
 Technology peripherals
AI
Use vision to prompt! Shen Xiangyang showed off the new model of IDEA Research Institute, which requires no training or fine-tuning and can be used out of the box.
Technology peripherals
AI
Use vision to prompt! Shen Xiangyang showed off the new model of IDEA Research Institute, which requires no training or fine-tuning and can be used out of the box.
Use vision to prompt! Shen Xiangyang showed off the new model of IDEA Research Institute, which requires no training or fine-tuning and can be used out of the box.

What kind of experience will it bring when using visual prompts?
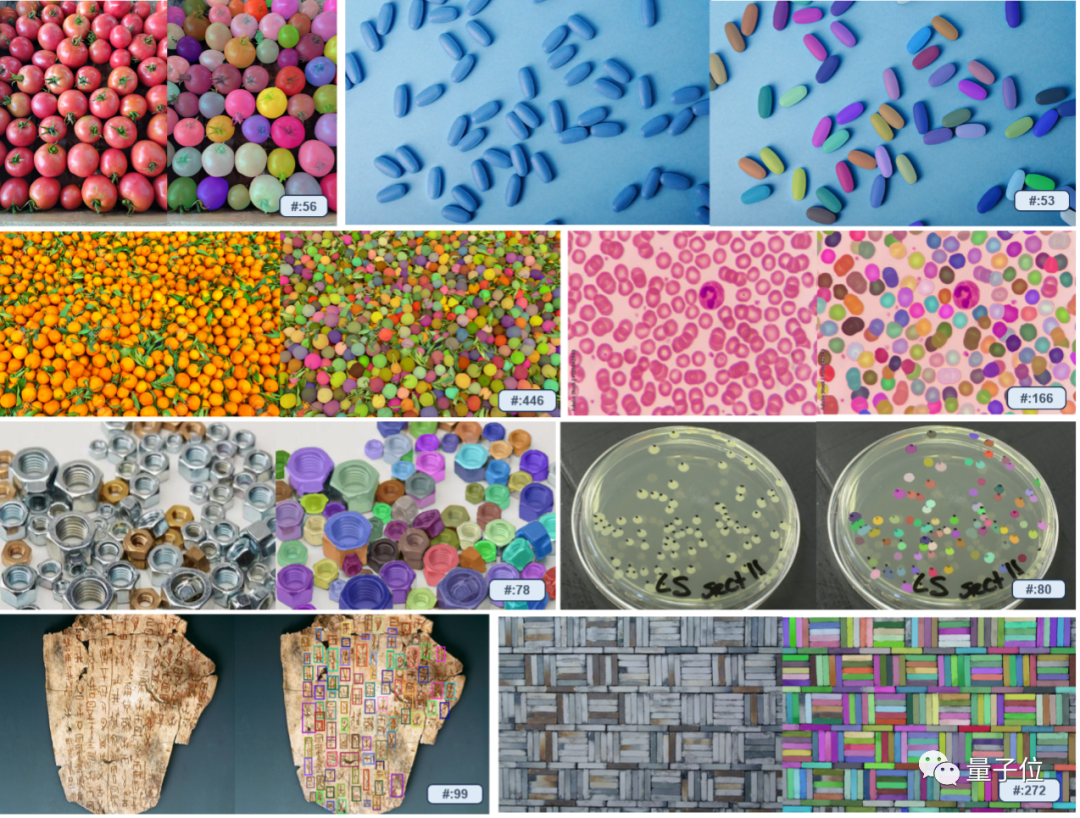
Just draw a random outline in the picture and the same category will be marked immediately!

Even the grain-counting step is difficult for GPT-4V to handle. You only need to manually pull the box to find all the rice grains.

There is a new target detection paradigm!
At the just-concluded IDEA Annual Conference, Shen Xiangyang, founding chairman of the IDEA Research Institute and foreign academician of the National Academy of Engineering, presented the latest research results -
Based on the Visual Prompt model The content of T-Rex needs to be rewritten

The entire interactive process is ready to use out of the box and can be completed in just a few steps.
Previously, Meta’s open source SAM segmented all models, which directly ushered in the GPT-3 moment in the CV field. However, it was still based on the text prompt paradigm, which would be more difficult to deal with some complex and rare scenarios.
Now you can easily solve the problem by exchanging pictures for pictures.
In addition, the entire conference is also full of useful information, such as Think-on-Graph knowledge-driven large model, developer platform MoonBit, AI scientific research artifact ReadPaper update 2.0, SPU confidential computing co-processor , controllable portrait video generation platform HiveNet, etc.
Finally, Shen Xiangyang also shared the project on which he spent the most time in the past few years: Low-altitude Economy.
I believe that when the low-altitude economy is relatively mature, there will be 100,000 drones in the sky of Shenzhen every day, and millions of drones taking off every day
Use vision to make prompts
In addition to the basic single-round prompt function, T-Rex also supports three advanced modes
- Multi-round positive mode
This is similar to multiple rounds of dialogue, which can produce more accurate results and avoid missed detections
- Positive and negative example mode
It is suitable for scenarios where visual cues are ambiguous and cause false detections.
Cross-graph mode allows you to redesign and layout charts to easily visualize data and information
By using one reference chart to detect other images

According to reports, T-Rex is not restricted by predefined categories and can use visual examples to specify detection targets, thereby solving the problem that certain objects are difficult to fully express in words and improving prompt efficiency. Especially in the case of complex components in some industrial scenarios, the effect is particularly obvious
In addition, by interacting with users, it can also be quickly evaluated at any time Test results and perform error correction, etc.
The composition of T-Rex mainly includes three components: image encoder, prompt encoder and frame decoder
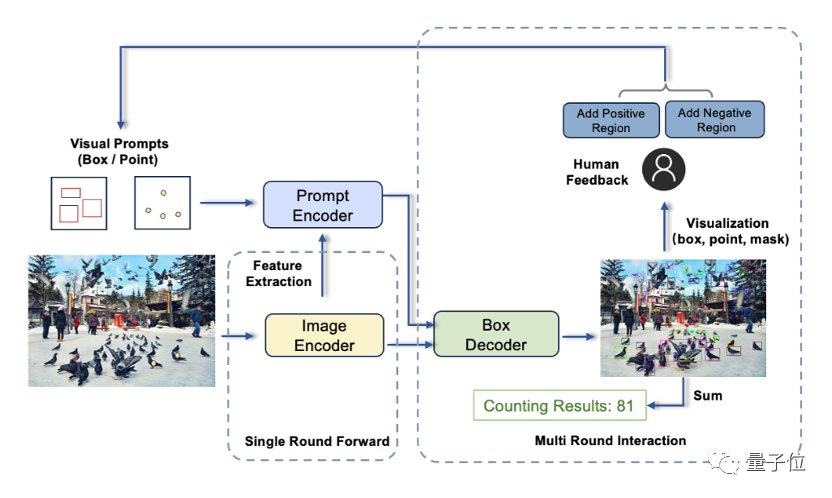
This work comes from IDEA Research Institute Computer Vision and Robotics Research Center.
The team’s previously open source target detection model DINO is the first DETR model to rank first in the COCO target detection list; it has become a hit on Github (it has received 11K stars so far) Grounding DINO, a zero-sample detector, and Grounded SAM, which can detect and segment everything. For more technical details, please click on the link at the end of the article.
The whole conference is full of useful information
In addition, several research results were also shared at the IDEA conference.
For exampleThink-on-Graph knowledge-driven large model, simply speaking, it combines the large model with the knowledge graph.
Large models are good at intention understanding and autonomous learning, while knowledge graphs are better at logical chain reasoning because of their structured knowledge storage methods.
Think-on-Graph drives the large model agent to "think" on the knowledge graph, and gradually searches and infers the optimal answer (search and reason step by step on the associated entities of the knowledge graph). In every step of reasoning, the large model is personally involved and learns from each other's strengths and weaknesses with the knowledge graph.

MoonBit is a developer platform powered by Wasm and designed for cloud computing and edge computing.
The system not only provides universal programming language design, but also integrates modules such as compilers, build systems, integrated development environments (IDEs), and deployment tools to improve development experience and efficiency

T-Rex link:
https://trex-counting.github.io/
The above is the detailed content of Use vision to prompt! Shen Xiangyang showed off the new model of IDEA Research Institute, which requires no training or fine-tuning and can be used out of the box.. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1387
1387
 52
52

 The difference between idea community version and professional version
Nov 07, 2023 pm 05:23 PM
The difference between idea community version and professional version
Nov 07, 2023 pm 05:23 PM
The differences between IDEA Community Edition and Professional Edition include authorization methods, functions, support and updates, plug-in support, cloud services and team collaboration, mobile development support, education and learning, integration and scalability, error handling and debugging, security and privacy protection. etc. Detailed introduction: 1. Authorization method. The community version is free and suitable for all developers, no matter what operating system is used. The community version supports open source projects and commercial projects. The professional version is paid and suitable for commercial development. The professional version has 30 There is a trial period of three days, after which you need to purchase a license to continue using it, etc.
 Beyond ORB-SLAM3! SL-SLAM: Low light, severe jitter and weak texture scenes are all handled
May 30, 2024 am 09:35 AM
Beyond ORB-SLAM3! SL-SLAM: Low light, severe jitter and weak texture scenes are all handled
May 30, 2024 am 09:35 AM
Written previously, today we discuss how deep learning technology can improve the performance of vision-based SLAM (simultaneous localization and mapping) in complex environments. By combining deep feature extraction and depth matching methods, here we introduce a versatile hybrid visual SLAM system designed to improve adaptation in challenging scenarios such as low-light conditions, dynamic lighting, weakly textured areas, and severe jitter. sex. Our system supports multiple modes, including extended monocular, stereo, monocular-inertial, and stereo-inertial configurations. In addition, it also analyzes how to combine visual SLAM with deep learning methods to inspire other research. Through extensive experiments on public datasets and self-sampled data, we demonstrate the superiority of SL-SLAM in terms of positioning accuracy and tracking robustness.
 Five IntelliJ IDEA plug-ins to write code efficiently
Jul 16, 2023 am 08:03 AM
Five IntelliJ IDEA plug-ins to write code efficiently
Jul 16, 2023 am 08:03 AM
Artificial intelligence AI is currently a widely recognized future trend and development direction. Although some people worry that AI may replace all jobs, in fact it will only replace jobs that are highly repetitive and low-output. Therefore, we should learn to work smarter rather than harder. This article introduces 5 AI-driven Intellij plug-ins. These plug-ins can help you improve productivity, reduce tedious repetitive work, and make your work more efficient and convenient. 1GithubCopilotGithubCopilot is an artificial intelligence code assistance tool jointly developed by OpenAI and GitHub. It uses OpenAI’s GPT model to analyze code context, predict and generate new code
 What is NeRF? Is NeRF-based 3D reconstruction voxel-based?
Oct 16, 2023 am 11:33 AM
What is NeRF? Is NeRF-based 3D reconstruction voxel-based?
Oct 16, 2023 am 11:33 AM
1 Introduction Neural Radiation Fields (NeRF) are a fairly new paradigm in the field of deep learning and computer vision. This technology was introduced in the ECCV2020 paper "NeRF: Representing Scenes as Neural Radiation Fields for View Synthesis" (which won the Best Paper Award) and has since become extremely popular, with nearly 800 citations to date [1 ]. The approach marks a sea change in the traditional way machine learning processes 3D data. Neural radiation field scene representation and differentiable rendering process: composite images by sampling 5D coordinates (position and viewing direction) along camera rays; feed these positions into an MLP to produce color and volumetric densities; and composite these values using volumetric rendering techniques image; the rendering function is differentiable, so it can be passed
 Idea how to start multiple SpringBoot projects
May 28, 2023 pm 06:46 PM
Idea how to start multiple SpringBoot projects
May 28, 2023 pm 06:46 PM
1. Preparation Use Idea to build a helloworld SpringBoot project. Development environment description: (1) SpringBoot2.7.0 (2) Idea: IntelliJIDEA2022.2.2 (3) OS: The MacOS environment is different. Some operations are slightly different, but the overall idea is the same. 2. Start multiple SpringBoot2.1 Solution 1: Modify the port of the configuration file In the SpringBoot project, the port number can be configured in the configuration file, so the simplest solution that can be thought of is to modify the port of the configuration file application.(properties/yml) Configurations
 How to solve the problem of empty mapper automatically injected into idea springBoot project
May 17, 2023 pm 06:49 PM
How to solve the problem of empty mapper automatically injected into idea springBoot project
May 17, 2023 pm 06:49 PM
In the SpringBoot project, if MyBatis is used as the persistence layer framework, you may encounter the problem of mapper reporting a null pointer exception when using automatic injection. This is because SpringBoot cannot correctly identify the Mapper interface of MyBatis during automatic injection and requires some additional configuration. There are two ways to solve this problem: 1. Add annotations to the Mapper interface. Add the @Mapper annotation to the Mapper interface to tell SpringBoot that this interface is a Mapper interface and needs to be proxied. An example is as follows: @MapperpublicinterfaceUserMapper{//...}2
 The first pure visual static reconstruction of autonomous driving
Jun 02, 2024 pm 03:24 PM
The first pure visual static reconstruction of autonomous driving
Jun 02, 2024 pm 03:24 PM
A purely visual annotation solution mainly uses vision plus some data from GPS, IMU and wheel speed sensors for dynamic annotation. Of course, for mass production scenarios, it doesn’t have to be pure vision. Some mass-produced vehicles will have sensors like solid-state radar (AT128). If we create a data closed loop from the perspective of mass production and use all these sensors, we can effectively solve the problem of labeling dynamic objects. But there is no solid-state radar in our plan. Therefore, we will introduce this most common mass production labeling solution. The core of a purely visual annotation solution lies in high-precision pose reconstruction. We use the pose reconstruction scheme of Structure from Motion (SFM) to ensure reconstruction accuracy. But pass
 Take a look at the past and present of Occ and autonomous driving! The first review comprehensively summarizes the three major themes of feature enhancement/mass production deployment/efficient annotation.
May 08, 2024 am 11:40 AM
Take a look at the past and present of Occ and autonomous driving! The first review comprehensively summarizes the three major themes of feature enhancement/mass production deployment/efficient annotation.
May 08, 2024 am 11:40 AM
Written above & The author’s personal understanding In recent years, autonomous driving has received increasing attention due to its potential in reducing driver burden and improving driving safety. Vision-based three-dimensional occupancy prediction is an emerging perception task suitable for cost-effective and comprehensive investigation of autonomous driving safety. Although many studies have demonstrated the superiority of 3D occupancy prediction tools compared to object-centered perception tasks, there are still reviews dedicated to this rapidly developing field. This paper first introduces the background of vision-based 3D occupancy prediction and discusses the challenges encountered in this task. Next, we comprehensively discuss the current status and development trends of current 3D occupancy prediction methods from three aspects: feature enhancement, deployment friendliness, and labeling efficiency. at last
