
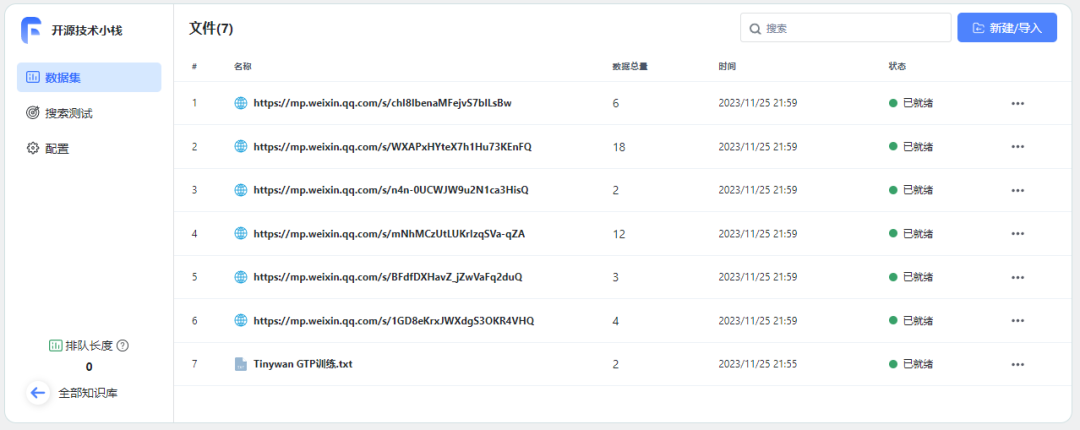
 Technology peripherals
AI
Quickly build a large language model AI knowledge base in just three minutes
Technology peripherals
AI
Quickly build a large language model AI knowledge base in just three minutes
Quickly build a large language model AI knowledge base in just three minutes

FastGPT
FastGPT is a knowledge base question and answer system built using the LLM large language model, which can provide plug-and-play data processing and model calling functions. At the same time, it also supports Flow visual workflow orchestration to realize complex question and answer scenarios
Knowledge base core flow chart
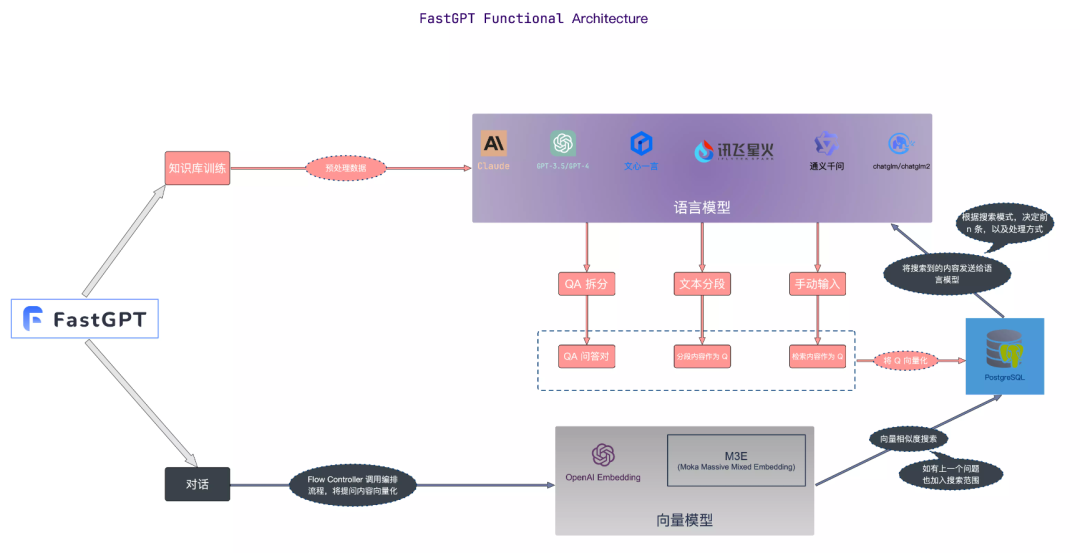 Picture
Picture
Image source: https://doc.fastgpt.in
Private deployment
Use Docker Compose here to quickly perform FastGPT privatization deployment
1. Install Docker
# 安装 Dockercurl -fsSL https://get.docker.com | bash -s docker --mirror Aliyunsystemctl enable --now docker# 安装 docker-composecurl -L https://github.com/docker/compose/releases/download/2.20.3/docker-compose-`uname -s`-`uname -m` -o /usr/local/bin/docker-composechmod +x /usr/local/bin/docker-compose# 验证安装docker -vdocker-compose -v
If it has already been installed, skip directly
2. Container orchestration
Create a local directory and enter the directory
mkdir tinywan-fastgptcd tinywan-fastgpt
The directory path created above is /d/Tinywan/GPT/tinywan-fastgpt
docker-compose.yml configuration file
version: '3.3'services:pg:image: registry.cn-hangzhou.aliyuncs.com/fastgpt/pgvector:v0.5.0 # 阿里云container_name: pgrestart: alwaysports: # 生产环境建议不要暴露- 5432:5432networks:- fastgptenvironment:# 这里的配置只有首次运行生效。修改后,重启镜像是不会生效的。需要把持久化数据删除再重启,才有效果- POSTGRES_USER=username- POSTGRES_PASSWORD=password- POSTGRES_DB=postgresvolumes:- ./pg/data:/var/lib/postgresql/datamongo:image: mongo:5.0.18# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/mongo:5.0.18 # 阿里云container_name: mongorestart: alwaysports: # 生产环境建议不要暴露- 27017:27017networks:- fastgptenvironment:# 这里的配置只有首次运行生效。修改后,重启镜像是不会生效的。需要把持久化数据删除再重启,才有效果- MONGO_INITDB_ROOT_USERNAME=username- MONGO_INITDB_ROOT_PASSWORD=passwordvolumes:- ./mongo/data:/data/dbfastgpt:container_name: fastgptimage: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt:latest # 阿里云ports:- 3000:3000networks:- fastgptdepends_on:- mongo- pgrestart: alwaysenvironment:# root 密码,用户名为: root- DEFAULT_ROOT_PSW=123465# 中转地址,如果是用官方号,不需要管- OPENAI_BASE_URL=https://api.openai.com/v1- CHAT_API_KEY=sb-xxx- DB_MAX_LINK=5 # database max link- TOKEN_KEY=any- ROOT_KEY=root_key- FILE_TOKEN_KEY=filetoken# mongo 配置,不需要改. 如果连不上,可能需要去掉 ?authSource=admin- MONGODB_URI=mongodb://username:password@mongo:27017/fastgpt?authSource=admin# pg配置. 不需要改- PG_URL=postgresql://username:password@pg:5432/postgresvolumes:- ./config.json:/app/data/config.jsonnetworks:fastgpt:
Note: Please fill in the value corresponding to CHAT_API_KEY.
config.json configuration file
{"SystemParams": {"pluginBaseUrl": "","vectorMaxProcess": 15,"qaMaxProcess": 15,"pgHNSWEfSearch": 100},"ChatModels": [{"model": "gpt-3.5-turbo-1106","name": "GPT35-1106","price": 0,"maxContext": 16000,"maxResponse": 4000,"quoteMaxToken": 2000,"maxTemperature": 1.2,"censor": false,"vision": false,"defaultSystemChatPrompt": ""},{"model": "gpt-3.5-turbo-16k","name": "GPT35-16k","maxContext": 16000,"maxResponse": 16000,"price": 0,"quoteMaxToken": 8000,"maxTemperature": 1.2,"censor": false,"vision": false,"defaultSystemChatPrompt": ""},{"model": "gpt-4","name": "GPT4-8k","maxContext": 8000,"maxResponse": 8000,"price": 0,"quoteMaxToken": 4000,"maxTemperature": 1.2,"censor": false,"vision": false,"defaultSystemChatPrompt": ""},{"model": "gpt-4-vision-preview","name": "GPT4-Vision","maxContext": 128000,"maxResponse": 4000,"price": 0,"quoteMaxToken": 100000,"maxTemperature": 1.2,"censor": false,"vision": true,"defaultSystemChatPrompt": ""}],"QAModels": [{"model": "gpt-3.5-turbo-16k","name": "GPT35-16k","maxContext": 16000,"maxResponse": 16000,"price": 0}],"CQModels": [{"model": "gpt-3.5-turbo-1106","name": "GPT35-1106","maxContext": 16000,"maxResponse": 4000,"price": 0,"functionCall": true,"functionPrompt": ""},{"model": "gpt-4","name": "GPT4-8k","maxContext": 8000,"maxResponse": 8000,"price": 0,"functionCall": true,"functionPrompt": ""}],"ExtractModels": [{"model": "gpt-3.5-turbo-1106","name": "GPT35-1106","maxContext": 16000,"maxResponse": 4000,"price": 0,"functionCall": true,"functionPrompt": ""}],"QGModels": [{"model": "gpt-3.5-turbo-1106","name": "GPT35-1106","maxContext": 1600,"maxResponse": 4000,"price": 0}],"VectorModels": [{"model": "text-embedding-ada-002","name": "Embedding-2","price": 0.2,"defaultToken": 700,"maxToken": 3000}],"AudioSpeechModels": [{"model": "tts-1","name": "OpenAI TTS1","price": 0,"voices": [{"label": "Alloy","value": "alloy","bufferId": "openai-Alloy"},{"label": "Echo","value": "echo","bufferId": "openai-Echo"},{"label": "Fable","value": "fable","bufferId": "openai-Fable"},{"label": "Onyx","value": "onyx","bufferId": "openai-Onyx"},{"label": "Nova","value": "nova","bufferId": "openai-Nova"},{"label": "Shimmer","value": "shimmer","bufferId": "openai-Shimmer"}]}],"WhisperModel": {"model": "whisper-1","name": "Whisper1","price": 0}}3. Start the container
Get the updated version of the image through the command docker-compose pull
 Picture
Picture
Start the container through the command docker-compose up -d
 Picture
Picture
View the startup status of the container
 Picture
Picture
4. Access FastGPT
Currently available Direct access via ip:3000. This is a local deployment, so you can access it directly through http://127.0.0.1:3000.
Deployment is successful, you can access the following page:
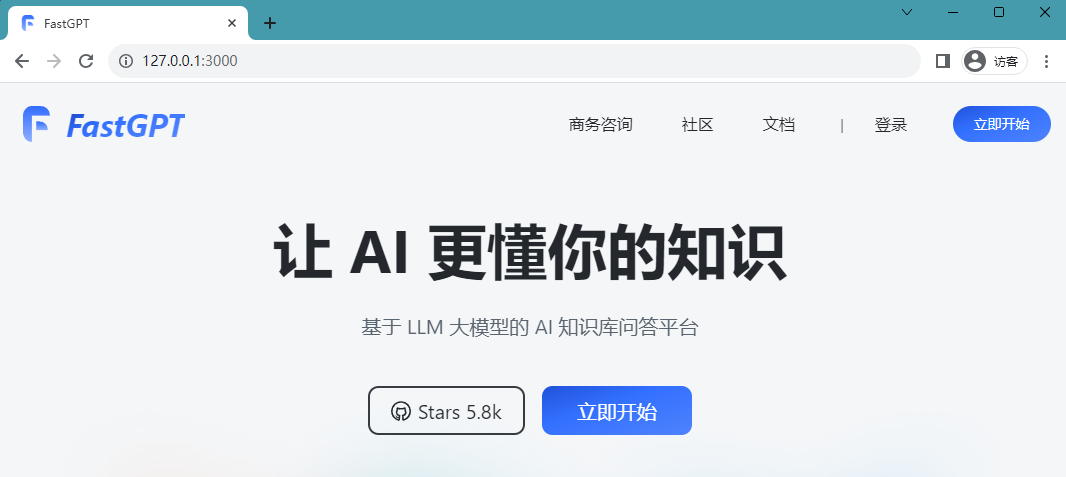 Picture
Picture
The login user name is root and the password is DEFAULT_ROOT_PSW set in the docker-compose.yml environment variable.
After successful login, you will be redirected to the following page:
 Picture
Picture
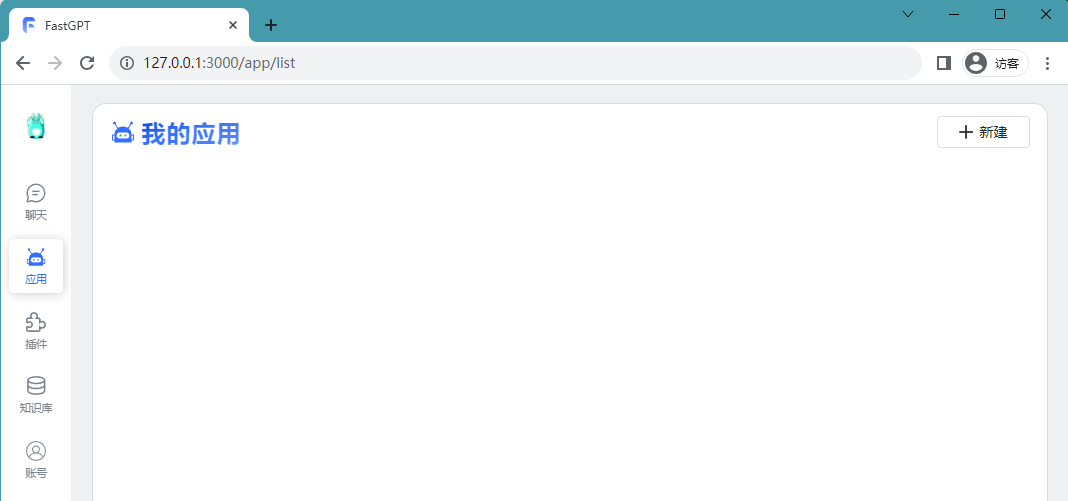
Build Knowledge Base
Create Knowledge Base
After successful login, we can create a new knowledge base and name it Open Source Technology Stack
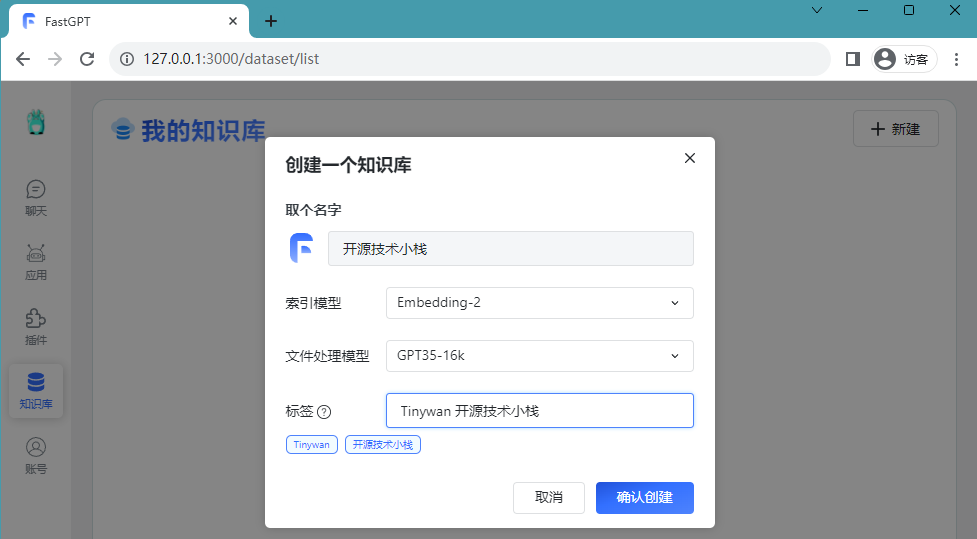 Picture
Picture
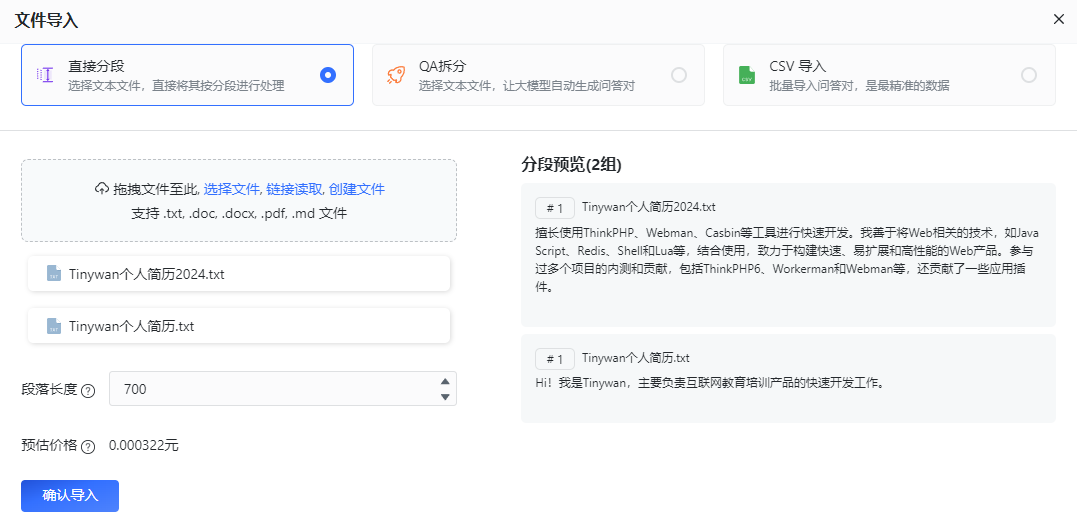
The way to import personal experience into the knowledge base is through file
. The content that needs to be rewritten is: [New/Import] [File Import]. Rewritten content: [Create/Import][File Import]
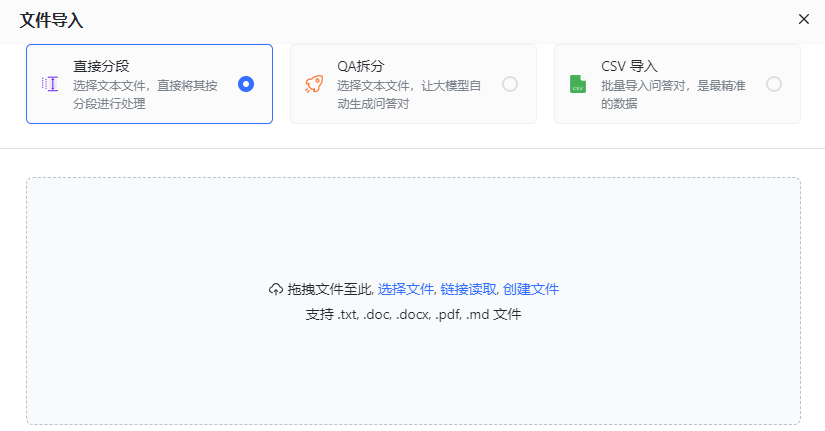 Picture
Picture
After confirmation, start converting the current data into vector data
 Picture
Picture
When selecting a file to import, you can choose the direct segmentation plan. Direct segmentation will use the sentence segmenter to split the text to a certain length, and finally split it into multiple groups of q. If you choose the direct segmentation solution, it is recommended to use a general template when setting the reference prompt words in the application. There is no need to select a question and answer template
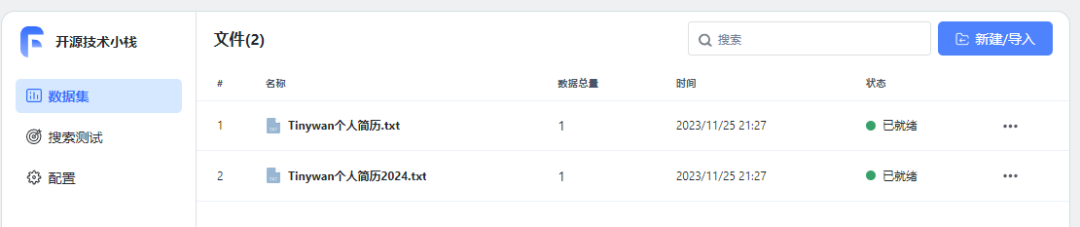
Import successful
 图片
图片
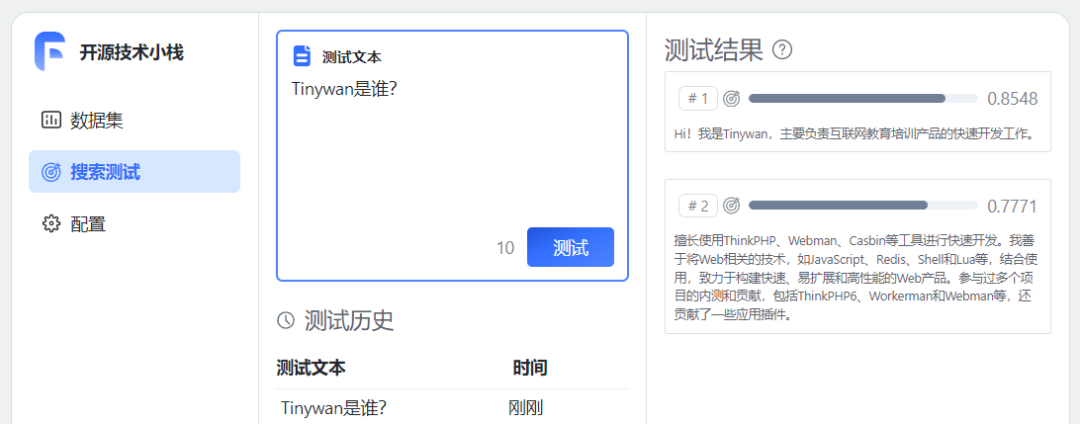
至此,个人知识库已经建好了。尝试进行测试问答
 图片
图片
重新书写后的内容:重新连接训练数据
https://mp.weixin.qq.com/s/1GD8eKrxJWXdgS3OKR4VHQhttps://mp.weixin.qq.com/s/BFdfDXHavZ_jZwVaFq2duQhttps://mp.weixin.qq.com/s/mNhMCzUtLUKrIzqSVa-qZAhttps://mp.weixin.qq.com/s/n4n-0UCWJW9u2N1ca3HisQhttps://mp.weixin.qq.com/s/WXAPxHYteX7h1Hu73KEnFQhttps://mp.weixin.qq.com/s/chI8IbenaMFejvS7blLsBw
 图片
图片
等待所有数据准备就绪
 图片
图片
使用知识库
创建应用
使用知识库必须要创建一个应用
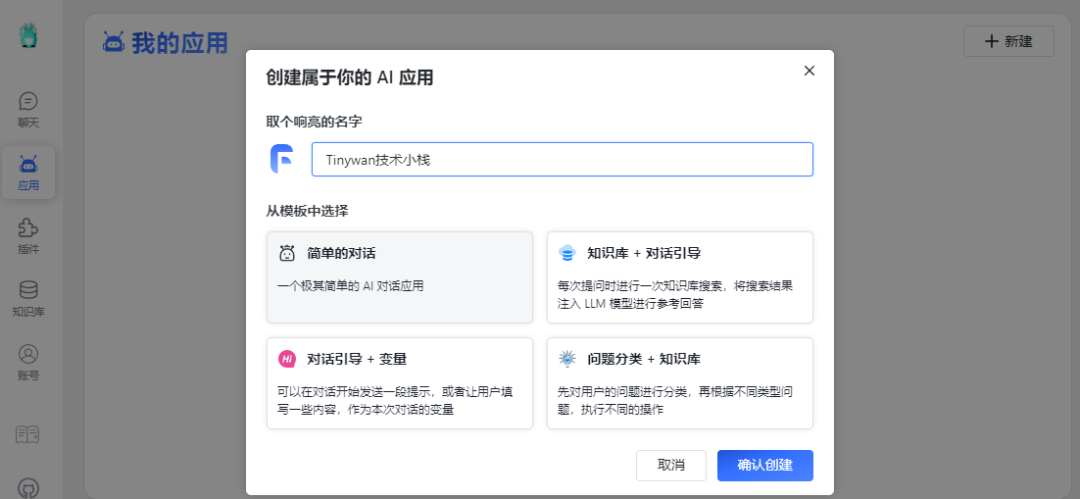 图片
图片
关联知识库
已添加开场白并选择绑定相应的知识库开源技术堆栈
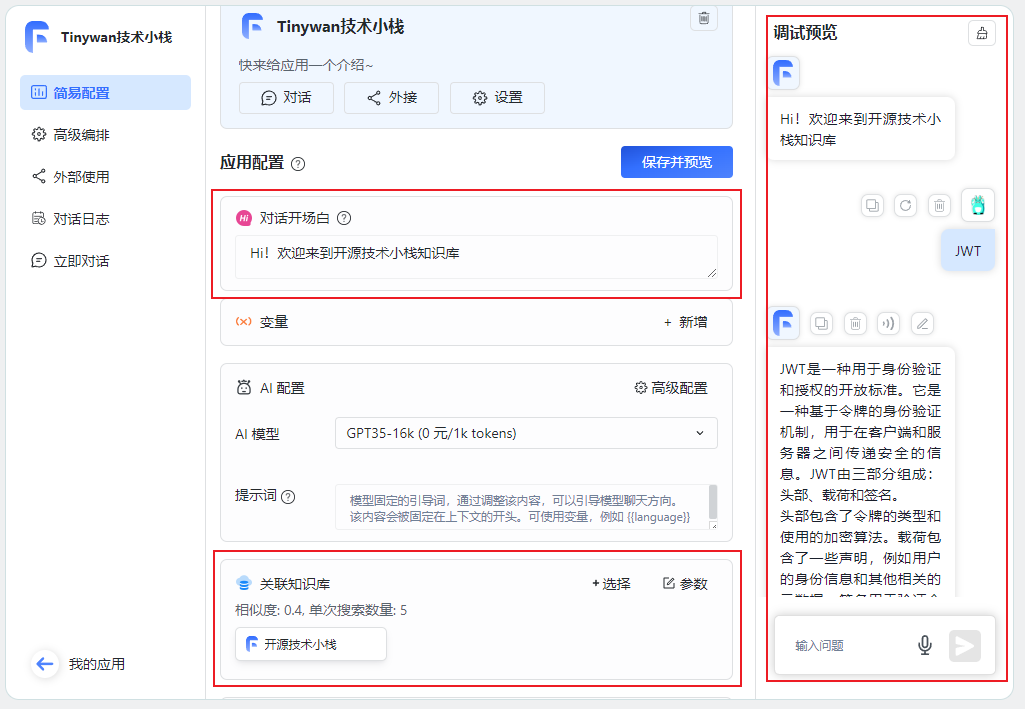 图片
图片
点击保存预留后,可以直接在右边调试预览框预览对话进行文档内容测试。
开始对话
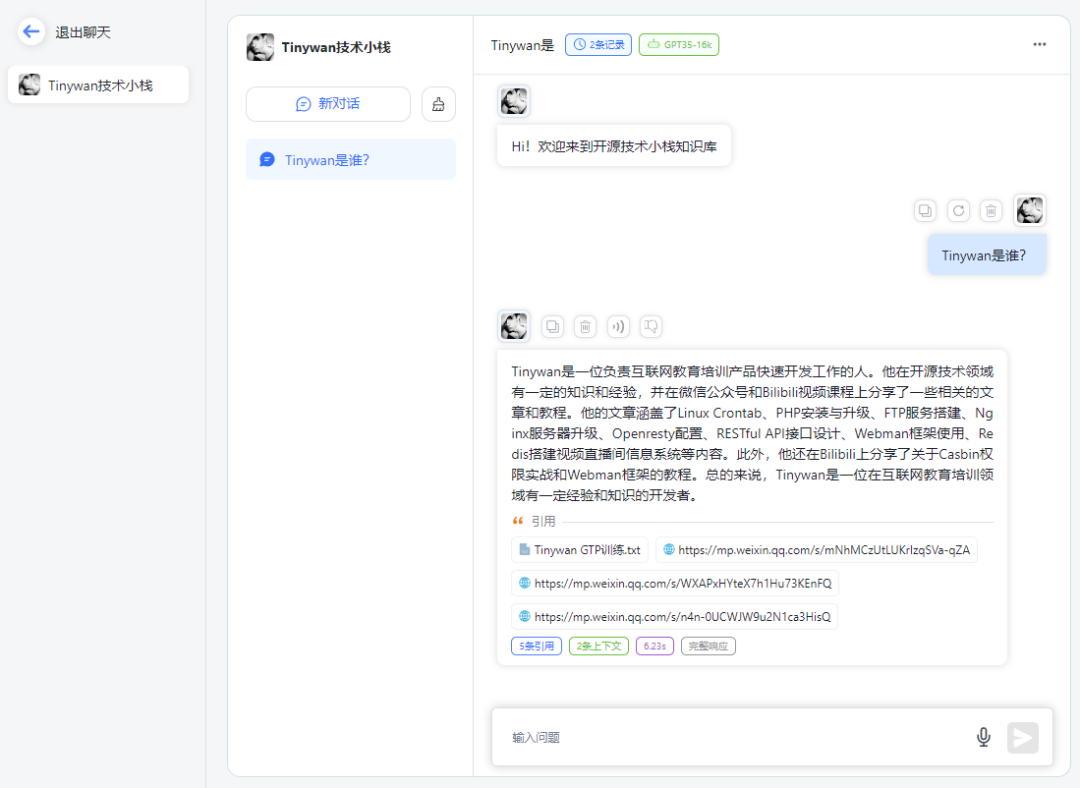 图片
图片
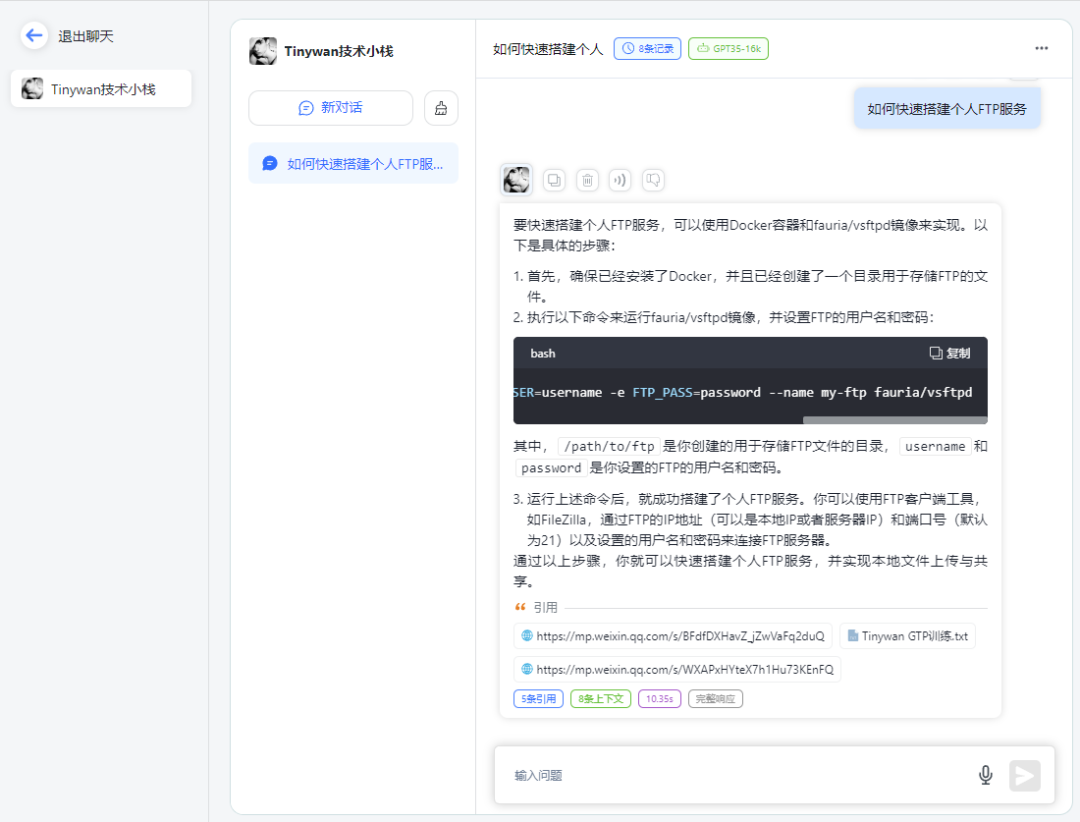 图片
图片
请点击链接查看知识库引用
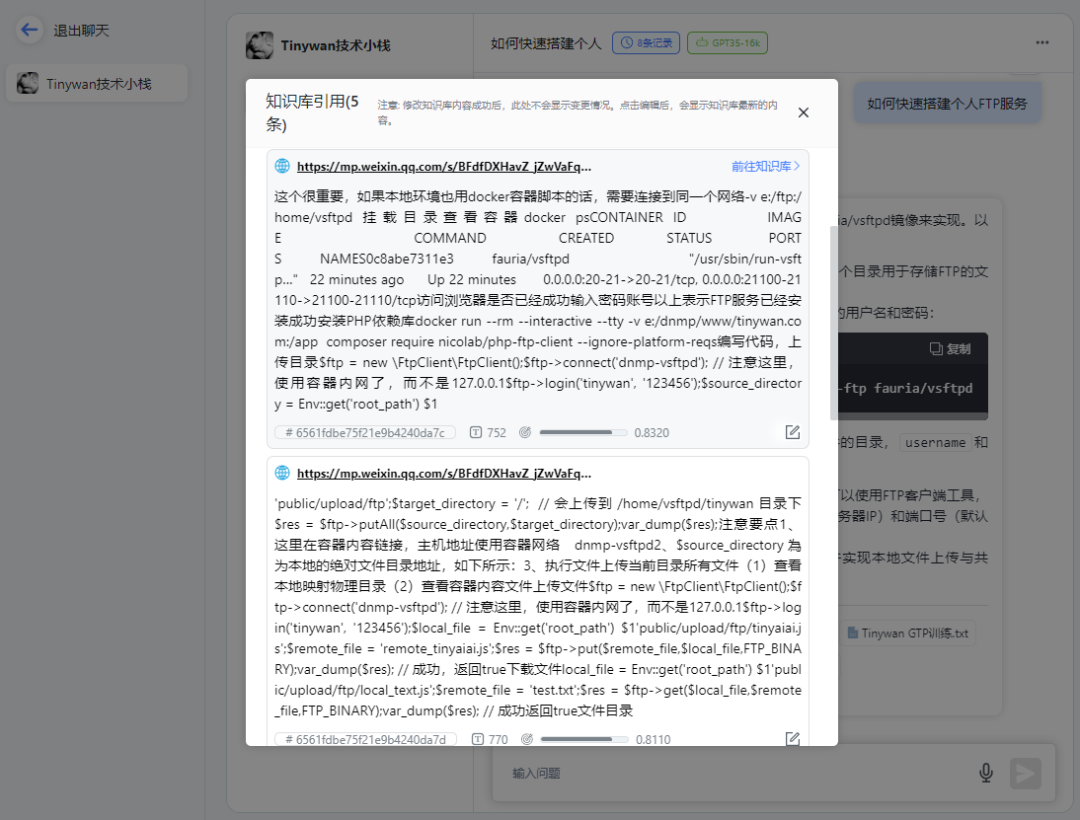 图片
图片
打开对应链接可以直接跳转到微信公众号文章地址
总结
构建私有数据训练服务,针对问题提供精准回答。可以通过AI服务训练自有数据,形成AI知识库,然后创建不同的机器人针对用户问题提供精准回答。并且可以通过API接口很方便整合到自己的产品服务中。
The above is the detailed content of Quickly build a large language model AI knowledge base in just three minutes. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1389
1389
 52
52

 Web3 trading platform ranking_Web3 global exchanges top ten summary
Apr 21, 2025 am 10:45 AM
Web3 trading platform ranking_Web3 global exchanges top ten summary
Apr 21, 2025 am 10:45 AM
Binance is the overlord of the global digital asset trading ecosystem, and its characteristics include: 1. The average daily trading volume exceeds $150 billion, supports 500 trading pairs, covering 98% of mainstream currencies; 2. The innovation matrix covers the derivatives market, Web3 layout and education system; 3. The technical advantages are millisecond matching engines, with peak processing volumes of 1.4 million transactions per second; 4. Compliance progress holds 15-country licenses and establishes compliant entities in Europe and the United States.
 What are the top ten platforms in the currency exchange circle?
Apr 21, 2025 pm 12:21 PM
What are the top ten platforms in the currency exchange circle?
Apr 21, 2025 pm 12:21 PM
The top exchanges include: 1. Binance, the world's largest trading volume, supports 600 currencies, and the spot handling fee is 0.1%; 2. OKX, a balanced platform, supports 708 trading pairs, and the perpetual contract handling fee is 0.05%; 3. Gate.io, covers 2700 small currencies, and the spot handling fee is 0.1%-0.3%; 4. Coinbase, the US compliance benchmark, the spot handling fee is 0.5%; 5. Kraken, the top security, and regular reserve audit.
 Rexas Finance (RXS) can surpass Solana (Sol), Cardano (ADA), XRP and Dogecoin (Doge) in 2025
Apr 21, 2025 pm 02:30 PM
Rexas Finance (RXS) can surpass Solana (Sol), Cardano (ADA), XRP and Dogecoin (Doge) in 2025
Apr 21, 2025 pm 02:30 PM
In the volatile cryptocurrency market, investors are looking for alternatives that go beyond popular currencies. Although well-known cryptocurrencies such as Solana (SOL), Cardano (ADA), XRP and Dogecoin (DOGE) also face challenges such as market sentiment, regulatory uncertainty and scalability. However, a new emerging project, RexasFinance (RXS), is emerging. It does not rely on celebrity effects or hype, but focuses on combining real-world assets (RWA) with blockchain technology to provide investors with an innovative way to invest. This strategy makes it hoped to be one of the most successful projects of 2025. RexasFi
 Top 10 cryptocurrency exchange platforms The world's largest digital currency exchange list
Apr 21, 2025 pm 07:15 PM
Top 10 cryptocurrency exchange platforms The world's largest digital currency exchange list
Apr 21, 2025 pm 07:15 PM
Exchanges play a vital role in today's cryptocurrency market. They are not only platforms for investors to trade, but also important sources of market liquidity and price discovery. The world's largest virtual currency exchanges rank among the top ten, and these exchanges are not only far ahead in trading volume, but also have their own advantages in user experience, security and innovative services. Exchanges that top the list usually have a large user base and extensive market influence, and their trading volume and asset types are often difficult to reach by other exchanges.
 Global Asset launches new AI-driven intelligent trading system to improve global trading efficiency
Apr 20, 2025 pm 09:06 PM
Global Asset launches new AI-driven intelligent trading system to improve global trading efficiency
Apr 20, 2025 pm 09:06 PM
Global Assets launches a new AI intelligent trading system to lead the new era of trading efficiency! The well-known comprehensive trading platform Global Assets officially launched its AI intelligent trading system, aiming to use technological innovation to improve global trading efficiency, optimize user experience, and contribute to the construction of a safe and reliable global trading platform. The move marks a key step for global assets in the field of smart finance, further consolidating its global market leadership. Opening a new era of technology-driven and open intelligent trading. Against the backdrop of in-depth development of digitalization and intelligence, the trading market's dependence on technology is increasing. The AI intelligent trading system launched by Global Assets integrates cutting-edge technologies such as big data analysis, machine learning and blockchain, and is committed to providing users with intelligent and automated trading services to effectively reduce human factors.
 How to avoid losses after ETH upgrade
Apr 21, 2025 am 10:03 AM
How to avoid losses after ETH upgrade
Apr 21, 2025 am 10:03 AM
After ETH upgrade, novices should adopt the following strategies to avoid losses: 1. Do their homework and understand the basic knowledge and upgrade content of ETH; 2. Control positions, test the waters in small amounts and diversify investment; 3. Make a trading plan, clarify goals and set stop loss points; 4. Profil rationally and avoid emotional decision-making; 5. Choose a formal and reliable trading platform; 6. Consider long-term holding to avoid the impact of short-term fluctuations.
 'Black Monday Sell' is a tough day for the cryptocurrency industry
Apr 21, 2025 pm 02:48 PM
'Black Monday Sell' is a tough day for the cryptocurrency industry
Apr 21, 2025 pm 02:48 PM
The plunge in the cryptocurrency market has caused panic among investors, and Dogecoin (Doge) has become one of the hardest hit areas. Its price fell sharply, and the total value lock-in of decentralized finance (DeFi) (TVL) also saw a significant decline. The selling wave of "Black Monday" swept the cryptocurrency market, and Dogecoin was the first to be hit. Its DeFiTVL fell to 2023 levels, and the currency price fell 23.78% in the past month. Dogecoin's DeFiTVL fell to a low of $2.72 million, mainly due to a 26.37% decline in the SOSO value index. Other major DeFi platforms, such as the boring Dao and Thorchain, TVL also dropped by 24.04% and 20, respectively.
 How to win KERNEL airdrop rewards on Binance Full process strategy
Apr 21, 2025 pm 01:03 PM
How to win KERNEL airdrop rewards on Binance Full process strategy
Apr 21, 2025 pm 01:03 PM
In the bustling world of cryptocurrencies, new opportunities always emerge. At present, KernelDAO (KERNEL) airdrop activity is attracting much attention and attracting the attention of many investors. So, what is the origin of this project? What benefits can BNB Holder get from it? Don't worry, the following will reveal it one by one for you.
