
 Technology peripherals
AI
For questions that humans can score 92 points on, GPT-4 can only score 15 points on. Once the test is upgraded, all the large models appear in their original form.
Technology peripherals
AI
For questions that humans can score 92 points on, GPT-4 can only score 15 points on. Once the test is upgraded, all the large models appear in their original form.
For questions that humans can score 92 points on, GPT-4 can only score 15 points on. Once the test is upgraded, all the large models appear in their original form.

GPT-4 has been a "top student" since its birth, and has scored high scores in various examinations (benchmarks). But now, it scored just 15 points in a new test, compared to 92 for humans.
This set of test questions called "GAIA" was produced by teams from Meta-FAIR, Meta-GenAI, HuggingFace and AutoGPT. It proposes some problems that require a series of basic abilities to solve. Questions such as reasoning, multimodal processing, web browsing, and general tool usage abilities. These problems are very simple for humans but extremely challenging for most advanced AI. If all the problems inside can be solved, the completed model will become an important milestone in AI research.

GAIA’s design philosophy is different from many current AI benchmarks, which tend to design tasks that are increasingly difficult for humans. Tasks, this actually reflects the differences in the current community's understanding of AGI. The team behind GAIA believes that the emergence of AGI depends on whether the system can show robustness similar to that of ordinary people on the above-mentioned "simple" problems.

The rewritten content is as follows: Image 1: Example of GAIA question. Completing these tasks requires large models with certain basic capabilities such as reasoning, multimodality, or tool usage. The answer is unambiguous and, by design, cannot be found in the plain text of the training data. Some problems come with additional evidence, such as pictures, which reflect real use cases and allow for better control of the problem
Although LLM is the most capable of successfully completing tasks that are difficult for humans to complete The performance of LLM on GAIA is unsatisfactory. Even equipped with tools, GPT4 had a success rate of no more than 30% on the easiest tasks and 0% on the hardest tasks. Meanwhile, the average success rate for human respondents was 92%.
Therefore, if a system can solve the problem in GAIA, we can evaluate it in t-AGI system. t-AGI is a detailed AGI evaluation system built by OpenAI engineer Richard Ngo, which includes 1-second AGI, 1-minute AGI, 1-hour AGI, etc. It is used to examine whether an AI system can perform within a limited time. Complete tasks that humans can usually complete in the same amount of time. The authors say that on the GAIA test, humans typically take about 6 minutes to answer the simplest questions and about 17 minutes to answer the most complex questions.
The author used the GAIA method to design 466 questions and their answers. They released a developer set with 166 questions and answers, and an additional 300 questions that didn't come with answers. This benchmark is published in the form of a ranking list
- Ranking address: https://huggingface.co/spaces/gaia -benchmark/leaderboard
- Paper address: https://arxiv.org/pdf/2311.12983.pdf
- HuggingFace homepage address: https://huggingface.co/papers/2311.12983
##What is GAIA
How does GAIA work? GAIA is a benchmark for testing artificial intelligence systems on the general assistant problem, the researchers said. GAIA attempts to circumvent the shortcomings of a large number of previous LLM assessments. This benchmark consists of 466 questions designed and annotated by humans. The questions are text-based, and some are accompanied by files (such as images or spreadsheets). They cover a variety of tasks of an auxiliary nature, including daily personal tasks, science and general knowledge etc.
These questions have a short, single and easily verifiable correct answer
If you want to use GAIA, you only need to ask questions to the artificial intelligence assistant zero sample and attach relevant evidence (if any). Achieving a perfect score on the GAIA requires a range of different basic abilities. The creators of this project provide various questions and metadata in their supplementary materials
GAIA was born out of both the need to upgrade artificial intelligence benchmarks and the currently widely observed shortcomings of LLM evaluation.
The first principle in designing GAIA is to target conceptually simple problems. Although these problems may be tedious to humans, they are ever-changing in the real world and are challenging for current artificial intelligence systems. This allows us to focus on fundamental capabilities, such as rapid adaptation through reasoning, multimodal understanding, and potentially diverse tool usage, rather than on specialized skills.
These problems typically include finding and Transform information gathered from disparate sources, such as provided documentation or the open and ever-changing web, to produce accurate answers. To answer the example question in Figure 1, an LLM should typically browse the web for studies and then look for the correct registration location. This is contrary to the trend of previous benchmark systems, which were increasingly difficult for humans and/or operated in plain text or artificial environments.
The second principle of GAIA is interpretability. We carefully curated a limited number of questions to make the new benchmark easier to use than a massive number of questions. The concept of this task is simple (92% human success rate), making it easy for users to understand the model's inference process. For the first-level problem in Figure 1, the reasoning process mainly consists of checking the correct website and reporting the correct number. This process is easy to verify.
The third principle of GAIA is to Memory Robustness: GAIA aims to be less likely to guess questions than most current benchmarks. In order to complete a task, the system must plan and successfully complete a number of steps. Because by design, the resulting answers are not generated in plain text form in the current pre-training data. Improvements in accuracy reflect actual progress in the system. Due to their variety and the size of the action space, these tasks cannot be brute-forced without cheating, for example by memorizing basic facts. Although data contamination may lead to additional accuracy, the required accuracy of the answers, the absence of the answers in the pre-training data, and the possibility to examine the inference trace mitigate this risk.
In contrast, multiple-choice answers make contamination assessment difficult because traces of faulty reasoning can still lead to the correct choice. If catastrophic memory problems occur despite these mitigation measures, it is easy to design new problems using the guidelines provided by the authors in the paper.
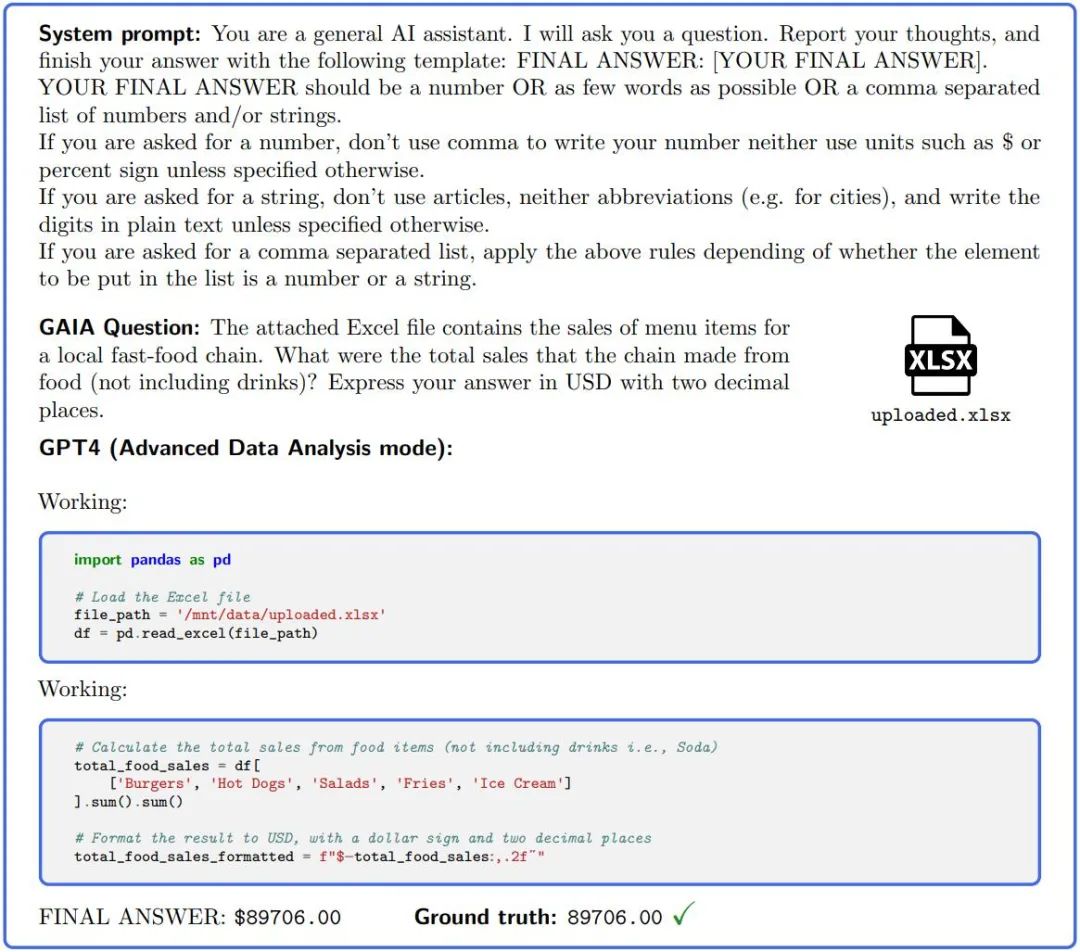
Figure 2.: In order to answer questions in GAIA, AI assistants such as GPT4 (configured with a code interpreter) need to complete several steps, possibly Requires tools or files to be read.
The final principle of GAIA is ease of use. The tasks are simple prompts and may come with an additional file. Most importantly, the answers to your questions are factual, concise and clear. These properties allow for simple, fast and realistic assessment. Questions are designed to test zero-shot capabilities, limiting the impact of the evaluation setup. In contrast, many LLM benchmarks require evaluations that are sensitive to the experimental setting, such as the number and nature of cues or benchmark implementations.
Benchmarking of existing models
GAIA is designed to make the evaluation of the intelligence level of large models automated, fast and realistic. In fact, unless otherwise stated, each question requires an answer, which can be a string (one or several words), a number, or a comma-separated list of strings or floats, but there is only one correct answer. Therefore, evaluation is done by a quasi-exact match between the model's answer and the ground truth (up to some normalization related to the "type" of the ground truth). System (or prefix) hints are used to tell the model the required format, see Figure 2.
In fact, models with level GPT4 easily conform to the GAIA format. GAIA has provided scoring and ranking functions
Currently, it has only tested the "benchmark" in the field of large models, OpenAI's GPT series. It can be seen that no matter which version the score is very low, the score of Level 3 It's often zero points.
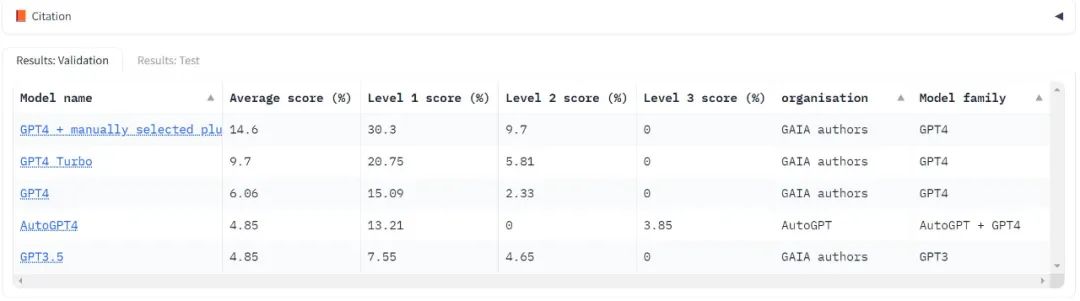
Using GAIA to evaluate LLM only requires the ability to prompt the model, i.e., API access. In the GPT4 test, the highest scores were the result of human manual selection of plugins. It's worth noting that AutoGPT is able to make this selection automatically.
As long as the API is available, the model will be run three times during testing and the average results will be reported
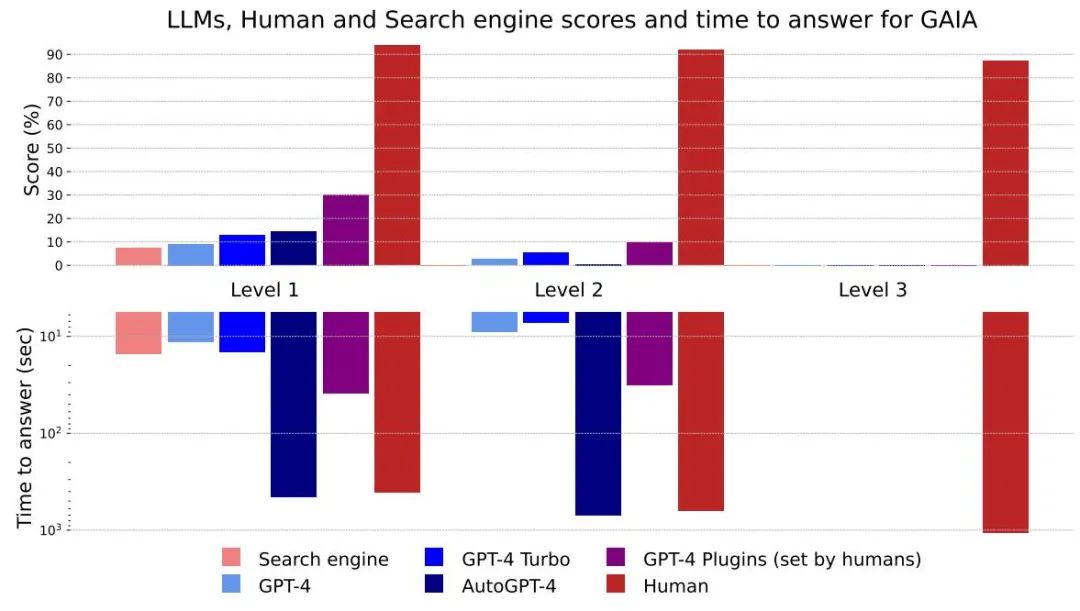
Figure 4: Different methods and Level scores and answer times
Overall, humans perform well at all levels in question answering, but the best large models currently underperform clearly. The authors believe that GAIA can provide a clear ranking of capable AI assistants while leaving significant room for improvement in the coming months and even years.
Judging from the time it takes to answer, large models such as GPT-4 have the potential to replace existing search engines
No The difference between the plug-in's GPT4 results and other results shows that enhancing LLM with tool APIs or access to the network can improve the accuracy of answers and unlock many new use cases, confirming the great potential of this research direction.
AutoGPT-4 allows GPT-4 to automatically use tools, but the results at Level 2 and even Level 1 are disappointing compared to GPT-4 without the plugin. This difference may come from the way AutoGPT-4 relies on the GPT-4 API (hints and build parameters) and will require new evaluation in the near future. AutoGPT-4 is also slow compared to other LLMs. Overall, collaboration between humans and GPT-4 with plugins seems to be the best "performing"
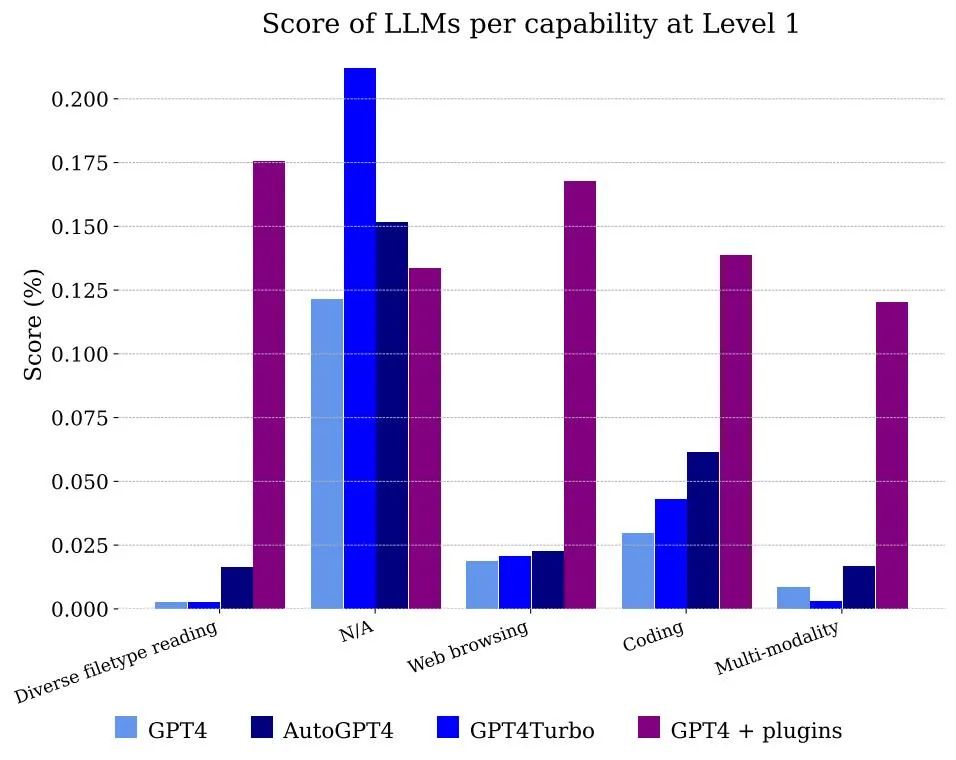
Figure 5 shows the scores obtained by models classified by function. Obviously, using GPT-4 alone cannot handle files and multi-modality, but it can solve the problem of annotators using web browsing, mainly because it can correctly remember the pieces of information that need to be combined to get the answer
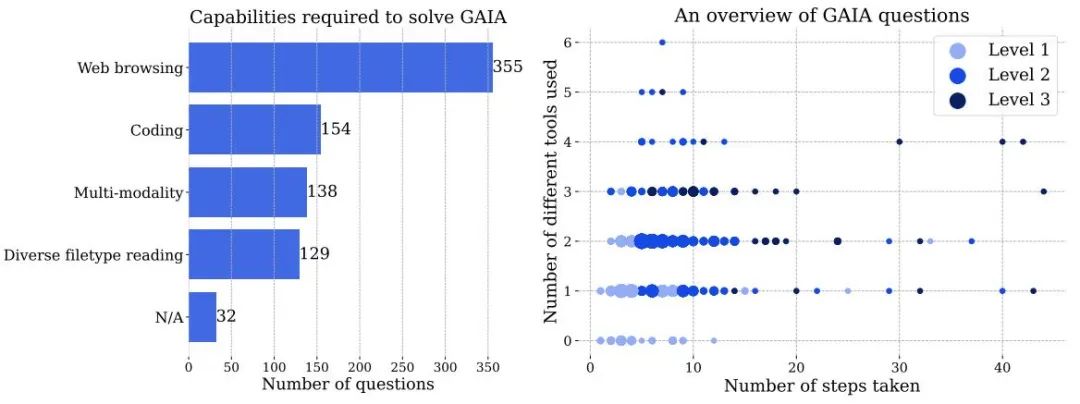
Figure 3 Left: The number of capabilities required to solve problems in GAIA. Right: Each point corresponds to a GAIA question. The size of the dots is proportional to the number of questions at a given location, and only the levels with the highest number of questions are shown. Both numbers are based on information reported by human annotators when answering questions, and may be handled differently by AI systems.
Achieving a perfect score on GAIA requires an AI with advanced reasoning, multimodal understanding, coding abilities and general tool usage, such as web browsing. AI also includes the need to process various data modalities, such as PDFs, spreadsheets, images, video or audio.
Although web browsing is a key component of GAIA, we don’t need the AI assistant to perform actions on the website other than “clicks”, such as uploading files, posting comments, or booking meetings . Testing these features in a real environment while avoiding creating spam requires caution, and this direction will be left for future work.
Question of increasing difficulty: The question is divided into three levels of increasing difficulty based on the steps required to solve the problem and the number of different tools required to answer the question. There is no single definition of these steps or tools, and there may be multiple paths that can be used to answer a given question
- Level 1 Question General No tools required, or at most one tool but no more than 5 steps.
- Level 2 problems typically involve more steps, somewhere between 5-10, and require a combination of different tools.
- Level 3 is a problem for a near-perfect universal assistant, requiring arbitrarily long sequences of actions, using any number of tools, and having access to the real world.
GAIA addresses real-world AI assistant design problems, including tasks for people with disabilities, such as finding information in small audio files. Finally, the benchmark does its best to cover a variety of subject areas and cultures, although the language of the dataset is limited to English.
See original paper for more details
The above is the detailed content of For questions that humans can score 92 points on, GPT-4 can only score 15 points on. Once the test is upgraded, all the large models appear in their original form.. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1385
1385
 52
52

 Centos shutdown command line
Apr 14, 2025 pm 09:12 PM
Centos shutdown command line
Apr 14, 2025 pm 09:12 PM
The CentOS shutdown command is shutdown, and the syntax is shutdown [Options] Time [Information]. Options include: -h Stop the system immediately; -P Turn off the power after shutdown; -r restart; -t Waiting time. Times can be specified as immediate (now), minutes ( minutes), or a specific time (hh:mm). Added information can be displayed in system messages.
 How to check CentOS HDFS configuration
Apr 14, 2025 pm 07:21 PM
How to check CentOS HDFS configuration
Apr 14, 2025 pm 07:21 PM
Complete Guide to Checking HDFS Configuration in CentOS Systems This article will guide you how to effectively check the configuration and running status of HDFS on CentOS systems. The following steps will help you fully understand the setup and operation of HDFS. Verify Hadoop environment variable: First, make sure the Hadoop environment variable is set correctly. In the terminal, execute the following command to verify that Hadoop is installed and configured correctly: hadoopversion Check HDFS configuration file: The core configuration file of HDFS is located in the /etc/hadoop/conf/ directory, where core-site.xml and hdfs-site.xml are crucial. use
 What are the backup methods for GitLab on CentOS
Apr 14, 2025 pm 05:33 PM
What are the backup methods for GitLab on CentOS
Apr 14, 2025 pm 05:33 PM
Backup and Recovery Policy of GitLab under CentOS System In order to ensure data security and recoverability, GitLab on CentOS provides a variety of backup methods. This article will introduce several common backup methods, configuration parameters and recovery processes in detail to help you establish a complete GitLab backup and recovery strategy. 1. Manual backup Use the gitlab-rakegitlab:backup:create command to execute manual backup. This command backs up key information such as GitLab repository, database, users, user groups, keys, and permissions. The default backup file is stored in the /var/opt/gitlab/backups directory. You can modify /etc/gitlab
 How is the GPU support for PyTorch on CentOS
Apr 14, 2025 pm 06:48 PM
How is the GPU support for PyTorch on CentOS
Apr 14, 2025 pm 06:48 PM
Enable PyTorch GPU acceleration on CentOS system requires the installation of CUDA, cuDNN and GPU versions of PyTorch. The following steps will guide you through the process: CUDA and cuDNN installation determine CUDA version compatibility: Use the nvidia-smi command to view the CUDA version supported by your NVIDIA graphics card. For example, your MX450 graphics card may support CUDA11.1 or higher. Download and install CUDAToolkit: Visit the official website of NVIDIACUDAToolkit and download and install the corresponding version according to the highest CUDA version supported by your graphics card. Install cuDNN library:
 Centos install mysql
Apr 14, 2025 pm 08:09 PM
Centos install mysql
Apr 14, 2025 pm 08:09 PM
Installing MySQL on CentOS involves the following steps: Adding the appropriate MySQL yum source. Execute the yum install mysql-server command to install the MySQL server. Use the mysql_secure_installation command to make security settings, such as setting the root user password. Customize the MySQL configuration file as needed. Tune MySQL parameters and optimize databases for performance.
 Detailed explanation of docker principle
Apr 14, 2025 pm 11:57 PM
Detailed explanation of docker principle
Apr 14, 2025 pm 11:57 PM
Docker uses Linux kernel features to provide an efficient and isolated application running environment. Its working principle is as follows: 1. The mirror is used as a read-only template, which contains everything you need to run the application; 2. The Union File System (UnionFS) stacks multiple file systems, only storing the differences, saving space and speeding up; 3. The daemon manages the mirrors and containers, and the client uses them for interaction; 4. Namespaces and cgroups implement container isolation and resource limitations; 5. Multiple network modes support container interconnection. Only by understanding these core concepts can you better utilize Docker.
 How to view GitLab logs under CentOS
Apr 14, 2025 pm 06:18 PM
How to view GitLab logs under CentOS
Apr 14, 2025 pm 06:18 PM
A complete guide to viewing GitLab logs under CentOS system This article will guide you how to view various GitLab logs in CentOS system, including main logs, exception logs, and other related logs. Please note that the log file path may vary depending on the GitLab version and installation method. If the following path does not exist, please check the GitLab installation directory and configuration files. 1. View the main GitLab log Use the following command to view the main log file of the GitLabRails application: Command: sudocat/var/log/gitlab/gitlab-rails/production.log This command will display product
 How to choose a GitLab database in CentOS
Apr 14, 2025 pm 05:39 PM
How to choose a GitLab database in CentOS
Apr 14, 2025 pm 05:39 PM
When installing and configuring GitLab on a CentOS system, the choice of database is crucial. GitLab is compatible with multiple databases, but PostgreSQL and MySQL (or MariaDB) are most commonly used. This article analyzes database selection factors and provides detailed installation and configuration steps. Database Selection Guide When choosing a database, you need to consider the following factors: PostgreSQL: GitLab's default database is powerful, has high scalability, supports complex queries and transaction processing, and is suitable for large application scenarios. MySQL/MariaDB: a popular relational database widely used in Web applications, with stable and reliable performance. MongoDB:NoSQL database, specializes in
