
 Technology peripherals
AI
The PyTorch team re-implemented the 'split everything” model eight times faster than the original implementation
Technology peripherals
AI
The PyTorch team re-implemented the 'split everything” model eight times faster than the original implementation
The PyTorch team re-implemented the 'split everything” model eight times faster than the original implementation

From the beginning of the year to now, generative AI has developed rapidly. But many times, we have to face a difficult problem: how to speed up the training, reasoning, etc. of generative AI, especially when using PyTorch.
In this article, researchers from the PyTorch team provide us with a solution. The article focuses on how to use pure native PyTorch to accelerate generative AI models. It also introduces new PyTorch features and practical examples of how to combine them.
What is the result? The PyTorch team said they rewrote Meta's "Split Everything" (SAM) model, resulting in code that is 8 times faster than the original implementation without losing accuracy, all optimized using native PyTorch.

Blog address: https://pytorch.org/blog/accelerating-generative-ai/
After reading this article, you will gain the following understanding:
- Torch.compile: PyTorch model compiler, PyTorch 2.0 has added a new function called torch .compile () can accelerate existing models with one line of code;
- GPU quantization: accelerate the model by reducing the calculation accuracy;
- SDPA (Scaled Dot Product Attention): A memory-efficient attention implementation;
- Semi-structured (2:4) Sparseness: A sparse memory format optimized for GPUs ;
- Nested Tensor: Nested Tensor packs {tensor, mask} together to batch non-uniformly sized data into a single tensor, such as images of different sizes;
- Triton Custom Operations: Use the Triton Python DSL to write GPU operations and easily integrate them into various components of PyTorch through custom operator registration.
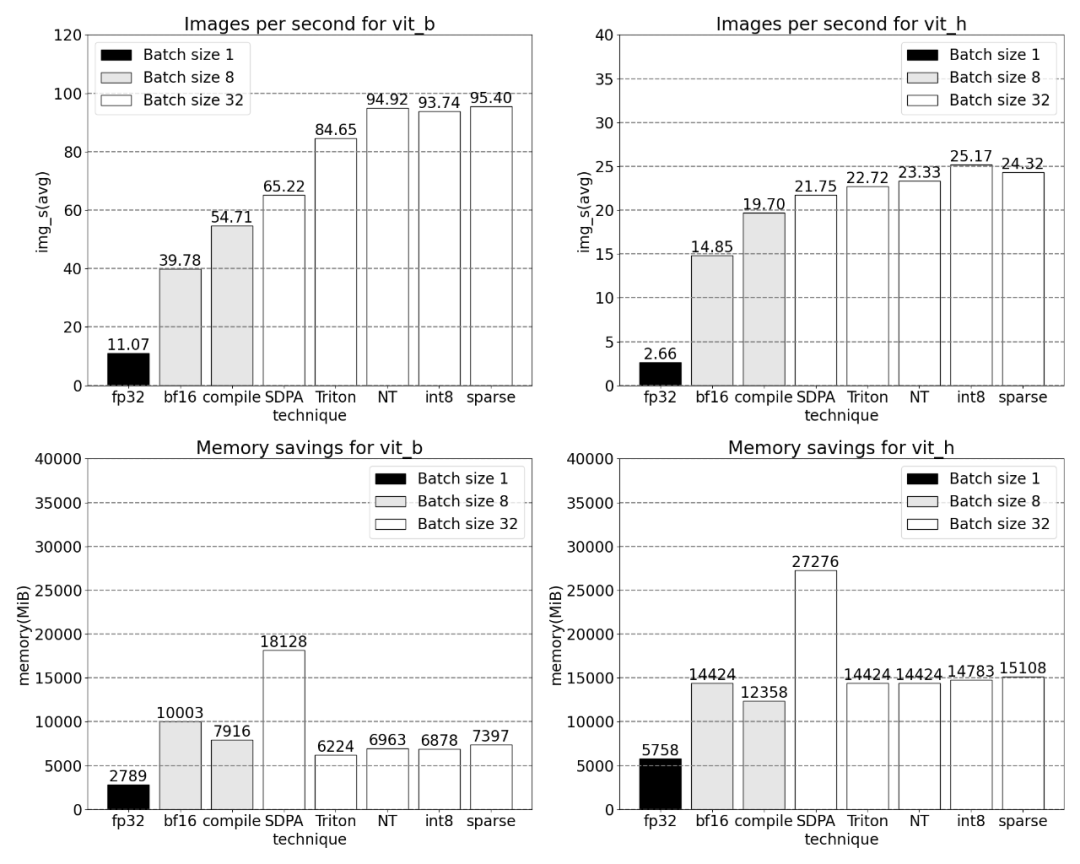
Increased throughput and reduced memory overhead brought about by PyTorch’s native features.
For more information about this research, please refer to the SAM proposed by Meta. Detailed articles can be found in "CV no longer exists? Meta releases "Split Everything" AI model, CV may usher in GPT-3 moment"

Next, we will introduce the SAM optimization process, including performance analysis, bottleneck identification, and how to integrate these new features into PyTorch to solve the problems faced by SAM. In addition, we will also introduce some new features of PyTorch, including torch.compile, SDPA, Triton kernels, Nested Tensor and semi-structured sparsity (semi-structured sparsity)
content step by step Going deeper, this article will introduce the fast version of SAM at the end. For interested readers, you can download it from GitHub. In addition, these data were visualized using Perfetto UI to demonstrate the application value of various features of PyTorch
GitHub address: https://github.com/pytorch-labs/segment The source code for this project can be found at -anything-fast
A rewrite of the Segmented Everything model SAM
The study points out that the The SAM baseline data type is float32 dtype, the batch size is 1, and the results of using PyTorch Profiler to view the core tracing are as follows:
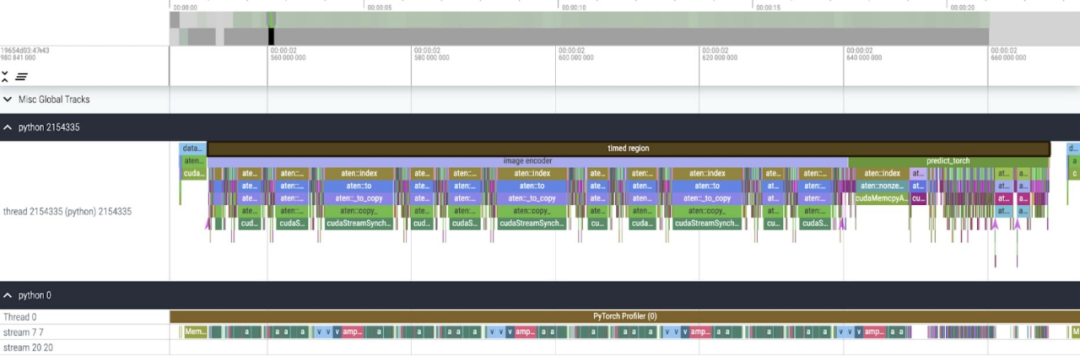
This article found that SAM has two places that can be optimized:
The first is the long call to aten::index, which is performed by the tensor index operation (such as []) Caused by the underlying calls generated. However, the actual time the GPU spends on aten::index is relatively low. The reason is that during the process of starting two cores, aten::index blocks cudaStreamSynchronize between the two. This means that the CPU waits for the GPU to finish processing until the second core is launched. Therefore, in order to optimize SAM, this paper believes that one should strive to eliminate blocking GPU synchronization that causes idle time.
The second problem is that SAM spends a lot of GPU time in matrix multiplication (dark green part as shown in the picture), which is very common in Transformers model. If we can reduce the GPU time of the SAM model on matrix multiplication, then we can significantly improve the speed of SAM
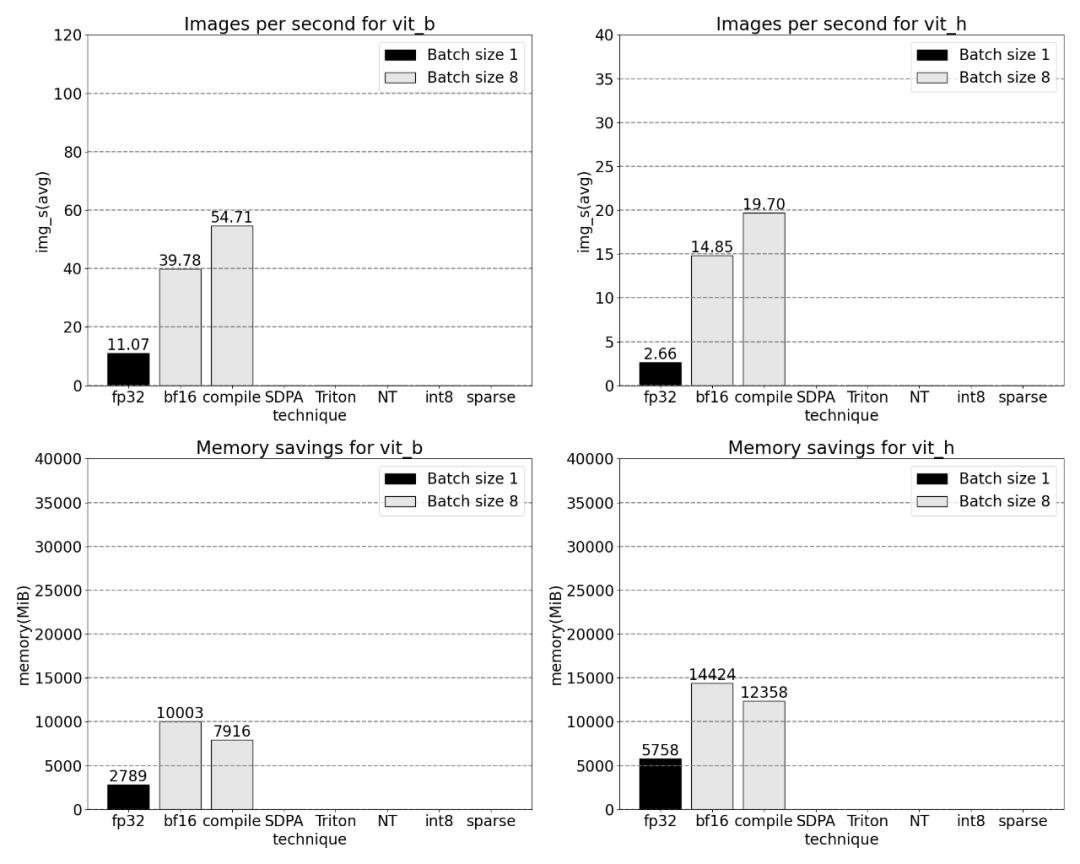
Next, we will take the throughput of SAM (img/s ) and memory overhead (GiB) to establish a baseline. Then there is the optimization process
The sentence that needs to be rewritten is: Bfloat16 half precision (plus GPU synchronization and Batch processing)
#In order to solve the above problem, that is, to reduce the time required for matrix multiplication, this article turns to bfloat16. bfloat16 is a commonly used half-precision type. By reducing the precision of each parameter and activation, it can save a lot of computing time and memory

##Replace fill type with bfloat16
In addition, this article found that there are two places that can be optimized to remove GPU synchronization


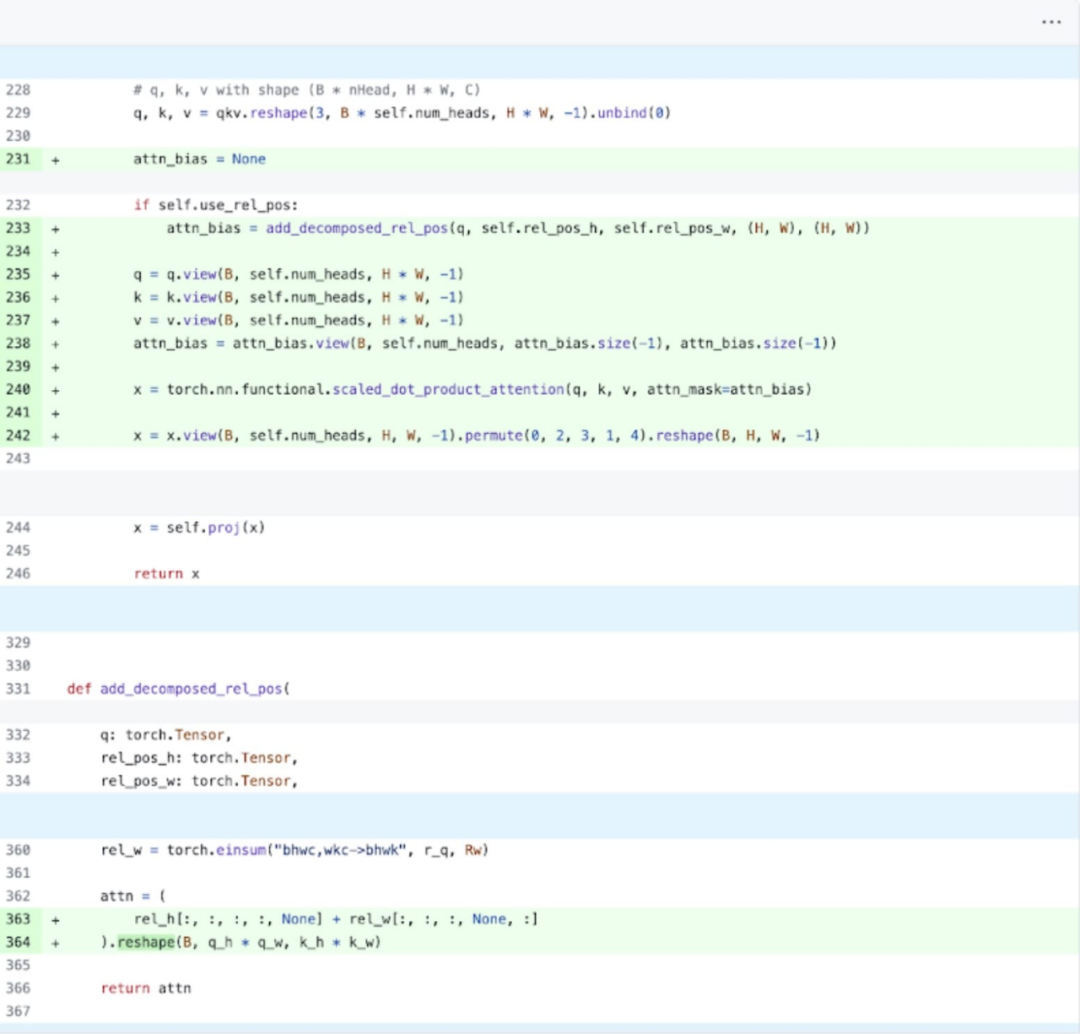
Specifically, it is easier to understand based on the picture above, the study found In the SAM image encoder, there are two variables q_coords and k_coords that act as coordinate scalers, and these variables are allocated and processed on the CPU. However, once these variables are used to index in rel_pos_resized, the indexing operation automatically moves these variables to the GPU, causing GPU synchronization issues. In order to solve this problem, the research pointed out that this part can be rewritten using the torch.where function to solve the problem, as shown above
Core Tracking
After applying these changes, we noticed that there was a noticeable time gap between individual kernel calls, especially with small batch sizes (here 1). To gain a deeper understanding of this phenomenon, we begin performance analysis of SAM inference with a batch size of 8
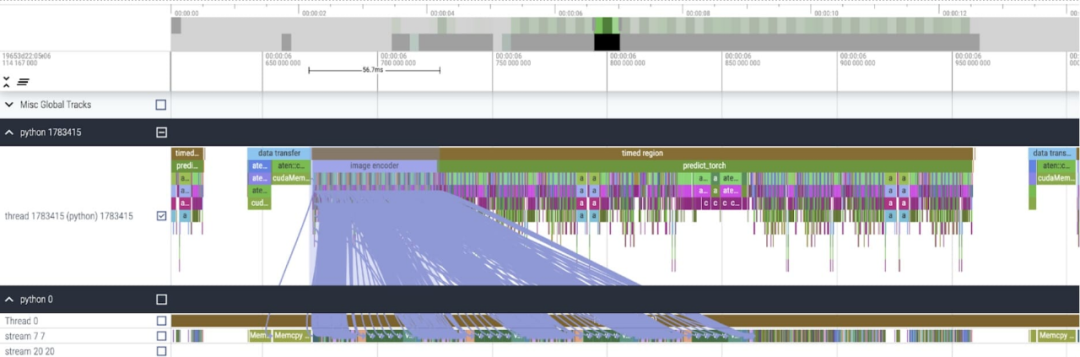
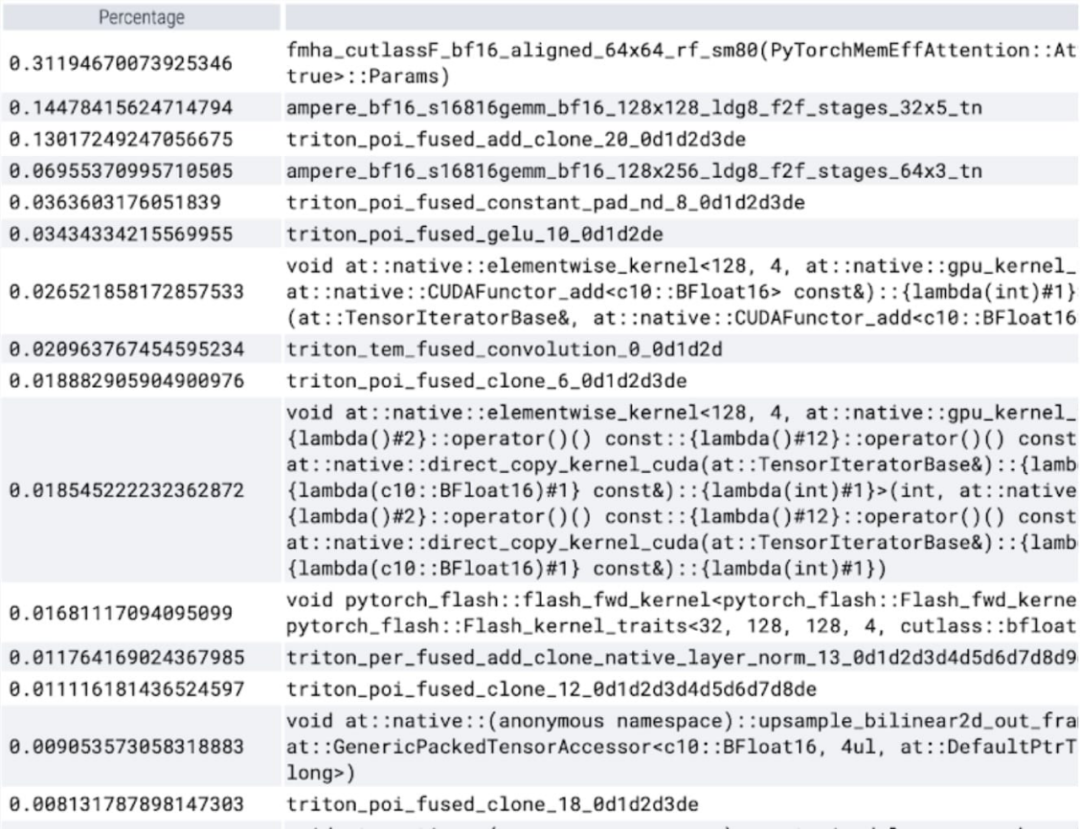
at When analyzing the time spent per kernel, we notice that most of the GPU time for SAM is spent on element-wise kernels and softmax operations
#We can now see the relative small overhead of matrix multiplication A lot.
Combining GPU synchronization and bfloat16 optimization, SAM performance is improved by 3x.
Torch.compile(graph breaks and CUDA graphs)
Discovered during the study of SAM Many small operations were performed. Researchers believe that using a compiler to integrate these operations is very beneficial, so PyTorch made the following optimizations to torch.compile
- Integrate sequences of operations such as nn.LayerNorm or nn.GELU into a single GPU kernel;
- Fuse operations immediately following the matrix multiplication kernel to reduce the number of GPU kernel calls.
Through these optimizations, the research reduced the number of GPU global memory roundtrips, thereby speeding up inference. We can now try torch.compile on SAM’s image encoder. To maximize performance, this article uses some advanced compilation techniques:

Core Tracking
## According to the results, torch.compile performs very well
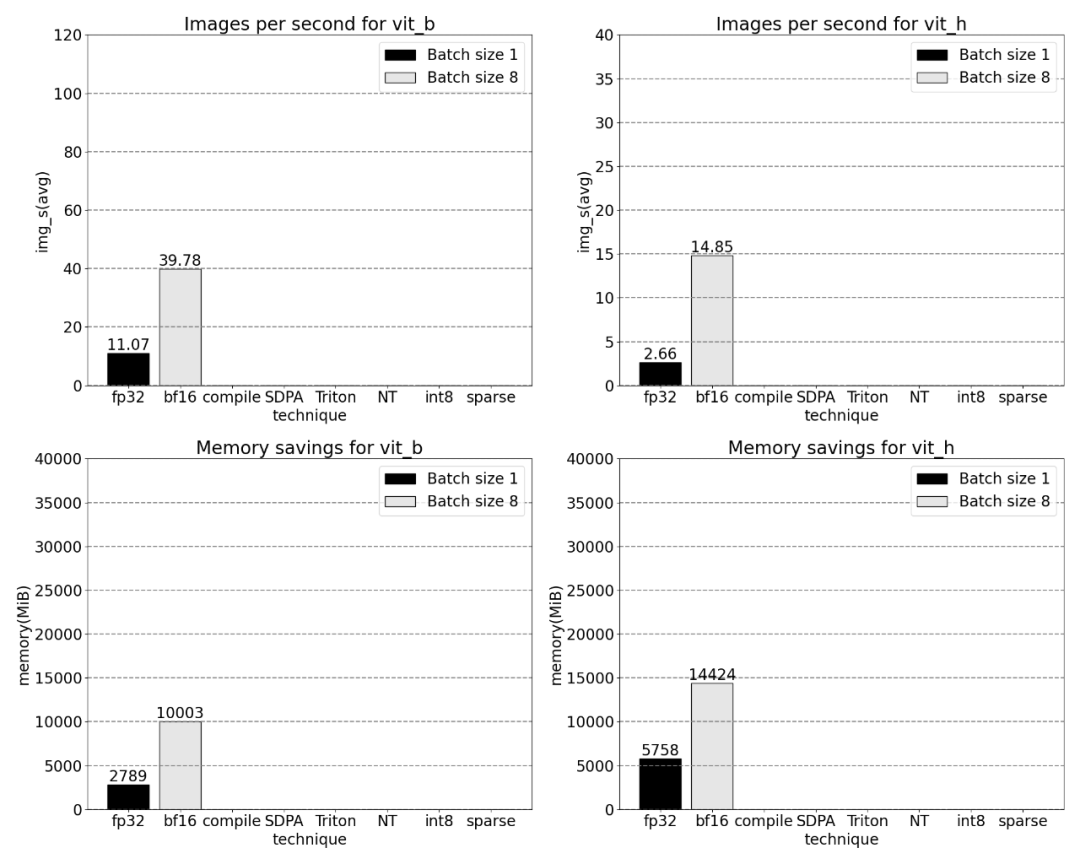
It can be observed that softmax takes up a large part of the time, followed by various GEMM variants . The following measurements are for batch sizes of 8 and above.
Next, this article discusses SDPA ( scaled_dot_product_attention) conducted experiments, focusing on the attention mechanism. In general, native attention mechanisms scale quadratically with sequence length in time and memory. PyTorch's SDPA operations are built on the memory-efficient attention principles of Flash Attention, FlashAttentionV2, and xFormer, which can significantly speed up GPU attention. Combined with torch.compile, this operation allows the expression and fusion of a common pattern in variants of MultiheadAttention. After a small change, the model can now use scaled_dot_product_attention.
Core Tracking
Now available to watch The memory-efficient attention kernel takes up a lot of computation time on the GPU:
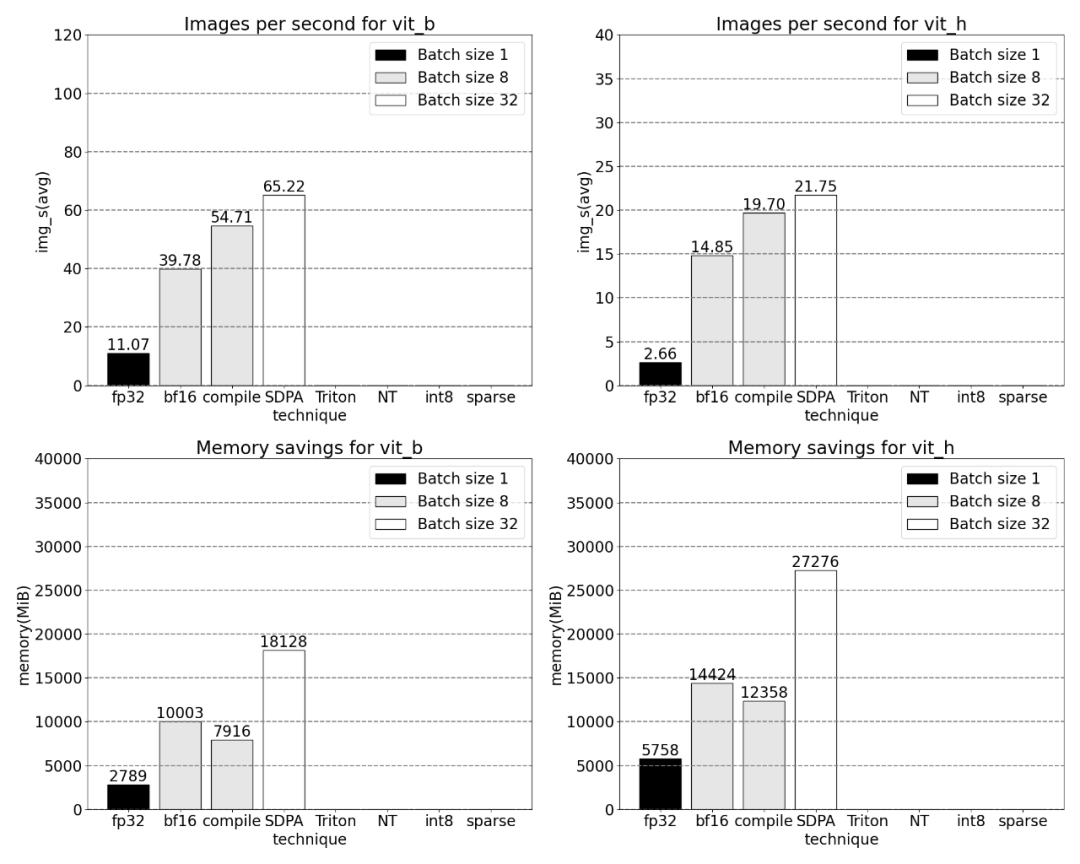
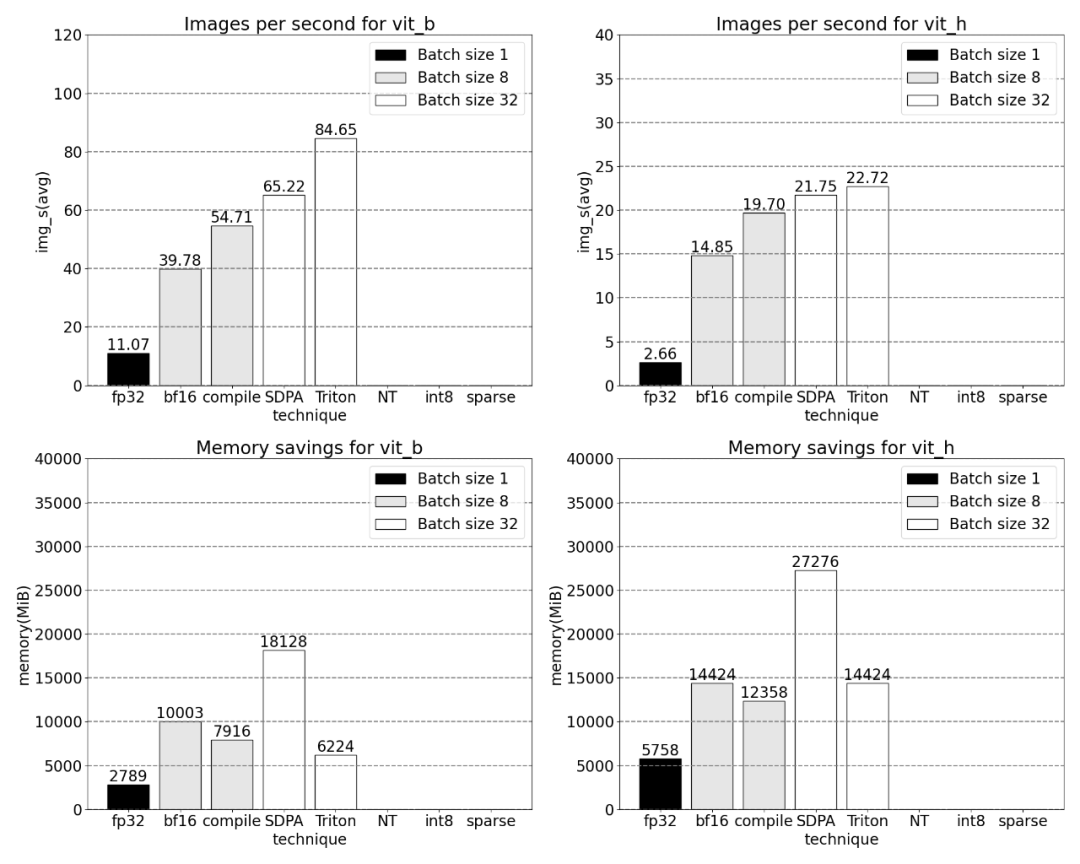
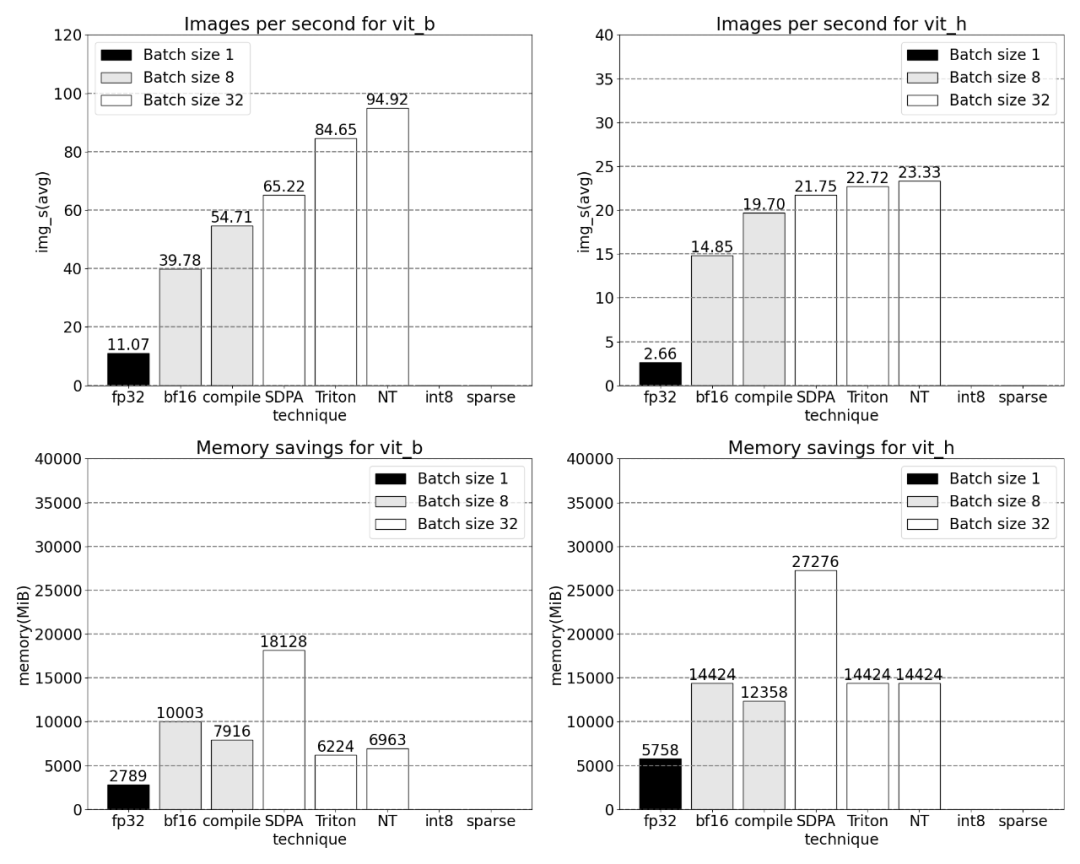
##Using PyTorch’s native scaled_dot_product_attention, batch sizes can be significantly increased. The graph below shows the changes for batch sizes of 32 and above.
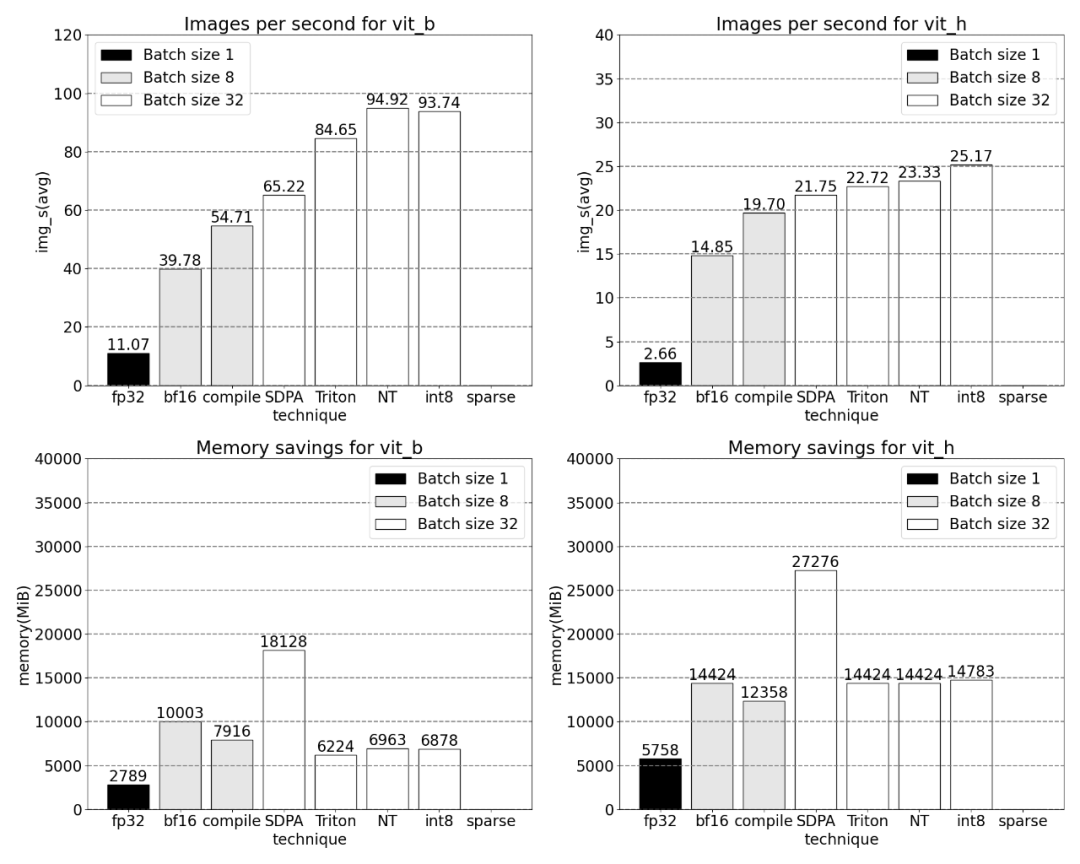
###############Next, the study was conducted on Triton, NestedTensor, batch Predict_torch, int8 quantization, semi-structured (2:4) sparsity Experiments on other operations############For example, this article uses a custom positional Triton kernel and observes measurement results with a batch size of 32. #####################Adopt Nested Tensor technology and adjust the batch size to 32 and above################ #####After adding quantization, the measurement results vary with batch size of 32 and above. ######################The end of the article is semi-structured sparsity. The study shows that matrix multiplication is still a bottleneck that needs to be faced. The solution is to use sparsification to approximate matrix multiplication. By sparse matrices (i.e. zeroing out the values) fewer bits can be used to store weights and activation tensors. The process of setting which weights in a tensor is set to zero is called pruning. Pruning out smaller weights can potentially reduce model size without significant loss of accuracy. ######There are many ways to prune, ranging from completely unstructured to highly structured. While unstructured pruning theoretically has minimal impact on accuracy, in the sparse case the GPU may experience significant performance degradation, despite being very efficient when doing large dense matrix multiplications. One pruning method recently supported by PyTorch is semi-structured (or 2:4) sparsity, which aims to find a balance. This sparse storage method reduces the original tensor by 50% while producing a dense tensor output. Please refer to the figure below for explanation
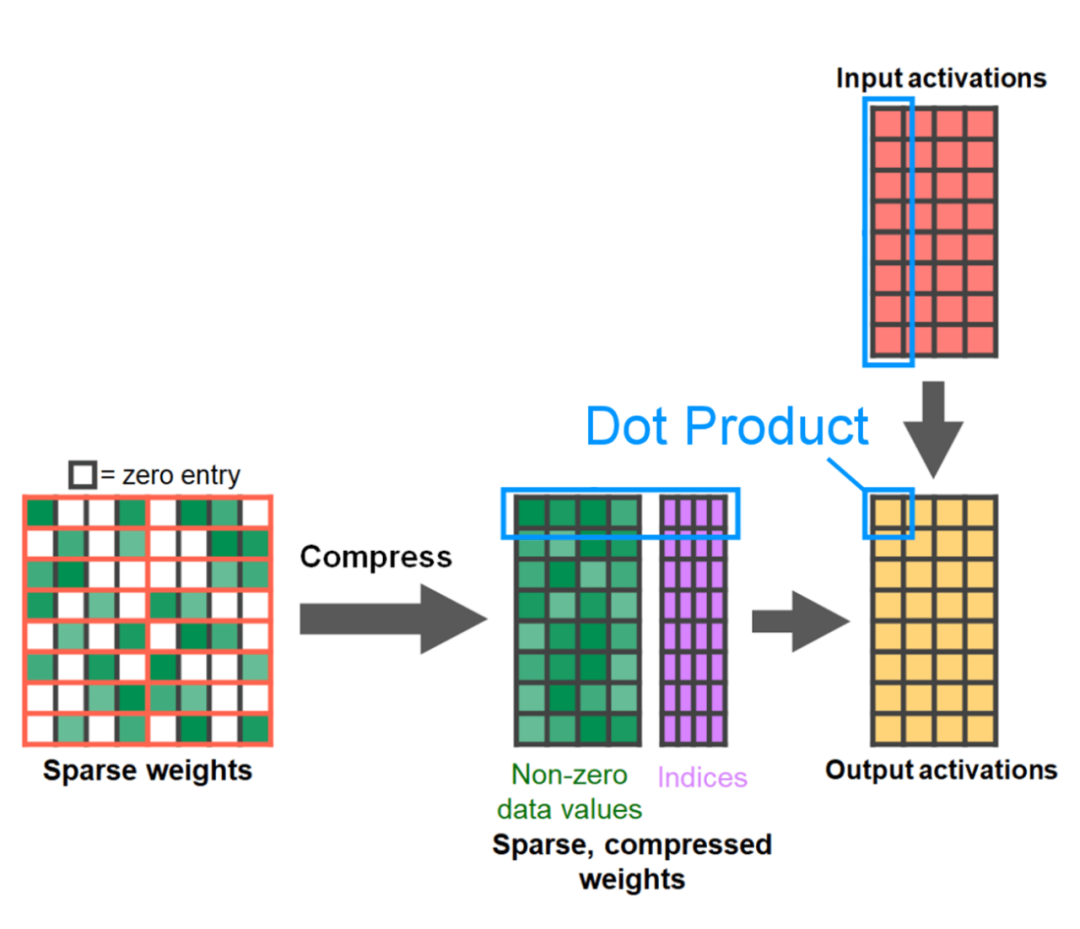
In order to use this sparse storage format and the associated fast kernel, the next thing to do is to prune the weights. This article selects the smallest two weights for pruning at a sparsity of 2:4. Changing the weights from the default PyTorch ("strided") layout to this new semi-structured sparse layout is easy. To implement apply_sparse (model), only 32 lines of Python code are needed:
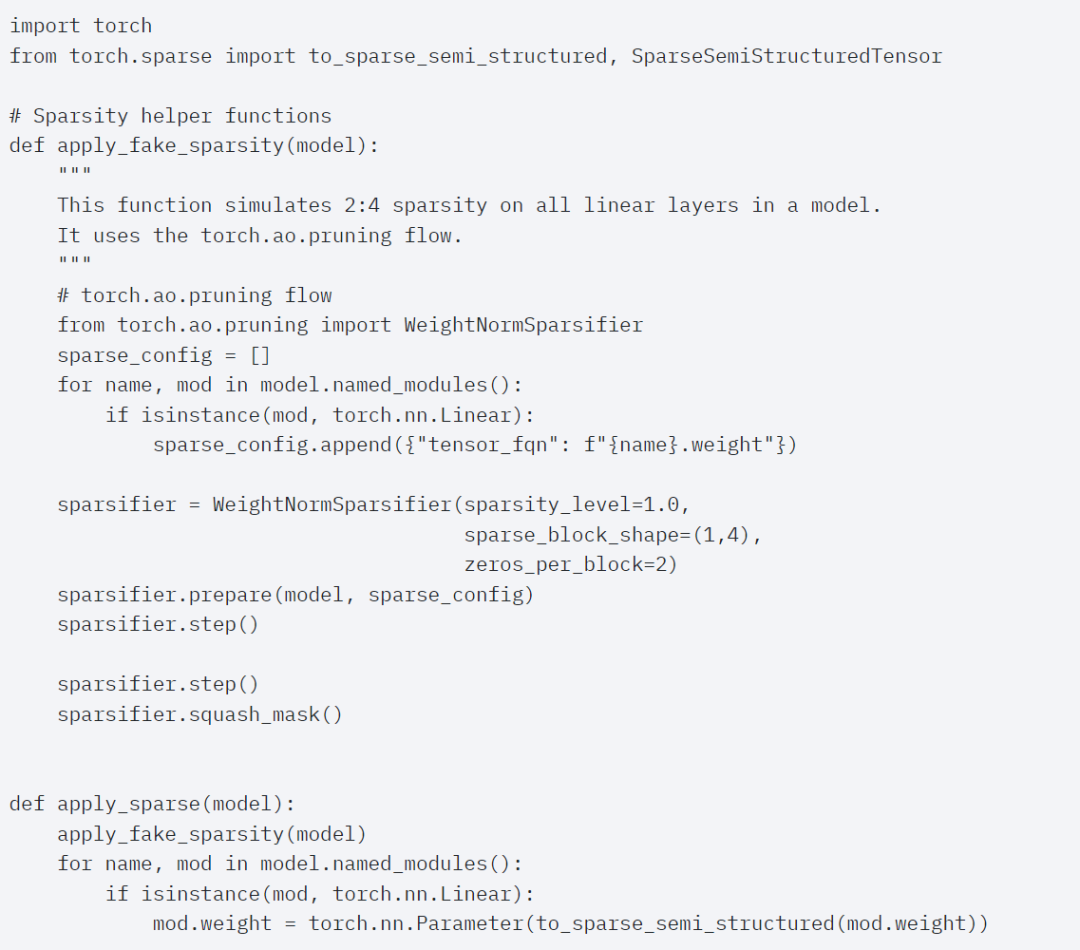
When the sparsity is 2:4, we observe that vit_b and SAM peak performance with batch size 32
Finally, the summary of this article is as follows: This article describes the implementation on PyTorch so far The fastest way to Segment Anything, with the help of a series of officially released new features, this article rewrites the original SAM in pure PyTorch without losing accuracy
For interested readers , you can check the original blog for more information
The above is the detailed content of The PyTorch team re-implemented the 'split everything” model eight times faster than the original implementation. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Imagine an artificial intelligence model that not only has the ability to surpass traditional computing, but also achieves more efficient performance at a lower cost. This is not science fiction, DeepSeek-V2[1], the world’s most powerful open source MoE model is here. DeepSeek-V2 is a powerful mixture of experts (MoE) language model with the characteristics of economical training and efficient inference. It consists of 236B parameters, 21B of which are used to activate each marker. Compared with DeepSeek67B, DeepSeek-V2 has stronger performance, while saving 42.5% of training costs, reducing KV cache by 93.3%, and increasing the maximum generation throughput to 5.76 times. DeepSeek is a company exploring general artificial intelligence
 Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas officially enters the era of electric robots! Yesterday, the hydraulic Atlas just "tearfully" withdrew from the stage of history. Today, Boston Dynamics announced that the electric Atlas is on the job. It seems that in the field of commercial humanoid robots, Boston Dynamics is determined to compete with Tesla. After the new video was released, it had already been viewed by more than one million people in just ten hours. The old people leave and new roles appear. This is a historical necessity. There is no doubt that this year is the explosive year of humanoid robots. Netizens commented: The advancement of robots has made this year's opening ceremony look like a human, and the degree of freedom is far greater than that of humans. But is this really not a horror movie? At the beginning of the video, Atlas is lying calmly on the ground, seemingly on his back. What follows is jaw-dropping
 KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
Earlier this month, researchers from MIT and other institutions proposed a very promising alternative to MLP - KAN. KAN outperforms MLP in terms of accuracy and interpretability. And it can outperform MLP running with a larger number of parameters with a very small number of parameters. For example, the authors stated that they used KAN to reproduce DeepMind's results with a smaller network and a higher degree of automation. Specifically, DeepMind's MLP has about 300,000 parameters, while KAN only has about 200 parameters. KAN has a strong mathematical foundation like MLP. MLP is based on the universal approximation theorem, while KAN is based on the Kolmogorov-Arnold representation theorem. As shown in the figure below, KAN has
 Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
The latest video of Tesla's robot Optimus is released, and it can already work in the factory. At normal speed, it sorts batteries (Tesla's 4680 batteries) like this: The official also released what it looks like at 20x speed - on a small "workstation", picking and picking and picking: This time it is released One of the highlights of the video is that Optimus completes this work in the factory, completely autonomously, without human intervention throughout the process. And from the perspective of Optimus, it can also pick up and place the crooked battery, focusing on automatic error correction: Regarding Optimus's hand, NVIDIA scientist Jim Fan gave a high evaluation: Optimus's hand is the world's five-fingered robot. One of the most dexterous. Its hands are not only tactile
 FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: the first target detection algorithm based on fisheye camera
Apr 26, 2024 am 11:37 AM
Target detection is a relatively mature problem in autonomous driving systems, among which pedestrian detection is one of the earliest algorithms to be deployed. Very comprehensive research has been carried out in most papers. However, distance perception using fisheye cameras for surround view is relatively less studied. Due to large radial distortion, standard bounding box representation is difficult to implement in fisheye cameras. To alleviate the above description, we explore extended bounding box, ellipse, and general polygon designs into polar/angular representations and define an instance segmentation mIOU metric to analyze these representations. The proposed model fisheyeDetNet with polygonal shape outperforms other models and simultaneously achieves 49.5% mAP on the Valeo fisheye camera dataset for autonomous driving
 New affordable Meta Quest 3S VR headset appears on FCC, suggesting imminent launch
Sep 04, 2024 am 06:51 AM
New affordable Meta Quest 3S VR headset appears on FCC, suggesting imminent launch
Sep 04, 2024 am 06:51 AM
The Meta Connect 2024event is set for September 25 to 26, and in this event, the company is expected to unveil a new affordable virtual reality headset. Rumored to be the Meta Quest 3S, the VR headset has seemingly appeared on FCC listing. This sugge
 The latest from Oxford University! Mickey: 2D image matching in 3D SOTA! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
The latest from Oxford University! Mickey: 2D image matching in 3D SOTA! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Project link written in front: https://nianticlabs.github.io/mickey/ Given two pictures, the camera pose between them can be estimated by establishing the correspondence between the pictures. Typically, these correspondences are 2D to 2D, and our estimated poses are scale-indeterminate. Some applications, such as instant augmented reality anytime, anywhere, require pose estimation of scale metrics, so they rely on external depth estimators to recover scale. This paper proposes MicKey, a keypoint matching process capable of predicting metric correspondences in 3D camera space. By learning 3D coordinate matching across images, we are able to infer metric relative
 Single card running Llama 70B is faster than dual card, Microsoft forced FP6 into A100 | Open source
Apr 29, 2024 pm 04:55 PM
Single card running Llama 70B is faster than dual card, Microsoft forced FP6 into A100 | Open source
Apr 29, 2024 pm 04:55 PM
FP8 and lower floating point quantification precision are no longer the "patent" of H100! Lao Huang wanted everyone to use INT8/INT4, and the Microsoft DeepSpeed team started running FP6 on A100 without official support from NVIDIA. Test results show that the new method TC-FPx's FP6 quantization on A100 is close to or occasionally faster than INT4, and has higher accuracy than the latter. On top of this, there is also end-to-end large model support, which has been open sourced and integrated into deep learning inference frameworks such as DeepSpeed. This result also has an immediate effect on accelerating large models - under this framework, using a single card to run Llama, the throughput is 2.65 times higher than that of dual cards. one
