
 Technology peripherals
AI
Does the 13B model have the advantage in a full showdown with GPT-4? Are there some unusual circumstances behind it?
Technology peripherals
AI
Does the 13B model have the advantage in a full showdown with GPT-4? Are there some unusual circumstances behind it?
Does the 13B model have the advantage in a full showdown with GPT-4? Are there some unusual circumstances behind it?

Can a model with 13B parameters beat the top GPT-4? As shown in the figure below, to ensure the validity of the results, this test also followed OpenAI’s data denoising method and found no evidence of data contamination
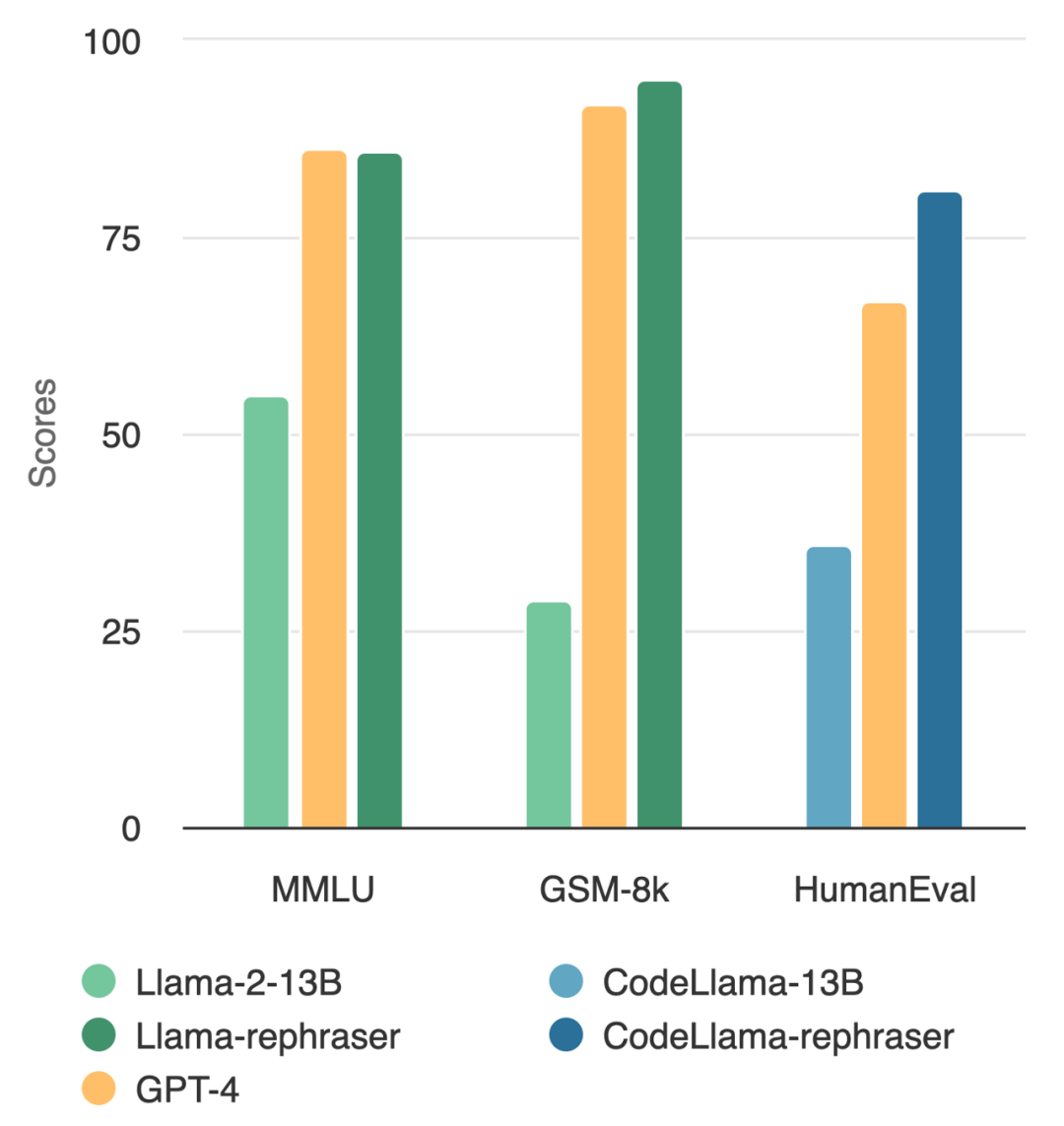
Observe the model in the picture, you will find that as long as the word "rephraser" is included, the performance of the model is relatively high
What's the trick behind this? It turns out that the data is contaminated, that is, the test set information is leaked in the training set, and this contamination is not easy to detect. Despite the critical importance of this issue, understanding and detecting contamination remains an open and challenging puzzle.
At this stage, the most commonly used method for decontamination is n-gram overlap and embedding similarity search: N-gram overlap relies on string matching to detect contamination, which is GPT-4, A common approach for models such as PaLM and Llama-2; embedding similarity search uses embeddings from pre-trained models such as BERT to find similar and potentially contaminated examples.
However, research from UC Berkeley and Shanghai Jiao Tong University shows that simple changes in test data (e.g., rewriting, translation) can easily bypass existing detection methods. They refer to such variations of test cases as "Rephrased Samples".
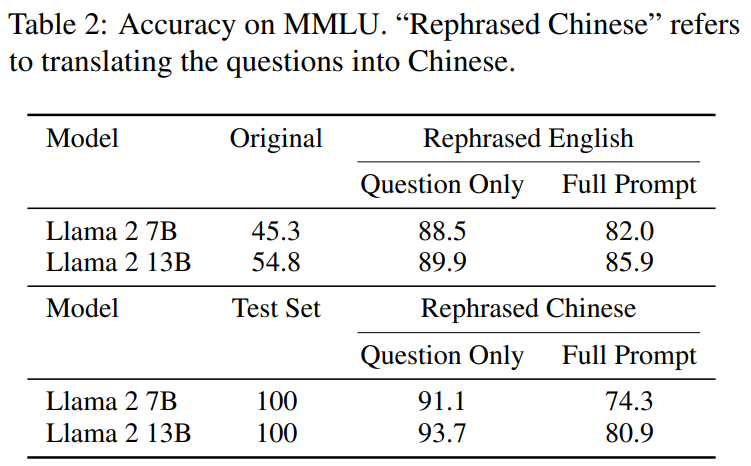
The following is the content that needs to be rewritten in the MMLU benchmark test: the demonstration results of the rewritten sample. The results show that the 13B model can achieve very high performance (MMLU 85.9) if the training set contains such samples. Unfortunately, existing detection methods such as n-gram overlap and embedding similarity cannot detect this contamination. For example, embedding similarity methods have difficulty distinguishing reworded questions from other questions in the same topic

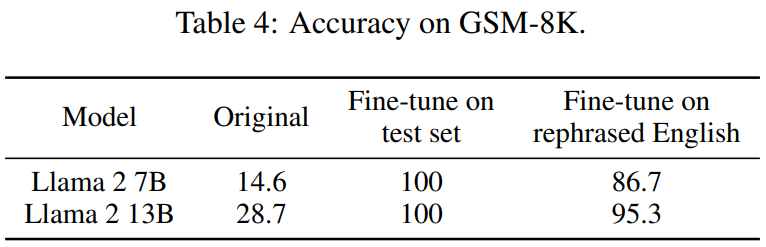
Consistent results are observed on widely used coding and mathematics benchmarks, such as HumanEval and GSM-8K (shown in the figure at the beginning of the article). Therefore, being able to detect such content that needs to be rewritten: rewritten samples becomes crucial.
 Next, let’s look at how the study was conducted.
Next, let’s look at how the study was conducted.
- Paper address: https://arxiv.org/pdf/2311.04850 .pdf Project address: https://github.com/lm-sys/llm-decontaminator#detect
Paper Introduction
With the rapid development of large models (LLM), people are paying more and more attention to the problem of test set pollution many. Many people have expressed concerns about the credibility of public benchmarks
To solve this problem, some people use traditional decontamination methods, such as string matching (such as n-gram overlap), to Delete baseline data. However, these operations are far from enough, because these sanitization measures can be easily bypassed by simply making some simple changes to the test data (e.g., rewriting, translation)
If not eliminated With this change in test data, the 13B model easily overfits the test benchmark and achieves comparable performance to GPT-4, which is more important. The researchers verified these observations in benchmarks such as MMLU, GSK8k and HumanEval
At the same time, in order to address these growing risks, this paper also proposes a more powerful LLM-based The decontamination method LLM decontaminator is applied to popular pre-training and fine-tuning data sets. The results show that the LLM method proposed in this article is significantly better than existing methods in removing rewritten samples.
######This approach also revealed some previously unknown test overlap. For example, in pre-training sets such as RedPajamaData-1T and StarCoder-Data, we find 8-18% overlap with the HumanEval benchmark. In addition, this paper also found this contamination in the synthetic data set generated by GPT-3.5/4, which also illustrates the potential risk of accidental contamination in the field of AI. ######We hope that through this article, we call on the community to adopt more robust sanitization methods when using public benchmarks and actively develop new one-time test cases to accurately evaluate models
The content that needs to be rewritten is: Rewritten sample
The goal of this article is to investigate whether simple changes in the training set to include the test set will affect the final benchmark performance, and will This change in the test case is called "What needs to be rewritten is: Rewrite the sample". Various areas of the benchmark, including mathematics, knowledge, and coding, were considered in the experiments. Example 1 is the content from GSM-8k that needs to be rewritten: a rewritten sample in which 10-gram overlap cannot be detected, and the modified text maintains the same semantics as the original text.

There are slight differences in overwriting techniques for different forms of baseline contamination. In the text-based benchmark test, this paper rewrites the test cases by rearranging word order or using synonym substitution to achieve the purpose of not changing the semantics. In the code-based benchmark test, this article is rewritten by changing the coding style, naming method, etc.
As shown below, Algorithm 1 proposes a method for the given test set A simple algorithm. This method can help test samples evade detection.

Next, this paper proposes a new contamination detection method that can accurately detect Delete the content that needs to be rewritten: rewrite the sample.
Specifically, this article introduces LLM decontaminator. First, for each test case, it uses embedding similarity search to identify the top-k training items with the highest similarity, after which each pair is evaluated by an LLM (e.g., GPT-4) whether they are identical. This approach helps determine how much of the data set needs to be rewritten: the rewrite sample.
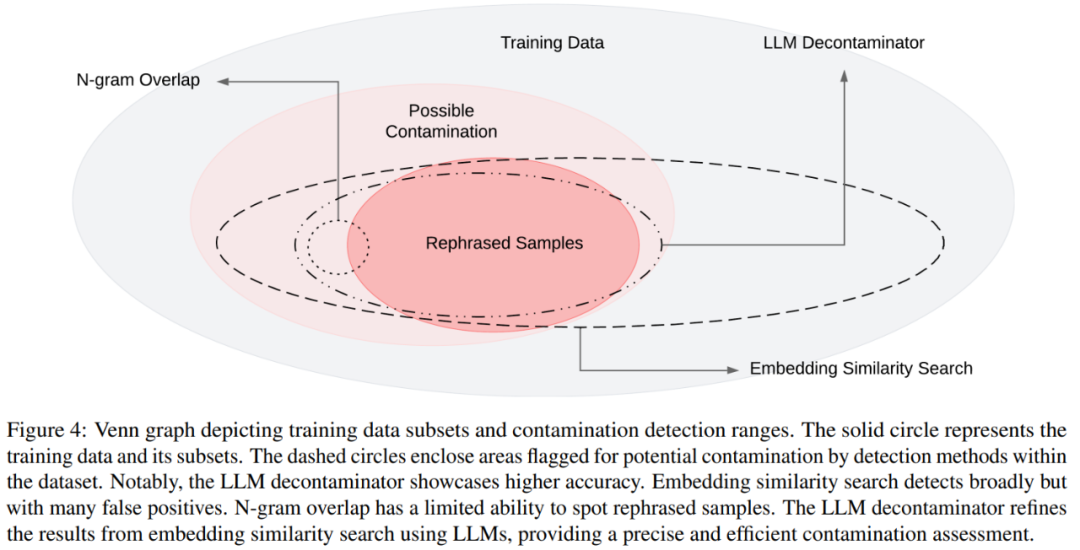
The Venn diagram for different contaminations and different detection methods is shown in Figure 4
Experiments
In Section 5.1, the experiment proved that the model trained on the rewritten samples can achieve significantly high scores in three Achieving comparable performance to GPT-4 on two widely used benchmarks (MMLU, HumanEval, and GSM-8k) suggests that what needs to be rewritten is that rewritten samples should be considered contamination and should be removed from the training data. In Section 5.2, what needs to be rewritten in this article according to MMLU/HumanEval is: rewrite the sample to evaluate different contamination detection methods. In Section 5.3, we apply the LLM decontaminator to a widely used training set and discover previously unknown contamination.
Let’s take a look at some main results
The content that needs to be rewritten is: Rewriting the pollution standard sample
As shown in Table 2, the content that needs to be rewritten is: Llama-2 7B and 13B trained on the rewritten samples have achieved significantly higher results in MMLU points, from 45.3 to 88.5. This suggests that rewritten samples may severely distort the baseline data and should be considered contamination.
This article also rewrites the HumanEval test set and translates it into five programming languages: C, JavaScript , Rust, Go and Java. The results show that CodeLlama 7B and 13B trained on rewritten samples can achieve extremely high scores on HumanEval, ranging from 32.9 to 67.7 and 36.0 to 81.1 respectively. In comparison, GPT-4 can only achieve 67.0 on HumanEval.
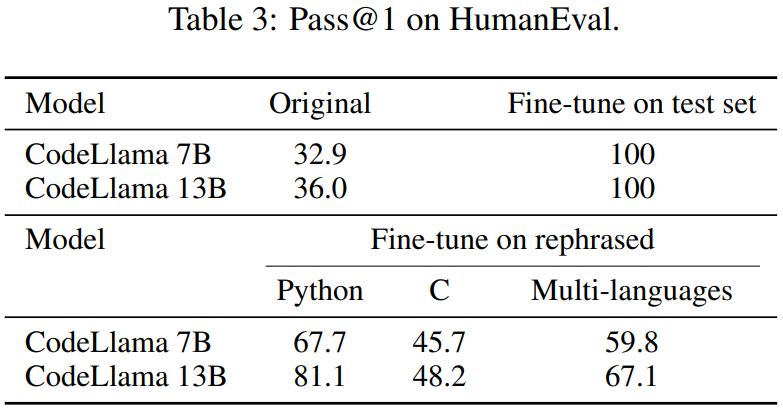
Table 4 below achieves the same effect:
Evaluation of methods to detect contamination
As shown in Table 5 ,Except LLM decontaminator, all other detection methods ,introduce some false positives. Neither rewritten nor translated samples are detected by n-gram overlap. Using multi-qa BERT, embedding similarity search proved completely ineffective on translated samples.

Contamination status of the data set
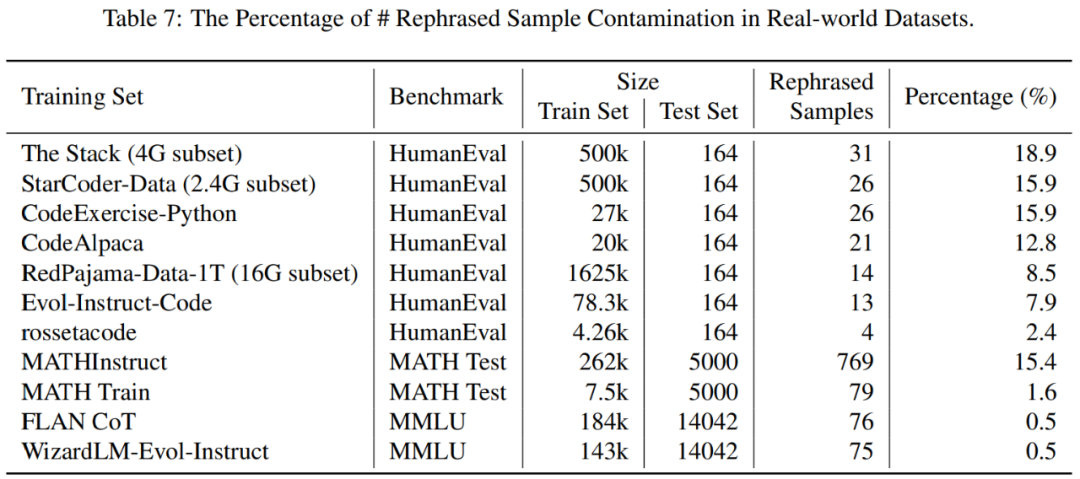
In Table 7, the percentage of data contamination for different benchmarks in each training dataset is shown
LLM decontaminator revealed 79 self-rewriting Yes: Examples of rewritten samples, accounting for 1.58% of the MATH test set. Example 5 is an adaptation of the MATH test on the MATH training data.

Please see the original paper for more information
The above is the detailed content of Does the 13B model have the advantage in a full showdown with GPT-4? Are there some unusual circumstances behind it?. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!
Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1392
1392
 52
52

 Web3 trading platform ranking_Web3 global exchanges top ten summary
Apr 21, 2025 am 10:45 AM
Web3 trading platform ranking_Web3 global exchanges top ten summary
Apr 21, 2025 am 10:45 AM
Binance is the overlord of the global digital asset trading ecosystem, and its characteristics include: 1. The average daily trading volume exceeds $150 billion, supports 500 trading pairs, covering 98% of mainstream currencies; 2. The innovation matrix covers the derivatives market, Web3 layout and education system; 3. The technical advantages are millisecond matching engines, with peak processing volumes of 1.4 million transactions per second; 4. Compliance progress holds 15-country licenses and establishes compliant entities in Europe and the United States.
 Top 10 cryptocurrency exchange platforms The world's largest digital currency exchange list
Apr 21, 2025 pm 07:15 PM
Top 10 cryptocurrency exchange platforms The world's largest digital currency exchange list
Apr 21, 2025 pm 07:15 PM
Exchanges play a vital role in today's cryptocurrency market. They are not only platforms for investors to trade, but also important sources of market liquidity and price discovery. The world's largest virtual currency exchanges rank among the top ten, and these exchanges are not only far ahead in trading volume, but also have their own advantages in user experience, security and innovative services. Exchanges that top the list usually have a large user base and extensive market influence, and their trading volume and asset types are often difficult to reach by other exchanges.
 'Black Monday Sell' is a tough day for the cryptocurrency industry
Apr 21, 2025 pm 02:48 PM
'Black Monday Sell' is a tough day for the cryptocurrency industry
Apr 21, 2025 pm 02:48 PM
The plunge in the cryptocurrency market has caused panic among investors, and Dogecoin (Doge) has become one of the hardest hit areas. Its price fell sharply, and the total value lock-in of decentralized finance (DeFi) (TVL) also saw a significant decline. The selling wave of "Black Monday" swept the cryptocurrency market, and Dogecoin was the first to be hit. Its DeFiTVL fell to 2023 levels, and the currency price fell 23.78% in the past month. Dogecoin's DeFiTVL fell to a low of $2.72 million, mainly due to a 26.37% decline in the SOSO value index. Other major DeFi platforms, such as the boring Dao and Thorchain, TVL also dropped by 24.04% and 20, respectively.
 What does cross-chain transaction mean? What are the cross-chain transactions?
Apr 21, 2025 pm 11:39 PM
What does cross-chain transaction mean? What are the cross-chain transactions?
Apr 21, 2025 pm 11:39 PM
Exchanges that support cross-chain transactions: 1. Binance, 2. Uniswap, 3. SushiSwap, 4. Curve Finance, 5. Thorchain, 6. 1inch Exchange, 7. DLN Trade, these platforms support multi-chain asset transactions through various technologies.
 How to avoid losses after ETH upgrade
Apr 21, 2025 am 10:03 AM
How to avoid losses after ETH upgrade
Apr 21, 2025 am 10:03 AM
After ETH upgrade, novices should adopt the following strategies to avoid losses: 1. Do their homework and understand the basic knowledge and upgrade content of ETH; 2. Control positions, test the waters in small amounts and diversify investment; 3. Make a trading plan, clarify goals and set stop loss points; 4. Profil rationally and avoid emotional decision-making; 5. Choose a formal and reliable trading platform; 6. Consider long-term holding to avoid the impact of short-term fluctuations.
 Rexas Finance (RXS) can surpass Solana (Sol), Cardano (ADA), XRP and Dogecoin (Doge) in 2025
Apr 21, 2025 pm 02:30 PM
Rexas Finance (RXS) can surpass Solana (Sol), Cardano (ADA), XRP and Dogecoin (Doge) in 2025
Apr 21, 2025 pm 02:30 PM
In the volatile cryptocurrency market, investors are looking for alternatives that go beyond popular currencies. Although well-known cryptocurrencies such as Solana (SOL), Cardano (ADA), XRP and Dogecoin (DOGE) also face challenges such as market sentiment, regulatory uncertainty and scalability. However, a new emerging project, RexasFinance (RXS), is emerging. It does not rely on celebrity effects or hype, but focuses on combining real-world assets (RWA) with blockchain technology to provide investors with an innovative way to invest. This strategy makes it hoped to be one of the most successful projects of 2025. RexasFi
 WorldCoin (WLD) price forecast 2025-2031: Will WLD reach USD 4 by 2031?
Apr 21, 2025 pm 02:42 PM
WorldCoin (WLD) price forecast 2025-2031: Will WLD reach USD 4 by 2031?
Apr 21, 2025 pm 02:42 PM
WorldCoin (WLD) stands out in the cryptocurrency market with its unique biometric verification and privacy protection mechanisms, attracting the attention of many investors. WLD has performed outstandingly among altcoins with its innovative technologies, especially in combination with OpenAI artificial intelligence technology. But how will the digital assets behave in the next few years? Let's predict the future price of WLD together. The 2025 WLD price forecast is expected to achieve significant growth in WLD in 2025. Market analysis shows that the average WLD price may reach $1.31, with a maximum of $1.36. However, in a bear market, the price may fall to around $0.55. This growth expectation is mainly due to WorldCoin2.
 Ranking of leveraged exchanges in the currency circle The latest recommendations of the top ten leveraged exchanges in the currency circle
Apr 21, 2025 pm 11:24 PM
Ranking of leveraged exchanges in the currency circle The latest recommendations of the top ten leveraged exchanges in the currency circle
Apr 21, 2025 pm 11:24 PM
The platforms that have outstanding performance in leveraged trading, security and user experience in 2025 are: 1. OKX, suitable for high-frequency traders, providing up to 100 times leverage; 2. Binance, suitable for multi-currency traders around the world, providing 125 times high leverage; 3. Gate.io, suitable for professional derivatives players, providing 100 times leverage; 4. Bitget, suitable for novices and social traders, providing up to 100 times leverage; 5. Kraken, suitable for steady investors, providing 5 times leverage; 6. Bybit, suitable for altcoin explorers, providing 20 times leverage; 7. KuCoin, suitable for low-cost traders, providing 10 times leverage; 8. Bitfinex, suitable for senior play
