
 Technology peripherals
AI
The rephrased title is: ByteDance's cooperation with East China Normal University: Exploring the contextual learning capabilities of small models
Technology peripherals
AI
The rephrased title is: ByteDance's cooperation with East China Normal University: Exploring the contextual learning capabilities of small models
The rephrased title is: ByteDance's cooperation with East China Normal University: Exploring the contextual learning capabilities of small models

It is well known that large language models (LLM) can learn from a small number of examples through contextual learning without the need for model fine-tuning. Currently, this contextual learning phenomenon can only be observed in large models. For example, large models such as GPT-4 and Llama have shown excellent performance in many fields, but due to resource constraints or high real-time requirements, large models cannot be used in many scenarios
So, do regular-sized models have this capability? In order to explore the contextual learning capabilities of small models, research teams from Byte and East China Normal University conducted research on scene text recognition tasks.
Currently, in practical application scenarios, scene text recognition faces a variety of challenges: different scenes, text layout, deformation, lighting changes, blurred writing, font diversity, etc. Therefore, It is difficult to train a unified text recognition model that can handle all scenarios.
A direct way to solve this problem is to collect corresponding data and fine-tune the model in specific scenarios. However, this process requires retraining the model, which is computationally intensive, and requires saving multiple model weights to adapt to different scenarios. If the text recognition model can have context learning capabilities, when faced with new scenarios, it only needs a small amount of annotated data as prompts to improve its performance on new scenarios, thus solving the above problems. However, scene text recognition is a resource-sensitive task, and using a large model as a text recognizer will consume a lot of resources. Through preliminary experimental observations, researchers found that traditional large model training methods are not suitable for scene text recognition tasks
In order to solve this problem, research from ByteDance and East China Normal University The team proposed a self-evolving text recognizer, E2STR (Ego-Evolving Scene Text Recognizer). This is a regular-sized text recognizer that incorporates contextual learning capabilities and can quickly adapt to different text recognition scenarios without the need for fine-tuning

paper Link: https://arxiv.org/pdf/2311.13120.pdf
E2STR is equipped with a contextual training and contextual reasoning mode, which not only reaches the SOTA level on conventional data sets , and a single model can be used to improve the recognition performance in various scenarios and achieve rapid adaptation to new scenarios, even exceeding the recognition performance of a dedicated model after fine-tuning. E2STR demonstrates that regular-sized models are sufficient to achieve effective context learning capabilities in text recognition tasks.
Method
In Figure 1, the training and inference process of E2STR is shown
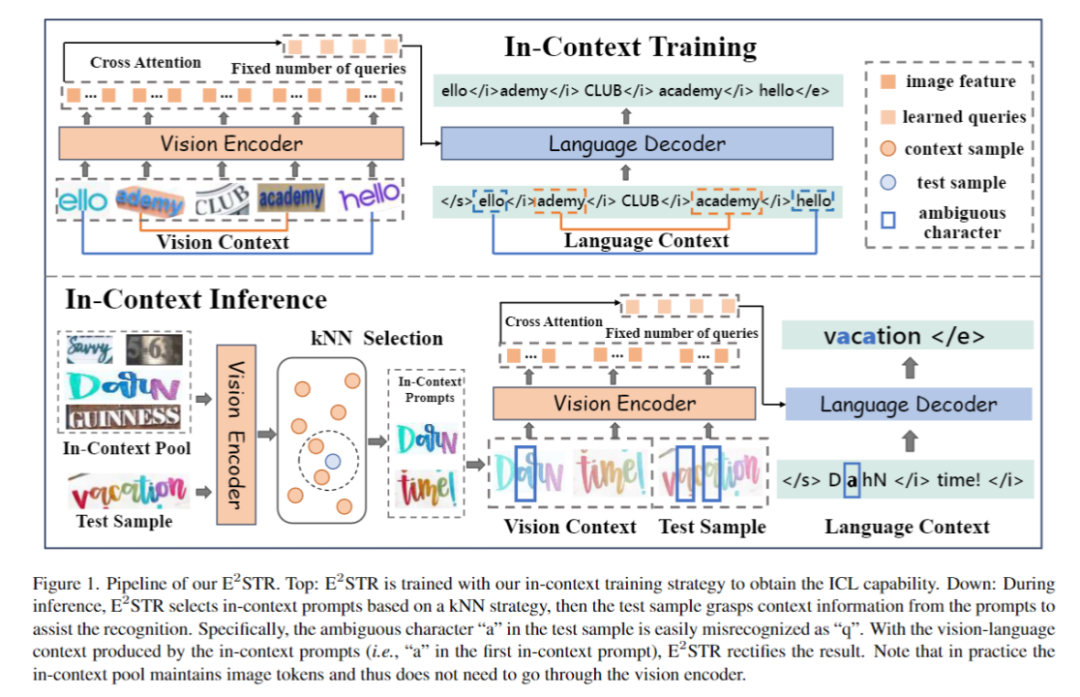
1. Basic text recognition training
#The basic text recognition training phase uses an autoregressive framework to train the visual encoder and language decoder , the purpose is to obtain text recognition capabilities:
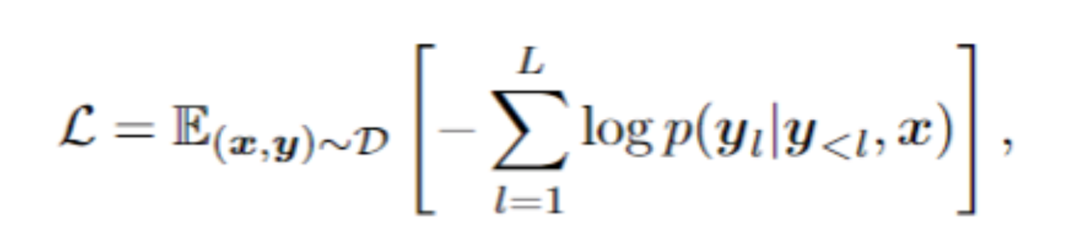
2. Context training
Context training phase E2STR will be further trained according to the context training paradigm proposed in the article. At this stage, E2STR will learn to understand the connections between different samples to gain reasoning capabilities from contextual cues.
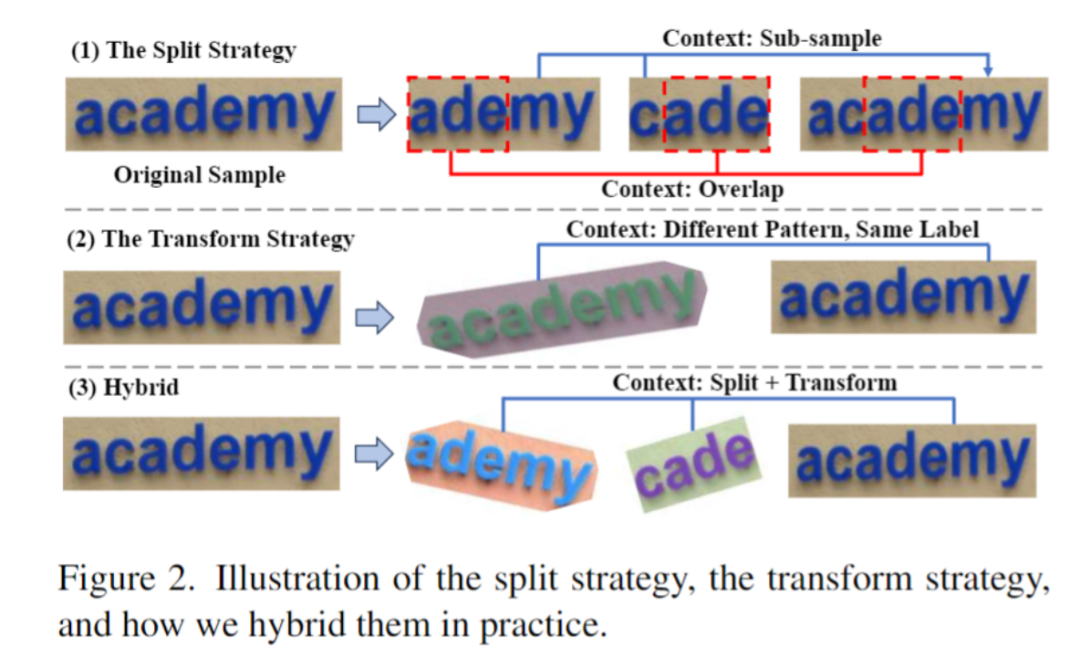
As shown in Figure 2, this article proposes the ST strategy to randomly segment and transform the scene text data to generate a set of "subsample". The subsamples are intrinsically linked both visually and linguistically. These intrinsically related samples are spliced into a sequence, and the model learns contextual knowledge from these semantically rich sequences, thereby gaining the ability to learn context. This stage also uses the autoregressive framework for training:
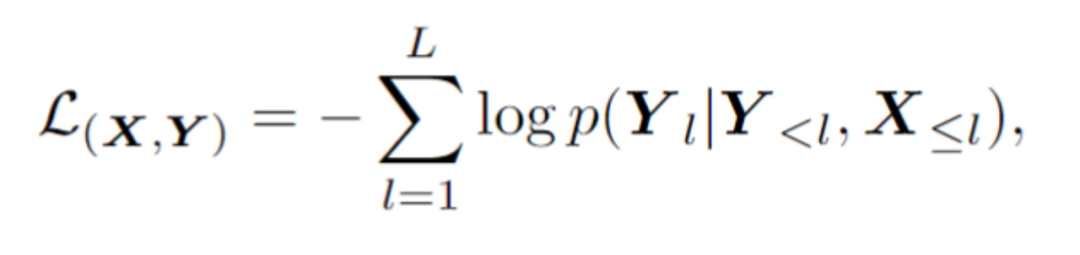
The content that needs to be rewritten is: 3. Contextual reasoning Rewritten content: 3. Reasoning based on context
#For a test sample, the framework will select N samples from the contextual cue pool, which are in the visual latent space Has the highest similarity with the test sample. Specifically, this article calculates image embedding I by averaging pooling on the visual token sequence. Then, the top N samples with the highest cosine similarity between image embeddings and I are selected from the context pool, thus forming contextual cues.
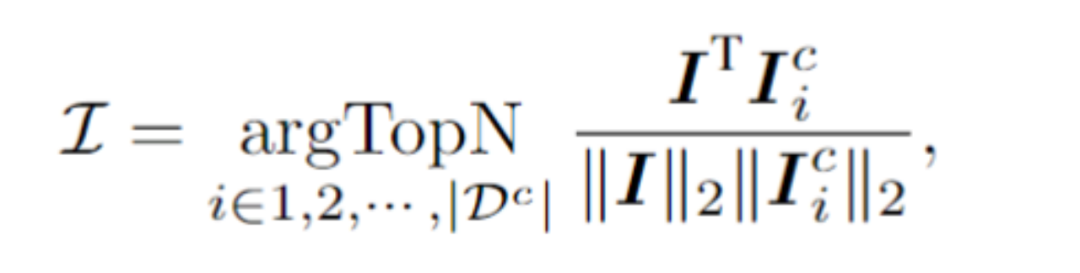
After the contextual cues and test samples are spliced together and fed into the model, E2STR will learn new knowledge from the contextual cues without training. , thereby improving the recognition accuracy of test samples. It is important to note that the contextual cue pool only retains tokens output by the visual encoder, making the contextual cue selection process very efficient. Furthermore, since the context hint pool is small and E2STR requires no training for inference, additional computational overhead is also minimized
Experiment
The experiment is mainly conducted from three aspects: traditional text recognition set, cross-domain scene recognition and difficult sample correction
1. Traditional data set
Randomly select a few samples (1000, 0.025% of the number of samples in the training set) from the training set to form a context prompt pool, and test it in 12 common scene text recognition test sets , the results are as follows:
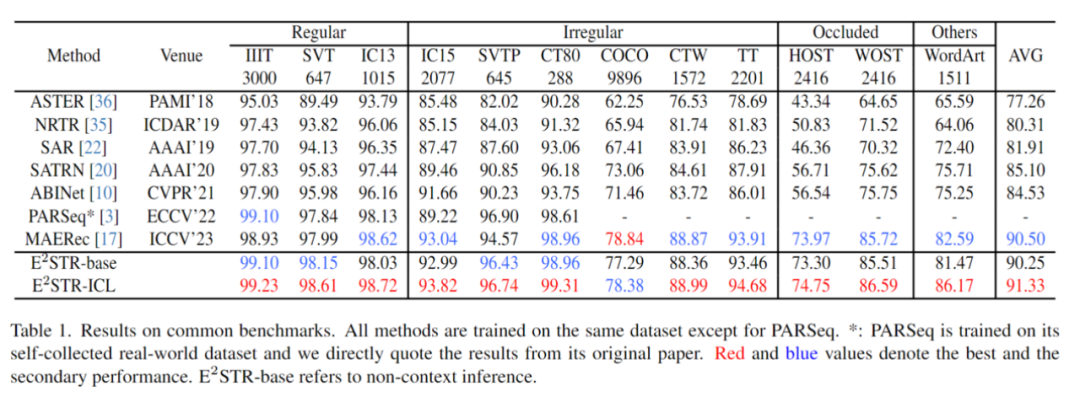
##It can be found that E2STR still improves on traditional data sets whose recognition performance is almost saturated, surpassing the performance of the SOTA model .
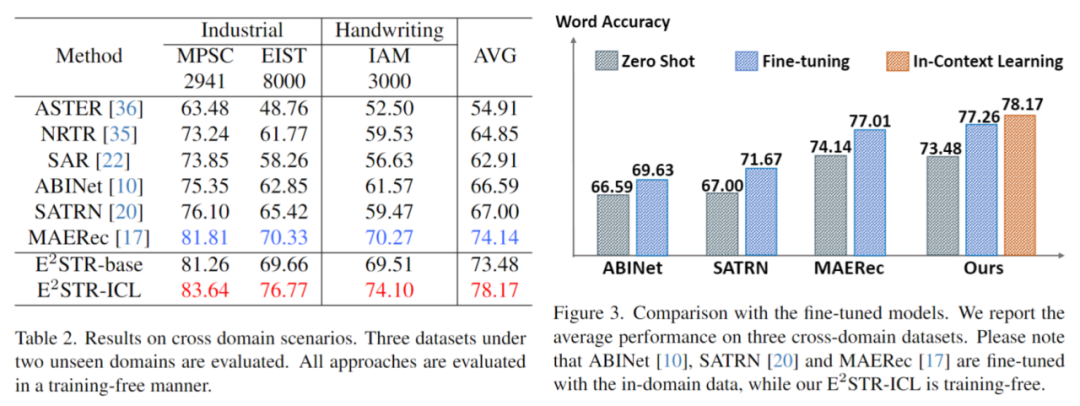
The content that needs to be rewritten is: 2. Cross-domain scenario
Each test set in the cross-domain scenario Only 100 in-domain training samples are provided. The comparison results between no training and fine-tuning are as follows. E2STR even exceeds the fine-tuning results of the SOTA method.
The content that needs to be rewritten is: 3. Modify difficult samples
The researchers collected a batch of difficult samples and provided 10% to 20% annotations for these samples. They compared E2STR's context learning method without training and the SOTA method's fine-tuning learning method. The results are as follows:
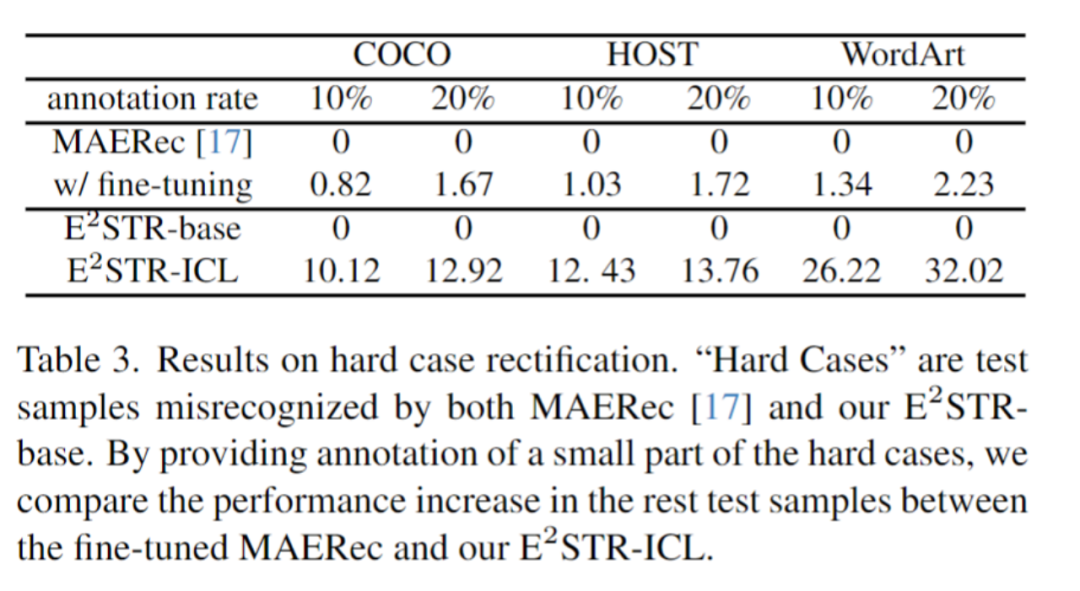
Compared with fine-tuning methods, E2STR-ICL significantly reduces the error rate of difficult samples
Future Outlook
E2STR proves that using appropriate training and inference strategies, small models can also have in-context learning capabilities similar to LLM. In some tasks with strong real-time requirements, small models can also be used to quickly adapt to new scenarios. More importantly, this method of using a single model to achieve rapid adaptation to new scenarios brings one step closer to building a unified and efficient small model.
The above is the detailed content of The rephrased title is: ByteDance's cooperation with East China Normal University: Exploring the contextual learning capabilities of small models. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1382
1382
 52
52

 Abandon the encoder-decoder architecture and use the diffusion model for edge detection, which is more effective. The National University of Defense Technology proposed DiffusionEdge
Feb 07, 2024 pm 10:12 PM
Abandon the encoder-decoder architecture and use the diffusion model for edge detection, which is more effective. The National University of Defense Technology proposed DiffusionEdge
Feb 07, 2024 pm 10:12 PM
Current deep edge detection networks usually adopt an encoder-decoder architecture, which contains up and down sampling modules to better extract multi-level features. However, this structure limits the network to output accurate and detailed edge detection results. In response to this problem, a paper on AAAI2024 provides a new solution. Thesis title: DiffusionEdge:DiffusionProbabilisticModelforCrispEdgeDetection Authors: Ye Yunfan (National University of Defense Technology), Xu Kai (National University of Defense Technology), Huang Yuxing (National University of Defense Technology), Yi Renjiao (National University of Defense Technology), Cai Zhiping (National University of Defense Technology) Paper link: https ://ar
 Open source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!
Apr 03, 2024 pm 12:04 PM
Open source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!
Apr 03, 2024 pm 12:04 PM
0.What does this article do? We propose DepthFM: a versatile and fast state-of-the-art generative monocular depth estimation model. In addition to traditional depth estimation tasks, DepthFM also demonstrates state-of-the-art capabilities in downstream tasks such as depth inpainting. DepthFM is efficient and can synthesize depth maps within a few inference steps. Let’s read about this work together ~ 1. Paper information title: DepthFM: FastMonocularDepthEstimationwithFlowMatching Author: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Tongyi Qianwen is open source again, Qwen1.5 brings six volume models, and its performance exceeds GPT3.5
Feb 07, 2024 pm 10:15 PM
Tongyi Qianwen is open source again, Qwen1.5 brings six volume models, and its performance exceeds GPT3.5
Feb 07, 2024 pm 10:15 PM
In time for the Spring Festival, version 1.5 of Tongyi Qianwen Model (Qwen) is online. This morning, the news of the new version attracted the attention of the AI community. The new version of the large model includes six model sizes: 0.5B, 1.8B, 4B, 7B, 14B and 72B. Among them, the performance of the strongest version surpasses GPT3.5 and Mistral-Medium. This version includes Base model and Chat model, and provides multi-language support. Alibaba’s Tongyi Qianwen team stated that the relevant technology has also been launched on the Tongyi Qianwen official website and Tongyi Qianwen App. In addition, today's release of Qwen 1.5 also has the following highlights: supports 32K context length; opens the checkpoint of the Base+Chat model;
 Large models can also be sliced, and Microsoft SliceGPT greatly increases the computational efficiency of LLAMA-2
Jan 31, 2024 am 11:39 AM
Large models can also be sliced, and Microsoft SliceGPT greatly increases the computational efficiency of LLAMA-2
Jan 31, 2024 am 11:39 AM
Large language models (LLMs) typically have billions of parameters and are trained on trillions of tokens. However, such models are very expensive to train and deploy. In order to reduce computational requirements, various model compression techniques are often used. These model compression techniques can generally be divided into four categories: distillation, tensor decomposition (including low-rank factorization), pruning, and quantization. Pruning methods have been around for some time, but many require recovery fine-tuning (RFT) after pruning to maintain performance, making the entire process costly and difficult to scale. Researchers from ETH Zurich and Microsoft have proposed a solution to this problem called SliceGPT. The core idea of this method is to reduce the embedding of the network by deleting rows and columns in the weight matrix.
 Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas officially enters the era of electric robots! Yesterday, the hydraulic Atlas just "tearfully" withdrew from the stage of history. Today, Boston Dynamics announced that the electric Atlas is on the job. It seems that in the field of commercial humanoid robots, Boston Dynamics is determined to compete with Tesla. After the new video was released, it had already been viewed by more than one million people in just ten hours. The old people leave and new roles appear. This is a historical necessity. There is no doubt that this year is the explosive year of humanoid robots. Netizens commented: The advancement of robots has made this year's opening ceremony look like a human, and the degree of freedom is far greater than that of humans. But is this really not a horror movie? At the beginning of the video, Atlas is lying calmly on the ground, seemingly on his back. What follows is jaw-dropping
 LLaVA-1.6, which catches up with Gemini Pro and improves reasoning and OCR capabilities, is too powerful
Feb 01, 2024 pm 04:51 PM
LLaVA-1.6, which catches up with Gemini Pro and improves reasoning and OCR capabilities, is too powerful
Feb 01, 2024 pm 04:51 PM
In April last year, researchers from the University of Wisconsin-Madison, Microsoft Research, and Columbia University jointly released LLaVA (Large Language and Vision Assistant). Although LLaVA is only trained with a small multi-modal instruction data set, it shows very similar inference results to GPT-4 on some samples. Then in October, they launched LLaVA-1.5, which refreshed the SOTA in 11 benchmarks with simple modifications to the original LLaVA. The results of this upgrade are very exciting, bringing new breakthroughs to the field of multi-modal AI assistants. The research team announced the launch of LLaVA-1.6 version, targeting reasoning, OCR and
 Kuaishou version of Sora 'Ke Ling' is open for testing: generates over 120s video, understands physics better, and can accurately model complex movements
Jun 11, 2024 am 09:51 AM
Kuaishou version of Sora 'Ke Ling' is open for testing: generates over 120s video, understands physics better, and can accurately model complex movements
Jun 11, 2024 am 09:51 AM
What? Is Zootopia brought into reality by domestic AI? Exposed together with the video is a new large-scale domestic video generation model called "Keling". Sora uses a similar technical route and combines a number of self-developed technological innovations to produce videos that not only have large and reasonable movements, but also simulate the characteristics of the physical world and have strong conceptual combination capabilities and imagination. According to the data, Keling supports the generation of ultra-long videos of up to 2 minutes at 30fps, with resolutions up to 1080p, and supports multiple aspect ratios. Another important point is that Keling is not a demo or video result demonstration released by the laboratory, but a product-level application launched by Kuaishou, a leading player in the short video field. Moreover, the main focus is to be pragmatic, not to write blank checks, and to go online as soon as it is released. The large model of Ke Ling is already available in Kuaiying.
 The vitality of super intelligence awakens! But with the arrival of self-updating AI, mothers no longer have to worry about data bottlenecks
Apr 29, 2024 pm 06:55 PM
The vitality of super intelligence awakens! But with the arrival of self-updating AI, mothers no longer have to worry about data bottlenecks
Apr 29, 2024 pm 06:55 PM
I cry to death. The world is madly building big models. The data on the Internet is not enough. It is not enough at all. The training model looks like "The Hunger Games", and AI researchers around the world are worrying about how to feed these data voracious eaters. This problem is particularly prominent in multi-modal tasks. At a time when nothing could be done, a start-up team from the Department of Renmin University of China used its own new model to become the first in China to make "model-generated data feed itself" a reality. Moreover, it is a two-pronged approach on the understanding side and the generation side. Both sides can generate high-quality, multi-modal new data and provide data feedback to the model itself. What is a model? Awaker 1.0, a large multi-modal model that just appeared on the Zhongguancun Forum. Who is the team? Sophon engine. Founded by Gao Yizhao, a doctoral student at Renmin University’s Hillhouse School of Artificial Intelligence.
