

Yolo V8: A closer look at its advanced capabilities and new features

Yolo is a computer vision model widely considered to be one of the most powerful and well-known currently. The breakthrough technology, called Yolo, short for "You Only Look Once," is a method of detecting objects at almost instantaneous processing speeds. Yolo V8 is the latest version of this technology and an improvement over previous versions. This article will conduct a comprehensive analysis of Yolo V8, explain its structure in detail and record its development process

Explain Yolo and its working principle
Yolo is an algorithm that can identify and locate objects in still photos and dynamic videos. It does this by analyzing the content of the image. Yolo is an alternative to traditional object detection algorithms, which typically process images by continuously applying the same method in a loop. After meshing the image, each grid cell independently predicts different bounding boxes and class probabilities. Yolo is able to recognize objects in real time because it only needs to process the image once.

#The main goal of Yolo is to utilize a single convolutional neural network (CNN) for prediction of bounding boxes and class probabilities. The basis of this concept is to use a network to accomplish both tasks simultaneously. The network is trained on a large-scale dataset of labeled photos to learn patterns and features associated with a variety of different objects. During the inference phase, the neural network will generate predictions of bounding boxes and class probabilities for each image as input
These results will then be displayed
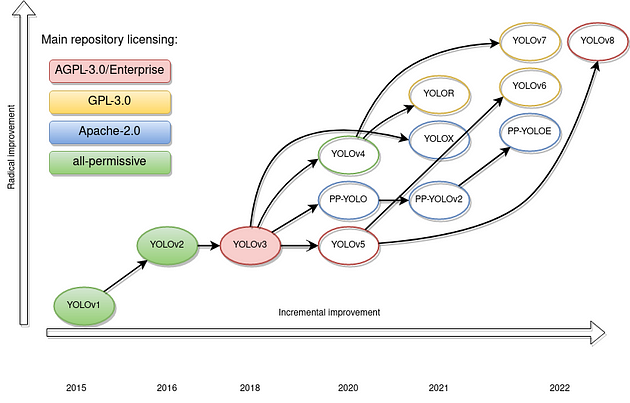
Yolo’s evolution : From Yolo V1 to Yolo V8
Yolo has gone through multiple versions, and each version has enhanced the core algorithm and added new features. Yolo V1 is the first version that provides grid-based image segmentation and bounding box prediction for the first time. However, it also suffers from some problems, including low recall and inaccurate locations. Yolo V2 introduces anchor boxes and multi-scale methods to overcome these problems.
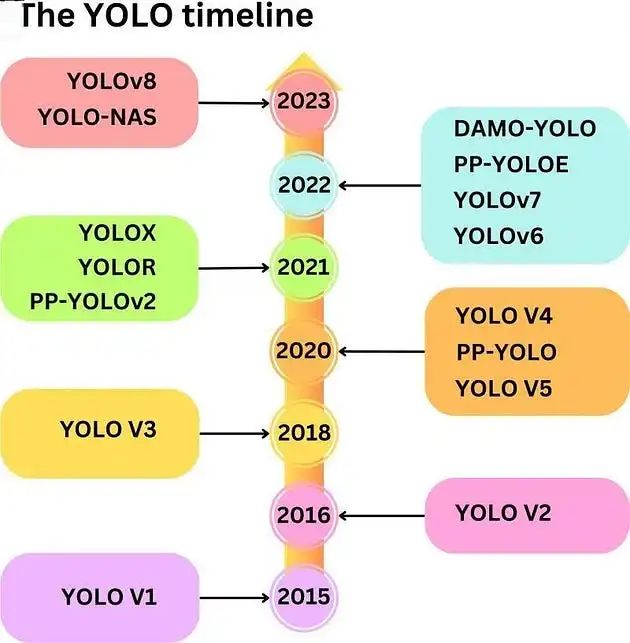
Yolo V3 has made a major breakthrough compared to previous versions because it incorporates feature pyramid networks and multiple detection scales. This implementation is cutting-edge in terms of accuracy and speed, making it an industry leader. With the launch of Yolo V4, many new features, such as CSPDarknet53 backbone network and PANet for feature fusion, are also available
Appreciate the structural components of the Yolo model
with earlier Compared with previous versions, the Yolo V8 architecture has made significant structural progress. It not only has a head, but also a neck and nervous system. The task of extracting high-level information from input photos falls under the responsibility of the backbone network. Yolo V8 uses an enhanced version of the CSPDarknet53 architecture, which has proven to be very effective at recording accurate location data. This architecture was developed by Yolo.
The task of the neck network is to fuse scale-invariant features. Path Aggregation Network, more commonly known as PANet, is the main backbone network of Yolo V8. PANet provides a more accurate feature representation by combining data collected from multiple layers of the underlying network.

#After the features are fused, they are input into the head network, and then predictions are made based on the information. Yolo V8, like its predecessor, provides bounding box and class probability predictions for each grid cell. However, through improved design and loss function, the accuracy and stability of the system have been improved
Improvements of Yolo V8 compared to previous versions
Yolo V8 relative There are many significant improvements over its predecessor. The introduction of the CSPDarknet53 backbone network significantly improves the model's ability to perceive spatial information. Due to better feature representation, the efficiency of object detection is significantly improved.
# Another significant improvement of Yolo V8 is the use of PANet as the neck network. By providing fast feature fusion, PANet ensures that the model can obtain features from multiple layers of the underlying network. These features can be obtained from the model. As a result, object recognition is improved, which is particularly advantageous when dealing with objects of different sizes.
Due to the new architectural changes and loss algorithms introduced in Yolo V8, the accuracy and stability of the model have been significantly improved. These improvements significantly improve the performance of Yolo V8 in target detection tasks, making a greater improvement compared to previous versions
Key Features of Yolo V8
The success of Yolo V8 can be attributed to its several outstanding features and product highlights. It is particularly suitable for applications that require fast and accurate object recognition because it can be processed in real time. This makes it an excellent choice. Yolo V8’s real-time processing capabilities provide a wide range of options for computer vision and artificial intelligence applications
One of the many features of Yolo V8 is its ability to differentiate between objects of different sizes. Yolo V8 is very reliable when dealing with real-life scenes as it provides a multi-scale approach to handling objects of different sizes.
In addition, the bounding box predictions generated by Yolo V8 are very accurate. This is critical for activities that require very precise bounding boxes, such as object tracking and localization.
Exploring the Ultralytics Yolo V8 implementation
Ultralytics’ Yolo V8 solution is extremely valuable to the computer vision community. Their implementation has a simple user interface, which means that both academics and programmers can use it. It provides ready-made models as well as resources for building your own models and applying them to your own datasets, both in addition to the main features provided by Yolo V8 , Ultralytics’ implementation also supports the simultaneous use of multiple GPUs and multiple levels of inference. These improvements significantly improve the functionality and performance of Yolo V8.
 Additionally, Yolo V8 plays an important role in medical applications, Especially in the field of medical image processing and diagnosis, it can help these processes. Yolo V8 has the ability to effectively identify and locate abnormalities in medical images, helping doctors make more informed decisions
Additionally, Yolo V8 plays an important role in medical applications, Especially in the field of medical image processing and diagnosis, it can help these processes. Yolo V8 has the ability to effectively identify and locate abnormalities in medical images, helping doctors make more informed decisions
Yolo V8’s application in deep learning and machine learning
Yolo V8 has achieved significant progress on multiple object detection tasks in deep learning and machine learning. With its simplified system design and real-time processing capabilities, it has successfully improved many object detection tasks
Both researchers and practitioners can use Yolo V8’s architecture and training methods to build your own target recognition model. These strategies apply to both groups. Yolo V8 has laid a solid foundation, and it is now even easier to build on it due to the availability of pre-trained models and implementation libraries such as Ultralytics. Additionally, Yolo V8 can be used as a standard to compare with other object detection algorithms to see how well they perform. It is considered a reliable standard due to its cutting-edge accuracy and lightning speed.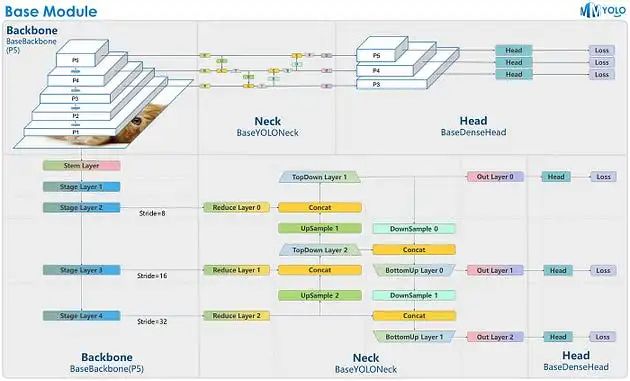 Yolo V8 Performance and Accuracy Analysis
Yolo V8 Performance and Accuracy Analysis
Yolo V8 is incredibly accurate and efficient when performing target recognition tasks. Unlike most other algorithms, it can process both still photos and dynamic videos in real time. Due to the accuracy of the bounding box predictions it generates, it is well suited for a variety of applications.
The Yolo V8 architecture represents a significant advancement compared to earlier versions. Not only does it have a head, it also has a neck and a nervous system. The task of extracting high-level information from input photos falls under the responsibility of the backbone network. Yolo V8 uses an enhanced version of the CSPDarknet53 architecture, which has proven to be very efficient at recording accurate location data. This architecture was developed by Yolo. The fusion of scale-invariant features is the responsibility of the neck network. Path Aggregation Network, more commonly known as PANet, is the main backbone network of Yolo V8. PANet provides a more accurate feature representation by combining data collected from multiple layers of the underlying networkAfter feature fusion, they are sent to the head network, and then Make predictions based on information. Yolo V8, like its predecessor, provides predictions of bounding boxes and class probabilities for each grid cell. However, as a result of these innovative developments in design and loss functions, the accuracy and robustness of the system have improved. 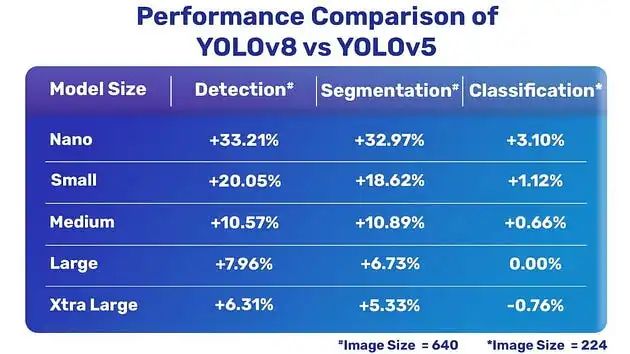
Yolo V8 Research Papers and Other Resources
Those who want to know more about this algorithm can read the academic paper "YOLOv8: An improved version of the Yolo series for target detection", which is detailed in this paper The process of this algorithm was studied. The experimental results, loss functions and architectural improvements of Yolo V8 are described in the paper
Research papers and various internet websites also provide information that can be used to learn more about Yolo V8 and how to use it of additional materials. Users can find a variety of Yolo V8 materials, such as tutorials and pre-trained models, on Ultralytics’ official website. These materials can be used by academics and practitioners to better understand Yolo V8 and its characteristics.
Conclusion: Yolo and the future of object detection
The emergence of Yolo V8 marks a significant advance in the field of object recognition, opening up both in terms of speed and accuracy new areas. Due to its fast processing speed and efficiency, it has wide application value in computer vision and artificial intelligence applications
With the continuous development of deep learning and computer vision, Yolo and other targets The detection algorithm will undoubtedly undergo more improvements and refinements. Yolo V8 lays the foundation for further future development, with researchers and practitioners leveraging its architecture and methods to build more efficient and accurate models than ever before
Due to Yolo V8’s advanced processing capabilities and real-time performance, the object recognition market has undergone tremendous changes. It changes the future development direction of target detection and opens up a new path for the application of computer vision and artificial intelligence
The above is the detailed content of Yolo V8: A closer look at its advanced capabilities and new features. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1377
1377
 52
52

 Bytedance Cutting launches SVIP super membership: 499 yuan for continuous annual subscription, providing a variety of AI functions
Jun 28, 2024 am 03:51 AM
Bytedance Cutting launches SVIP super membership: 499 yuan for continuous annual subscription, providing a variety of AI functions
Jun 28, 2024 am 03:51 AM
This site reported on June 27 that Jianying is a video editing software developed by FaceMeng Technology, a subsidiary of ByteDance. It relies on the Douyin platform and basically produces short video content for users of the platform. It is compatible with iOS, Android, and Windows. , MacOS and other operating systems. Jianying officially announced the upgrade of its membership system and launched a new SVIP, which includes a variety of AI black technologies, such as intelligent translation, intelligent highlighting, intelligent packaging, digital human synthesis, etc. In terms of price, the monthly fee for clipping SVIP is 79 yuan, the annual fee is 599 yuan (note on this site: equivalent to 49.9 yuan per month), the continuous monthly subscription is 59 yuan per month, and the continuous annual subscription is 499 yuan per year (equivalent to 41.6 yuan per month) . In addition, the cut official also stated that in order to improve the user experience, those who have subscribed to the original VIP
 Context-augmented AI coding assistant using Rag and Sem-Rag
Jun 10, 2024 am 11:08 AM
Context-augmented AI coding assistant using Rag and Sem-Rag
Jun 10, 2024 am 11:08 AM
Improve developer productivity, efficiency, and accuracy by incorporating retrieval-enhanced generation and semantic memory into AI coding assistants. Translated from EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, author JanakiramMSV. While basic AI programming assistants are naturally helpful, they often fail to provide the most relevant and correct code suggestions because they rely on a general understanding of the software language and the most common patterns of writing software. The code generated by these coding assistants is suitable for solving the problems they are responsible for solving, but often does not conform to the coding standards, conventions and styles of the individual teams. This often results in suggestions that need to be modified or refined in order for the code to be accepted into the application
 Can fine-tuning really allow LLM to learn new things: introducing new knowledge may make the model produce more hallucinations
Jun 11, 2024 pm 03:57 PM
Can fine-tuning really allow LLM to learn new things: introducing new knowledge may make the model produce more hallucinations
Jun 11, 2024 pm 03:57 PM
Large Language Models (LLMs) are trained on huge text databases, where they acquire large amounts of real-world knowledge. This knowledge is embedded into their parameters and can then be used when needed. The knowledge of these models is "reified" at the end of training. At the end of pre-training, the model actually stops learning. Align or fine-tune the model to learn how to leverage this knowledge and respond more naturally to user questions. But sometimes model knowledge is not enough, and although the model can access external content through RAG, it is considered beneficial to adapt the model to new domains through fine-tuning. This fine-tuning is performed using input from human annotators or other LLM creations, where the model encounters additional real-world knowledge and integrates it
 Seven Cool GenAI & LLM Technical Interview Questions
Jun 07, 2024 am 10:06 AM
Seven Cool GenAI & LLM Technical Interview Questions
Jun 07, 2024 am 10:06 AM
To learn more about AIGC, please visit: 51CTOAI.x Community https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou is different from the traditional question bank that can be seen everywhere on the Internet. These questions It requires thinking outside the box. Large Language Models (LLMs) are increasingly important in the fields of data science, generative artificial intelligence (GenAI), and artificial intelligence. These complex algorithms enhance human skills and drive efficiency and innovation in many industries, becoming the key for companies to remain competitive. LLM has a wide range of applications. It can be used in fields such as natural language processing, text generation, speech recognition and recommendation systems. By learning from large amounts of data, LLM is able to generate text
 To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
To provide a new scientific and complex question answering benchmark and evaluation system for large models, UNSW, Argonne, University of Chicago and other institutions jointly launched the SciQAG framework
Jul 25, 2024 am 06:42 AM
Editor |ScienceAI Question Answering (QA) data set plays a vital role in promoting natural language processing (NLP) research. High-quality QA data sets can not only be used to fine-tune models, but also effectively evaluate the capabilities of large language models (LLM), especially the ability to understand and reason about scientific knowledge. Although there are currently many scientific QA data sets covering medicine, chemistry, biology and other fields, these data sets still have some shortcomings. First, the data form is relatively simple, most of which are multiple-choice questions. They are easy to evaluate, but limit the model's answer selection range and cannot fully test the model's ability to answer scientific questions. In contrast, open-ended Q&A
 Five schools of machine learning you don't know about
Jun 05, 2024 pm 08:51 PM
Five schools of machine learning you don't know about
Jun 05, 2024 pm 08:51 PM
Machine learning is an important branch of artificial intelligence that gives computers the ability to learn from data and improve their capabilities without being explicitly programmed. Machine learning has a wide range of applications in various fields, from image recognition and natural language processing to recommendation systems and fraud detection, and it is changing the way we live. There are many different methods and theories in the field of machine learning, among which the five most influential methods are called the "Five Schools of Machine Learning". The five major schools are the symbolic school, the connectionist school, the evolutionary school, the Bayesian school and the analogy school. 1. Symbolism, also known as symbolism, emphasizes the use of symbols for logical reasoning and expression of knowledge. This school of thought believes that learning is a process of reverse deduction, through existing
 SOTA performance, Xiamen multi-modal protein-ligand affinity prediction AI method, combines molecular surface information for the first time
Jul 17, 2024 pm 06:37 PM
SOTA performance, Xiamen multi-modal protein-ligand affinity prediction AI method, combines molecular surface information for the first time
Jul 17, 2024 pm 06:37 PM
Editor | KX In the field of drug research and development, accurately and effectively predicting the binding affinity of proteins and ligands is crucial for drug screening and optimization. However, current studies do not take into account the important role of molecular surface information in protein-ligand interactions. Based on this, researchers from Xiamen University proposed a novel multi-modal feature extraction (MFE) framework, which for the first time combines information on protein surface, 3D structure and sequence, and uses a cross-attention mechanism to compare different modalities. feature alignment. Experimental results demonstrate that this method achieves state-of-the-art performance in predicting protein-ligand binding affinities. Furthermore, ablation studies demonstrate the effectiveness and necessity of protein surface information and multimodal feature alignment within this framework. Related research begins with "S
 Laying out markets such as AI, GlobalFoundries acquires Tagore Technology's gallium nitride technology and related teams
Jul 15, 2024 pm 12:21 PM
Laying out markets such as AI, GlobalFoundries acquires Tagore Technology's gallium nitride technology and related teams
Jul 15, 2024 pm 12:21 PM
According to news from this website on July 5, GlobalFoundries issued a press release on July 1 this year, announcing the acquisition of Tagore Technology’s power gallium nitride (GaN) technology and intellectual property portfolio, hoping to expand its market share in automobiles and the Internet of Things. and artificial intelligence data center application areas to explore higher efficiency and better performance. As technologies such as generative AI continue to develop in the digital world, gallium nitride (GaN) has become a key solution for sustainable and efficient power management, especially in data centers. This website quoted the official announcement that during this acquisition, Tagore Technology’s engineering team will join GLOBALFOUNDRIES to further develop gallium nitride technology. G
