

The introduction of the 2D diffusion model greatly simplifies the creation process of image content and brings innovation to the 2D design industry. In recent years, this diffusion model has expanded into 3D creation, reducing labor costs in applications such as VR, AR, robotics, and gaming. Many studies have begun to explore the use of pre-trained 2D diffusion models, as well as NeRFs methods employing Scored Distillation Sampling (SDS) loss. However, SDS-based methods usually require hours of resource optimization and often cause geometric problems in graphics, such as the multifaceted Janus problem
On the other hand, researchers do not need to spend a lot of time on Various attempts have been made to optimize each resource and achieve diversified generation of 3D diffusion models. These methods usually require obtaining 3D models/point clouds containing real data for training. However, for real images, such training data is difficult to obtain. Since current 3D diffusion methods are usually based on two-stage training, this results in a blurry and difficult-to-denoise latent space on unclassified, highly diverse 3D datasets, making high-quality rendering an urgent challenge.
In order to solve this problem, some researchers have proposed single-stage models, but most of these models only target specific simple categories and have poor generalization
Therefore, the goal of the researchers in this article is to achieve fast, realistic and versatile 3D generation. To this end, they proposed DMV3D. DMV3D is a new single-stage all-category diffusion model that can generate 3D NeRF directly based on the input of model text or a single image. In just 30 seconds on a single A100 GPU, DMV3D can generate a variety of high-fidelity 3D images.

Specifically, DMV3D is a 2D multi-view image diffusion model that integrates the reconstruction and rendering of 3D NeRF into its denoiser and trained in an end-to-end manner without direct 3D supervision. Doing so avoids problems that may arise in separately training 3D NeRF encoders for latent space diffusion (e.g. two-stage models) and tedious methods that optimize for each object (e.g. SDS)
The method in this article is essentially 3D reconstruction based on the framework of 2D multi-view diffusion. This approach is inspired by the RenderDiffusion method, a method for 3D generation via single-view diffusion. However, the limitation of the RenderDiffusion method is that the training data requires prior knowledge of a specific category, and the objects in the data require specific angles or poses, so its generalization is poor and it cannot generate 3D for any type of object
According to researchers, in comparison, only a set of four multi-view sparse projections containing an object is needed to describe an unoccluded 3D object. This training data originates from human spatial imagination, which allows people to construct a complete 3D object from planar views around several objects. This imagination is usually very precise and concrete
However, when applying this input, the task of 3D reconstruction under sparse views still needs to be solved. This is a long-standing problem that is very challenging even when the input is noisy. Our method is able to achieve 3D generation based on a single image/text. For image input, they fix one sparse view as noise-free input and perform denoising on other views similar to 2D image inpainting. To achieve text-based 3D generation, the researchers used attention-based text conditions and type-independent classifiers commonly used in 2D diffusion models.
They only used image space supervision during training and used a large dataset composed of Objaverse synthesized images and MVImgNet real captured images. According to the results, DMV3D has reached the SOTA level in single-image 3D reconstruction, surpassing previous SDS-based methods and 3D diffusion models. In addition, the text-based 3D model generation method is also better than the previous method
 Paper address: https ://arxiv.org/pdf/2311.09217.pdf
Paper address: https ://arxiv.org/pdf/2311.09217.pdf


How to train and Reasoning about single-stage 3D diffusion models?
The researchers first introduced a new diffusion framework that uses a reconstruction-based denoiser to denoise noisy multi-view images for 3D generation; secondly, they A new multi-view denoiser based on LRM, conditioned on the diffusion time step, is proposed to progressively denoise multi-view images through 3D NeRF reconstruction and rendering; finally, the model is further diffused to support Text and image adjustment for controllable generation.
The content that needs to be rewritten is: multi-view diffusion and denoising. Rewritten content: Multi-angle view diffusion and noise reduction
Multi-view diffusion. The original x_0 distribution processed in the 2D diffusion model is a single image distribution in the dataset. Instead, we consider the joint distribution of multi-view images 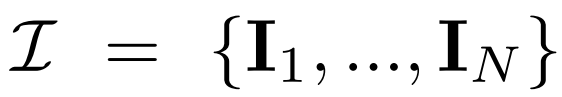 , where each group
, where each group 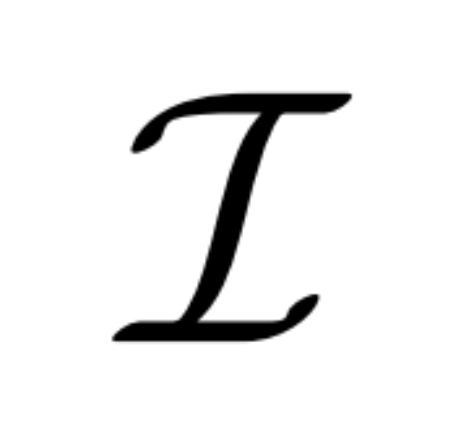 is viewed from viewpoint C = {c_1, .. ., c_N} Image observations of the same 3D scene (asset) in . The diffusion process is equivalent to performing a diffusion operation on each image independently using the same noise schedule, as shown in equation (1) below.
is viewed from viewpoint C = {c_1, .. ., c_N} Image observations of the same 3D scene (asset) in . The diffusion process is equivalent to performing a diffusion operation on each image independently using the same noise schedule, as shown in equation (1) below.
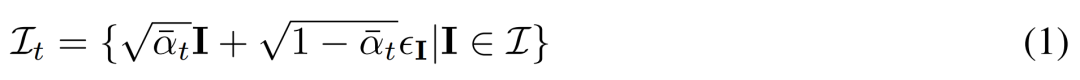
Reconstruction-based denoising. The inverse of the 2D diffusion process is essentially denoising. In this paper, researchers propose to use 3D reconstruction and rendering to achieve 2D multi-view image denoising while outputting clean 3D models for 3D generation. Specifically, they use the 3D reconstruction module E (・) to reconstruct the 3D representation S from the noisy multi-view image 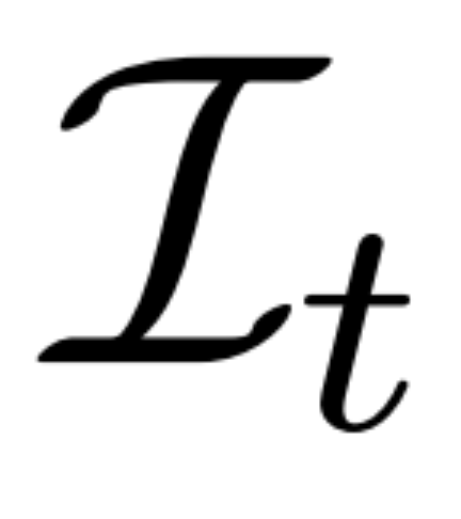 , and use the differentiable rendering module R (・) to reconstruct the denoised image Rendering is performed as shown in formula (2) below.
, and use the differentiable rendering module R (・) to reconstruct the denoised image Rendering is performed as shown in formula (2) below.
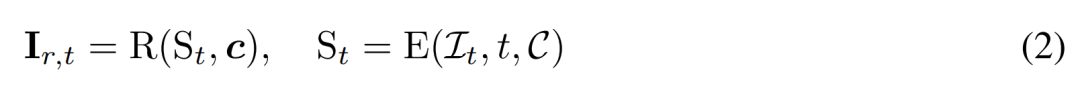
Reconstruction-based multi-view denoiser
The researchers built a multi-view denoiser based on LRM and used a large transformer model to reconstruct a clean three-plane NeRF from the noisy sparse view pose image, and then used the rendering of the reconstructed three-plane NeRF as Denoised output.
Rebuild and render. As shown in Figure 3 below, the researcher uses a Vision Transformer (DINO) to convert the input image 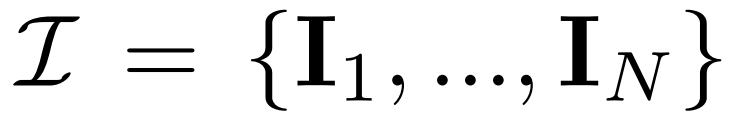 into a 2D token, and then uses the transformer to map the learned three-plane position embedding to the final three-plane , to represent the 3D shape and appearance of the asset. The predicted three planes are next used to decode volume density and color via an MLP for differentiable volume rendering.
into a 2D token, and then uses the transformer to map the learned three-plane position embedding to the final three-plane , to represent the 3D shape and appearance of the asset. The predicted three planes are next used to decode volume density and color via an MLP for differentiable volume rendering.
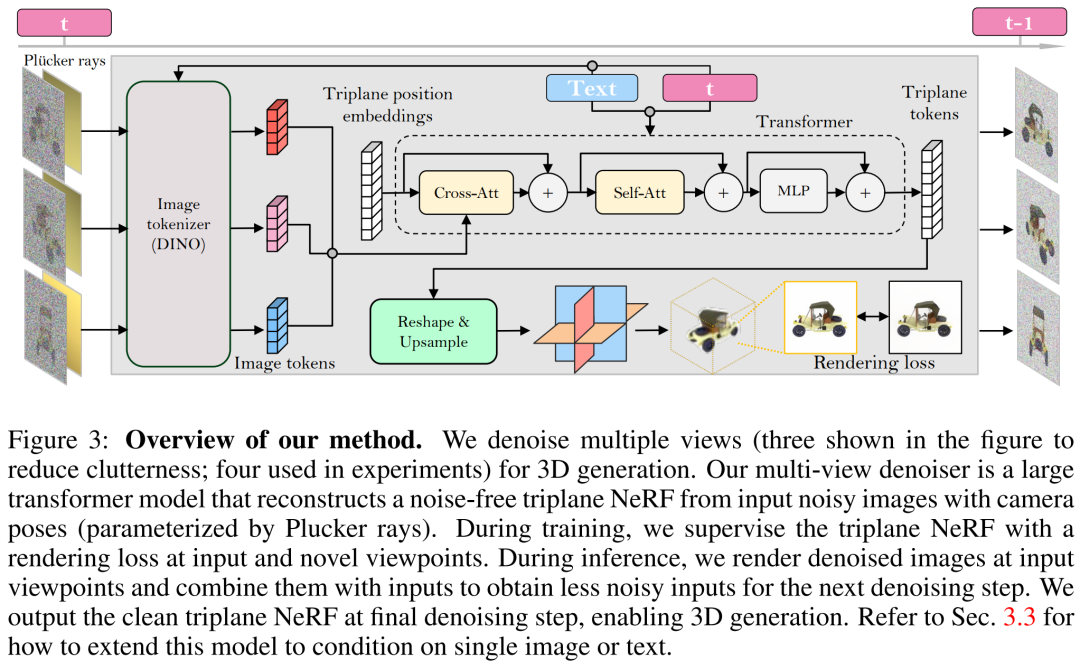
Time adjustment. Compared with the CNN-based DDPM (Denoising Diffusion Probabilistic Model), our transformer-based model requires a different temporal adjustment design.
When training the model in this article, the researchers pointed out that on highly diverse camera intrinsic and extrinsic parameter data sets (such as MVImgNet), it is necessary to effectively design input camera adjustments to help The model understands the camera and performs 3D reasoning
When rewriting the content, the language of the original text needs to be converted into Chinese without changing the meaning of the original text
The above method enables the model proposed by the researcher to serve as an unconditional generative model. They describe how to use conditional denoisers 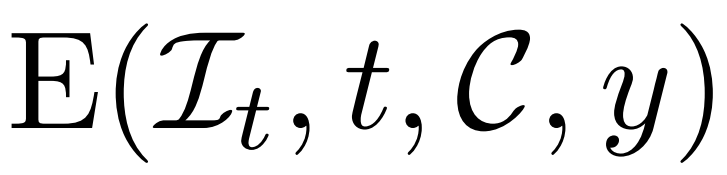 to model conditional probability distributions, where y represents text or images, to achieve controlled 3D generation.
to model conditional probability distributions, where y represents text or images, to achieve controlled 3D generation.
In terms of image conditioning, the researchers proposed a simple and effective strategy that does not require modifications to the model's architecture
Text conditioning . To add text conditioning to their model, the researchers adopted a strategy similar to Stable Diffusion. They use a CLIP text encoder to generate text embeddings and inject them into a denoiser using cross-attention.
The content that needs to be rewritten is: training and inference
Training. During the training phase, we sample time steps t uniformly within the range [1, T] and add noise according to cosine scheduling. They sample the input image using random camera poses and also randomly sample additional new viewpoints to supervise the rendering for better quality.
The researcher uses the conditional signal y to minimize the training objective
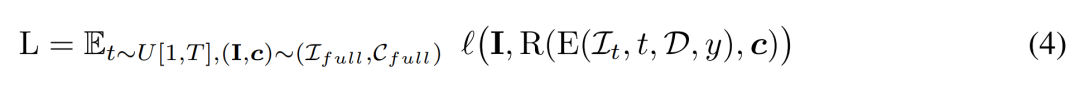
reasoning. During the inference phase, we selected viewpoints that evenly surrounded the object in a circle to ensure good coverage of the resulting 3D assets. They fixed the camera market angle at 50 degrees for the four views.
In the experiment, the researchers used the AdamW optimizer to train their model with an initial learning rate of 4e^- 4. They used 3K steps of warm-up and cosine decay for this learning rate, used 256×256 input images to train the denoising model, and used 128×128 cropped images for supervised rendering
The content about the data set needs to be rewritten as: the researcher's model only needs to use multi-view pose images for training. Therefore, they used rendered multi-view images of approximately 730k objects from the Objaverse dataset. For each object, they performed 32 image renderings at random viewpoints with a fixed 50-degree FOV according to the LRM settings, and performed uniform illumination
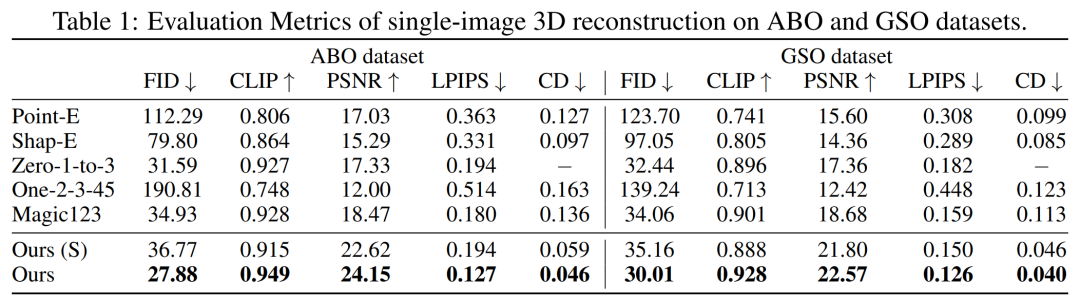
First, single image reconstruction . The researchers compared their image-conditioning model with previous methods such as Point-E, Shap-E, Zero-1-to-3, and Magic123 on a single image reconstruction task. They used metrics such as PSNR, LPIPS, CLIP similarity score, and FID to evaluate the new view rendering quality of all methods.
The quantitative results on the GSO and ABO test sets are shown in Table 1 below. Our model outperforms all baseline methods and achieves new SOTA for all metrics on both datasets
The results generated by the model in this article have higher quality than the baseline in terms of geometry and appearance details. This result can be qualitatively demonstrated through Figure 4
DMV3D is a 2D image-based In contrast, it eliminates the need to optimize each asset individually while eliminating multi-view diffusion noise and directly generating 3D NeRF models. Overall, DMV3D is able to generate 3D images quickly and achieve the best single-image 3D reconstruction results

Rewritten As follows: The researchers also evaluated DMV3D on text-based 3D generation results. The researchers compared DMV3D with Shap-E and Point-E, which also support fast reasoning across all categories. The researchers let the three models generate based on 50 text prompts from Shap-E, and used the CLIP accuracy and average accuracy of two different ViT models to evaluate the generation results, as shown in Table 2
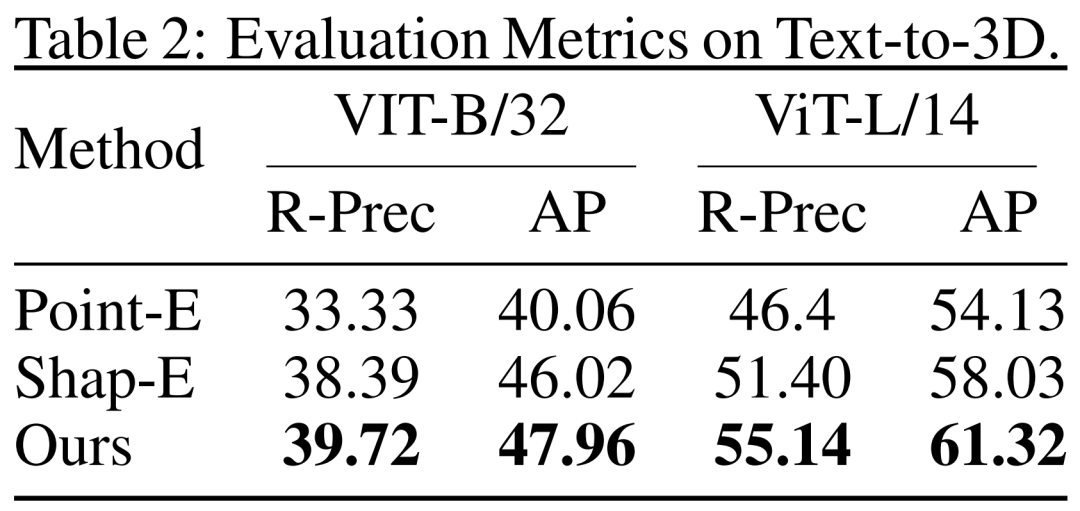
According to the data in the table, DMV3D shows the best accuracy. As can be seen from the qualitative results in Figure 5, compared to the results generated by other models, the graphics generated by DMV3D clearly contain richer geometric and appearance details, and the results are more realistic

What needs to be rewritten is: other results
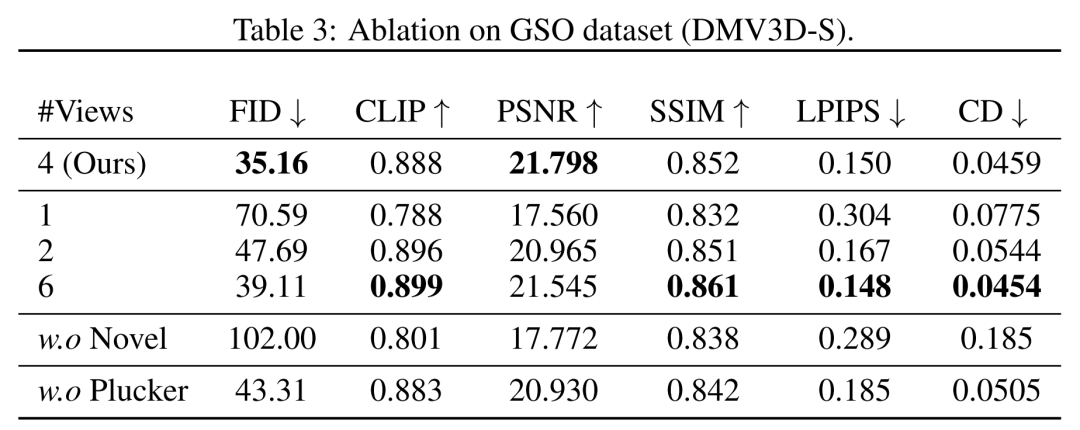
In terms of perspective, the researcher shows in Table 3 and Figure 8 Quantitative and qualitative comparison of models trained with different numbers of input views (1, 2, 4, 6).

#In terms of multi-instance generation, similar to other diffusion models, the model proposed in this article can generate a variety of examples based on random input, as shown in Figure 1, which demonstrates the generalization of the results generated by the model.

DMV3D has extensive flexibility and versatility in applications, and has strong development potential in the field of 3D generation applications. As shown in Figures 1 and 2, our method can lift any object in a 2D photo to a 3D dimension in image editing applications through methods such as segmentation (such as SAM)
Please read the original paper for more technical details and experimental results

The above is the detailed content of Adobe's new technology: It only takes 30 seconds to generate 3D images with A100, making text and images move. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



