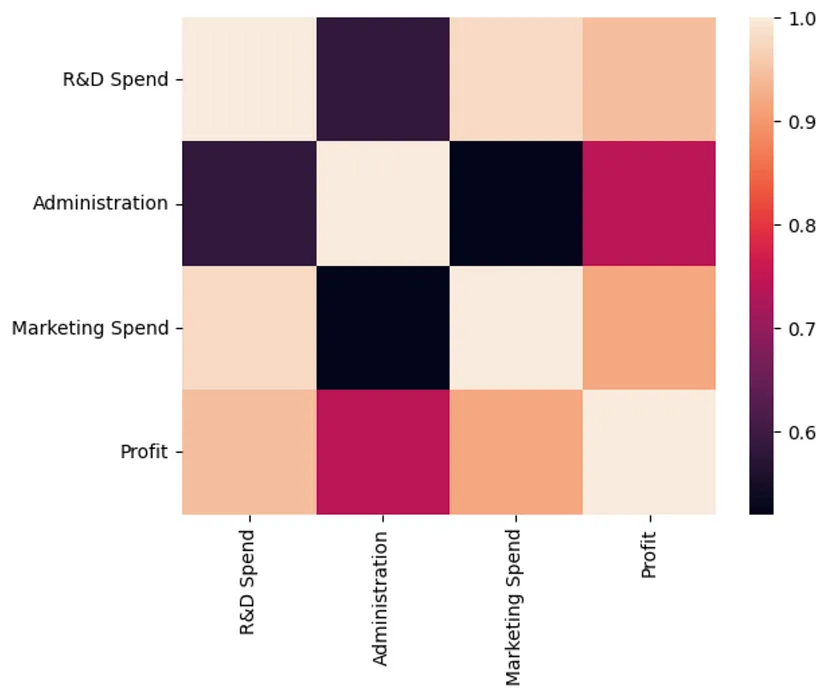
It’s important to understand that the data described in this article is about a company’s spending. Meaningful predictive power can only be derived when spending data is combined with data on revenue growth, local taxes, amortization and market conditions
R&D Spend |
Administration |
# #Marketing |
Investment income |
| The content that needs to be rewritten is: 165349.2 | ##136897.8
| The content that needs to be rewritten is: 192261.83||
|
|
|
|
|
153441.51 |
##101145.55 | ##Needs to be rewritten The content is: 407934.54
The above is the detailed content of Profit prediction is no longer difficult, scikit-learn linear regression method allows you to get twice the result with half the effort. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 I Tried Vibe Coding with Cursor AI and It's Amazing!
Mar 20, 2025 pm 03:34 PM
I Tried Vibe Coding with Cursor AI and It's Amazing!
Mar 20, 2025 pm 03:34 PM
Vibe coding is reshaping the world of software development by letting us create applications using natural language instead of endless lines of code. Inspired by visionaries like Andrej Karpathy, this innovative approach lets dev
 Top 5 GenAI Launches of February 2025: GPT-4.5, Grok-3 & More!
Mar 22, 2025 am 10:58 AM
Top 5 GenAI Launches of February 2025: GPT-4.5, Grok-3 & More!
Mar 22, 2025 am 10:58 AM
February 2025 has been yet another game-changing month for generative AI, bringing us some of the most anticipated model upgrades and groundbreaking new features. From xAI’s Grok 3 and Anthropic’s Claude 3.7 Sonnet, to OpenAI’s G
 How to Use YOLO v12 for Object Detection?
Mar 22, 2025 am 11:07 AM
How to Use YOLO v12 for Object Detection?
Mar 22, 2025 am 11:07 AM
YOLO (You Only Look Once) has been a leading real-time object detection framework, with each iteration improving upon the previous versions. The latest version YOLO v12 introduces advancements that significantly enhance accuracy
 Is ChatGPT 4 O available?
Mar 28, 2025 pm 05:29 PM
Is ChatGPT 4 O available?
Mar 28, 2025 pm 05:29 PM
ChatGPT 4 is currently available and widely used, demonstrating significant improvements in understanding context and generating coherent responses compared to its predecessors like ChatGPT 3.5. Future developments may include more personalized interactions and real-time data processing capabilities, further enhancing its potential for various applications.
 Best AI Art Generators (Free & Paid) for Creative Projects
Apr 02, 2025 pm 06:10 PM
Best AI Art Generators (Free & Paid) for Creative Projects
Apr 02, 2025 pm 06:10 PM
The article reviews top AI art generators, discussing their features, suitability for creative projects, and value. It highlights Midjourney as the best value for professionals and recommends DALL-E 2 for high-quality, customizable art.
 o1 vs GPT-4o: Is OpenAI's New Model Better Than GPT-4o?
Mar 16, 2025 am 11:47 AM
o1 vs GPT-4o: Is OpenAI's New Model Better Than GPT-4o?
Mar 16, 2025 am 11:47 AM
OpenAI's o1: A 12-Day Gift Spree Begins with Their Most Powerful Model Yet December's arrival brings a global slowdown, snowflakes in some parts of the world, but OpenAI is just getting started. Sam Altman and his team are launching a 12-day gift ex
 Google's GenCast: Weather Forecasting With GenCast Mini Demo
Mar 16, 2025 pm 01:46 PM
Google's GenCast: Weather Forecasting With GenCast Mini Demo
Mar 16, 2025 pm 01:46 PM
Google DeepMind's GenCast: A Revolutionary AI for Weather Forecasting Weather forecasting has undergone a dramatic transformation, moving from rudimentary observations to sophisticated AI-powered predictions. Google DeepMind's GenCast, a groundbreak
 Which AI is better than ChatGPT?
Mar 18, 2025 pm 06:05 PM
Which AI is better than ChatGPT?
Mar 18, 2025 pm 06:05 PM
The article discusses AI models surpassing ChatGPT, like LaMDA, LLaMA, and Grok, highlighting their advantages in accuracy, understanding, and industry impact.(159 characters)
