

Improve large model inference performance by 40x using toolkit

Intel® What is Extension for Transformer?
Intel® Extension for Transformers[1] is an innovative toolkit launched by Intel that can be based on the Intel® architecture platform, especially the fourth generation Intel® Xeon® Scalable processors (codenamed Sapphire Rapids[2], SPR) significantly accelerate Transformer-based Large Language Model (LLM). Its main features include:
- Provide users with a seamless model compression experience by extending the Hugging Face transformers API[3] and leveraging Intel® Neural Compressor[4];
- Provides LLM inference runtime using low-bit quantization kernel (NeurIPS 2023: Efficient LLM inference on CPU [5]), supporting Falcon, LLaMA, MPT, Llama2, BLOOM, OPT, ChatGLM2, GPT-J- Common LLMs such as 6B, Baichuan-13B-Base, Baichuan2-13B-Base, Qwen-7B, Qwen-14B and Dolly-v2-3B[6];
- Advanced compressed sensing runtime[7] (NeurIPS 2022: Fast Distillation on CPU and QuaLA-MiniLM: Quantization Length Adaptive MiniLM; NeurIPS 2021: Prune once, forget it: sparse/prune pre-trained language models).
This article will focus on the LLM inference runtime (referred to as "LLM runtime") , and how to use the Transformer-based API to run on Intel® Xeon ® Achieve more efficient LLM reasoning on scalable processors and how to deal with the application problems of LLM in chat scenarios.
LLM RuntimeIntel® The LLM Runtime[8] provided by Extension for Transformers is a lightweight but efficient LLM inference runtime , which is inspired by GGML[9] and is compatible with llama.cpp[10]. It has the following characteristics:
- The kernel has been built-in for
- Intel® Xeon® CPU Multiple AI acceleration technologies (such as AMX, VNNI) and AVX512F and AVX2 instruction sets have been optimized; can provide more quantization options, such as: different granularity (by channel or by group), different groups Size (such as: 32/128);
- has better KV cache access and memory allocation strategy;
- has tensor parallelization function, which can help distribution in multi-channel systems reasoning.
from transformers import AutoTokenizer, TextStreamerfrom intel_extension_for_transformers.transformers import AutoModelForCausalLMmodel_name = "Intel/neural-chat-7b-v3-1” prompt = "Once upon a time, there existed a little girl,"tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)inputs = tokenizer(prompt, return_tensors="pt").input_idsstreamer = TextStreamer(tokenizer)model = AutoModelForCausalLM.from_pretrained(model_name, load_in_4bit=True)outputs = model.generate(inputs, streamer=streamer, max_new_tokens=300)
from transformers import AutoTokenizer, TextStreamerfrom intel_extension_for_transformers.transformers import AutoModelForCausalLM, WeightOnlyQuantConfigmodel_name = "Intel/neural-chat-7b-v3-1” prompt = "Once upon a time, there existed a little girl,"woq_config = WeightOnlyQuantConfig(compute_dtype="int8", weight_dtype="int4")tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)inputs = tokenizer(prompt, return_tensors="pt").input_idsstreamer = TextStreamer(tokenizer)model = AutoModelForCausalLM.from_pretrained(model_name,quantization_cnotallow=woq_config)outputs = model.generate(inputs, streamer=streamer, max_new_tokens=300)
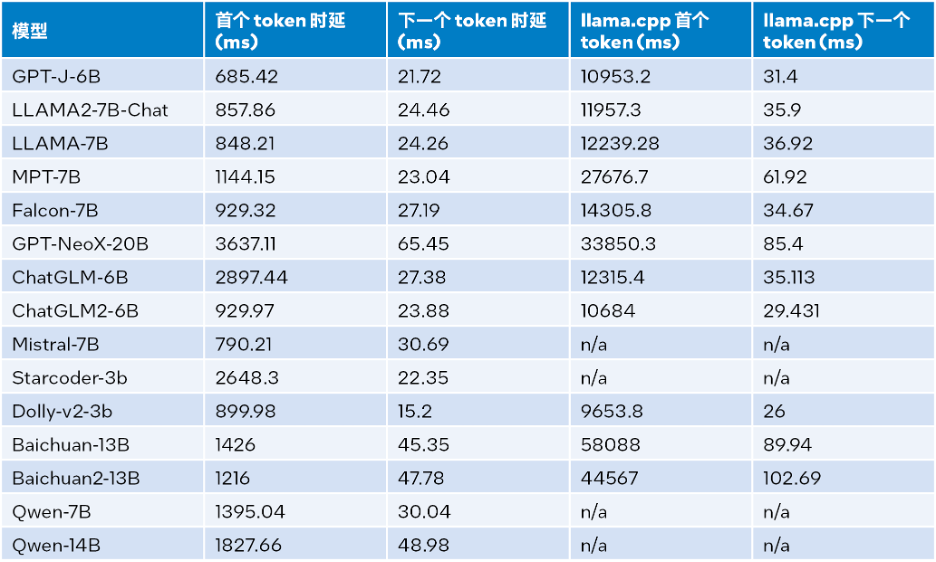
Intel® 256 GB total memory (16 x 16 GB DDR5 4800 MT/s [4800 MT/s]), BIOS 3A14.TEL2P1, microcode 0x2b0001b0, CentOS Stream 8. The results of the inference performance test are shown in the table below, where the input size is 32, the output size is 32, and the beam is 1
##△ Table 1. Comparison of inference performance between LLM Runtime and llama.cpp (input size = 32, output size = 32, beam = 1) 
Inference performance when the input size is 1024, the output size is 32, and the beam is 1 The test results are detailed in the following table:
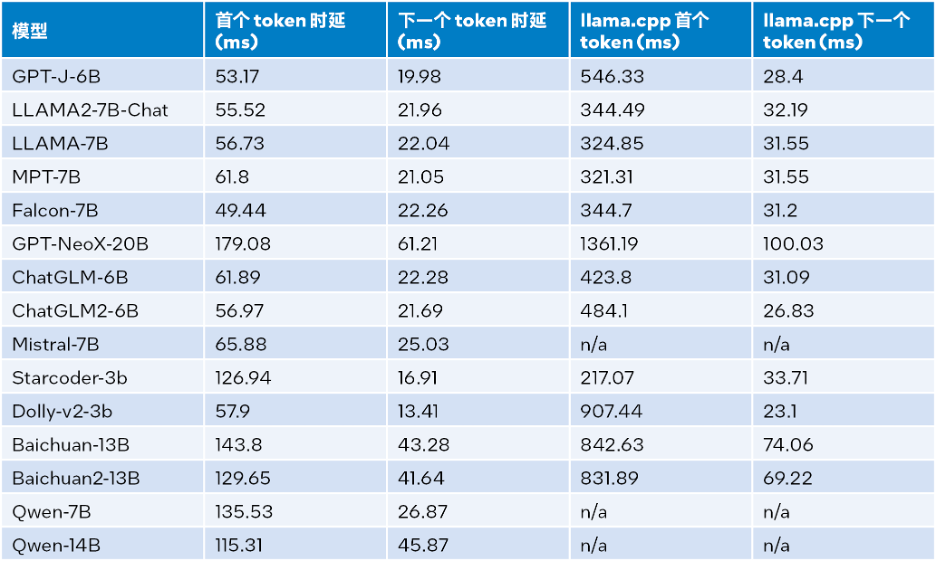
△Table 2. LLM Runtime and llama.cpp inference performance comparison (input size = 1024, output size=32,beam=1)
According to Table 2 above: Compared with llama.cpp also running on the fourth generation Intel® Xeon® scalable processor, whether it is the first token or the next token, LLM Runtime can significantly reduce latency, and the inference speed of the first token and the next token is increased by up to 40 times[a] (Baichuan-13B, input is 1024) and 2.68 times [ b] (MPT-7B, input is 1024). The test of llama.cpp uses the default code base [10].
Combining the test results in Table 1 and Table 2, we can get: Compared with llama.cpp also running on the fourth generation Intel® Xeon® scalable processor, LLM Runtime can significantly improve the overall performance of many common LLMs: when the input size is 1024, it achieves an improvement of 3.58 to 21.5 times; when the input size is 32, it achieves an improvement of 1.76 to 3.43 times[c] .
Accuracy Test
Intel® Extension for Transformers available Intel® SignRound[11], RTN and GPTQ[12] in Neural Compressor ] and other quantification methods, and verified the INT4 inference accuracy using lambada_openai, piqa, winogrande and hellaswag data sets. The table below compares test result averages to FP32 accuracy.
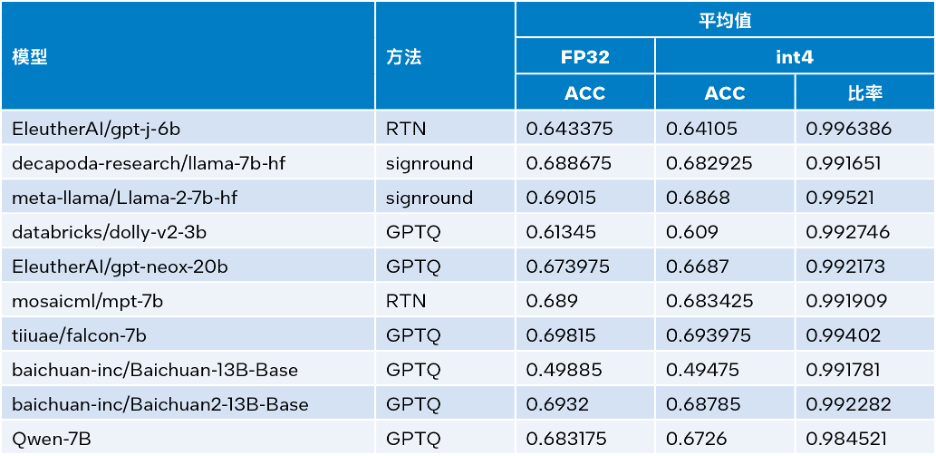
△Table 3. Accuracy comparison between INT4 and FP32
As can be seen from Table 3 above, the INT4 inference performed by multiple models based on LLM Runtime is accurate The sexual loss is so small that it can almost be ignored. We verified many models, but only some are listed here due to space limitations. If you would like more information or details, please visit this link: https://medium.com/@NeuralCompressor/llm-performance-of-intel-extension-for-transformers-f7d061556176.
More advanced functions: meet the application needs of LLM in more scenarios
At the same time, LLM Runtime[8] also has the tensor parallelization function of dual-channel CPU, which is the first to have such a function one of the products. In the future, dual nodes will be further supported.
However, the advantage of LLM Runtime is not only its better performance and accuracy. We have also invested a lot of effort to enhance its functions in chat application scenarios and solve the problems that LLM may encounter in chat scenarios. The following application problems are encountered:
- Dialogue is not only related to LLM reasoning, but dialogue history is also very useful.
- Limited output length: LLM model pre-training is mainly based on limited sequence length. Therefore, its accuracy decreases when the sequence length exceeds the attention window size used during pre-training.
- Inefficiency: During the decoding stage, Transformer-based LLM will store the key-value status (KV) of all previously generated tokens, resulting in excessive memory usage and increased decoding latency.
Regarding the first issue, LLM Runtime's dialogue function is solved by incorporating more dialogue history data and generating more output, which llama.cpp is not yet well equipped to deal with. .
Regarding the second and third questions, we integrated streaming LLM (Steaming LLM) into Intel® Extension for Transformers, which can significantly optimize memory usage and reduce inference time extension.
Streaming LLM
Different from the traditional KV caching algorithm, our method combines Attention Sink (4 initial tokens) to improve attention calculation Stability, and retaining the latest token with the help of rolling KV cache, which is crucial for language modeling. The design is highly flexible and can be seamlessly integrated into autoregressive language models capable of utilizing rotational position encoding RoPE and relative position encoding ALiBi.
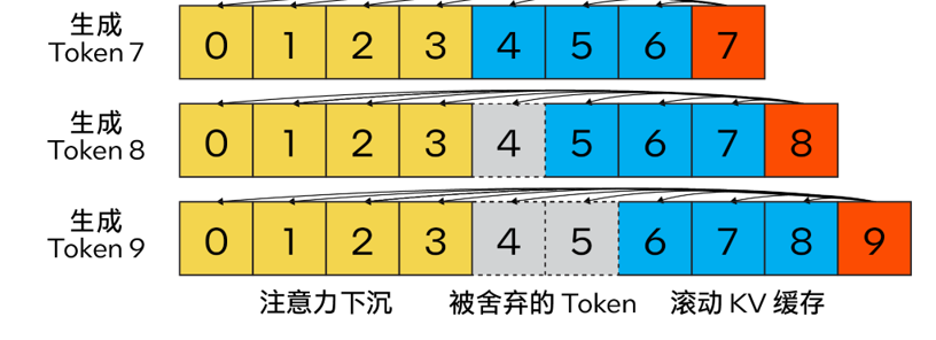
The content that needs to be rewritten is: △ Figure 2. KV cache of Steam LLM using attention sinking to implement efficient streaming language model (Picture source: [13] )
Moreover, unlike llama.cpp, this optimization plan also adds new parameters such as "n_keep" and "n_discard" to enhance the Streaming LLM strategy. Users can use the "n_keep" parameter to specify the number of tokens to keep in the KV cache, and the "n_discard" parameter to determine the number to discard among the generated tokens. In order to better balance performance and accuracy, the system discards half of the latest token number in the KV cache by default
At the same time, to further improve performance, we have also added Streaming LLM to the MHA fusion mode. If the model uses rotational position encoding (RoPE) to implement position embedding, then you only need to apply a "shift operation" to the existing K-Cache to avoid performing operations on previously generated tokens that have not been discarded. Repeated calculation. This method not only takes full advantage of the full context size when generating long text, but also does not incur additional overhead until the KV cache context is completely filled.
“shift operation”依赖于旋转的交换性和关联性,或复数乘法。例如:如果某个token的K-张量初始放置位置为m并且旋转了m×θi for i ∈ [0,d/2),那么当它需要移动到m-1这个位置时,则可以旋转回到(-1)×θi for i ∈ [0,d/2)。这正是每次舍弃n_discard个token的缓存时发生的事情,而此时剩余的每个token都需要“移动”n_discard个位置。下图以“n_keep=4、n_ctx=16、n_discard=1”为例,展示了这一过程。

△图3.Ring-Buffer KV-Cache和Shift-RoPE工作原理
需要注意的是:融合注意力层无需了解上述过程。如果对K-cache和V-cache进行相同的洗牌,注意力层会输出几乎相同的结果(可能存在因浮点误差导致的微小差异)。
您可以使用下面的代码来启动Streaming LLM:
from transformers import AutoTokenizer, TextStreamer from intel_extension_for_transformers.transformers import AutoModelForCausalLM, WeightOnlyQuantConfig model_name = "Intel/neural-chat-7b-v1-1" # Hugging Face model_id or local model woq_config = WeightOnlyQuantConfig(compute_dtype="int8", weight_dtype="int4") prompt = "Once upon a time, a little girl"tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True) inputs = tokenizer(prompt, return_tensors="pt").input_ids streamer = TextStreamer(tokenizer)model = AutoModelForCausalLM.from_pretrained(model_name, quantization_cnotallow=woq_config, trust_remote_code=True) # Recommend n_keep=4 to do attention sinks (four initial tokens) and n_discard=-1 to drop half rencetly tokens when meet length threshold outputs = model.generate(inputs, streamer=streamer, max_new_tokens=300, ctx_size=100, n_keep=4, n_discard=-1)
结论与展望
本文基于上述实践经验,提供了一个在英特尔® 至强® 可扩展处理器上实现高效的低位(INT4)LLM推理的解决方案,并且在一系列常见LLM上验证了其通用性以及展现了其相对于其他基于CPU的开源解决方案的性能优势。未来,我们还将进一步提升CPU张量库和跨节点并行性能。
欢迎您试用英特尔® Extension for Transformers[1],并在英特尔® 平台上更高效地运行LLM推理!也欢迎您向代码仓库(repository)提交修改请求 (pull request)、问题或疑问。期待您的反馈!
特别致谢
在此致谢为此篇文章做出贡献的英特尔公司人工智能资深经理张瀚文及工程师许震中、余振滔、刘振卫、丁艺、王哲、刘宇澄。
[a]根据表2 Baichuan-13B的首个token测试结果计算而得。
[b]根据表2 MPT-7B的下一个token测试结果计算而得。
[c]当输入大小为1024时,整体性能=首个token性能+1023下一个token性能;当输入大小为32时,整体性能=首个token性能+31下一个token性能。
The above is the detailed content of Improve large model inference performance by 40x using toolkit. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 Use ddrescue to recover data on Linux
Mar 20, 2024 pm 01:37 PM
Use ddrescue to recover data on Linux
Mar 20, 2024 pm 01:37 PM
DDREASE is a tool for recovering data from file or block devices such as hard drives, SSDs, RAM disks, CDs, DVDs and USB storage devices. It copies data from one block device to another, leaving corrupted data blocks behind and moving only good data blocks. ddreasue is a powerful recovery tool that is fully automated as it does not require any interference during recovery operations. Additionally, thanks to the ddasue map file, it can be stopped and resumed at any time. Other key features of DDREASE are as follows: It does not overwrite recovered data but fills the gaps in case of iterative recovery. However, it can be truncated if the tool is instructed to do so explicitly. Recover data from multiple files or blocks to a single
 Open source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!
Apr 03, 2024 pm 12:04 PM
Open source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!
Apr 03, 2024 pm 12:04 PM
0.What does this article do? We propose DepthFM: a versatile and fast state-of-the-art generative monocular depth estimation model. In addition to traditional depth estimation tasks, DepthFM also demonstrates state-of-the-art capabilities in downstream tasks such as depth inpainting. DepthFM is efficient and can synthesize depth maps within a few inference steps. Let’s read about this work together ~ 1. Paper information title: DepthFM: FastMonocularDepthEstimationwithFlowMatching Author: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Google is ecstatic: JAX performance surpasses Pytorch and TensorFlow! It may become the fastest choice for GPU inference training
Apr 01, 2024 pm 07:46 PM
Google is ecstatic: JAX performance surpasses Pytorch and TensorFlow! It may become the fastest choice for GPU inference training
Apr 01, 2024 pm 07:46 PM
The performance of JAX, promoted by Google, has surpassed that of Pytorch and TensorFlow in recent benchmark tests, ranking first in 7 indicators. And the test was not done on the TPU with the best JAX performance. Although among developers, Pytorch is still more popular than Tensorflow. But in the future, perhaps more large models will be trained and run based on the JAX platform. Models Recently, the Keras team benchmarked three backends (TensorFlow, JAX, PyTorch) with the native PyTorch implementation and Keras2 with TensorFlow. First, they select a set of mainstream
 Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Hello, electric Atlas! Boston Dynamics robot comes back to life, 180-degree weird moves scare Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas officially enters the era of electric robots! Yesterday, the hydraulic Atlas just "tearfully" withdrew from the stage of history. Today, Boston Dynamics announced that the electric Atlas is on the job. It seems that in the field of commercial humanoid robots, Boston Dynamics is determined to compete with Tesla. After the new video was released, it had already been viewed by more than one million people in just ten hours. The old people leave and new roles appear. This is a historical necessity. There is no doubt that this year is the explosive year of humanoid robots. Netizens commented: The advancement of robots has made this year's opening ceremony look like a human, and the degree of freedom is far greater than that of humans. But is this really not a horror movie? At the beginning of the video, Atlas is lying calmly on the ground, seemingly on his back. What follows is jaw-dropping
 Slow Cellular Data Internet Speeds on iPhone: Fixes
May 03, 2024 pm 09:01 PM
Slow Cellular Data Internet Speeds on iPhone: Fixes
May 03, 2024 pm 09:01 PM
Facing lag, slow mobile data connection on iPhone? Typically, the strength of cellular internet on your phone depends on several factors such as region, cellular network type, roaming type, etc. There are some things you can do to get a faster, more reliable cellular Internet connection. Fix 1 – Force Restart iPhone Sometimes, force restarting your device just resets a lot of things, including the cellular connection. Step 1 – Just press the volume up key once and release. Next, press the Volume Down key and release it again. Step 2 – The next part of the process is to hold the button on the right side. Let the iPhone finish restarting. Enable cellular data and check network speed. Check again Fix 2 – Change data mode While 5G offers better network speeds, it works better when the signal is weaker
 The vitality of super intelligence awakens! But with the arrival of self-updating AI, mothers no longer have to worry about data bottlenecks
Apr 29, 2024 pm 06:55 PM
The vitality of super intelligence awakens! But with the arrival of self-updating AI, mothers no longer have to worry about data bottlenecks
Apr 29, 2024 pm 06:55 PM
I cry to death. The world is madly building big models. The data on the Internet is not enough. It is not enough at all. The training model looks like "The Hunger Games", and AI researchers around the world are worrying about how to feed these data voracious eaters. This problem is particularly prominent in multi-modal tasks. At a time when nothing could be done, a start-up team from the Department of Renmin University of China used its own new model to become the first in China to make "model-generated data feed itself" a reality. Moreover, it is a two-pronged approach on the understanding side and the generation side. Both sides can generate high-quality, multi-modal new data and provide data feedback to the model itself. What is a model? Awaker 1.0, a large multi-modal model that just appeared on the Zhongguancun Forum. Who is the team? Sophon engine. Founded by Gao Yizhao, a doctoral student at Renmin University’s Hillhouse School of Artificial Intelligence.
 Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
The latest video of Tesla's robot Optimus is released, and it can already work in the factory. At normal speed, it sorts batteries (Tesla's 4680 batteries) like this: The official also released what it looks like at 20x speed - on a small "workstation", picking and picking and picking: This time it is released One of the highlights of the video is that Optimus completes this work in the factory, completely autonomously, without human intervention throughout the process. And from the perspective of Optimus, it can also pick up and place the crooked battery, focusing on automatic error correction: Regarding Optimus's hand, NVIDIA scientist Jim Fan gave a high evaluation: Optimus's hand is the world's five-fingered robot. One of the most dexterous. Its hands are not only tactile
 Kuaishou version of Sora 'Ke Ling' is open for testing: generates over 120s video, understands physics better, and can accurately model complex movements
Jun 11, 2024 am 09:51 AM
Kuaishou version of Sora 'Ke Ling' is open for testing: generates over 120s video, understands physics better, and can accurately model complex movements
Jun 11, 2024 am 09:51 AM
What? Is Zootopia brought into reality by domestic AI? Exposed together with the video is a new large-scale domestic video generation model called "Keling". Sora uses a similar technical route and combines a number of self-developed technological innovations to produce videos that not only have large and reasonable movements, but also simulate the characteristics of the physical world and have strong conceptual combination capabilities and imagination. According to the data, Keling supports the generation of ultra-long videos of up to 2 minutes at 30fps, with resolutions up to 1080p, and supports multiple aspect ratios. Another important point is that Keling is not a demo or video result demonstration released by the laboratory, but a product-level application launched by Kuaishou, a leading player in the short video field. Moreover, the main focus is to be pragmatic, not to write blank checks, and to go online as soon as it is released. The large model of Ke Ling is already available in Kuaiying.
