
 Technology peripherals
AI
Based on LLaMA but changing the tensor name, Kai-Fu Lee's large model caused controversy, and the official response is here
Technology peripherals
AI
Based on LLaMA but changing the tensor name, Kai-Fu Lee's large model caused controversy, and the official response is here
Based on LLaMA but changing the tensor name, Kai-Fu Lee's large model caused controversy, and the official response is here

Some time ago, the field of open source large models ushered in a new model - the context window size exceeded 200k and can handle "Yi" of 400,000 Chinese characters at a time.
Kai-fu Lee, Chairman and CEO of Innovation Works, founded the large model company "Zero One Thousand Things" and built this large model, including Yi-6B and Yi-34B. Version
According to Hugging Face English open source community platform and C-Eval Chinese evaluation list, Yi-34B achieved a number of SOTA international best performance indicator recognitions when it was launched, becoming a global open source giant. The model is a "double champion", defeating open source competing products such as LLaMA2 and Falcon.
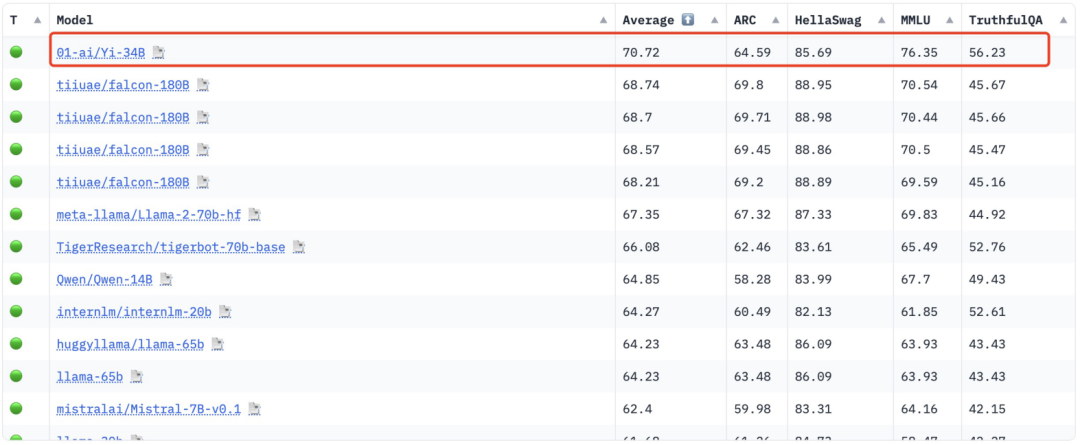
Yi-34B also became the only domestic model to successfully top the Hugging Face global open source model rankings at that time. , called "the world's strongest open source model."
After its release, this model attracted the attention of many domestic and foreign researchers and developers
But recently, some researchers discovered that, The Yi-34B model basically adopts the LLaMA architecture, except that two tensors are renamed.
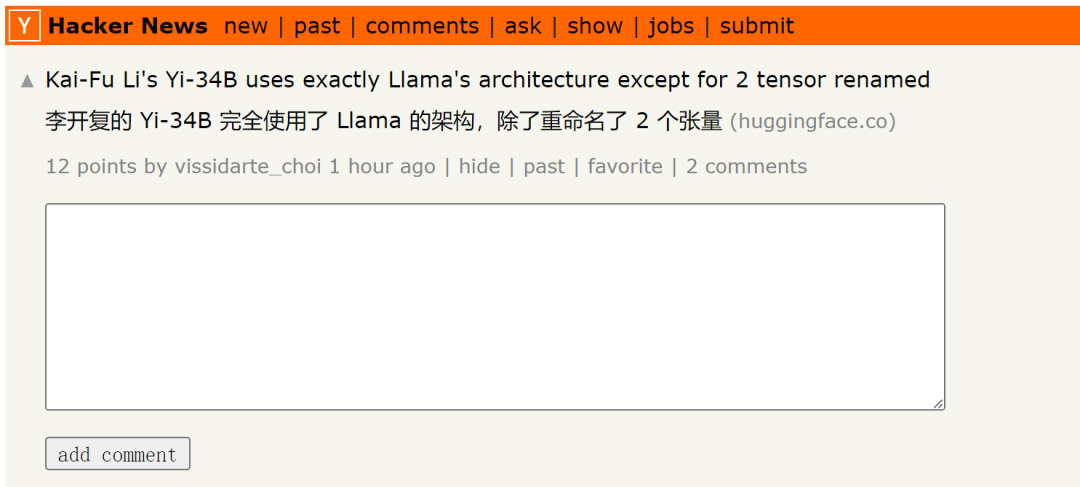
Please click this link to view the original post: https://news.ycombinator.com/item?id=38258015
The post also mentioned:
The code of Yi-34B is actually a reconstruction of the LLaMA code, but it does not seem to have made any substantial changes. This model is obviously an edit based on the original Apache version 2.0 LLaMA file, but makes no mention of LLaMA:

Yi vs LLaMA Code comparison. Code link: https://www.diffchecker.com/bJTqkvmQ/
In addition, these code changes are not submitted to the transformers project through Pull Request. , but instead attach it as external code, which may pose security risks or be unsupported by the framework. The HuggingFace leaderboard won't even benchmark this model with a context window up to 200K because it doesn't have a custom code strategy.
They claim this is a 32K model, but it is configured as a 4K model, there is no RoPE scaling configuration, and there is no explanation of how to scale (note: zero one thing before means that the model itself is on the 4K sequence for training, but can scale to 32K during inference phase). Currently, there is zero information about its fine-tuning data. They also did not provide instructions for reproducing their benchmarks, including the suspiciously high MMLU scores.
Anyone who has worked in the field of artificial intelligence for a while will not turn a blind eye to this. Is this false advertising? License violation? Was it actually cheating on the benchmark? Who cares? We could change a paper, or in this case, take all the venture capital money. At least Yi is above the standard because it is a basic model and its performance is really good
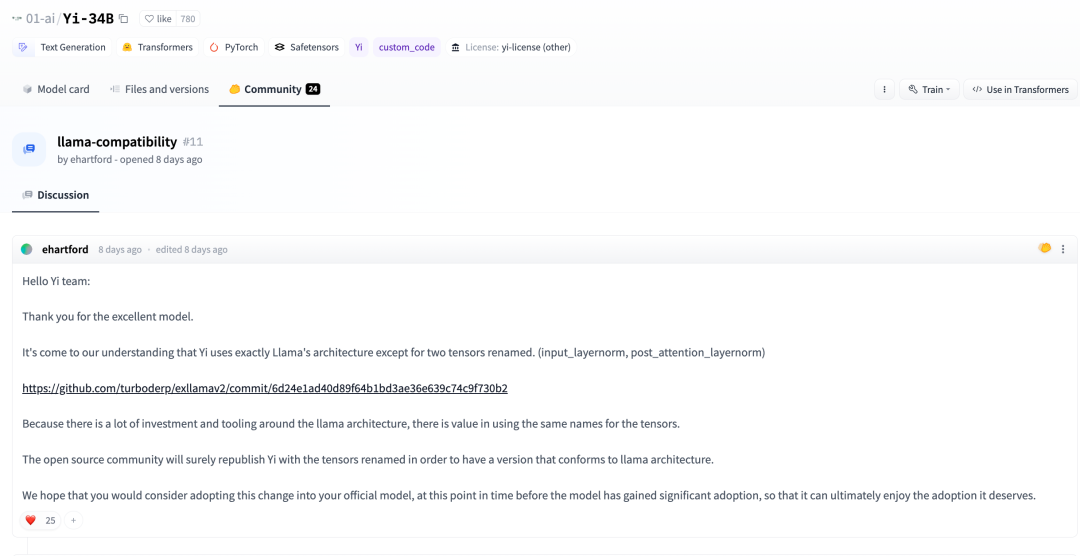
A few days ago, in the Huggingface community, a developer also pointed out:
According to our understanding, except for renaming two tensors, Yi completely adopts the LLaMA architecture. (input_layernorm, post_attention_layernorm)
#In the discussion, some netizens said: If they want to use Meta LLaMA’s architecture, code base and other related resources exactly, Must abide by the license agreement stipulated by LLaMA

In order to comply with LLaMA's open source license, a developer decided to change his name back and republish it On huggingface
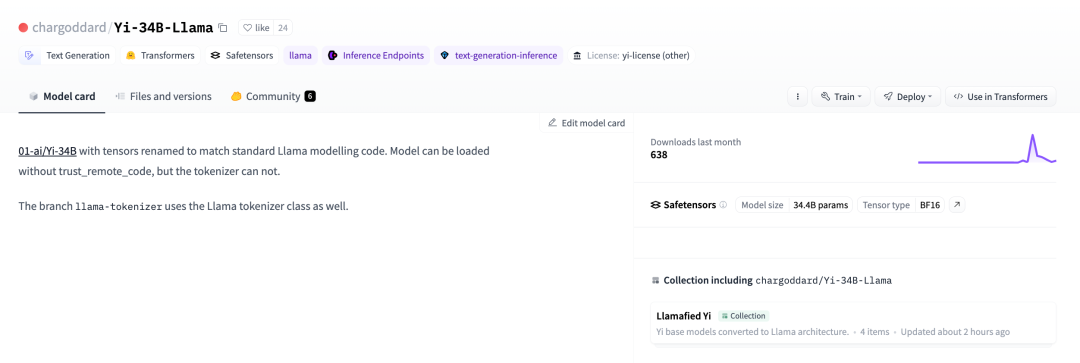 01-ai/Yi-34B, the tensors have been renamed to match the standard LLaMA model code. Related links: https://huggingface.co/chargoddard/Yi-34B-LLaMA
01-ai/Yi-34B, the tensors have been renamed to match the standard LLaMA model code. Related links: https://huggingface.co/chargoddard/Yi-34B-LLaMA
By reading this content, we can infer that the news that Jia Yangqing left Alibaba and started a business was mentioned in his circle of friends a few days ago

Regarding this matter, the Heart of the Machine also sought verification from Zero One and All Things. Lingyiwu responded:
GPT is a mature architecture recognized in the industry, and LLaMA made a summary on GPT. The structural design of the large R&D model of Zero One Thousand Things is based on the mature structure of GPT, drawing on top-level public results in the industry. At the same time, the Zero One Thousand Things team has done a lot of work on the understanding of the model and training. This is the first time we have released excellent results. one of the foundations. At the same time, Zero One Thousand Things is also continuing to explore essential breakthroughs at the model structure level.
The model structure is only part of the model training. Yi's open source model focuses on other aspects, such as data engineering, training methods, baby sitting (training process monitoring) skills, hyperparameter settings, evaluation methods, depth of understanding of the nature of evaluation indicators, and depth of research on the principles of model generalization capabilities. , the industry's top AI Infra capabilities, etc., a lot of research and development and foundation work have been invested. These tasks often play a greater role and value than the basic structure. These are also the core technologies of Zero One Wagon in the large model pre-training stage. moat.
In the process of conducting a large number of training experiments, we renamed the code according to the needs of experimental execution. We attach great importance to the feedback from the open source community and have updated the code to better integrate into the Transformer ecosystem
We are very grateful for the feedback from the community. We have just started in the open source community and hope to work with everyone to create a community. Prosperity, Yi Kaiyuan will do its best to continue to make progress
The above is the detailed content of Based on LLaMA but changing the tensor name, Kai-Fu Lee's large model caused controversy, and the official response is here. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1371
1371
 52
52

 What method is used to convert strings into objects in Vue.js?
Apr 07, 2025 pm 09:39 PM
What method is used to convert strings into objects in Vue.js?
Apr 07, 2025 pm 09:39 PM
When converting strings to objects in Vue.js, JSON.parse() is preferred for standard JSON strings. For non-standard JSON strings, the string can be processed by using regular expressions and reduce methods according to the format or decoded URL-encoded. Select the appropriate method according to the string format and pay attention to security and encoding issues to avoid bugs.
 Laravel's geospatial: Optimization of interactive maps and large amounts of data
Apr 08, 2025 pm 12:24 PM
Laravel's geospatial: Optimization of interactive maps and large amounts of data
Apr 08, 2025 pm 12:24 PM
Efficiently process 7 million records and create interactive maps with geospatial technology. This article explores how to efficiently process over 7 million records using Laravel and MySQL and convert them into interactive map visualizations. Initial challenge project requirements: Extract valuable insights using 7 million records in MySQL database. Many people first consider programming languages, but ignore the database itself: Can it meet the needs? Is data migration or structural adjustment required? Can MySQL withstand such a large data load? Preliminary analysis: Key filters and properties need to be identified. After analysis, it was found that only a few attributes were related to the solution. We verified the feasibility of the filter and set some restrictions to optimize the search. Map search based on city
 Vue and Element-UI cascade drop-down box v-model binding
Apr 07, 2025 pm 08:06 PM
Vue and Element-UI cascade drop-down box v-model binding
Apr 07, 2025 pm 08:06 PM
Vue and Element-UI cascaded drop-down boxes v-model binding common pit points: v-model binds an array representing the selected values at each level of the cascaded selection box, not a string; the initial value of selectedOptions must be an empty array, not null or undefined; dynamic loading of data requires the use of asynchronous programming skills to handle data updates in asynchronously; for huge data sets, performance optimization techniques such as virtual scrolling and lazy loading should be considered.
 How to set the timeout of Vue Axios
Apr 07, 2025 pm 10:03 PM
How to set the timeout of Vue Axios
Apr 07, 2025 pm 10:03 PM
In order to set the timeout for Vue Axios, we can create an Axios instance and specify the timeout option: In global settings: Vue.prototype.$axios = axios.create({ timeout: 5000 }); in a single request: this.$axios.get('/api/users', { timeout: 10000 }).
 Vue.js How to convert an array of string type into an array of objects?
Apr 07, 2025 pm 09:36 PM
Vue.js How to convert an array of string type into an array of objects?
Apr 07, 2025 pm 09:36 PM
Summary: There are the following methods to convert Vue.js string arrays into object arrays: Basic method: Use map function to suit regular formatted data. Advanced gameplay: Using regular expressions can handle complex formats, but they need to be carefully written and considered. Performance optimization: Considering the large amount of data, asynchronous operations or efficient data processing libraries can be used. Best practice: Clear code style, use meaningful variable names and comments to keep the code concise.
 How to use mysql after installation
Apr 08, 2025 am 11:48 AM
How to use mysql after installation
Apr 08, 2025 am 11:48 AM
The article introduces the operation of MySQL database. First, you need to install a MySQL client, such as MySQLWorkbench or command line client. 1. Use the mysql-uroot-p command to connect to the server and log in with the root account password; 2. Use CREATEDATABASE to create a database, and USE select a database; 3. Use CREATETABLE to create a table, define fields and data types; 4. Use INSERTINTO to insert data, query data, update data by UPDATE, and delete data by DELETE. Only by mastering these steps, learning to deal with common problems and optimizing database performance can you use MySQL efficiently.
 Remote senior backend engineers (platforms) need circles
Apr 08, 2025 pm 12:27 PM
Remote senior backend engineers (platforms) need circles
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineer Job Vacant Company: Circle Location: Remote Office Job Type: Full-time Salary: $130,000-$140,000 Job Description Participate in the research and development of Circle mobile applications and public API-related features covering the entire software development lifecycle. Main responsibilities independently complete development work based on RubyonRails and collaborate with the React/Redux/Relay front-end team. Build core functionality and improvements for web applications and work closely with designers and leadership throughout the functional design process. Promote positive development processes and prioritize iteration speed. Requires more than 6 years of complex web application backend
 How to optimize database performance after mysql installation
Apr 08, 2025 am 11:36 AM
How to optimize database performance after mysql installation
Apr 08, 2025 am 11:36 AM
MySQL performance optimization needs to start from three aspects: installation configuration, indexing and query optimization, monitoring and tuning. 1. After installation, you need to adjust the my.cnf file according to the server configuration, such as the innodb_buffer_pool_size parameter, and close query_cache_size; 2. Create a suitable index to avoid excessive indexes, and optimize query statements, such as using the EXPLAIN command to analyze the execution plan; 3. Use MySQL's own monitoring tool (SHOWPROCESSLIST, SHOWSTATUS) to monitor the database health, and regularly back up and organize the database. Only by continuously optimizing these steps can the performance of MySQL database be improved.
