
 Technology peripherals
AI
NeRF and the past and present of autonomous driving, a summary of nearly 10 papers!
Technology peripherals
AI
NeRF and the past and present of autonomous driving, a summary of nearly 10 papers!
NeRF and the past and present of autonomous driving, a summary of nearly 10 papers!

Since Neural Radiance Fields was proposed in 2020, the number of related papers has increased exponentially. It has not only become an important branch direction of three-dimensional reconstruction, but has also gradually become active at the research frontier as an important tool for autonomous driving.
NeRF has suddenly emerged in the past two years, mainly because it skips the feature point extraction and matching, epipolar geometry and triangulation, PnP plus Bundle Adjustment and other steps of the traditional CV reconstruction pipeline, and even skips the reconstruction of mesh, Texture and ray tracing learn a radiation field directly from a 2D input image, and then output a rendered image from the radiation field that approximates a real photo. In other words, let an implicit 3D model based on a neural network fit the 2D image from a specified perspective, and make it have both new perspective synthesis and capabilities. The development of NeRF is also closely related to autonomous driving, which is specifically reflected in the application of real scene reconstruction and autonomous driving simulators. NeRF is good at rendering photo-level images, so street scenes modeled with NeRF can provide highly realistic training data for autonomous driving; NeRF maps can be edited to combine buildings, vehicles, and pedestrians into various corners that are difficult to capture in reality. case can be used to test the performance of algorithms such as perception, planning, and obstacle avoidance. Therefore, NeRF is a branch of 3D reconstruction and a modeling tool. Mastering NeRF has become an indispensable skill for researchers doing reconstruction or autonomous driving.
Today I will sort out the content related to Nerf and autonomous driving. Nearly 11 articles will take you to explore the past and present of Nerf and autonomous driving;
1. The beginning of Nerf The rewritten content is: NeRF: Neural Radiation Field Representation of Scenes for View Synthesis. In the first article of ECCV2020
, a Nerf method is proposed, which uses a sparse input view set to optimize the underlying continuous volume scene function to achieve the latest view results for synthesizing complex scenes. This algorithm uses a fully connected (non-convolutional) deep network to represent the scene. The input is a single continuous 5D coordinate (including spatial position (x, y, z) and viewing direction (θ, ξ)), and the output is the spatial position of Volume density and view-related emission radiationNERF uses 2D posed images as supervision. There is no need to convolve the image. Instead, it learns a set of hidden images by continuously learning position encoding and using image color as supervision. formula parameters, representing complex three-dimensional scenes. Through implicit representation, rendering from any perspective can be completed.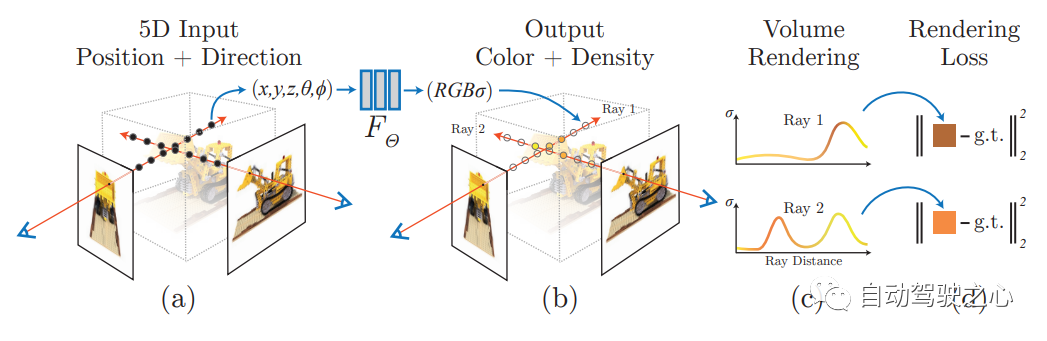 2.Mip-NeRF 360
2.Mip-NeRF 360
The research content of CVPR2020 is about outdoor borderless scenes. Among them, Mip-NeRF 360: Boundless anti-aliasing neural radiation field is one of the research directions
Paper link: https://arxiv.org/pdf/2111.12077.pdfAlthough neural Radiative Fields (NeRF) have demonstrated good view synthesis results on small bounding regions of objects and space, but they are difficult to implement in "boundaryless" scenes where the camera may point in any direction and the content may exist at any distance. In this case, existing NeRF-like models often produce blurry or low-resolution renderings (due to imbalanced detail and scale of nearby and distant objects), are slower to train, and suffer from poor reconstruction from a set of small images. Artifacts may occur due to the inherent ambiguity of the task in large scenes. This paper proposes an extension of mip-NeRF, a NeRF variant that solves sampling and aliasing problems, that uses nonlinear scene parameterization, online distillation, and a new distortion-based regularizer to overcome the problems brought by unbounded scenes. challenges. It achieves a 57% reduction in mean square error compared to mip-NeRF and is able to generate realistic synthetic views and detailed depth maps for highly complex, boundaryless real-world scenes.
#3.Instant-NGP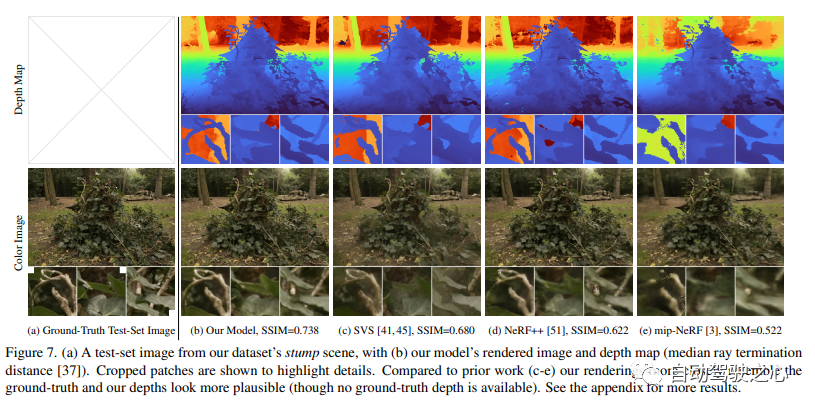
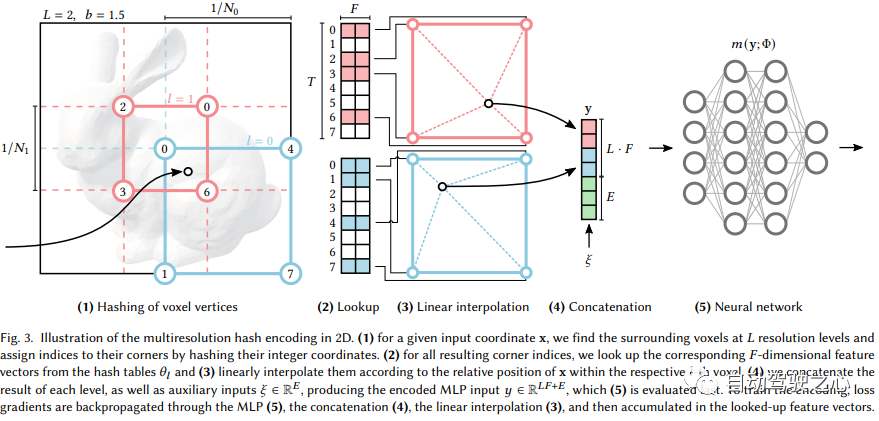
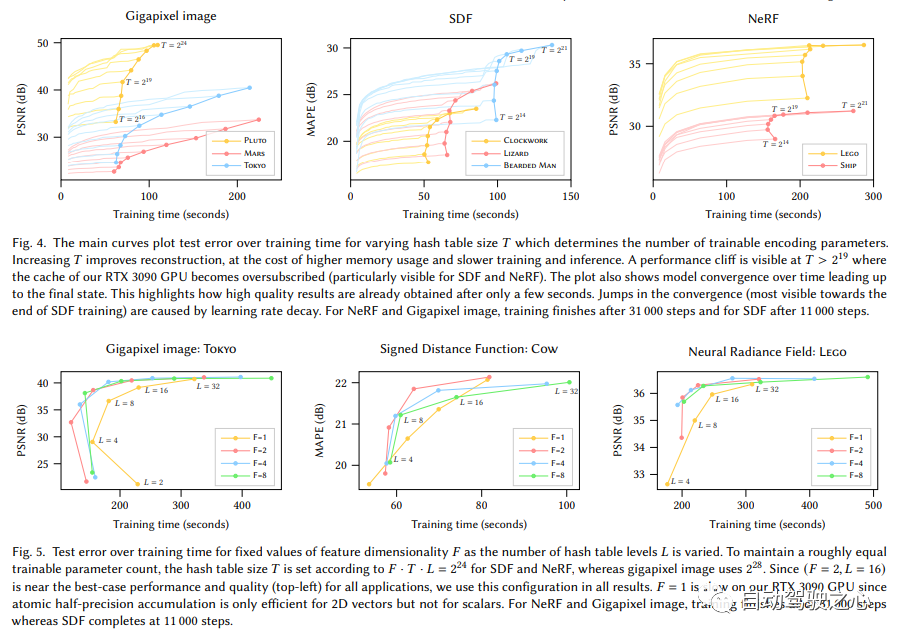
#The content that needs to be rewritten is: "Display Mixed scene representation of voxels plus implicit features (SIGGRAPH 2022)》Real-time neurographic primitives encoded with multi-resolution hashing
The content that needs to be rewritten is: Link: https ://nvlabs.github.io/instant-ngp
Let us first take a look at the similarities and differences between Instant-NGP and NeRF:
- Also based on volume rendering
- Different from NeRF's MLP, NGP uses a sparse parameterized voxel grid as scene expression;
- Based on gradients, it optimizes the scene and MLP at the same time ( One of the MLPs is used as decoder).
It can be seen that the large framework is still the same. The most important difference is that NGP selects the parameterized voxel grid as the scene expression. Through learning, the parameters saved in voxel become the shape of the scene density. The biggest problem with MLP is that it is slow. In order to reconstruct the scene with high quality, a relatively large network is often required, and it will take a lot of time to pass through the network for each sampling point. Interpolation within the grid is much faster. However, if the grid wants to express high-precision scenes, it requires high-density voxels, which will cause extremely high memory usage. Considering that there are many places in the scene that are blank, NVIDIA proposed a sparse structure to express the scene.
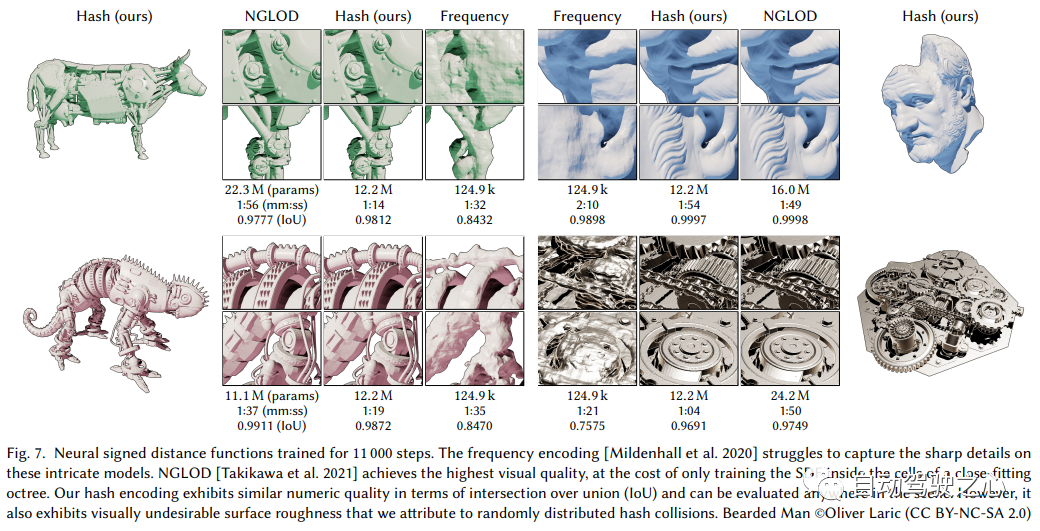

##4. F2-NeRF
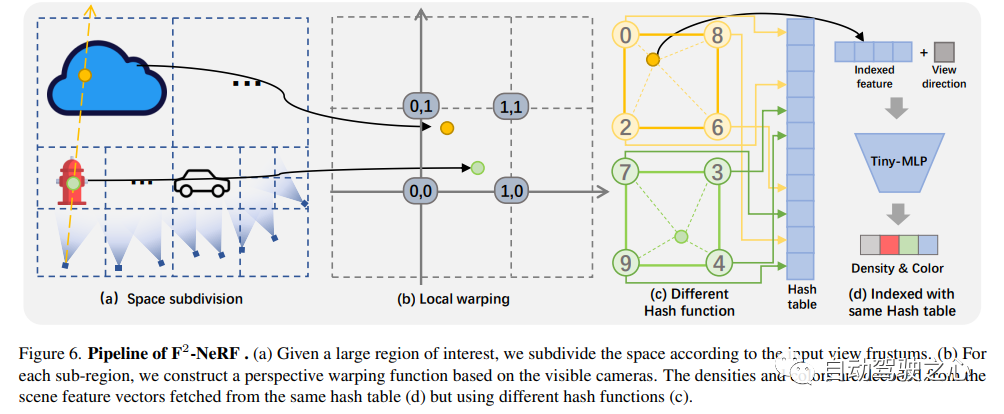
F2-NeRF: Fast Neural Radiance Field Training with Free Camera TrajectoriesPaper link: https://totoro97.github.io/projects/f2-nerf/Proposed a new grid-based NeRF, called F2-NeRF (Fast Free NeRF), for new view synthesis, which can achieve arbitrary input camera trajectories and only requires a few minutes of training time . Existing fast grid-based NeRF training frameworks, such as Instant NGP, Plenoxels, DVGO or TensoRF, are mainly designed for bounded scenes and rely on spatial warpping to handle unbounded scenes. Two existing widely used spatial warpping methods only target forward-facing trajectories or 360◦ object-centered trajectories, but cannot handle arbitrary trajectories. This article conducts an in-depth study of the mechanism of spatial warpping to handle unbounded scenes. We further propose a new spatial warpping method called perspective warpping, which allows us to handle arbitrary trajectories in the grid-based NeRF framework. Extensive experiments show that F2-NeRF is able to render high-quality images using the same perspective warping on two collected standard datasets and a new free trajectory dataset.
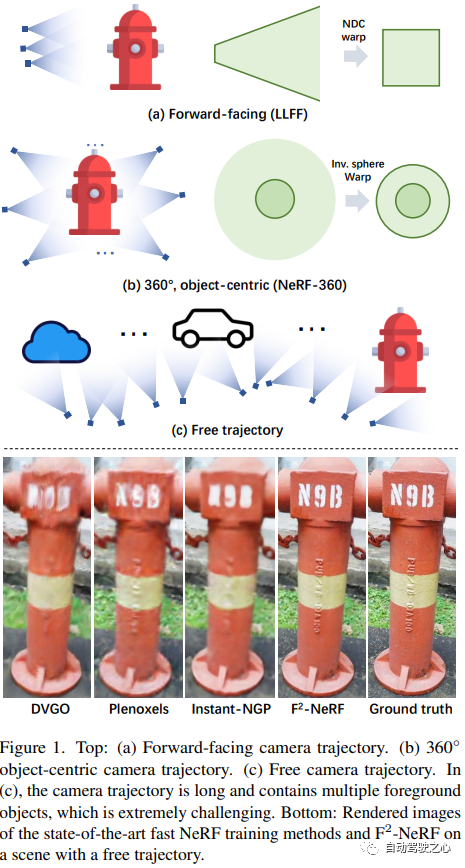
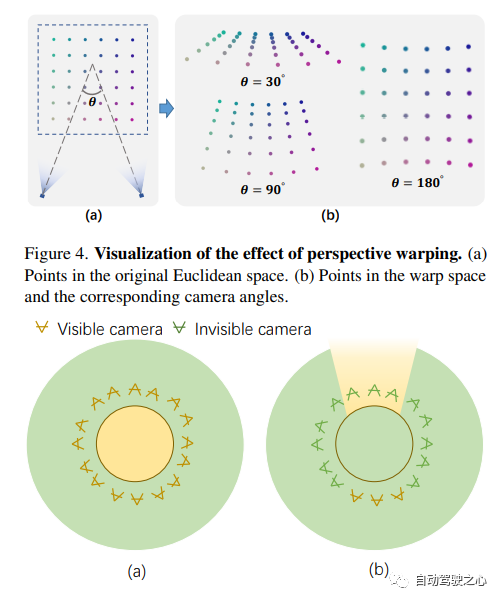
Real-time rendering The mobile application implements the function of Nerf exporting Mesh, and this technology has been adopted by the CVPR2023 conference!
MobileNeRF: Exploiting the Polygon Rasterization Pipeline for Efficient Neural Field Rendering on Mobile Architectures.
The content that needs to be rewritten is: https://arxiv.org/pdf/2208.00277.pdf
Neural Radiation Fields (NeRF) have demonstrated the amazing ability to synthesize 3D scene images from novel views. However, they rely on specialized volumetric rendering algorithms based on ray marching that do not match the capabilities of widely deployed graphics hardware. This paper introduces a new textured polygon-based NeRF representation that can efficiently synthesize new images through standard rendering pipelines. NeRF is represented as a set of polygons whose textures represent binary opacity and feature vectors. Traditional rendering of polygons using a z-buffer produces an image in which each pixel has characteristics that are interpreted by a small view-dependent MLP running in the fragment shader to produce the final pixel color. This approach enables NeRF to render using a traditional polygon rasterization pipeline that provides massive pixel-level parallelism, enabling interactive frame rates across a variety of computing platforms, including mobile phones.
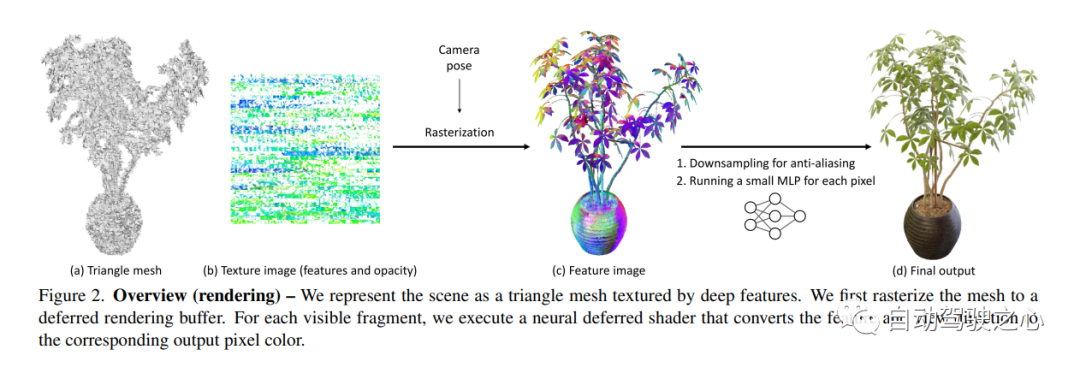
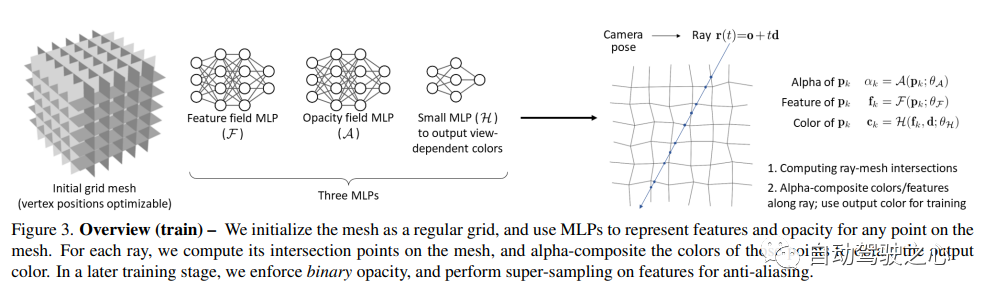

6.Co-SLAM
Our real-time visual localization and NeRF mapping work has been included in CVPR2023
Co-SLAM: Joint Coordinate and Sparse Parametric Encodings for Neural Real-Time SLAM
Paper link: https://arxiv.org/pdf/2304.14377.pdf
Co-SLAM is a real-time An RGB-D SLAM system that uses neural implicit representations for camera tracking and high-fidelity surface reconstruction. Co-SLAM represents the scene as a multi-resolution hash grid to exploit its ability to quickly converge and represent local features. In addition, in order to incorporate surface consistency priors, Co-SLAM uses a block encoding method, which proves that it can powerfully complete scene completion in unobserved areas. Our joint encoding combines the advantages of Co-SLAM’s speed, high-fidelity reconstruction, and surface consistency priors. Through a ray sampling strategy, Co-SLAM is able to globally bundle adjustments to all keyframes!
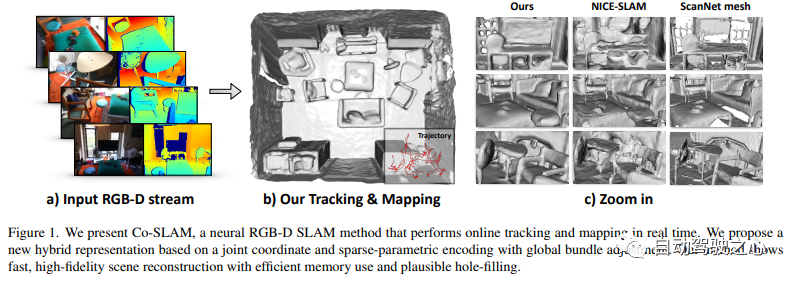
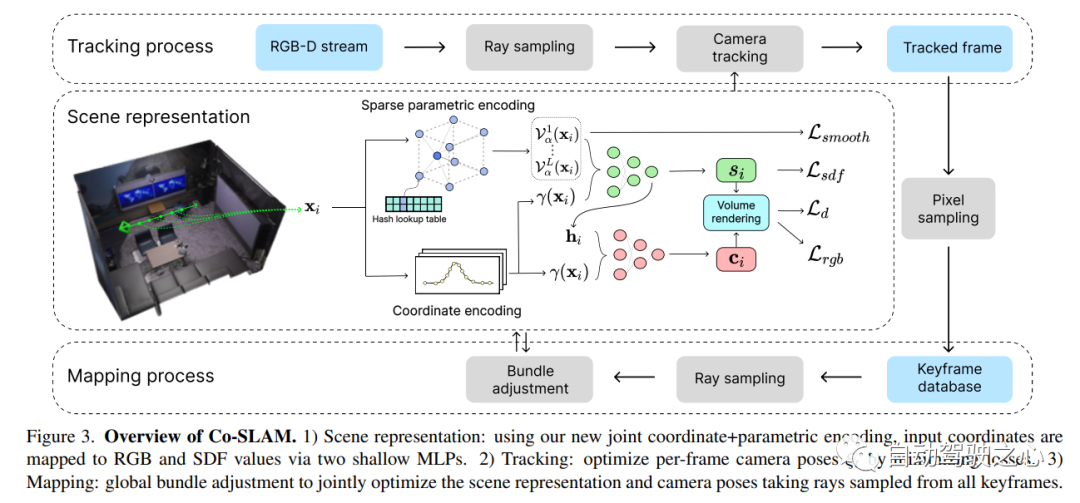
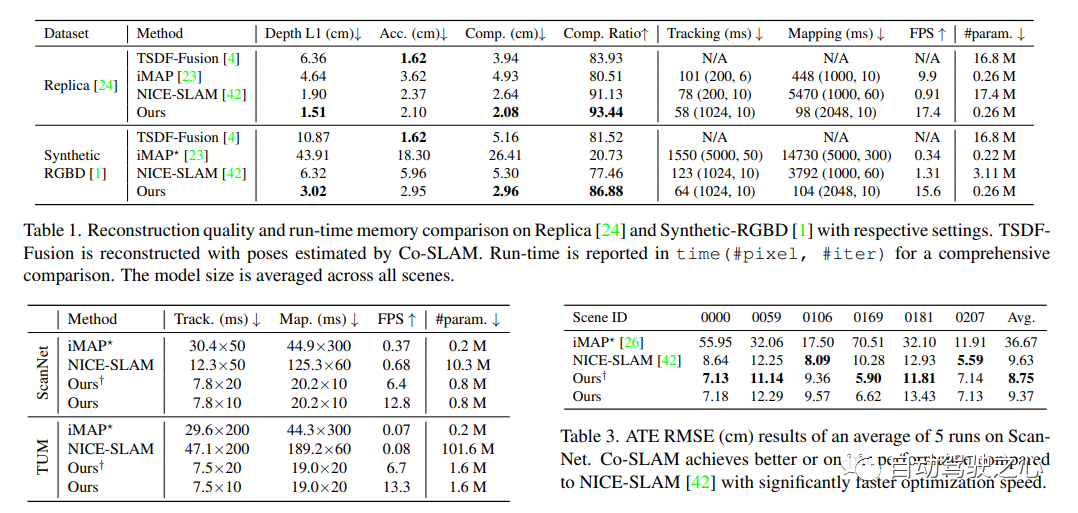

##7.Neuralangelo
The current best NeRF surface reconstruction method (CVPR2023)
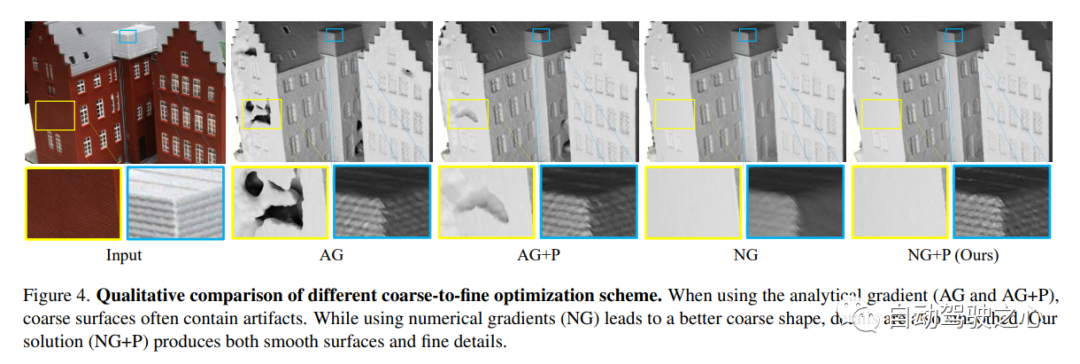
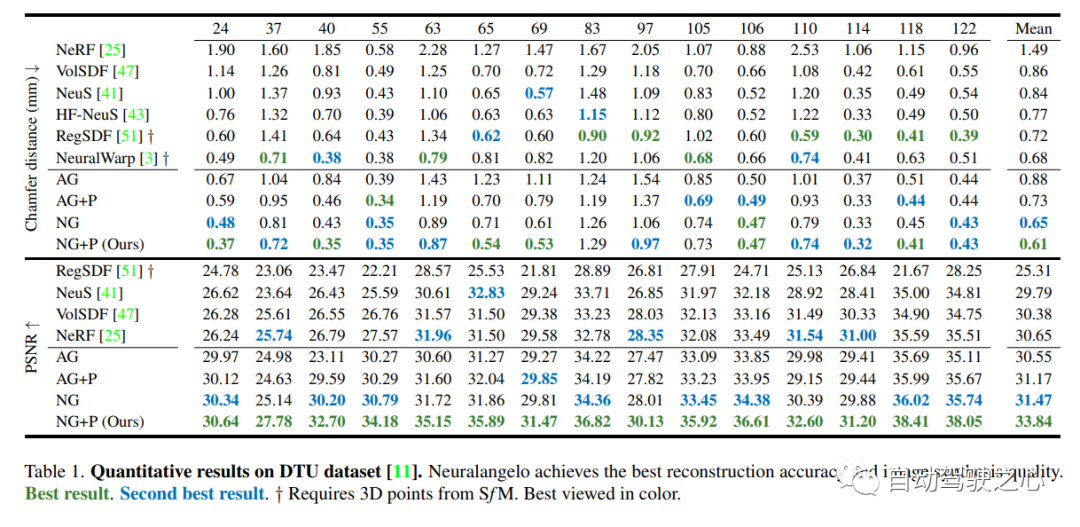


The first open source autonomous driving NeRF simulation tool.
What needs to be rewritten is: https://arxiv.org/pdf/2307.15058.pdf
Self-driving cars can drive smoothly under ordinary circumstances. It is generally believed that realistic sensor simulation Will play a key role in resolving remaining corner situations. To this end, MARS proposes an autonomous driving simulator based on neural radiation fields. Compared with existing works, MARS has three distinctive features: (1) Instance awareness. The simulator models the foreground instances and the background environment separately using separate networks so that the static (e.g., size and appearance) and dynamic (e.g., trajectory) characteristics of the instances can be controlled separately. (2) Modularity. The simulator allows flexible switching between different modern NeRF-related backbones, sampling strategies, input modes, etc. It is hoped that this modular design can promote academic progress and industrial deployment of NeRF-based autonomous driving simulations. (3) Real. The simulator is set up for state-of-the-art photorealistic results with optimal module selection.
The most important point is: open source!
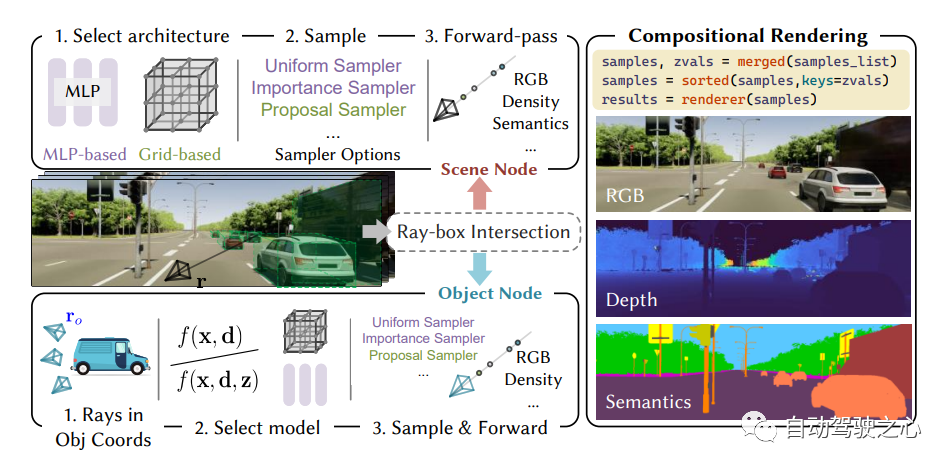
##9.UniOcc
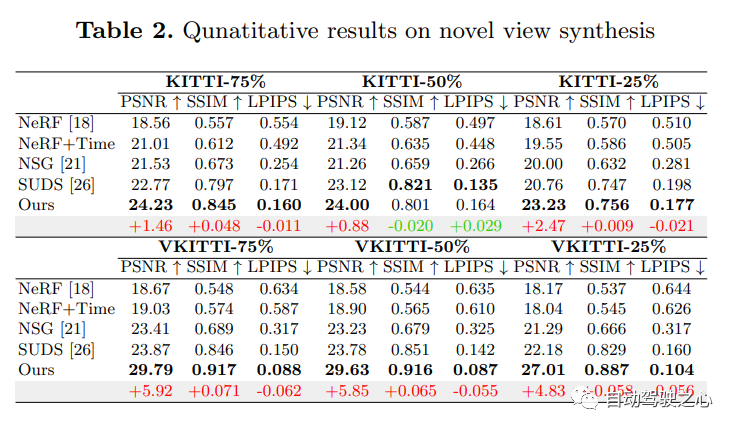
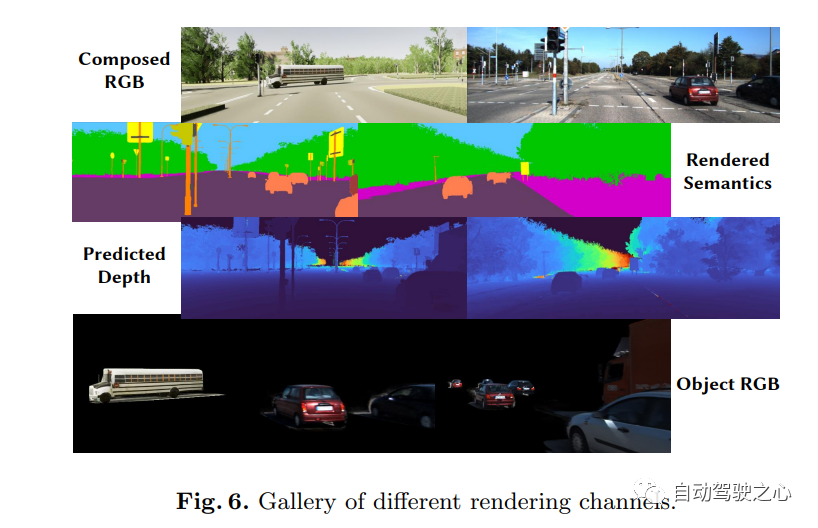
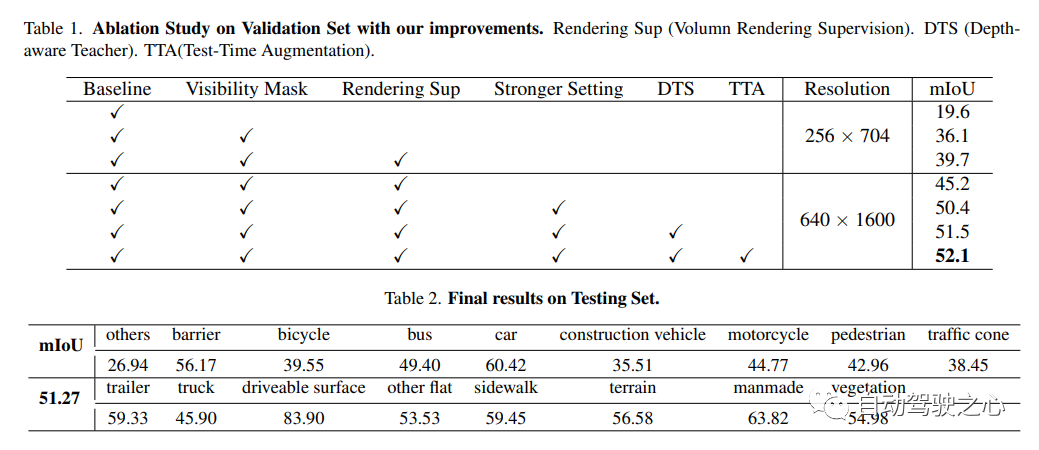
For the content that needs to be re-written, "NeRF and 3D occupy the network, AD2023 Challenge"UniOcc: Unifying Vision-Centric 3D Occupancy Prediction with Geometric and Semantic Rendering.Paper link: https://arxiv.org/abs/2306.09117 UniOCC is a vision-centric 3D occupancy prediction method. Traditional occupancy prediction methods mainly use 3D occupancy labels to optimize the projection features of 3D space. However, the generation process of these labels is complex and expensive, relies on 3D semantic annotations, and is limited by voxel resolution and cannot provide fine-grained space. Semantics. To address this issue, this paper proposes a new unified occupancy (UniOcc) prediction method that explicitly imposes spatial geometric constraints and supplements fine-grained semantic supervision through volume ray rendering. This approach significantly improves model performance and demonstrates the potential in reducing manual annotation costs. Considering the complexity of labeling 3D occupancy, we further introduce the depth-sensing teacher-student (DTS) framework to utilize unlabeled data to improve prediction accuracy. Our solution achieved an mIoU score of 51.27% in the official ranking of single models, ranking third in this challenge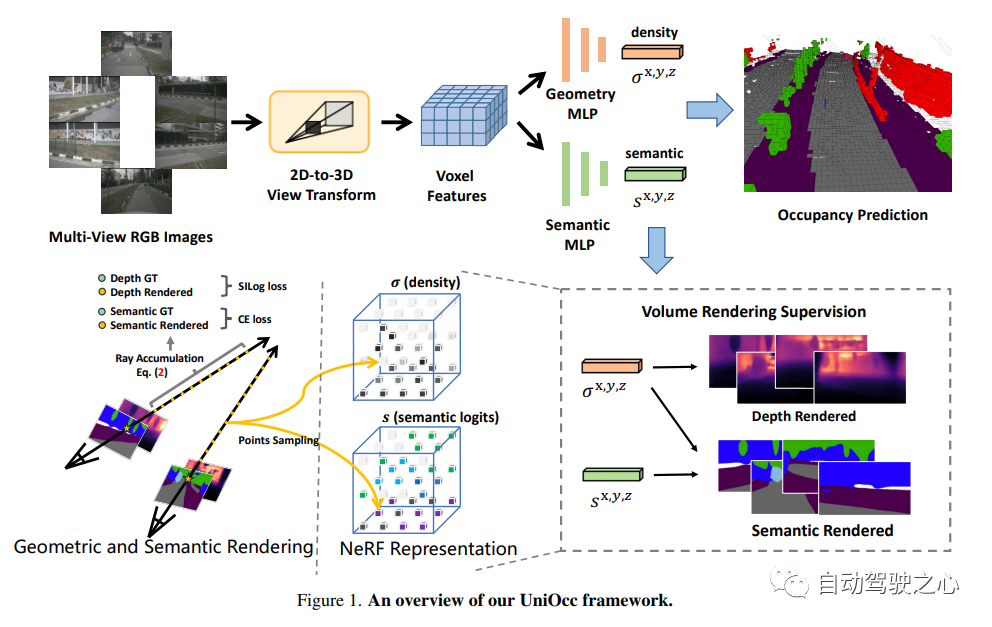
Produced by Wowaoao, it is definitely a high-quality product!
UniSim: A neural closed-loop sensor simulator
Paper link: https://arxiv.org/pdf/2308.01898.pdf
An important reason that hinders the popularization of autonomous driving But security is still not enough. The real world is too complex, especially with the long tail effect. Boundary scenarios are critical to safe driving and are diverse but difficult to encounter. It is very difficult to test the performance of autonomous driving systems in these scenarios because they are difficult to encounter and very expensive and dangerous to test in the real world
To solve this challenge, both industry and academia have begun to pay attention to simulation System development. At the beginning, the simulation system mainly focused on simulating the movement behavior of other vehicles/pedestrians and testing the accuracy of the autonomous driving planning module. In recent years, the focus of research has gradually shifted to sensor-level simulation, that is, simulation to generate raw data such as lidar and camera images, to achieve end-to-end testing of autonomous driving systems from perception, prediction to planning.
Different from previous work, UniSim has simultaneously achieved for the first time:
- High realism:
- Can accurately simulate reality World (pictures and LiDAR), reducing the domain gap Closed-loop simulation:
- Can generate rare dangerous scenes to test unmanned car, and allows the unmanned car to interact freely with the environment Scalable:
- Can be easily expanded to more scenes, and only needs to be collected once data, you can reconstruct and simulate the test

UniSim First, from the collected data,
reconstructthe autonomous driving scene in the digital world, including cars, pedestrians, roads, buildings and traffic signs. Then, control the reconstructed scene for simulation to generate some rare key scenes.
Closed-loop simulationUniSim can perform closed-loop simulation testing. First, by controlling the behavior of the car, UniSim can create a dangerous and rare scene. , For example, a car suddenly comes oncoming in the current lane; then, UniSim simulates and generates corresponding data; then, runs the autonomous driving system and outputs the results of path planning; based on the results of path planning, the unmanned vehicle moves to the next designated location , and update the scene (the location of the unmanned vehicle and other vehicles); then we continue to simulate, run the autonomous driving system, and update the virtual world state... Through this closed-loop test, the autonomous driving system and the simulation environment can interact to create A scene completely different from the original data

The above is the detailed content of NeRF and the past and present of autonomous driving, a summary of nearly 10 papers!. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1377
1377
 52
52

 Why is Gaussian Splatting so popular in autonomous driving that NeRF is starting to be abandoned?
Jan 17, 2024 pm 02:57 PM
Why is Gaussian Splatting so popular in autonomous driving that NeRF is starting to be abandoned?
Jan 17, 2024 pm 02:57 PM
Written above & the author’s personal understanding Three-dimensional Gaussiansplatting (3DGS) is a transformative technology that has emerged in the fields of explicit radiation fields and computer graphics in recent years. This innovative method is characterized by the use of millions of 3D Gaussians, which is very different from the neural radiation field (NeRF) method, which mainly uses an implicit coordinate-based model to map spatial coordinates to pixel values. With its explicit scene representation and differentiable rendering algorithms, 3DGS not only guarantees real-time rendering capabilities, but also introduces an unprecedented level of control and scene editing. This positions 3DGS as a potential game-changer for next-generation 3D reconstruction and representation. To this end, we provide a systematic overview of the latest developments and concerns in the field of 3DGS for the first time.
 How to solve the long tail problem in autonomous driving scenarios?
Jun 02, 2024 pm 02:44 PM
How to solve the long tail problem in autonomous driving scenarios?
Jun 02, 2024 pm 02:44 PM
Yesterday during the interview, I was asked whether I had done any long-tail related questions, so I thought I would give a brief summary. The long-tail problem of autonomous driving refers to edge cases in autonomous vehicles, that is, possible scenarios with a low probability of occurrence. The perceived long-tail problem is one of the main reasons currently limiting the operational design domain of single-vehicle intelligent autonomous vehicles. The underlying architecture and most technical issues of autonomous driving have been solved, and the remaining 5% of long-tail problems have gradually become the key to restricting the development of autonomous driving. These problems include a variety of fragmented scenarios, extreme situations, and unpredictable human behavior. The "long tail" of edge scenarios in autonomous driving refers to edge cases in autonomous vehicles (AVs). Edge cases are possible scenarios with a low probability of occurrence. these rare events
 Choose camera or lidar? A recent review on achieving robust 3D object detection
Jan 26, 2024 am 11:18 AM
Choose camera or lidar? A recent review on achieving robust 3D object detection
Jan 26, 2024 am 11:18 AM
0.Written in front&& Personal understanding that autonomous driving systems rely on advanced perception, decision-making and control technologies, by using various sensors (such as cameras, lidar, radar, etc.) to perceive the surrounding environment, and using algorithms and models for real-time analysis and decision-making. This enables vehicles to recognize road signs, detect and track other vehicles, predict pedestrian behavior, etc., thereby safely operating and adapting to complex traffic environments. This technology is currently attracting widespread attention and is considered an important development area in the future of transportation. one. But what makes autonomous driving difficult is figuring out how to make the car understand what's going on around it. This requires that the three-dimensional object detection algorithm in the autonomous driving system can accurately perceive and describe objects in the surrounding environment, including their locations,
 The Stable Diffusion 3 paper is finally released, and the architectural details are revealed. Will it help to reproduce Sora?
Mar 06, 2024 pm 05:34 PM
The Stable Diffusion 3 paper is finally released, and the architectural details are revealed. Will it help to reproduce Sora?
Mar 06, 2024 pm 05:34 PM
StableDiffusion3’s paper is finally here! This model was released two weeks ago and uses the same DiT (DiffusionTransformer) architecture as Sora. It caused quite a stir once it was released. Compared with the previous version, the quality of the images generated by StableDiffusion3 has been significantly improved. It now supports multi-theme prompts, and the text writing effect has also been improved, and garbled characters no longer appear. StabilityAI pointed out that StableDiffusion3 is a series of models with parameter sizes ranging from 800M to 8B. This parameter range means that the model can be run directly on many portable devices, significantly reducing the use of AI
 Have you really mastered coordinate system conversion? Multi-sensor issues that are inseparable from autonomous driving
Oct 12, 2023 am 11:21 AM
Have you really mastered coordinate system conversion? Multi-sensor issues that are inseparable from autonomous driving
Oct 12, 2023 am 11:21 AM
The first pilot and key article mainly introduces several commonly used coordinate systems in autonomous driving technology, and how to complete the correlation and conversion between them, and finally build a unified environment model. The focus here is to understand the conversion from vehicle to camera rigid body (external parameters), camera to image conversion (internal parameters), and image to pixel unit conversion. The conversion from 3D to 2D will have corresponding distortion, translation, etc. Key points: The vehicle coordinate system and the camera body coordinate system need to be rewritten: the plane coordinate system and the pixel coordinate system. Difficulty: image distortion must be considered. Both de-distortion and distortion addition are compensated on the image plane. 2. Introduction There are four vision systems in total. Coordinate system: pixel plane coordinate system (u, v), image coordinate system (x, y), camera coordinate system () and world coordinate system (). There is a relationship between each coordinate system,
 This article is enough for you to read about autonomous driving and trajectory prediction!
Feb 28, 2024 pm 07:20 PM
This article is enough for you to read about autonomous driving and trajectory prediction!
Feb 28, 2024 pm 07:20 PM
Trajectory prediction plays an important role in autonomous driving. Autonomous driving trajectory prediction refers to predicting the future driving trajectory of the vehicle by analyzing various data during the vehicle's driving process. As the core module of autonomous driving, the quality of trajectory prediction is crucial to downstream planning control. The trajectory prediction task has a rich technology stack and requires familiarity with autonomous driving dynamic/static perception, high-precision maps, lane lines, neural network architecture (CNN&GNN&Transformer) skills, etc. It is very difficult to get started! Many fans hope to get started with trajectory prediction as soon as possible and avoid pitfalls. Today I will take stock of some common problems and introductory learning methods for trajectory prediction! Introductory related knowledge 1. Are the preview papers in order? A: Look at the survey first, p
 SIMPL: A simple and efficient multi-agent motion prediction benchmark for autonomous driving
Feb 20, 2024 am 11:48 AM
SIMPL: A simple and efficient multi-agent motion prediction benchmark for autonomous driving
Feb 20, 2024 am 11:48 AM
Original title: SIMPL: ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving Paper link: https://arxiv.org/pdf/2402.02519.pdf Code link: https://github.com/HKUST-Aerial-Robotics/SIMPL Author unit: Hong Kong University of Science and Technology DJI Paper idea: This paper proposes a simple and efficient motion prediction baseline (SIMPL) for autonomous vehicles. Compared with traditional agent-cent
 nuScenes' latest SOTA | SparseAD: Sparse query helps efficient end-to-end autonomous driving!
Apr 17, 2024 pm 06:22 PM
nuScenes' latest SOTA | SparseAD: Sparse query helps efficient end-to-end autonomous driving!
Apr 17, 2024 pm 06:22 PM
Written in front & starting point The end-to-end paradigm uses a unified framework to achieve multi-tasking in autonomous driving systems. Despite the simplicity and clarity of this paradigm, the performance of end-to-end autonomous driving methods on subtasks still lags far behind single-task methods. At the same time, the dense bird's-eye view (BEV) features widely used in previous end-to-end methods make it difficult to scale to more modalities or tasks. A sparse search-centric end-to-end autonomous driving paradigm (SparseAD) is proposed here, in which sparse search fully represents the entire driving scenario, including space, time, and tasks, without any dense BEV representation. Specifically, a unified sparse architecture is designed for task awareness including detection, tracking, and online mapping. In addition, heavy
