

About a year ago I was assigned the task of extracting and structuring data from files, mainly data contained in tables. I had no prior knowledge of computer vision and was having a hard time finding a suitable "plug and play" solution. The options available at the time were either solutions based on the latest neural networks (NN), which were large and cumbersome, or simpler solutions based on OpenCV, which were not consistent enough.
Inspired by existing OpenCV scripts, I developed a simple and consistent way to extract tables and made it into an open source Python library: img2table
The content that needs to be rewritten is: Link: https://github.com/xavctn/img2table

Compared to deep learning solutions, this lightweight package requires no training and minimal parameterization. It provides the following functionality:
You can use pip to install this library, and you can use it after the installation is complete
pip install img2table
To identify tables in a document, you only need to call a function:
从img2table.document导入Image类# 图像实例化 img = Image(src="myimage.jpg")# 表格识别 img_tables = img.extract_tables()# 表格识别结果 img_tables[ExtractedTable(title=None, bbox=(10, 8, 745, 314),shape=(6, 3)), ExtractedTable(title=None, bbox=(936, 9, 1129, 111),shape=(2, 2))]
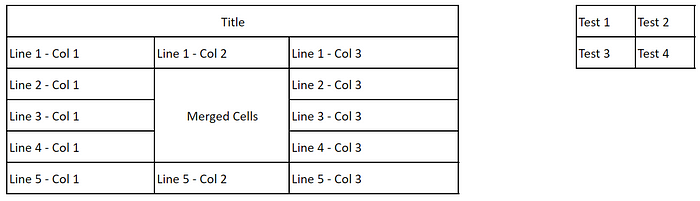
The content that needs to be rewritten is: the image used in the above example
If we want to extract the content of the table , you need to use an OCR tool. You can follow the steps below:
from img2table.document import PDFfrom img2table.ocr import TesseractOCR# Instantiation of the pdfpdf = PDF(src="mypdf.pdf")# Instantiation of the OCR, Tesseract, which requires prior installationocr = TesseractOCR(lang="eng")# Table identification and extractionpdf_tables = pdf.extract_tables(ocr=ocr)# We can also create an excel file with the tablespdf.to_xlsx('tables.xlsx',ocr=ocr)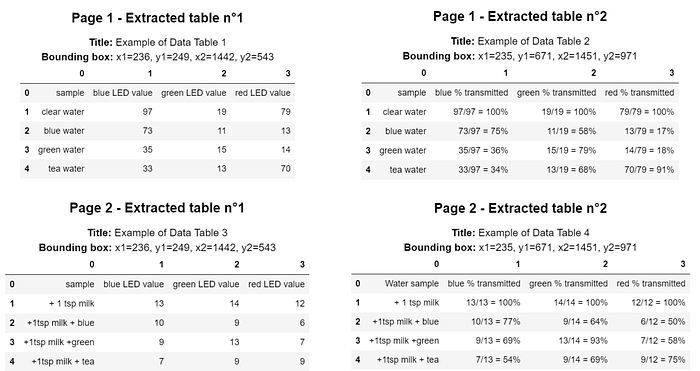
The sample table is a sample extracted from a PDF file
Finally, in simple cases, the extraction of "borderless" tables can be performed by setting the `borderless_tables` parameter. This allows detection of tables where the cells do not need to be completely surrounded by borders.
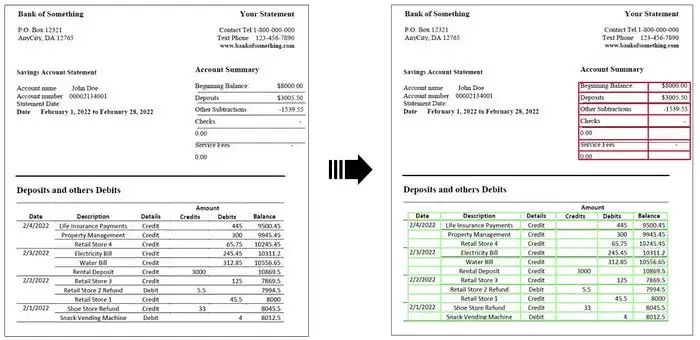
No need to change the original meaning, what needs to be rewritten is: "Borderless" table extraction example
This is the full content ! In fact, the repository is not complicated as our goal is to simplify it as much as possible and avoid introducing other solutions that may bring complexity
Please visit the project's GitHub page for more details Documentation and examples: https://github.com/xavctn/img2table
All image processing uses OpenCV and opencv -python library completed. However, this is still pretty basic.
The core of the algorithm is the Hough transform, which is able to identify straight lines in the image, allowing us to detect horizontal and vertical lines in the image
需要重写的内容是:cv2.HoughLinesP(img, rho, theta, threshold, None, minLinLength, maxLineGap)
After this, we need to do some processing on the lines in order to identify the cells from them and further identify the tables from the cells
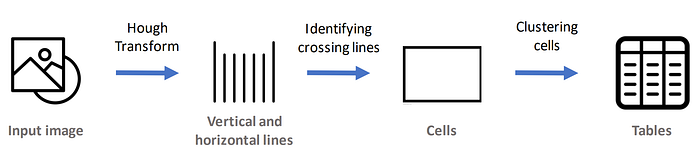
Implementation of simplified algorithm representation
Most calculations are done using Polars for good performance and speed.
The above is the detailed content of Extract table from image using Python. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



