
 Technology peripherals
AI
AWS provides comprehensive solutions for the implementation of generative AI
Technology peripherals
AI
AWS provides comprehensive solutions for the implementation of generative AI
AWS provides comprehensive solutions for the implementation of generative AI

Without changing the original meaning, it needs to be rewritten into Chinese: We have previously introduced to you a series of new technologies that Amazon Web Services (AWS) just announced at re:Invent 2023 aimed at accelerating generative artificial intelligence. Measures for the practical application of intelligence-related technologies

These include but are not limited to establishing a deeper strategic partnership with NVIDIA, the first computing cluster based on the GH200 super chip, and new self-developed general-purpose processors and AI inference chips, etc.

But as we all know, generative AI relies not only on powerful computing power in hardware, but also on good AI models. Especially in the current technical background, developers and enterprise users are often faced with many choices. Since different models are good at different generative categories, this leads to reasonable selection of models, parameter settings, and even effect evaluation. In practice, It has become a very troublesome thing for many users, and it has also greatly increased the difficulty of applying generative AI to actual application scenarios.

So how to solve the difficulties in the practical application of generative AI and truly liberate the productivity of new technologies? In the early morning of November 30, 2023, Beijing time, AWS gave a series of answers.
Currently, more model choices are brought together
First, AWS today announced further expansion of the Amazon Bedrock service. Previously, the service already included multiple industry-leading large language model sources, including AI21 Labs, Anthropic, Cohere, Meta, Stability AI and Amazon. Through this hosting service, users can conveniently choose to use various large language models on one platform without having to visit other platforms

During today’s keynote, AI security and research company Anthropic announced that they have brought the latest version of the Claude 2.1 model to Amazon Bedrock. Claude 2.1 excels at summarizing, performing Q&A, and comparisons on large volumes of text, making it particularly suitable for working with financial statements and internal data sets. According to Anthropic, Claude 2.1 offers significant improvements in honesty compared to the previous model, with 2x fewer false statements

At the same time, the well-known large language model Llama 2 has also introduced a new version with a scale of up to 70 billion parameters into Amazon Bedrock. As Meta's next generation large language model, Llama 2 has 40% more training data than the previous generation, and the context length has doubled. In its latest version, it has been fine-tuned with a data set of instructions and over 1 million human annotations, and optimized for conversational use cases.

What’s more important is that AWS has previously successfully developed their own AI large language model Titan. In addition to the previously released Amazon Titan Text Embeddings and Amazon Titan Text models for text generation, the Amazon Titan Image Generator and Amazon Titan Multimodal Embeddings, which focus on image generation, have also been officially announced today. Compared with traditional generative image models, AWS's own model also embeds unique technology for copyright protection and supports embedding image and text information into the database to generate more accurate search results in the future.
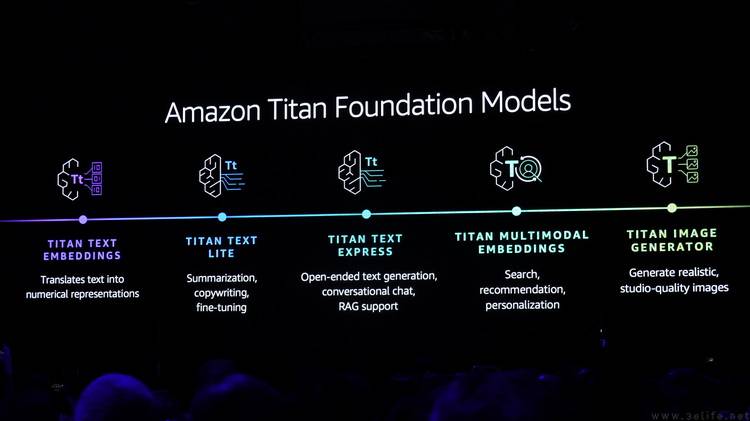
In addition, AWS has also innovatively proposed a copyright compensation policy for content generated by large models. That is, AWS will compensate customers for accusations that the generally available Amazon Titan model or its output infringes on third-party copyrights.
Using large language models more accurately and safely is now easy
In traditional use cases, enterprises may need to spend a long time to determine benchmarks, set up evaluation tools, and evaluate different models based on rich professional knowledge before they can choose the model that best suits them
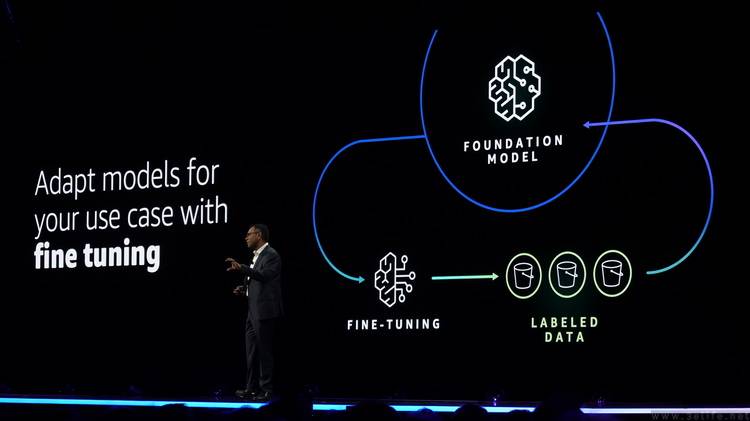
But now with the model evaluation function on Amazon Bedrock, all the above troubles can be avoided. Users only need to select preset evaluation criteria (such as accuracy, robustness) in the console, and then upload their own test data set, or select from a preset data amount to run complete automation. large model evaluation process.

Even if manual evaluation is required, AWS's expert team can provide detailed evaluation reports based on customer-defined indicators (such as relevance, style, brand image). While greatly saving time, it also significantly lowers the technical threshold for enterprises to use generative AI.

Not only that, in Amazon Bedrock, multiple large language models, including Cohere Command, Meta Llama 2, Amazon Titan, and Anthropic Claude 2.1 that will be adapted in the future, will support users to fine-tune according to their own needs. In addition, the Amazon Bedrock knowledge base function will also allow large models to connect to an enterprise's proprietary data sources, thereby providing more accurate and enterprise-specific responses for use cases such as chatbots and question-and-answer systems. .

At the same time, for the protection mechanism in the use of generative AI, Guardrails for Amazon Bedrock will now allow enterprises to customize the language principles of generative AI. They can set which topics will be rejected, configure thresholds for hate speech, insults, sexual language and violence to filter harmful content to their desired level. In the future, Guardrails for Amazon Bedrock will also introduce word filter functionality and use the same or different guard levels across multiple different model use cases.
After gaining the trust of a large number of users, AWS is fully promoting the implementation of generative AI
In addition to dramatically simplifying the process of selecting and using generative AI through new technologies, AWS’s acclaimed Amazon SageMaker service is now being used by customers such as Hugging Face, Perplexity, Salesforce, Stability AI, and Vanguard for Continuously train and enhance their large language models. Compared with using the company's own computing equipment, AWS's huge hardware advantages and flexible business model make the evolution of "large models" faster and simpler.

Not only that, we can see including Alida, Automation Anywhere, Blueshift, BMW Group, Clariant, Coinbase, Cox Automotive, dentsu, Druva, Genesys, Gilead, GoDaddy, Hellmann Worldwide Logistics, KONE, LexisNexis Legal & Professional, A series of companies such as Lonely Planet and NatWest have chosen to put their data on AWS and use this data to privately "customize" their own generative AI services without having to worry about the data being leaked or used by other competitors. Used by opponents. And because "any input or output of Amazon Bedrock will not be used to train its basic model, this is not only AWS's self-guarantee, but also a technical constraint they have made on third-party large model providers

In fact, if you list the relevant partners of AWS that appeared in today’s keynote speech, you will find that they cover almost all the industry chain links of today’s generative AI, such as basic model selection to accelerate training and iteration on AWS. ; Model service providers host their services on AWS to reach more users; and users of large models also prefer AWS's related payments, because the platform greatly simplifies their use of AI technology to improve service quality and business operation efficiency. Threshold, but also has excellent cost performance and extremely high reliability.

A few months ago, everyone may have been thinking about how to truly apply “generative artificial intelligence” to actual enterprises and users and bring benefits to them. However, after today's AWS re:Invent 2023 keynote, the answer is obvious
The above is the detailed content of AWS provides comprehensive solutions for the implementation of generative AI. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 From 'human + RPA' to 'human + generative AI + RPA', how does LLM affect RPA human-computer interaction?
Jun 05, 2023 pm 12:30 PM
From 'human + RPA' to 'human + generative AI + RPA', how does LLM affect RPA human-computer interaction?
Jun 05, 2023 pm 12:30 PM
Image source@visualchinesewen|Wang Jiwei From "human + RPA" to "human + generative AI + RPA", how does LLM affect RPA human-computer interaction? From another perspective, how does LLM affect RPA from the perspective of human-computer interaction? RPA, which affects human-computer interaction in program development and process automation, will now also be changed by LLM? How does LLM affect human-computer interaction? How does generative AI change RPA human-computer interaction? Learn more about it in one article: The era of large models is coming, and generative AI based on LLM is rapidly transforming RPA human-computer interaction; generative AI redefines human-computer interaction, and LLM is affecting the changes in RPA software architecture. If you ask what contribution RPA has to program development and automation, one of the answers is that it has changed human-computer interaction (HCI, h
 Why is generative AI sought after by various industries?
Mar 30, 2024 pm 07:36 PM
Why is generative AI sought after by various industries?
Mar 30, 2024 pm 07:36 PM
Generative AI is a type of human artificial intelligence technology that can generate various types of content, including text, images, audio and synthetic data. So what is artificial intelligence? What is the difference between artificial intelligence and machine learning? Artificial intelligence is the discipline, a branch of computer science, that studies the creation of intelligent agents, which are systems that can reason, learn, and perform actions autonomously. At its core, artificial intelligence is concerned with the theories and methods of building machines that think and act like humans. Within this discipline, machine learning ML is a field of artificial intelligence. It is a program or system that trains a model based on input data. The trained model can make useful predictions from new or unseen data derived from the unified data on which the model was trained.
 Say goodbye to design software to generate renderings in one sentence, generative AI subverts the field of decoration and decoration, with 28 popular tools
Jun 10, 2023 pm 03:33 PM
Say goodbye to design software to generate renderings in one sentence, generative AI subverts the field of decoration and decoration, with 28 popular tools
Jun 10, 2023 pm 03:33 PM
▲This picture was generated by AI. Kujiale, Sanweijia, Dongyi Risheng, etc. have already taken action. The decoration and decoration industry chain has introduced AIGC on a large scale. What are the applications of generative AI in the field of decoration and decoration? What impact does it have on designers? One article to understand and say goodbye to various design software to generate renderings in one sentence. Generative AI is subverting the field of decoration and decoration. Using artificial intelligence to enhance capabilities improves design efficiency. Generative AI is revolutionizing the decoration and decoration industry. What impact does generative AI have on the decoration and decoration industry? What are the future development trends? One article to understand how LLM is revolutionizing decoration and decoration. These 28 popular generative AI decoration design tools are worth trying. Article/Wang Jiwei In the field of decoration and decoration, there has been a lot of news related to AIGC recently. Collov launches generative AI-powered design tool Col
 Watch: What is the potential of applying generative AI to network automation?
Aug 17, 2023 pm 07:57 PM
Watch: What is the potential of applying generative AI to network automation?
Aug 17, 2023 pm 07:57 PM
Generative artificial intelligence (GenAI) is expected to become a compelling technology trend by 2023, bringing important applications to businesses and individuals, including education, according to a new report from market research firm Omdia. In the telecom space, use cases for GenAI are mainly focused on delivering personalized marketing content or supporting more sophisticated virtual assistants to enhance customer experience. Although the application of generative AI in network operations is not obvious, EnterpriseWeb has developed an interesting concept. Validation, demonstrating the potential of generative AI in the field, the capabilities and limitations of generative AI in network automation One of the early applications of generative AI in network operations was the use of interactive guidance to replace engineering manuals to help install network elements, from
 Which technology giant is behind Haier and Siemens' generative AI innovation?
Nov 21, 2023 am 09:02 AM
Which technology giant is behind Haier and Siemens' generative AI innovation?
Nov 21, 2023 am 09:02 AM
Gu Fan, General Manager of the Strategic Business Development Department of Amazon Cloud Technology Greater China In 2023, large language models and generative AI will "surge" in the global market, not only triggering "an overwhelming" follow-up in the AI and cloud computing industry, but also vigorously Attract manufacturing giants to join the industry. Haier Innovation Design Center created the country's first AIGC industrial design solution, which significantly shortened the design cycle and reduced conceptual design costs. It not only accelerated the overall conceptual design by 83%, but also increased the integrated rendering efficiency by about 90%, effectively solving Problems include high labor costs and low concept output and approval efficiency in the design stage. Siemens China's intelligent knowledge base and intelligent conversational robot "Xiaoyu" based on its own model has natural language processing, knowledge base retrieval, and big language training through data
 Using AWS in Go: A Complete Guide
Jun 17, 2023 pm 09:51 PM
Using AWS in Go: A Complete Guide
Jun 17, 2023 pm 09:51 PM
Go (or Golang) is a modern, high-performance programming language that has become widely popular among developers in recent years. AWS (Amazon Web Services) is one of the industry's leading cloud computing service providers, providing developers with a wealth of cloud computing products and API interfaces. In this article, we will introduce how to use AWS in Go language to build high-performance cloud applications. This article will cover the following topics: Install AWS SDK for Go to connect AWS storage data
 Tencent Hunyuan upgrades model matrix, launching 256k long text model on the cloud
Jun 01, 2024 pm 01:46 PM
Tencent Hunyuan upgrades model matrix, launching 256k long text model on the cloud
Jun 01, 2024 pm 01:46 PM
The implementation of large models is accelerating, and "industrial practicality" has become a development consensus. On May 17, 2024, the Tencent Cloud Generative AI Industry Application Summit was held in Beijing, announcing a series of progress in large model development and application products. Tencent's Hunyuan large model capabilities continue to upgrade. Multiple versions of models hunyuan-pro, hunyuan-standard, and hunyuan-lite are open to the public through Tencent Cloud to meet the model needs of enterprise customers and developers in different scenarios, and to implement the most cost-effective model solutions. . Tencent Cloud releases three major tools: knowledge engine for large models, image creation engine, and video creation engine, creating a native tool chain for the era of large models, simplifying data access, model fine-tuning, and application development processes through PaaS services to help enterprises
 Using AWS CloudWatch in Go: A Complete Guide
Jun 17, 2023 am 10:46 AM
Using AWS CloudWatch in Go: A Complete Guide
Jun 17, 2023 am 10:46 AM
AWS CloudWatch is a monitoring, log management, and metric collection service that helps you understand the performance and health of your applications, systems, and services. As a full-featured service provided by AWS, AWS CloudWatch can help users monitor and manage AWS resources, as well as the monitorability of applications and services. Using AWS CloudWatch in Go, you can easily monitor your applications and resolve performance issues as soon as they are discovered. This article
