


November 16 news, Google recently issued a press release introducing Mirasol, a small artificial intelligence model that can answer questions about videos and set new records.
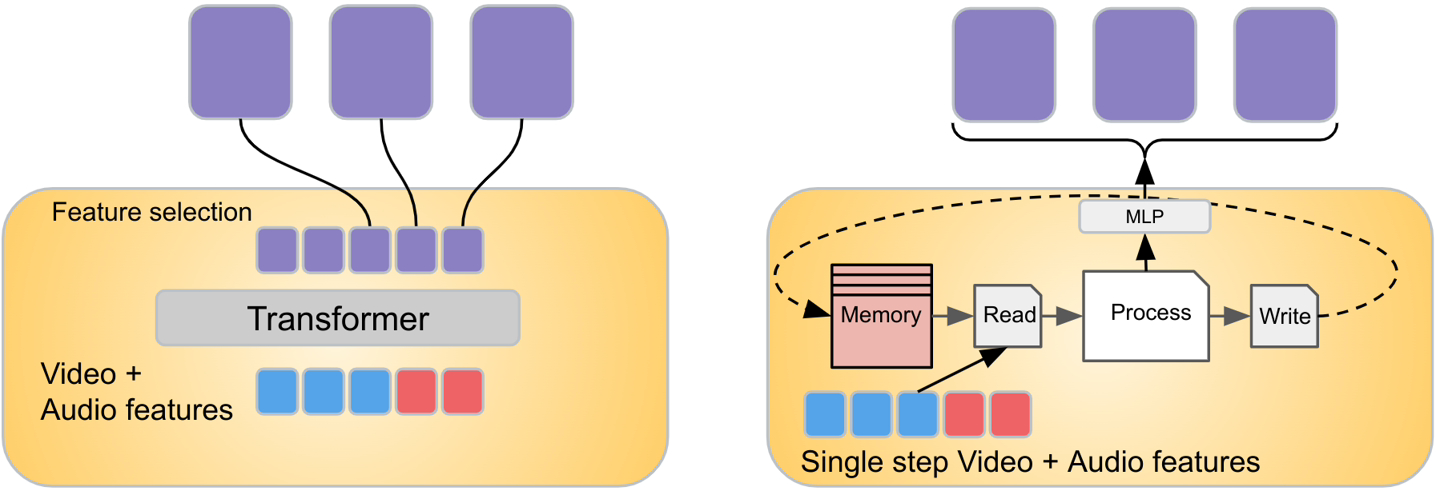
It is currently difficult for AI models to handle different data streams. If you want AI to understand video, you need to integrate information from different modalities such as video, audio, and text. This greatly increases the difficulty.
Researchers at Google and Google Deepmind have proposed new methods to extend multimodal understanding to the domain of long videos.
With the Mirasol AI model, the team worked to solve two key challenges:
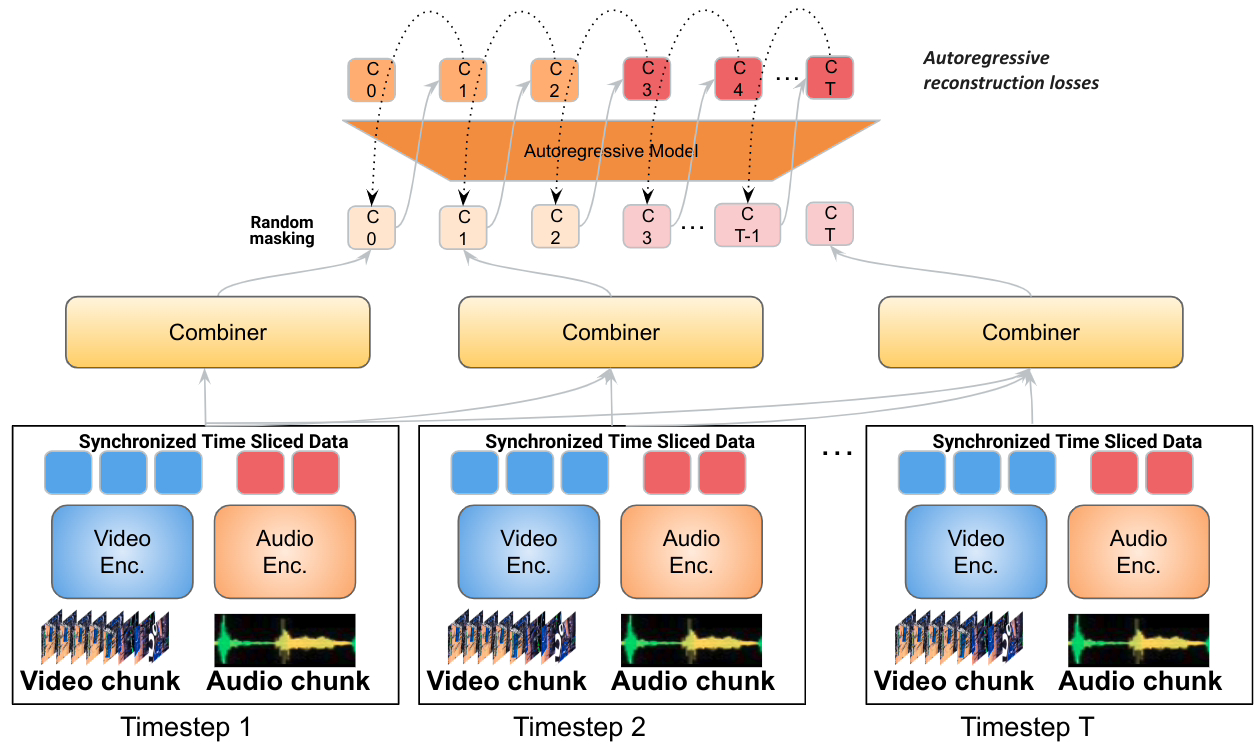
In Mirasol, Google adopts the combiner and autoregressive converter model
This model component will process the time-synchronized video and audio signals, and then split the video into An independent fragment
transformer processes each fragment and learns the connections between each fragment, and then uses another transformer to process the contextual text. The two components exchange information about their respective inputs.
A new transformation module called Combiner is able to extract a common representation from each fragment and compress the data through dimensionality reduction. Each clip contains 4 to 64 frames, and the model currently has 3 billion parameters and can handle videos from 128 to 512 frames
In testing, Mirasol3B was used in video problem analysis It reaches a new benchmark in terms of size, is significantly smaller, and can handle longer videos. By using a variant of the combiner with memory, the team was able to further reduce the required computing power by 18%
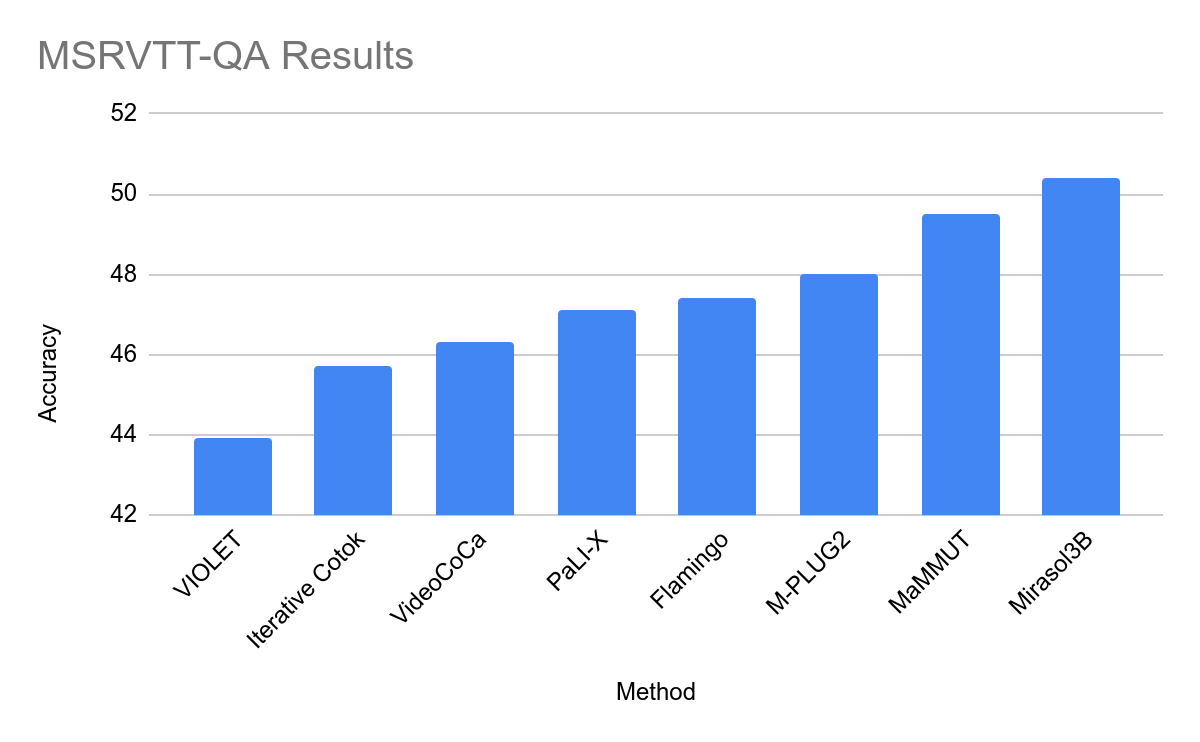
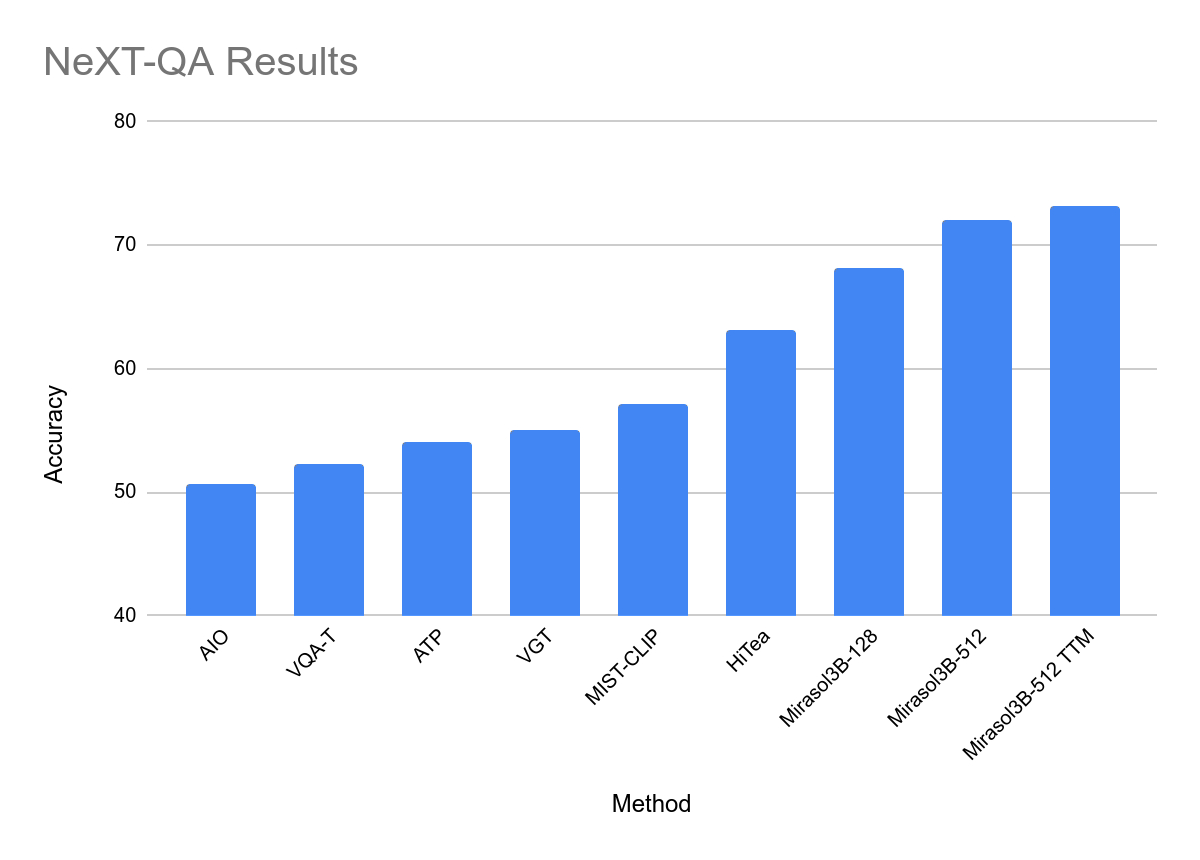
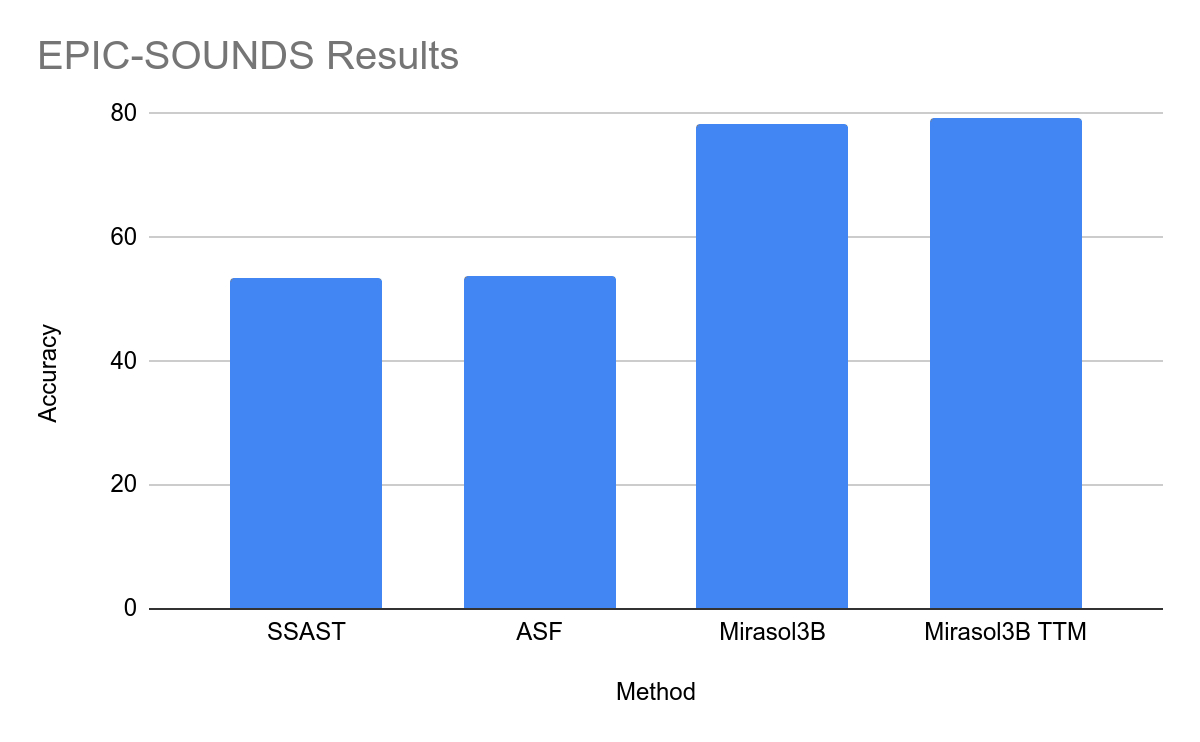
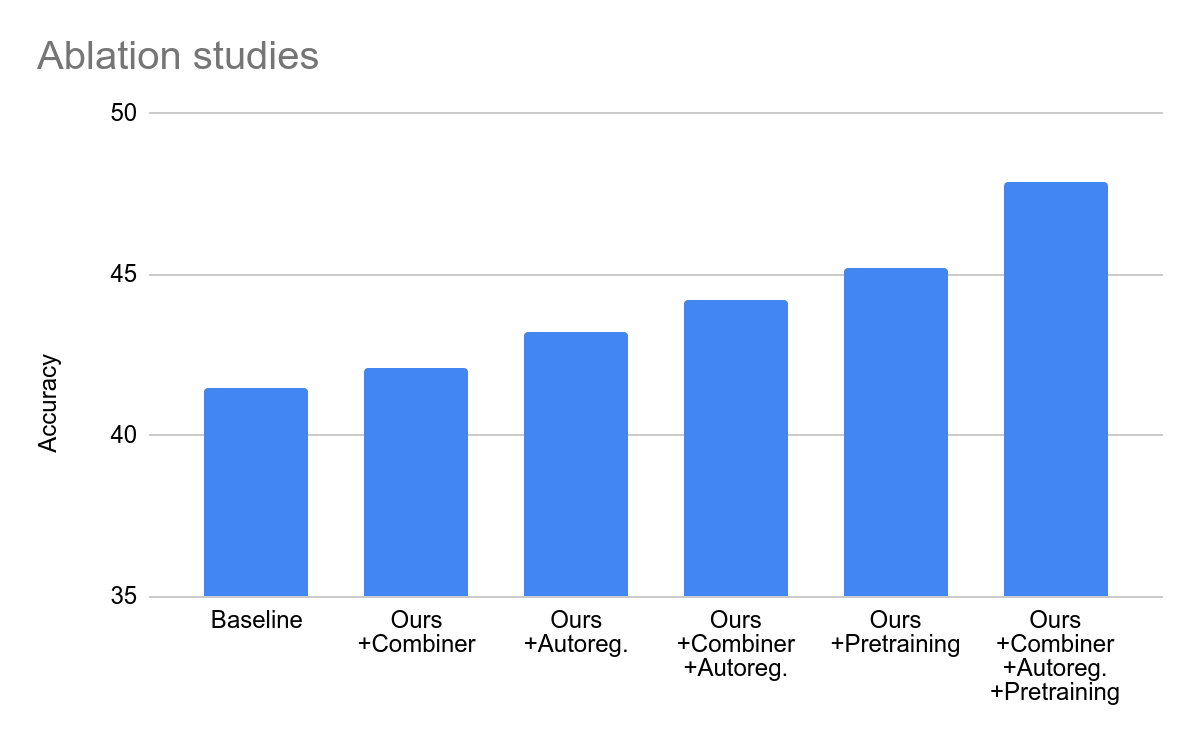
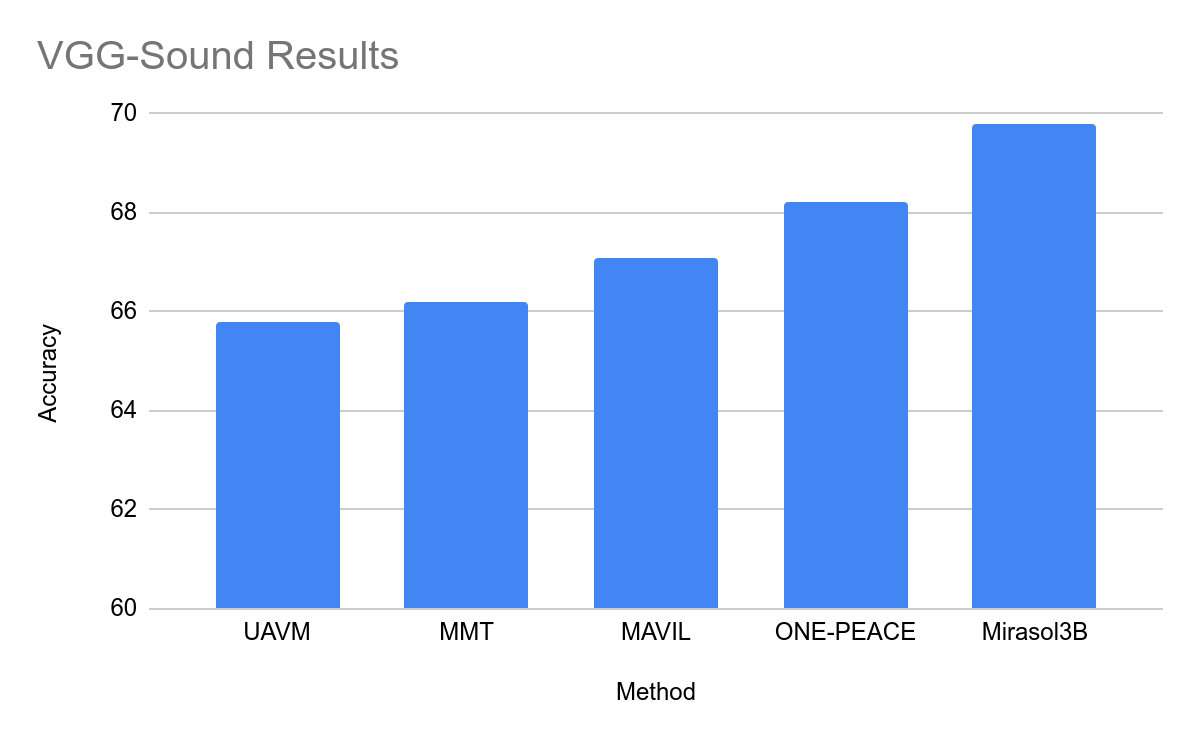
This site attaches the official press release of Mirasol. Interested users can read it in depth.
The above is the detailed content of Google launches Mirasol: 3 billion parameters, extending multimodal understanding to long videos. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



