
 Technology peripherals
AI
Through 8 billion parameters OtterHD, the Chinese team of Nanyang Polytechnic brings you the experience of counting camels in 'Along the River During Qingming Festival'
Technology peripherals
AI
Through 8 billion parameters OtterHD, the Chinese team of Nanyang Polytechnic brings you the experience of counting camels in 'Along the River During Qingming Festival'
Through 8 billion parameters OtterHD, the Chinese team of Nanyang Polytechnic brings you the experience of counting camels in 'Along the River During Qingming Festival'

Want to know how many camels are in "Along the River During Qingming Festival"? Let’s take a look at this multi-modal model that supports UHD input.
Recently, a Chinese team from Nanyang Polytechnic built the 8 billion parameter multi-modal large model OtterHD based on Fuyu-8B.

Paper address: https://arxiv.org/abs/2311.04219
with restrictions Unlike traditional models of fixed-size visual encoders, OtterHD-8B has the ability to handle flexible input sizes, ensuring its versatility under various inference needs.
At the same time, the team also proposed a new benchmark test MagnifierBench, which can carefully evaluate LLM's ability to distinguish the minute details and spatial relationships of objects in large-size images.
Experimental results show that the performance of OtterHD-8B is significantly better than similar models in directly processing high-resolution inputs
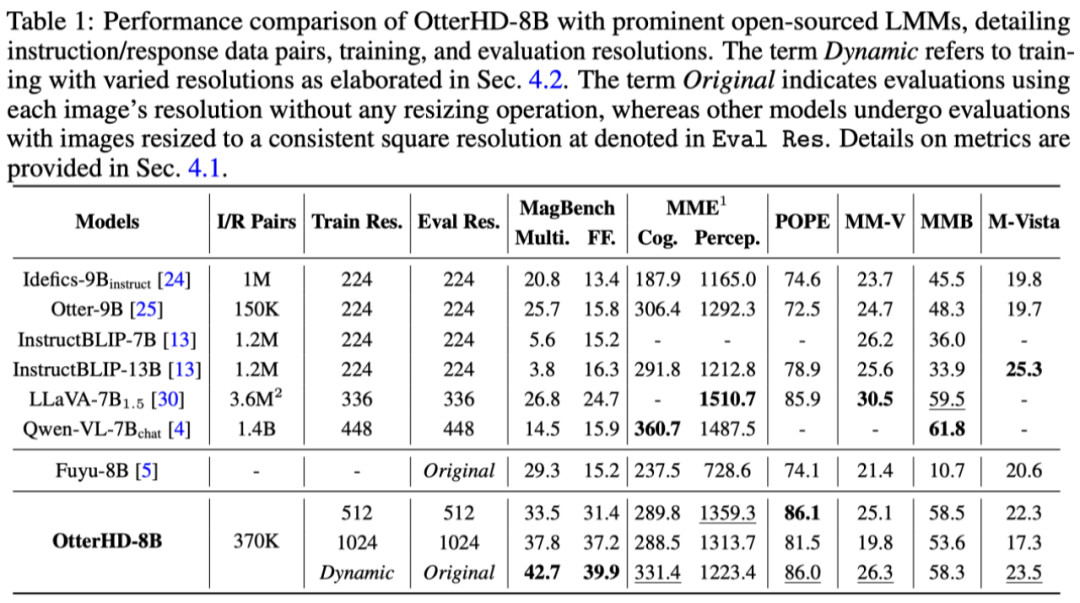
Effect Demonstration
As shown below, we ask how many camels are in the Qingming River Scene (part). The image input reaches 2446x1766 pixels, and the model can also answer the question successfully. .
Faced with the apple-counting problem that GPT4-V once confused, the model successfully calculated that it contained 11 apples

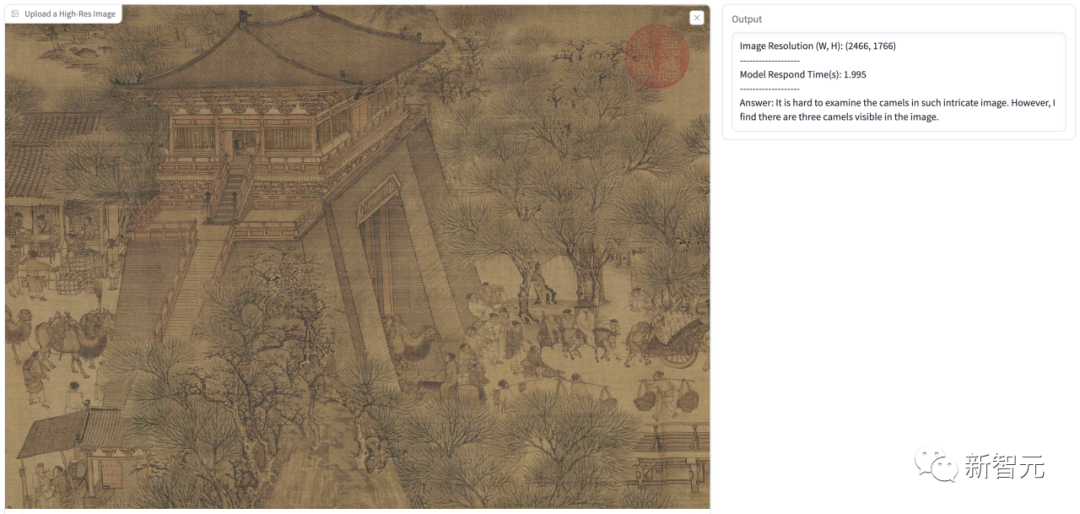
In addition to the high-definition input example shown in the paper, we also conducted some tests. In the figure below, we let the model assume that the user It's a PhD from Cambridge University, explaining what this picture means.
The model's answer accurately identified the Black Hole and White Hole information in the picture, and identified it as a tunnel-like structure, and then gave a detailed explanation. .
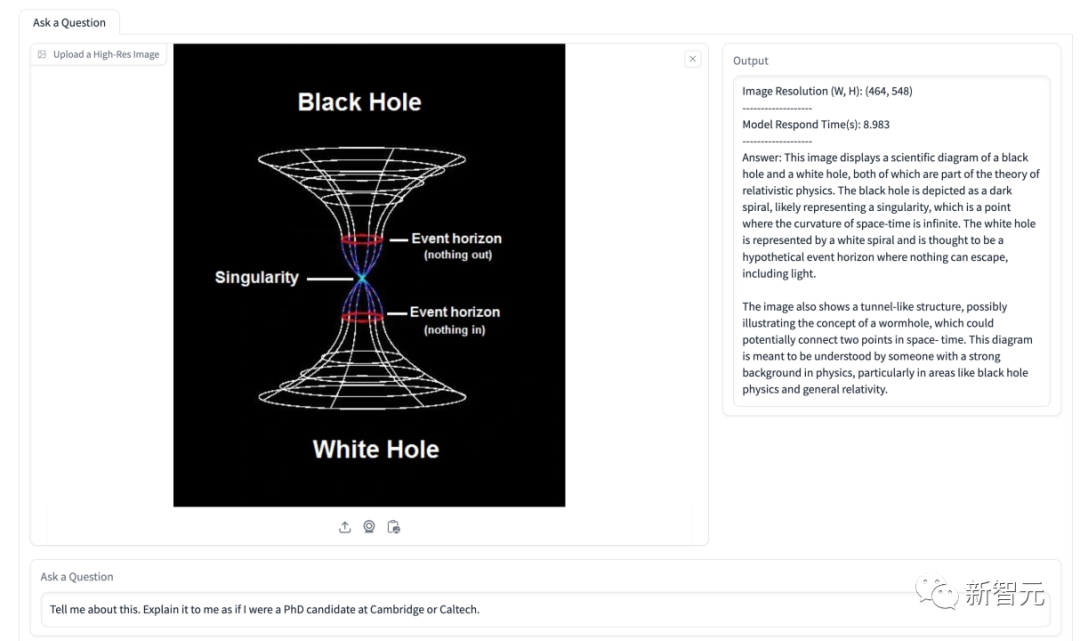
In the diagram below, the model is asked to explain the situation regarding energy share. The model successfully identifies several energy types shown in the figure and accurately presents their proportions over time
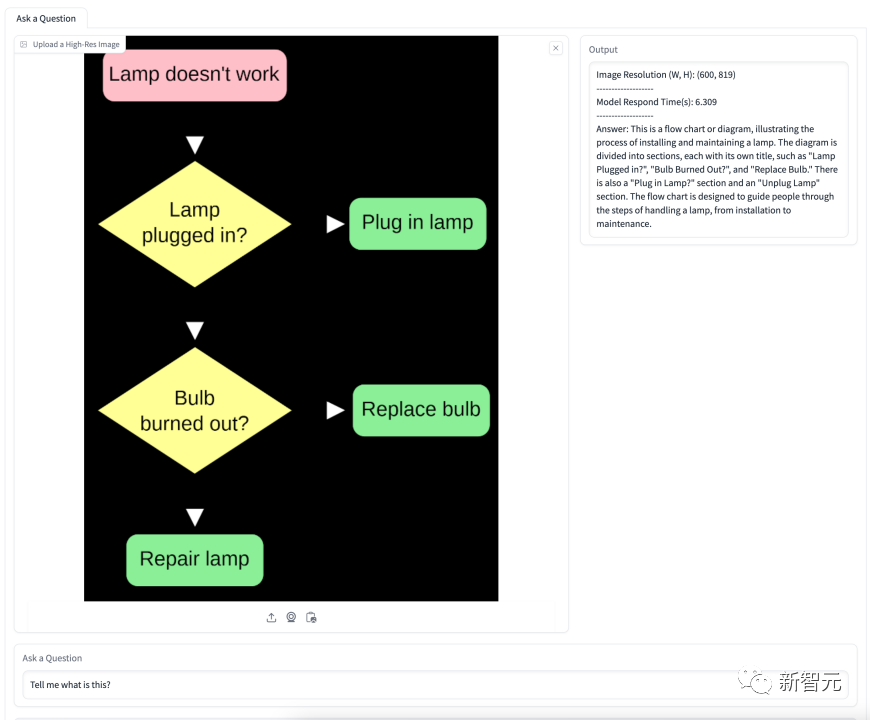
Figure is about the flow chart of changing a light bulb. The model accurately understands the meaning of the flow chart and gives step-by-step detailed guidance.
8 billion parameter command fine-tuning OtterHD-8B
Fuyu-8B’s OtterHD-8B is the first An open source instruction to fine-tune large language models trained on inputs up to 1024×1024, which is noteworthy
Additionally, during inference, it can be further extended to larger Resolution (such as 1440×1440).
Training details
In preliminary experiments, the team found that Fuyu was good at training certain The benchmark performed poorly in responding to specific instructions, which resulted in very weak model performance on MME and MMBench
To address these issues, the team performed instruction fine-tuning, based on 370K Mixed data adjusts the Fuyu model and refers to the similar instruction template of LLaVA-1.5 to standardize the format of model answers
In the training phase, all data sets are organized into instructions/responses Yes, summarized into a unified dataloader and uniformly sampled to ensure representative integrity.
In order to improve the performance of the modeling code, the team adopted FlashAttention-2 and the operator fusion technology in the FlashAttention resource library
With the help of Fuyu’s simplified architecture , as shown in Figure 2, these modifications significantly improved GPU utilization and throughput
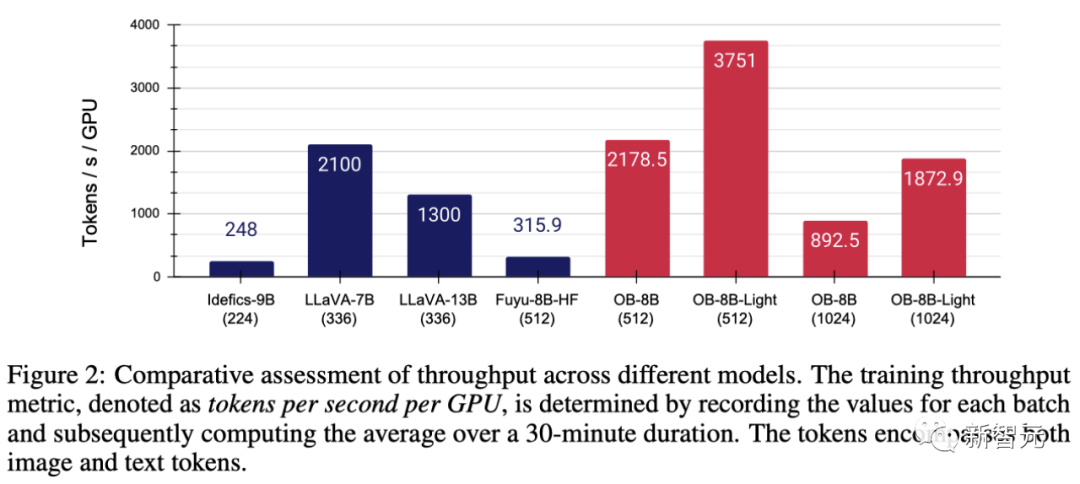
# Specifically, the method proposed by the team can Full parameter training is completed in 3 hours/epoch on an 8×A100 GPU, while it only takes 1 hour per epoch after LoRA fine-tuning.
When training the model using the AdamW optimizer, the batch size is 64, the learning rate is set to 1×10^-5, and the weight decay is 0.1.
Ultra-fine evaluation benchmark MagnifierBench
The human visual system can naturally perceive the details of objects within the field of view, but the benchmark currently used to test LMM There is no particular focus on assessing competencies in this area.
With the advent of the Fuyu and OtterHD models, we are extending the resolution of the input image to a larger range for the first time.
To this end, the team created a new test benchmark MagnifierBench covering 166 images and a total of 283 sets of questions based on the Panoptic Scene Graph Generation (PVSG) data set.
The PVSG dataset consists of video data, which contains a large number of messy and complex scenes, especially first-person housework videos.
During the annotation phase, the team carefully examined every question-answer pair in the dataset, eliminating those that involved large objects, or that were easily answered with common sense knowledge. For example, most remote controls are black, which is easy to guess, but colors such as red and yellow are not included in this list.
As shown in Figure 3, the types of questions designed by MagnifierBench include recognition, number, color-related questions, etc. An important criterion for this dataset is that the questions must be complex enough that even the annotator must be in full-screen mode or even zoom in on the image to answer accurately

Compared with short answers, LMM is better at generating extended answers in conversational environments.
-Multiple choice questions
The problem faced by this model is that there are multiple options to choose from. To guide the model to choose a letter (such as A, B, C) as the answer, the team preceded the question with a letter from a given choice as a prompt. In this case, only the answer that exactly matches the correct option will be considered the correct answer
- Open question
Multiple options will simplify the task because random guessing has a 25% chance of being correct. Furthermore, this does not reflect real-life scenarios faced by chat assistants, as users typically do not provide predefined options to the model. To eliminate this potential bias, the team also asked the model questions in a straightforward, open-ended manner with no prompt options.
Experimental analysis
The research results show that although many models achieve high scores on established benchmarks such as MME and POPE, they fail to perform well on MagnifierBench The performance is often unsatisfactory. The OtterHD-8B, on the other hand, performed well on MagnifierBench.
In order to further explore the effect of increasing the resolution and test the generalization ability of OtterHD at different, possibly higher resolutions, the team conducted experiments on Otter8B using fixed or dynamic resolutions. The x-axis shows that as the resolution increases, more image tokens are sent to the language decoder, thus providing more image details.
Experimental results show that as the resolution increases, the performance of MagnifierBench also improves accordingly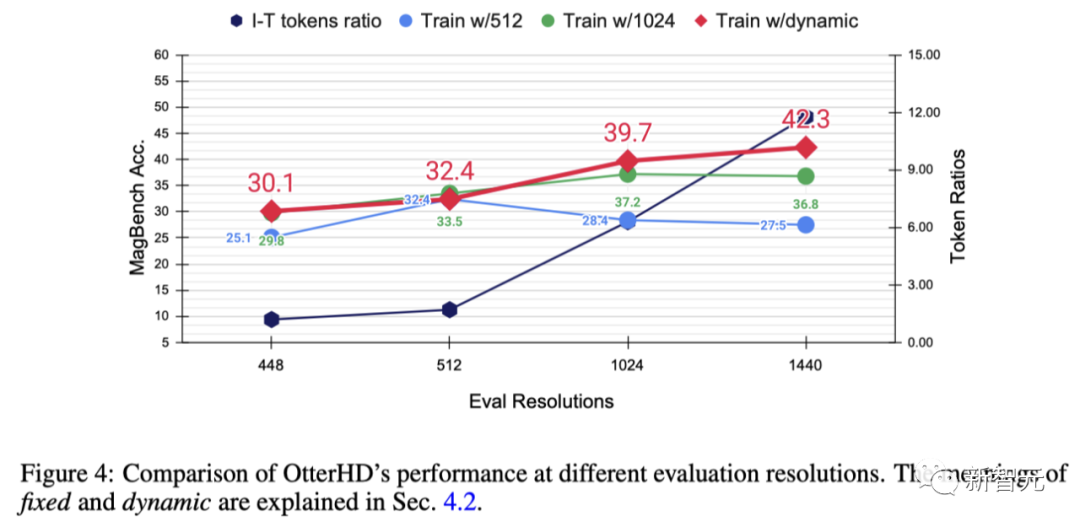
As the resolution increases, the ratio of images to text gradually increases. This is because the average number of text tokens remains the same. This change highlights the importance of LMM resolution, especially for tasks that require complex visual association.

Furthermore, the performance difference between fixed and dynamic training methods highlights the advantages of dynamic resizing, especially in preventing overfitting at specific resolutions.
The dynamic strategy also has the advantage of allowing the model to adapt to higher resolutions (1440) even if it has not been seen during training
Some comparisons




##Conclusion
Based on the innovative architecture of Fuyu-8B, the research team proposed the OtterHD-8B model, It can effectively handle images of various resolutions and get rid of the limitations of fixed resolution input in most LMMs
At the same time, OtterHD-8B is very good at processing high-resolution images. Excellent performance
This becomes especially evident in the new MagnifierBench benchmark. The purpose of this benchmark is to evaluate the LMM's ability to recognize details in complex scenes, highlighting the importance of more flexible support for different resolutions
The above is the detailed content of Through 8 billion parameters OtterHD, the Chinese team of Nanyang Polytechnic brings you the experience of counting camels in 'Along the River During Qingming Festival'. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1664
1664
 14
1422
52
1316
25
1268
29
1240
24
14
1422
52
1316
25
1268
29
1240
24

 Open source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!
Apr 03, 2024 pm 12:04 PM
Open source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!
Apr 03, 2024 pm 12:04 PM
0.What does this article do? We propose DepthFM: a versatile and fast state-of-the-art generative monocular depth estimation model. In addition to traditional depth estimation tasks, DepthFM also demonstrates state-of-the-art capabilities in downstream tasks such as depth inpainting. DepthFM is efficient and can synthesize depth maps within a few inference steps. Let’s read about this work together ~ 1. Paper information title: DepthFM: FastMonocularDepthEstimationwithFlowMatching Author: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Use ddrescue to recover data on Linux
Mar 20, 2024 pm 01:37 PM
Use ddrescue to recover data on Linux
Mar 20, 2024 pm 01:37 PM
DDREASE is a tool for recovering data from file or block devices such as hard drives, SSDs, RAM disks, CDs, DVDs and USB storage devices. It copies data from one block device to another, leaving corrupted data blocks behind and moving only good data blocks. ddreasue is a powerful recovery tool that is fully automated as it does not require any interference during recovery operations. Additionally, thanks to the ddasue map file, it can be stopped and resumed at any time. Other key features of DDREASE are as follows: It does not overwrite recovered data but fills the gaps in case of iterative recovery. However, it can be truncated if the tool is instructed to do so explicitly. Recover data from multiple files or blocks to a single
 Google is ecstatic: JAX performance surpasses Pytorch and TensorFlow! It may become the fastest choice for GPU inference training
Apr 01, 2024 pm 07:46 PM
Google is ecstatic: JAX performance surpasses Pytorch and TensorFlow! It may become the fastest choice for GPU inference training
Apr 01, 2024 pm 07:46 PM
The performance of JAX, promoted by Google, has surpassed that of Pytorch and TensorFlow in recent benchmark tests, ranking first in 7 indicators. And the test was not done on the TPU with the best JAX performance. Although among developers, Pytorch is still more popular than Tensorflow. But in the future, perhaps more large models will be trained and run based on the JAX platform. Models Recently, the Keras team benchmarked three backends (TensorFlow, JAX, PyTorch) with the native PyTorch implementation and Keras2 with TensorFlow. First, they select a set of mainstream
 Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas officially enters the era of electric robots! Yesterday, the hydraulic Atlas just "tearfully" withdrew from the stage of history. Today, Boston Dynamics announced that the electric Atlas is on the job. It seems that in the field of commercial humanoid robots, Boston Dynamics is determined to compete with Tesla. After the new video was released, it had already been viewed by more than one million people in just ten hours. The old people leave and new roles appear. This is a historical necessity. There is no doubt that this year is the explosive year of humanoid robots. Netizens commented: The advancement of robots has made this year's opening ceremony look like a human, and the degree of freedom is far greater than that of humans. But is this really not a horror movie? At the beginning of the video, Atlas is lying calmly on the ground, seemingly on his back. What follows is jaw-dropping
 Slow Cellular Data Internet Speeds on iPhone: Fixes
May 03, 2024 pm 09:01 PM
Slow Cellular Data Internet Speeds on iPhone: Fixes
May 03, 2024 pm 09:01 PM
Facing lag, slow mobile data connection on iPhone? Typically, the strength of cellular internet on your phone depends on several factors such as region, cellular network type, roaming type, etc. There are some things you can do to get a faster, more reliable cellular Internet connection. Fix 1 – Force Restart iPhone Sometimes, force restarting your device just resets a lot of things, including the cellular connection. Step 1 – Just press the volume up key once and release. Next, press the Volume Down key and release it again. Step 2 – The next part of the process is to hold the button on the right side. Let the iPhone finish restarting. Enable cellular data and check network speed. Check again Fix 2 – Change data mode While 5G offers better network speeds, it works better when the signal is weaker
 Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
The latest video of Tesla's robot Optimus is released, and it can already work in the factory. At normal speed, it sorts batteries (Tesla's 4680 batteries) like this: The official also released what it looks like at 20x speed - on a small "workstation", picking and picking and picking: This time it is released One of the highlights of the video is that Optimus completes this work in the factory, completely autonomously, without human intervention throughout the process. And from the perspective of Optimus, it can also pick up and place the crooked battery, focusing on automatic error correction: Regarding Optimus's hand, NVIDIA scientist Jim Fan gave a high evaluation: Optimus's hand is the world's five-fingered robot. One of the most dexterous. Its hands are not only tactile
 Kuaishou version of Sora 'Ke Ling' is open for testing: generates over 120s video, understands physics better, and can accurately model complex movements
Jun 11, 2024 am 09:51 AM
Kuaishou version of Sora 'Ke Ling' is open for testing: generates over 120s video, understands physics better, and can accurately model complex movements
Jun 11, 2024 am 09:51 AM
What? Is Zootopia brought into reality by domestic AI? Exposed together with the video is a new large-scale domestic video generation model called "Keling". Sora uses a similar technical route and combines a number of self-developed technological innovations to produce videos that not only have large and reasonable movements, but also simulate the characteristics of the physical world and have strong conceptual combination capabilities and imagination. According to the data, Keling supports the generation of ultra-long videos of up to 2 minutes at 30fps, with resolutions up to 1080p, and supports multiple aspect ratios. Another important point is that Keling is not a demo or video result demonstration released by the laboratory, but a product-level application launched by Kuaishou, a leading player in the short video field. Moreover, the main focus is to be pragmatic, not to write blank checks, and to go online as soon as it is released. The large model of Ke Ling is already available in Kuaiying.
 Alibaba 7B multi-modal document understanding large model wins new SOTA
Apr 02, 2024 am 11:31 AM
Alibaba 7B multi-modal document understanding large model wins new SOTA
Apr 02, 2024 am 11:31 AM
New SOTA for multimodal document understanding capabilities! Alibaba's mPLUG team released the latest open source work mPLUG-DocOwl1.5, which proposed a series of solutions to address the four major challenges of high-resolution image text recognition, general document structure understanding, instruction following, and introduction of external knowledge. Without further ado, let’s look at the effects first. One-click recognition and conversion of charts with complex structures into Markdown format: Charts of different styles are available: More detailed text recognition and positioning can also be easily handled: Detailed explanations of document understanding can also be given: You know, "Document Understanding" is currently An important scenario for the implementation of large language models. There are many products on the market to assist document reading. Some of them mainly use OCR systems for text recognition and cooperate with LLM for text processing.
