
 Technology peripherals
AI
Stable Video Diffusion is here! 3D synthesis function attracts attention, netizens: progress is too fast
Technology peripherals
AI
Stable Video Diffusion is here! 3D synthesis function attracts attention, netizens: progress is too fast
Stable Video Diffusion is here! 3D synthesis function attracts attention, netizens: progress is too fast

Stable Video Diffusion officially started to process videos -
Released the generative video modelStable Video Diffusion (SVD).
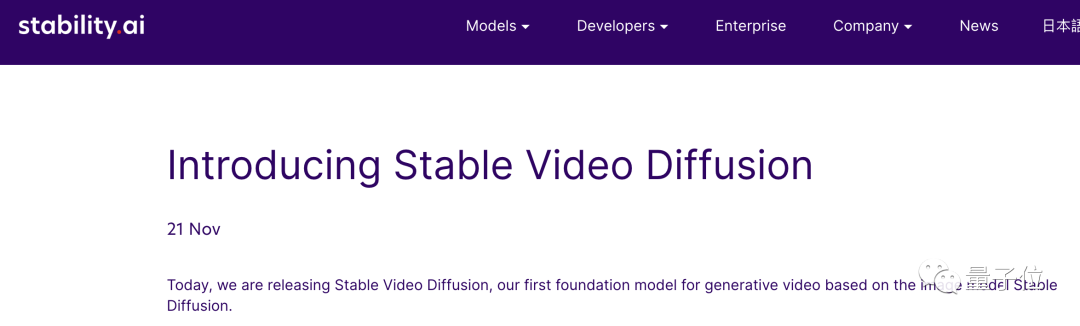
Stability AI official blog shows that the new SVD supports text-to-video and image-to-video generation:

and also Supports the transformation of objects from a single perspective to multiple perspectives, that is, 3D synthesis:

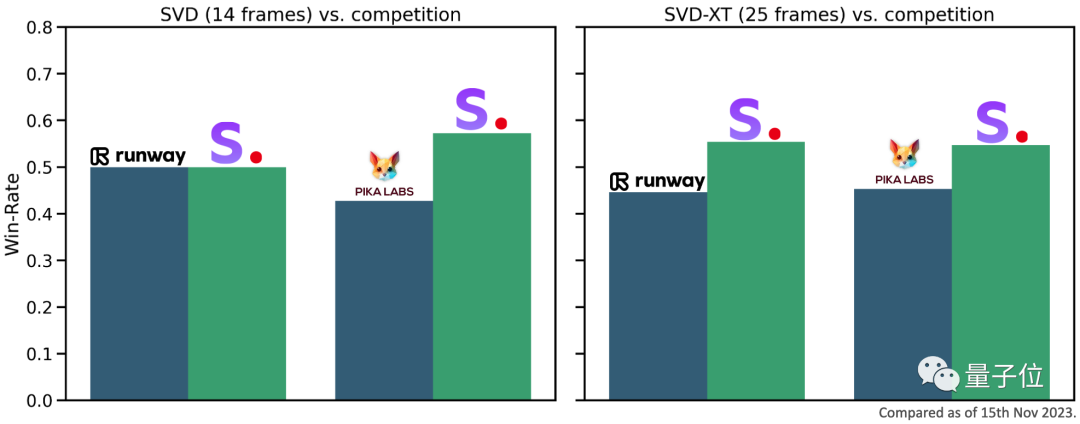
According to external evaluation, the official claims that SVD is even better than runway and Pika. Video generation AI is more popular among users.
Although only the basic model has been released so far, the official revealed that "it is planning to continue to expand and establish an ecosystem similar to stable diffusion"
The paper code weight is now online.

Recently, new methods of play have been emerging in the field of video generation. Now it is the turn of Stable Diffusion to appear, so that netizens have lamented "fast", such progress is too fast. !

But judging from the demo effect alone, more netizens said they were not very surprised.
Although I like SD, and these demos are great...but there are also some flaws, the lighting and shadow are wrong, and the overall incoherence(video flickers between frames).

All in all, this is the beginning. Netizens are very optimistic about SVD’s 3D synthesis function:
I can guarantee that there will be more soon. When good things come out, you only need a brief description to present a complete 3D scene

SD video official version is coming
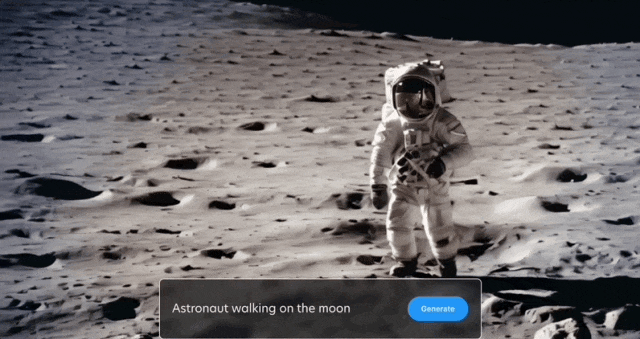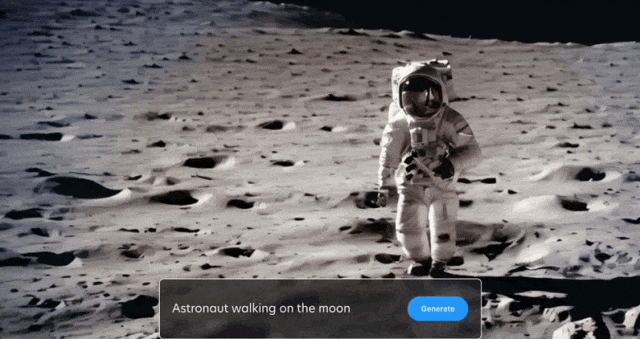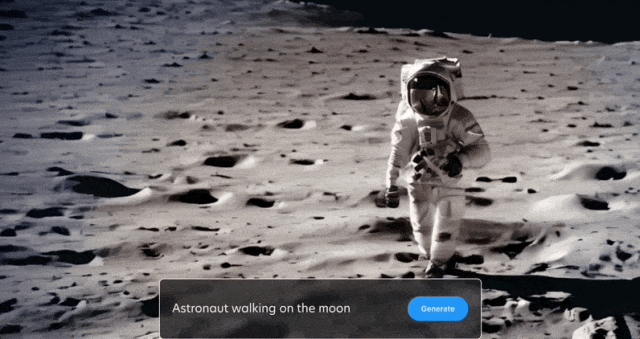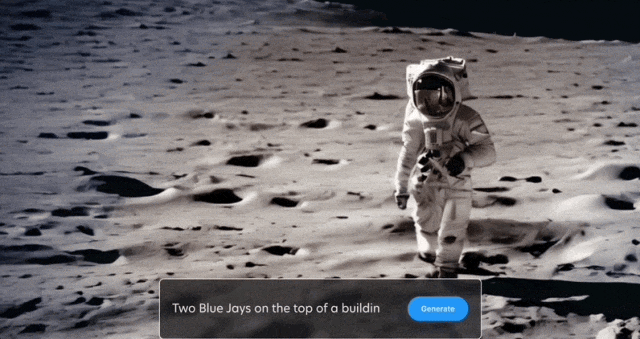
In addition to what is shown above Yes, the official has also released more demonstrations, let’s take a look first:

Space walks are also arranged:
You can also keep the background still and only let the two birds move:

The research paper on SVD has also been released. According to reports, SVD is based on Stable Diffusion 2.1 and uses about The base model is pre-trained on a video data set of 600 million samples.
Easily adaptable to a variety of downstream tasks, including multi-view synthesis from a single image by fine-tuning multi-view datasets.
After fine-tuning, two image-to-video models were officially announced. These models can generate 14-frame (SVD) and 25-frame (SVD-XT) video at custom frame rates from 3 to 30 frames per second depending on the user's needs
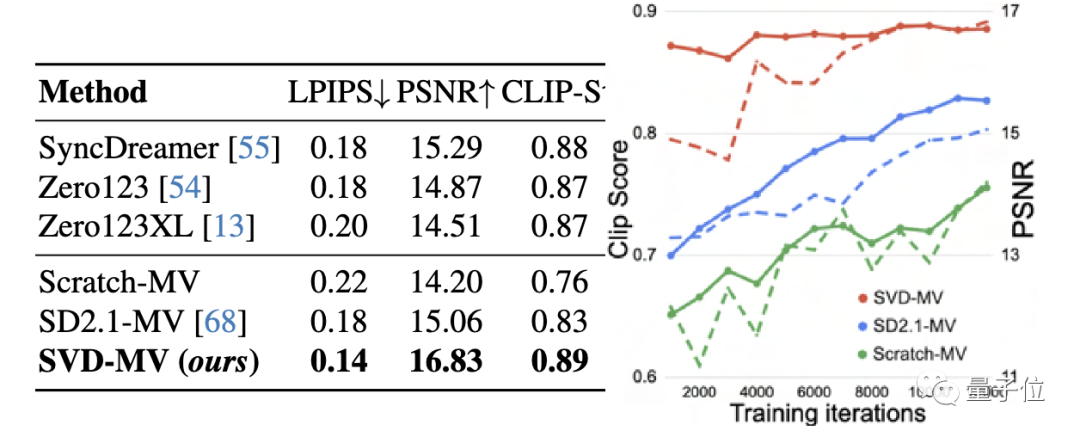
#After fine-tuning the multi-view video generation model, we named it SVD-MV

According to the test results, on the GSO dataset, SVD-MV scored excellent For multi-view generation models Zero123, Zero123XL, SyncDreamer:
It is worth mentioning that Stability AI stated that SVD is currently limited to research and is not suitable for practical or commercial applications. SVD is not currently available to everyone, but user waiting list registration is open.
The explosion of video generation
Recently, there has been a state of "melee" in the field of video generation
There was previously Vincent Video AI developed by PikaLabs:

Later, the so-called "most powerful video generation AI in historyMoonvalley was launched:

Recently, Gen-2's "Motion Brush" function has also been officially launched. You can draw where you want:

Now SVD has appeared again , and there is the possibility of 3D video generation.
However, there seems to be not much progress in text to 3D generation, and netizens are also very confused about this phenomenon.

Some people think that data is the bottleneck that hinders development:

Some netizens think that the problem is that the ability of reinforcement learning is not strong enough

Do you know the latest progress in this area? Welcome to share in the comment area~
Paper link: https://static1.squarespace.com/static/6213c340453c3f502425776e /t/655ce779b9d47d342a93c890/1700587395994/stable_video_diffusion.pdf What needs to be rewritten is:
The above is the detailed content of Stable Video Diffusion is here! 3D synthesis function attracts attention, netizens: progress is too fast. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1377
1377
 52
52

 How to create oracle database How to create oracle database
Apr 11, 2025 pm 02:36 PM
How to create oracle database How to create oracle database
Apr 11, 2025 pm 02:36 PM
To create an Oracle database, the common method is to use the dbca graphical tool. The steps are as follows: 1. Use the dbca tool to set the dbName to specify the database name; 2. Set sysPassword and systemPassword to strong passwords; 3. Set characterSet and nationalCharacterSet to AL32UTF8; 4. Set memorySize and tablespaceSize to adjust according to actual needs; 5. Specify the logFile path. Advanced methods are created manually using SQL commands, but are more complex and prone to errors. Pay attention to password strength, character set selection, tablespace size and memory
 How to create an oracle database How to create an oracle database
Apr 11, 2025 pm 02:33 PM
How to create an oracle database How to create an oracle database
Apr 11, 2025 pm 02:33 PM
Creating an Oracle database is not easy, you need to understand the underlying mechanism. 1. You need to understand the concepts of database and Oracle DBMS; 2. Master the core concepts such as SID, CDB (container database), PDB (pluggable database); 3. Use SQL*Plus to create CDB, and then create PDB, you need to specify parameters such as size, number of data files, and paths; 4. Advanced applications need to adjust the character set, memory and other parameters, and perform performance tuning; 5. Pay attention to disk space, permissions and parameter settings, and continuously monitor and optimize database performance. Only by mastering it skillfully requires continuous practice can you truly understand the creation and management of Oracle databases.
 How to write oracle database statements
Apr 11, 2025 pm 02:42 PM
How to write oracle database statements
Apr 11, 2025 pm 02:42 PM
The core of Oracle SQL statements is SELECT, INSERT, UPDATE and DELETE, as well as the flexible application of various clauses. It is crucial to understand the execution mechanism behind the statement, such as index optimization. Advanced usages include subqueries, connection queries, analysis functions, and PL/SQL. Common errors include syntax errors, performance issues, and data consistency issues. Performance optimization best practices involve using appropriate indexes, avoiding SELECT *, optimizing WHERE clauses, and using bound variables. Mastering Oracle SQL requires practice, including code writing, debugging, thinking and understanding the underlying mechanisms.
 How to add, modify and delete MySQL data table field operation guide
Apr 11, 2025 pm 05:42 PM
How to add, modify and delete MySQL data table field operation guide
Apr 11, 2025 pm 05:42 PM
Field operation guide in MySQL: Add, modify, and delete fields. Add field: ALTER TABLE table_name ADD column_name data_type [NOT NULL] [DEFAULT default_value] [PRIMARY KEY] [AUTO_INCREMENT] Modify field: ALTER TABLE table_name MODIFY column_name data_type [NOT NULL] [DEFAULT default_value] [PRIMARY KEY]
 What are the integrity constraints of oracle database tables?
Apr 11, 2025 pm 03:42 PM
What are the integrity constraints of oracle database tables?
Apr 11, 2025 pm 03:42 PM
The integrity constraints of Oracle databases can ensure data accuracy, including: NOT NULL: null values are prohibited; UNIQUE: guarantee uniqueness, allowing a single NULL value; PRIMARY KEY: primary key constraint, strengthen UNIQUE, and prohibit NULL values; FOREIGN KEY: maintain relationships between tables, foreign keys refer to primary table primary keys; CHECK: limit column values according to conditions.
 Detailed explanation of nested query instances in MySQL database
Apr 11, 2025 pm 05:48 PM
Detailed explanation of nested query instances in MySQL database
Apr 11, 2025 pm 05:48 PM
Nested queries are a way to include another query in one query. They are mainly used to retrieve data that meets complex conditions, associate multiple tables, and calculate summary values or statistical information. Examples include finding employees above average wages, finding orders for a specific category, and calculating the total order volume for each product. When writing nested queries, you need to follow: write subqueries, write their results to outer queries (referenced with alias or AS clauses), and optimize query performance (using indexes).
 What does oracle do
Apr 11, 2025 pm 06:06 PM
What does oracle do
Apr 11, 2025 pm 06:06 PM
Oracle is the world's largest database management system (DBMS) software company. Its main products include the following functions: relational database management system (Oracle database) development tools (Oracle APEX, Oracle Visual Builder) middleware (Oracle WebLogic Server, Oracle SOA Suite) cloud service (Oracle Cloud Infrastructure) analysis and business intelligence (Oracle Analytics Cloud, Oracle Essbase) blockchain (Oracle Blockchain Pla
 What are the system development tools for oracle databases?
Apr 11, 2025 pm 03:45 PM
What are the system development tools for oracle databases?
Apr 11, 2025 pm 03:45 PM
Oracle database development tools include not only SQL*Plus, but also the following tools: PL/SQL Developer: Paid tool, provides code editing, debugging, and database management functions, and supports syntax highlighting and automatic completion of PL/SQL code. Toad for Oracle: Paid tool that provides PL/SQL Developer-like features, and additional database performance monitoring and SQL optimization capabilities. SQL Developer: Oracle's official free tool, providing basic functions of code editing, debugging and database management, suitable for developers with limited budgets. DataGrip: JetBrains
