
 Technology peripherals
AI
New approximate attention mechanism HyperAttention: friendly to long contexts, speeding up LLM inference by 50%
Technology peripherals
AI
New approximate attention mechanism HyperAttention: friendly to long contexts, speeding up LLM inference by 50%
New approximate attention mechanism HyperAttention: friendly to long contexts, speeding up LLM inference by 50%

Transformer has been successful in a variety of learning tasks in areas such as natural language processing, computer vision, and time series prediction. Despite their success, these models still face severe scalability limitations. The reason is that the exact computation of the attention layer results in quadratic (in sequence length) running time and memory complexity. This brings fundamental challenges to extending the Transformer model to longer context lengths
The industry has explored various methods to solve the problem of the quadratic temporal attention layer, among which One noteworthy direction is to approximate intermediate matrices in attention layers. Methods to achieve this include approximation via sparse matrices, low-rank matrices, or a combination of both.
However, these methods do not provide end-to-end guarantees for the approximation of the attention output matrix. These methods aim to approximate the individual components of attention faster, but none provide an end-to-end approximation of full dot product attention. These methods also do not support the use of causal masks, which are an important part of modern Transformer architectures. Recent theoretical bounds suggest that in general it is not possible to perform a piecewise approximation of the attention matrix in sub-quadratic time
However, a recent study called KDEFormer shows that , which provides provable approximations in subquadratic time under the assumption that the attention matrix terms are bounded. Theoretically, the runtime of KDEFormer is approximately Probability. However, current KDE algorithms lack practical efficiency, and even in theory there is a gap between KDEFormer's runtime and a theoretically feasible O(n) time algorithm. In the article, the author proves that under the same bounded entry assumption, a near-linear time 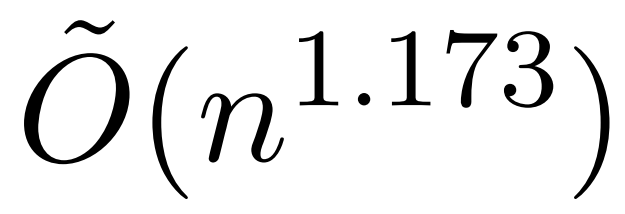 algorithm is possible. However, their algorithm also involves using polynomial methods to approximate the softmax, which is likely to be impractical.
algorithm is possible. However, their algorithm also involves using polynomial methods to approximate the softmax, which is likely to be impractical. 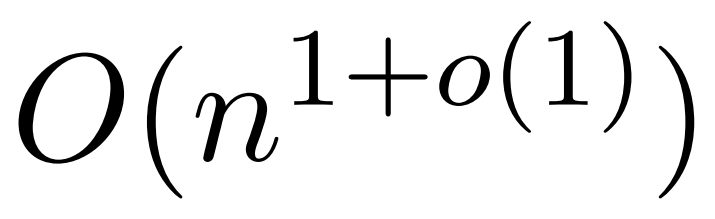 In this article, researchers from Yale University, Google Research and other institutions provide an algorithm that has the best of both worlds, which is both practical and efficient, and can achieve optimal near-linear time ensure. Furthermore, the method supports causal masking, which was not possible in previous work.
In this article, researchers from Yale University, Google Research and other institutions provide an algorithm that has the best of both worlds, which is both practical and efficient, and can achieve optimal near-linear time ensure. Furthermore, the method supports causal masking, which was not possible in previous work.
 Please click the following link to view the paper: https://arxiv.org/abs/2310.05869
Please click the following link to view the paper: https://arxiv.org/abs/2310.05869
This article proposes an approximate attention mechanism called "HyperAttention" to address the computational challenges caused by using long contexts in large language models. Recent research shows that in the worst case, quadratic time is necessary unless the entries of the attention matrix are bounded or the stable rank of the matrix is low
Rewrite content As follows: The researchers introduced two parameters to measure: (1) the maximum column norm normalized attention matrix, (2) the proportion of row norms in the non-normalized attention matrix after deleting large entries. They use these fine-grained parameters to reflect the difficulty of the problem. As long as the above parameters are small, even if the matrix has unbounded entries or a large stable rank, the linear time sampling algorithm can be implemented
HyperAttention has the characteristics of modular design and can Easily integrate other fast low-level implementations, especially FlashAttention. Empirically, Super Attention outperforms existing methods when employing the LSH algorithm to identify large entries, and achieves significant speed improvements compared to state-of-the-art solutions such as FlashAttention. Researchers verified the performance of HyperAttention on a variety of context datasets of varying lengths
#For example, HyperAttention made ChatGLM2’s inference time 50% faster on 32k context lengths, while perplexity degree increased from 5.6 to 6.3. HyperAttention is 5x faster on a single attention layer with larger context lengths (e.g. 131k) and causal masks.
Method Overview
Dot product attention involves processing three input matrices: Q (queries), K (key), V (value) , are all of size nxd, where n is the number of tokens in the input sequence and d is the dimension of the underlying representation. The output of this process is as follows:
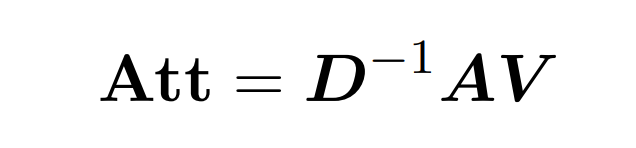
Here, matrix A := exp (QK^T) is defined as the element index of QK^T. D is an n×n diagonal matrix derived from the sum of the rows of A, where 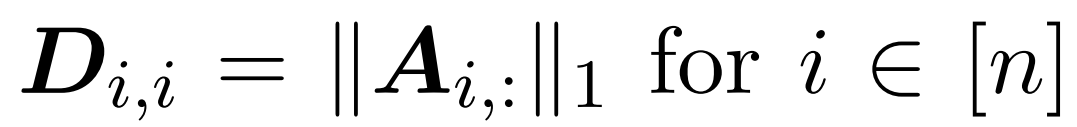 . In this case, matrix A is called the "attention matrix" and (D^-1) A is called the "softmax matrix". It is worth noting that directly computing the attention matrix A requires Θ(n²d) operations, while storing it consumes Θ(n²) memory. Therefore, directly computing Att requires Ω(n²d) runtime and Ω(n²) memory.
. In this case, matrix A is called the "attention matrix" and (D^-1) A is called the "softmax matrix". It is worth noting that directly computing the attention matrix A requires Θ(n²d) operations, while storing it consumes Θ(n²) memory. Therefore, directly computing Att requires Ω(n²d) runtime and Ω(n²) memory.
The researcher's goal is to efficiently approximate the output matrix Att while retaining its spectral characteristics. Their strategy consists of designing a near-linear time efficient estimator for the diagonally scaling matrix D. Furthermore, they quickly approximate the matrix product of the softmax matrix D^-1A by subsampling. More specifically, their goal is to find a sampling matrix 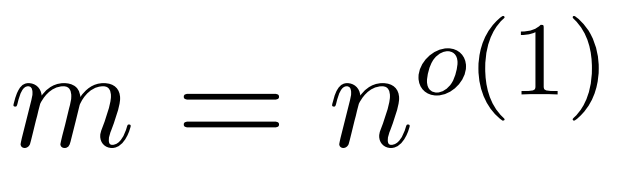 with a finite number of rows
with a finite number of rows 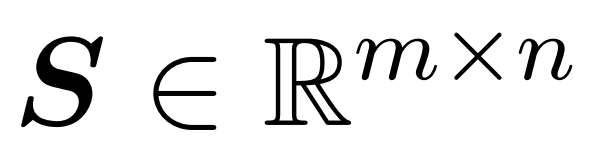 and a diagonal matrix
and a diagonal matrix 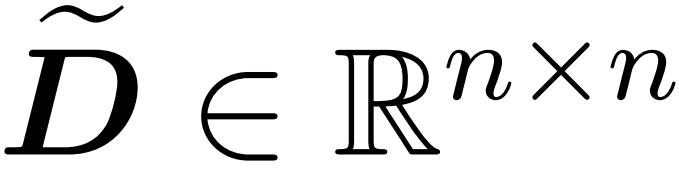 , thus satisfying the following constraints of the operator specification of the error:
, thus satisfying the following constraints of the operator specification of the error:
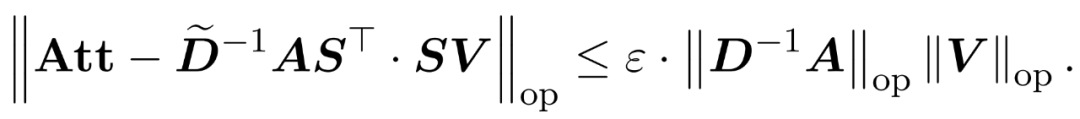
The researchers showed that by defining the sampling matrix S based on the row specification of V, it can be efficiently Solve the matrix multiplication part of the attention approximation problem in Equation (1). The more challenging problem is: how to obtain a reliable approximation of the diagonal matrix D. In recent results, Zandieh effectively exploits the fast KDE solver to obtain high-quality approximations of D. We simplified the KDEformer program and demonstrated that uniform sampling is sufficient to achieve the required spectral guarantees without the need for kernel density-based importance sampling. This significant simplification allowed them to develop a practical, provable linear-time algorithm.
Unlike previous research, our method does not require bounded entries or bounded stable ranks. Furthermore, even if the entries or stable ranks in the attention matrix are large, the fine-grained parameters introduced to analyze the time complexity may still be small.
As a result, HyperAttention is significantly faster, with over 50 times faster forward and backward propagation at sequence length n= 131k. The method still achieves a substantial 5x speedup when dealing with causal masks. Furthermore, when the method is applied to a pre-trained LLM (such as chatqlm2-6b-32k) and evaluated on the long context benchmark dataset LongBench, it maintains a performance level close to the original model even without the need for fine-tuning. The researchers also evaluated specific tasks and found that summarization and code completion tasks had a greater impact on approximate attentional layers than problem-solving tasks.
Algorithm
#In order to obtain spectrum guarantee when approximating Att, the first step in this article is to perform 1 ± ε approximation. Subsequently, the matrix product between A and V is approximated by sampling (D^-1) according to the square row ℓ₂-norms of V.
The process of approximating D consists of two steps. First, an algorithm rooted in Hamming's sorting LSH is used to identify the primary entries in the attention matrix, as shown in Definition 1. The second step is to randomly select a small subset of K. This paper will show that, under certain mild assumptions about matrices A and D, this simple method can establish the spectral bounds of the estimated matrices. The researcher's goal is to find an approximate matrix D that is accurate enough to satisfy:

The assumption of this article is that the column norm of the softmax matrix exhibits a relatively uniform distribution. More precisely, the researcher assumes that for any i ∈ [n] t there exists some 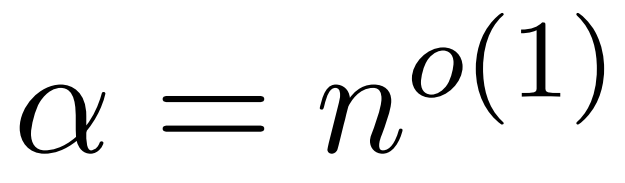 such that
such that 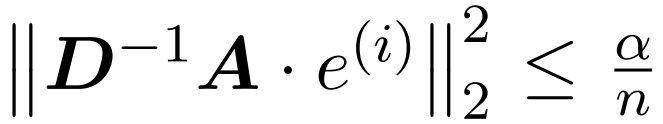 .
.
The first step of the algorithm is to identify large entries in the attention matrix A by hashing keys and queries into uniformly sized buckets using Hamming sort LSH (sortLSH). Algorithm 1 details this process and Figure 1 illustrates it visually.
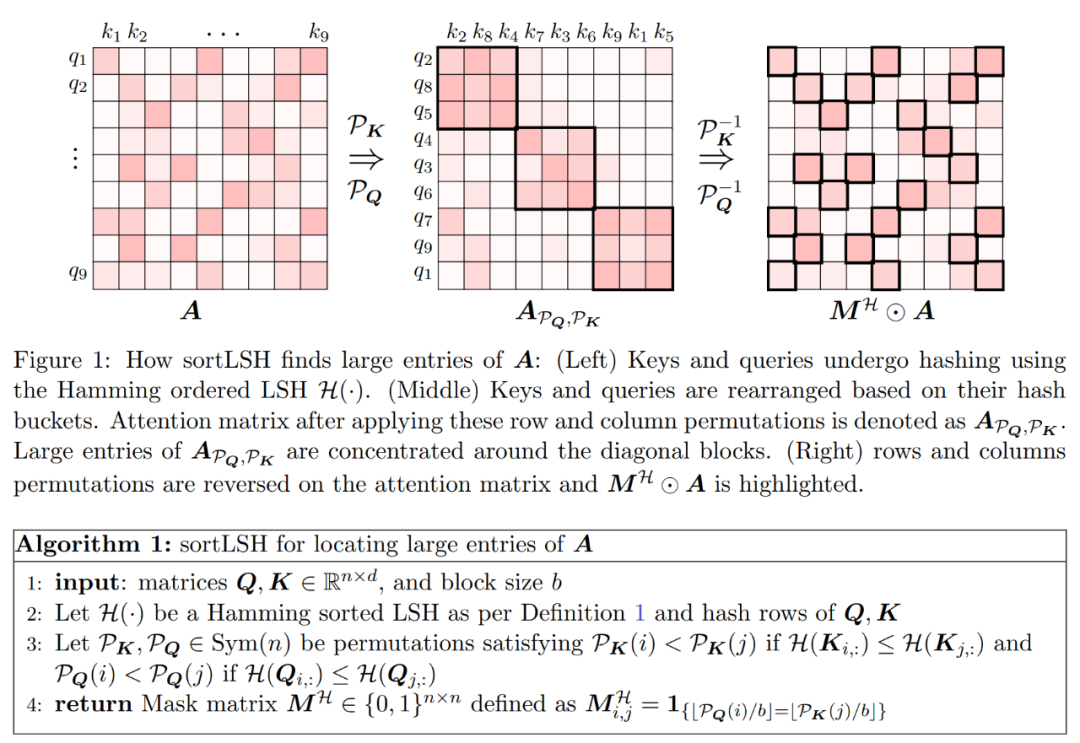
The function of Algorithm 1 is to return a sparse mask that is used to isolate the main entries of the attention matrix. After obtaining this mask, researchers can compute an approximation of the matrix D in Algorithm 2 that satisfies the spectrum guarantee in Equation (2). The algorithm is implemented by combining the attention value corresponding to the mask with a randomly selected set of columns in the attention matrix. The algorithm in this paper can be widely applied and can be used efficiently by using predefined masks to specify the position of the main entries in the attention matrix. The main guarantees of this algorithm are given in Theorem 1


## A subroutine that integrates matrix products between the approximate diagonal 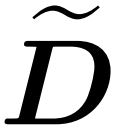 and the approximate
and the approximate 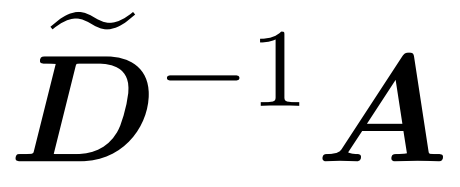 with the value matrix V . Therefore, the researchers introduced HyperAttention, an efficient algorithm that can approximate the attention mechanism with spectrum guarantee in formula (1) in approximately linear time. Algorithm 3 takes as input a mask MH that defines the position of the dominant entry in the attention matrix. This mask can be generated using the sortLSH algorithm (Algorithm 1) or can be a predefined mask, similar to the approach in [7]. We assume that the large entry mask M^H is sparse by design and its number of non-zero entries is bounded
with the value matrix V . Therefore, the researchers introduced HyperAttention, an efficient algorithm that can approximate the attention mechanism with spectrum guarantee in formula (1) in approximately linear time. Algorithm 3 takes as input a mask MH that defines the position of the dominant entry in the attention matrix. This mask can be generated using the sortLSH algorithm (Algorithm 1) or can be a predefined mask, similar to the approach in [7]. We assume that the large entry mask M^H is sparse by design and its number of non-zero entries is bounded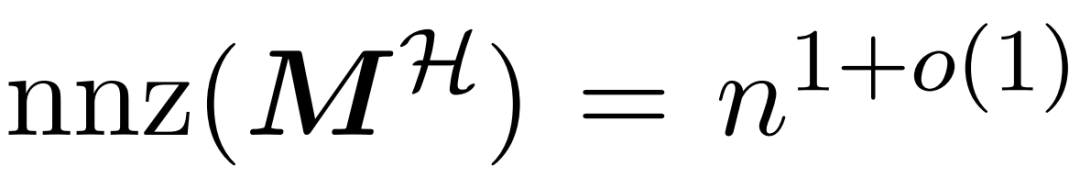 .
.
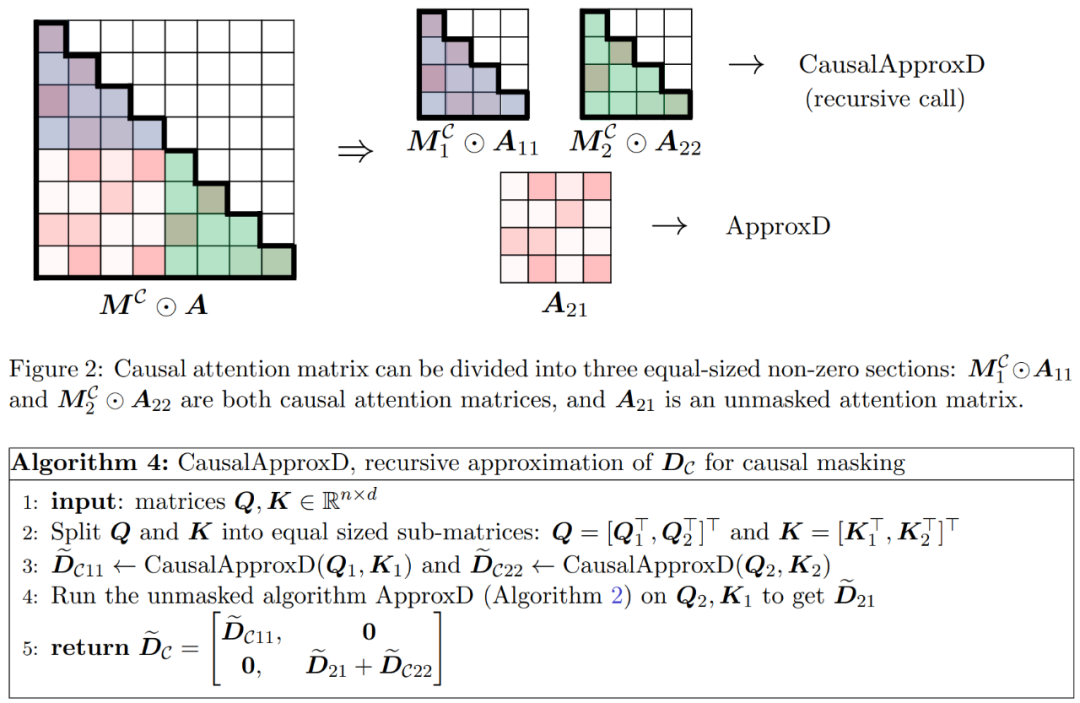
As shown in Figure 2, the method in this paper is based on an important observation. The masked attention M^C⊙A can be decomposed into three non-zero matrices, each of which is half the size of the original attention matrix. Block A_21 completely below the diagonal is unmasked attention. Therefore, we can approximate its row sum using Algorithm 2.
The two diagonal blocks  and
and  shown in Figure 2 are causal attention, and their size Only half of the original size. To deal with these causal relationships, the researchers used a recursive approach, further dividing them into smaller chunks and repeating the process. The pseudocode for this process is given in Algorithm 4.
shown in Figure 2 are causal attention, and their size Only half of the original size. To deal with these causal relationships, the researchers used a recursive approach, further dividing them into smaller chunks and repeating the process. The pseudocode for this process is given in Algorithm 4.
Experiments and results
The researchers processed long range sequences by extending the existing large language model , and then benchmark the algorithm. All experiments were run on a single 40GB A100 GPU and used FlashAttention 2 for precise attention computation.
In order to keep the original meaning unchanged, the content needs to be rewritten into Chinese, and the original sentence does not need to appear
##Researcher HyperAttention is first evaluated on two pre-trained LLMs, and two models with different architectures that are widely used in practical applications are selected: chatglm2-6b-32k and phi-1.5.
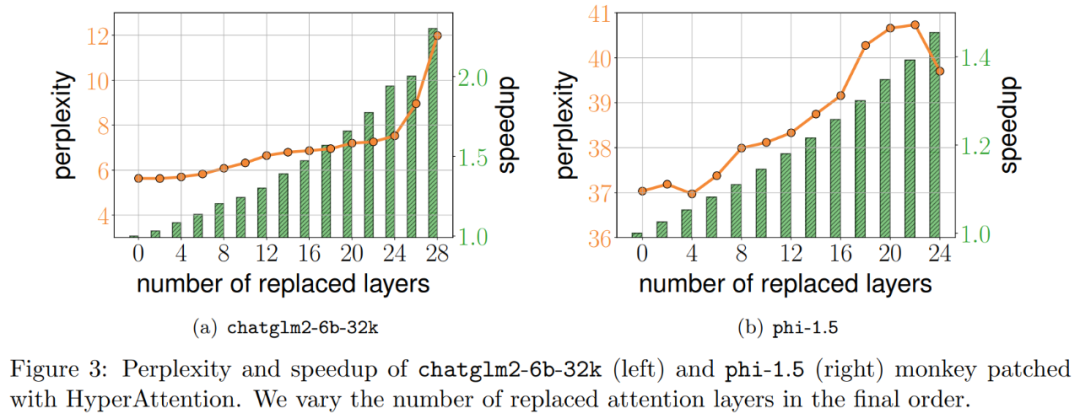
In operation, they patch the final ℓ attention layer by replacing it with HyperAttention, where the number of ℓ can vary from 0 to the total number of all attention layers in each LLM . Note that attention in both models requires a causal mask, and Algorithm 4 is applied recursively until the input sequence length n is less than 4,096. For all sequence lengths, we set the bucket size b and the number of sampled columns m to 256. They evaluated the performance of such monkey patched models in terms of perplexity and acceleration.
At the same time, the researchers used LongBench, a collection of long context benchmark data sets, which contains 6 different tasks, namely single/multi-document question answering, summarization, small sample learning, and synthesis Task and code completion. They selected a subset of the dataset with coding sequence length greater than 32,768 and pruned it if the length exceeded 32,768. Then calculate the perplexity of each model, which is the loss of predicting the next token. To highlight scalability for long sequences, we also calculated the total speedup across all attention layers, whether performed by HyperAttention or FlashAttention.
The results shown in Figure 3 above are as follows. Even if chatglm2-6b-32k has passed the HyperAttention monkey patch, it still shows a reasonable degree of confusion. For example, after replacing layer 20, the perplexity increases by approximately 1 and continues to increase slowly until reaching layer 24. The runtime of the attention layer has been improved by approximately 50%. If all layers are replaced, the perplexity rises to 12 and runs 2.3 times faster. The phi-1.5 model also shows a similar situation, but as the number of HyperAttention increases, the perplexity will increase linearly
In addition, the researchers also The performance of monkey patched chatglm2-6b-32k on the LongBench data set was evaluated, and the evaluation scores for respective tasks such as single/multi-document question answering, summarization, small sample learning, synthesis tasks, and code completion were calculated. The evaluation results are shown in Table 1 below
While replacing HyperAttention generally results in a performance penalty, they observed that its impact varies based on the task at hand. For example, summarization and code completion are the most robust relative to other tasks.
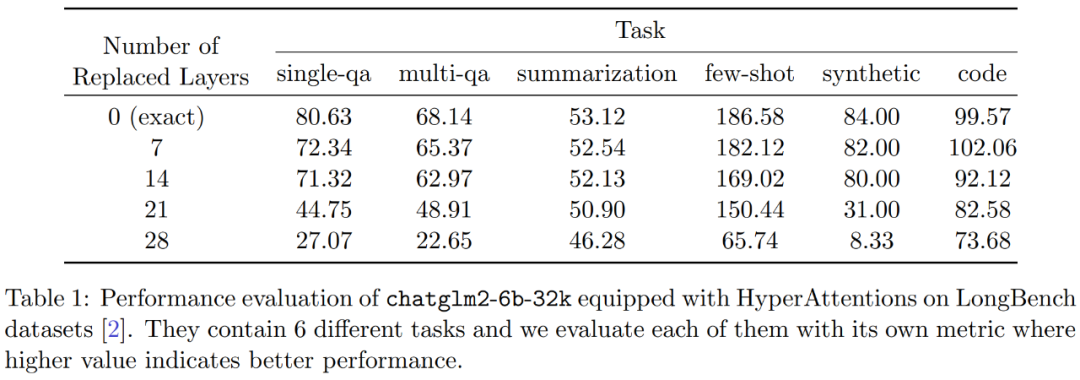
The significant point is that when half of the attention layers (i.e. 14 layers) were patched, the researchers confirmed the performance of most tasks The decline will not exceed 13%. Especially for the summary task, performance remains almost unchanged, indicating that this task is the most robust to partial modifications in the attention mechanism. When n=32k, the calculation speed of the attention layer is increased by 1.5 times.
Single self-attention layer
##The researchers further explored sequence lengths ranging from 4,096 The acceleration of HyperAttention when varying from 131,072 to 131,072. They measured the wall clock time of forward and forward-backward operations when computed using FlashAttention or accelerated by HyperAttention. Wall clock time with and without causal masking was also measured. All inputs Q, K, and V are of the same length, the dimensionality is fixed to d = 64, and the number of attention heads is 12.They choose the same parameters as before in HyperAttention. As shown in Figure 4, when the causal mask is not applied, the speed of HyperAttention is increased by 54 times, and with the causal mask, the speed is increased by 5.4 times. Although the temporal perplexity of causal masking and non-masking is the same, the actual algorithm of causal masking (Algorithm 1) requires additional operations such as partitioning Q, K and V, merging attention outputs, resulting in an increase in actual runtime . When the sequence length n increases, the acceleration will be higher
The researchers believe that these results are not only applicable to inference, but can also be used to train or fine-tune LLM to adapt to longer sequences, which Opens up new possibilities for the expansion of self-attention
The above is the detailed content of New approximate attention mechanism HyperAttention: friendly to long contexts, speeding up LLM inference by 50%. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 Open source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!
Apr 03, 2024 pm 12:04 PM
Open source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!
Apr 03, 2024 pm 12:04 PM
0.What does this article do? We propose DepthFM: a versatile and fast state-of-the-art generative monocular depth estimation model. In addition to traditional depth estimation tasks, DepthFM also demonstrates state-of-the-art capabilities in downstream tasks such as depth inpainting. DepthFM is efficient and can synthesize depth maps within a few inference steps. Let’s read about this work together ~ 1. Paper information title: DepthFM: FastMonocularDepthEstimationwithFlowMatching Author: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Imagine an artificial intelligence model that not only has the ability to surpass traditional computing, but also achieves more efficient performance at a lower cost. This is not science fiction, DeepSeek-V2[1], the world’s most powerful open source MoE model is here. DeepSeek-V2 is a powerful mixture of experts (MoE) language model with the characteristics of economical training and efficient inference. It consists of 236B parameters, 21B of which are used to activate each marker. Compared with DeepSeek67B, DeepSeek-V2 has stronger performance, while saving 42.5% of training costs, reducing KV cache by 93.3%, and increasing the maximum generation throughput to 5.76 times. DeepSeek is a company exploring general artificial intelligence
 AI subverts mathematical research! Fields Medal winner and Chinese-American mathematician led 11 top-ranked papers | Liked by Terence Tao
Apr 09, 2024 am 11:52 AM
AI subverts mathematical research! Fields Medal winner and Chinese-American mathematician led 11 top-ranked papers | Liked by Terence Tao
Apr 09, 2024 am 11:52 AM
AI is indeed changing mathematics. Recently, Tao Zhexuan, who has been paying close attention to this issue, forwarded the latest issue of "Bulletin of the American Mathematical Society" (Bulletin of the American Mathematical Society). Focusing on the topic "Will machines change mathematics?", many mathematicians expressed their opinions. The whole process was full of sparks, hardcore and exciting. The author has a strong lineup, including Fields Medal winner Akshay Venkatesh, Chinese mathematician Zheng Lejun, NYU computer scientist Ernest Davis and many other well-known scholars in the industry. The world of AI has changed dramatically. You know, many of these articles were submitted a year ago.
 Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas officially enters the era of electric robots! Yesterday, the hydraulic Atlas just "tearfully" withdrew from the stage of history. Today, Boston Dynamics announced that the electric Atlas is on the job. It seems that in the field of commercial humanoid robots, Boston Dynamics is determined to compete with Tesla. After the new video was released, it had already been viewed by more than one million people in just ten hours. The old people leave and new roles appear. This is a historical necessity. There is no doubt that this year is the explosive year of humanoid robots. Netizens commented: The advancement of robots has made this year's opening ceremony look like a human, and the degree of freedom is far greater than that of humans. But is this really not a horror movie? At the beginning of the video, Atlas is lying calmly on the ground, seemingly on his back. What follows is jaw-dropping
 KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
Earlier this month, researchers from MIT and other institutions proposed a very promising alternative to MLP - KAN. KAN outperforms MLP in terms of accuracy and interpretability. And it can outperform MLP running with a larger number of parameters with a very small number of parameters. For example, the authors stated that they used KAN to reproduce DeepMind's results with a smaller network and a higher degree of automation. Specifically, DeepMind's MLP has about 300,000 parameters, while KAN only has about 200 parameters. KAN has a strong mathematical foundation like MLP. MLP is based on the universal approximation theorem, while KAN is based on the Kolmogorov-Arnold representation theorem. As shown in the figure below, KAN has
 The vitality of super intelligence awakens! But with the arrival of self-updating AI, mothers no longer have to worry about data bottlenecks
Apr 29, 2024 pm 06:55 PM
The vitality of super intelligence awakens! But with the arrival of self-updating AI, mothers no longer have to worry about data bottlenecks
Apr 29, 2024 pm 06:55 PM
I cry to death. The world is madly building big models. The data on the Internet is not enough. It is not enough at all. The training model looks like "The Hunger Games", and AI researchers around the world are worrying about how to feed these data voracious eaters. This problem is particularly prominent in multi-modal tasks. At a time when nothing could be done, a start-up team from the Department of Renmin University of China used its own new model to become the first in China to make "model-generated data feed itself" a reality. Moreover, it is a two-pronged approach on the understanding side and the generation side. Both sides can generate high-quality, multi-modal new data and provide data feedback to the model itself. What is a model? Awaker 1.0, a large multi-modal model that just appeared on the Zhongguancun Forum. Who is the team? Sophon engine. Founded by Gao Yizhao, a doctoral student at Renmin University’s Hillhouse School of Artificial Intelligence.
 Kuaishou version of Sora 'Ke Ling' is open for testing: generates over 120s video, understands physics better, and can accurately model complex movements
Jun 11, 2024 am 09:51 AM
Kuaishou version of Sora 'Ke Ling' is open for testing: generates over 120s video, understands physics better, and can accurately model complex movements
Jun 11, 2024 am 09:51 AM
What? Is Zootopia brought into reality by domestic AI? Exposed together with the video is a new large-scale domestic video generation model called "Keling". Sora uses a similar technical route and combines a number of self-developed technological innovations to produce videos that not only have large and reasonable movements, but also simulate the characteristics of the physical world and have strong conceptual combination capabilities and imagination. According to the data, Keling supports the generation of ultra-long videos of up to 2 minutes at 30fps, with resolutions up to 1080p, and supports multiple aspect ratios. Another important point is that Keling is not a demo or video result demonstration released by the laboratory, but a product-level application launched by Kuaishou, a leading player in the short video field. Moreover, the main focus is to be pragmatic, not to write blank checks, and to go online as soon as it is released. The large model of Ke Ling is already available in Kuaiying.
 Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
The latest video of Tesla's robot Optimus is released, and it can already work in the factory. At normal speed, it sorts batteries (Tesla's 4680 batteries) like this: The official also released what it looks like at 20x speed - on a small "workstation", picking and picking and picking: This time it is released One of the highlights of the video is that Optimus completes this work in the factory, completely autonomously, without human intervention throughout the process. And from the perspective of Optimus, it can also pick up and place the crooked battery, focusing on automatic error correction: Regarding Optimus's hand, NVIDIA scientist Jim Fan gave a high evaluation: Optimus's hand is the world's five-fingered robot. One of the most dexterous. Its hands are not only tactile
