
 Technology peripherals
AI
If they disagree, they will score points. Why are big domestic AI models addicted to 'swiping the rankings'?
Technology peripherals
AI
If they disagree, they will score points. Why are big domestic AI models addicted to 'swiping the rankings'?
If they disagree, they will score points. Why are big domestic AI models addicted to 'swiping the rankings'?

I believe that friends who follow the mobile phone circle will not be unfamiliar with the phrase "get a score if you don't accept it". For example, theoretical performance testing software such as AnTuTu and GeekBench have attracted much attention from players because they can reflect the performance of mobile phones to a certain extent. Similarly, there are corresponding benchmarking software for PC processors and graphics cards to measure their performance
Since "everything can run", the most popular large AI models have also begun to participate in the running score competition. Especially after the "Hundred Model War" began, breakthroughs were made almost every day, and each company called itself "running" Score first"
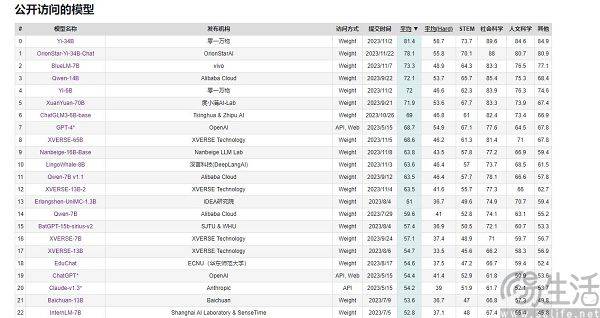
Domestic AI large models have almost never lagged behind in terms of performance scores, but they have never been able to surpass GPT-4 in terms of user experience. This raises a question, that is, at major sales points, each mobile phone manufacturer can always claim that its products are "number one in sales". By constantly adding attributive terms, the market is subdivided and subdivided, so that everyone has the opportunity to become the number one. , but in the field of AI large models, the situation is different. After all, their evaluation criteria are basically unified, including MMLU (used to measure multi-task language understanding ability), Big-Bench (used to quantify and extrapolate the ability of LLMs), and AGIEval (used to evaluate the ability to deal with human-level problems). Task ability)
Currently, the large-scale model evaluation lists that are often cited in China include SuperCLUE, CMMLU and C-Eval. Among them, CMMLU and C-Eval are comprehensive examination evaluation sets jointly constructed by Tsinghua University, Shanghai Jiao Tong University and University of Edinburgh. CMMLU is jointly launched by MBZUAI, Shanghai Jiao Tong University and Microsoft Research Asia. As for SuperCLUE, it is co-written by artificial intelligence professionals from major universities
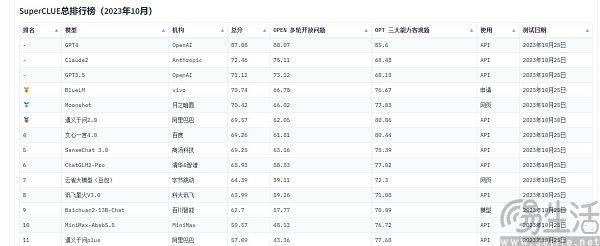
Take C-Eval as an example. On the list in early September, Yuntian Lifei's large model "Yuntian Shu" ranked first, 360 ranked eighth, but GPT-4 could only rank tenth. Since the standard is quantifiable, why are there counter-intuitive results? The reason why the large model running score list shows a scene of "devils dancing around" is actually because the current methods of evaluating the performance of large AI models have limitations. They use a "question solving" method to measure the ability of large models.
As we all know, in order to protect their lifespan, smartphone SoCs, computer CPUs and graphics cards will automatically reduce frequency under high temperatures, while low temperatures can improve chip performance. Therefore, some people will put their mobile phones in the refrigerator or equip their computers with more powerful cooling systems for performance testing, and can usually get higher scores than normal. In addition, major mobile phone manufacturers will also carry out "exclusive optimization" for various benchmarking software, which has become their standard operation
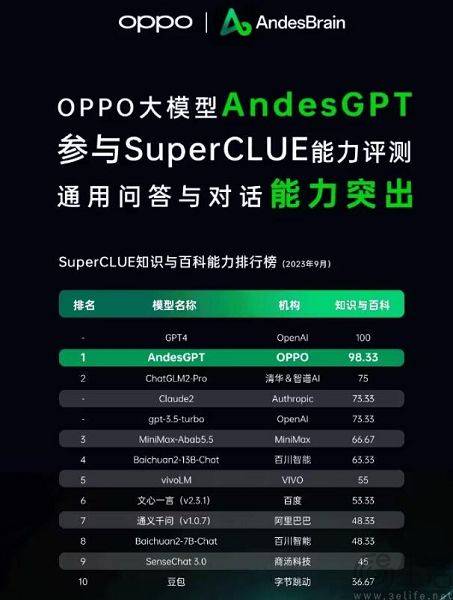
In the same way, the scoring of large artificial intelligence models is centered around question-taking, so there will naturally be a question bank. Yes, this is the reason why some large domestic models continue to be on the list. Due to various reasons, the question banks of major model lists are currently almost one-way transparent to manufacturers, which is what is called "benchmark leakage". For example, the C-Eval list had 13,948 questions when it was first launched, and due to the limited question bank, some unknown large models were allowed to "pass" by completing questions
You can imagine that before the exam, if you accidentally see the test paper and standard answers, and then memorize the questions suddenly, the exam scores will be greatly improved. Therefore, the question bank preset by the large model list is added to the training set, so that the large model becomes a model that fits the benchmark data. Moreover, the current LLM itself is known for its excellent memory, and reciting standard answers is simply a piece of cake
Through this method, small-size models can also have better results than large-size models in running scores. Some of the high scores achieved by large models are achieved through such "fine-tuning". In the paper "Don't Make Your LLM an Evaluation Benchmark Cheater", the Renmin University Hillhouse team bluntly pointed out this phenomenon, and this opportunistic approach is harmful to the performance of large models.
Researchers from the Hillhouse team found that benchmark leakage will cause large models to run exaggerated results. For example, a 1.3B model can surpass a model 10 times the size in some tasks, but the side effect is that these are specially designed for "test-taking" "The performance of large models designed on other normal testing tasks will be adversely affected. After all, if you think about it, you will know that the large AI model was originally supposed to be a "question maker", but it has become a "question memorizer". In order to get high scores on a certain list, it uses the specific knowledge and output style of the list. It will definitely mislead the large model.

The non-intersection of the training set, verification set, and test set is obviously only an ideal state. After all, the reality is very skinny, and the problem of data leakage is almost inevitable from the root. With the continuous advancement of related technologies, the memory and reception capabilities of the Transformer structure, which is the cornerstone of current large models, are constantly improving. This summer, Microsoft Research's General AI strategy has enabled the model to receive 100 million Tokens without causing unacceptable of forgetfulness. In other words, in the future, large AI models are likely to have the ability to read the entire Internet.
Even if technological progress is put aside, data pollution is actually difficult to avoid based on the current technical level, because high-quality data is always scarce and production capacity is limited. A paper published by the AI research team Epoch at the beginning of this year showed that AI will use up all high-quality human language data in less than 5 years, and this result is that it will increase the growth rate of human language data, that is, all human beings will publish in the next 5 years. Books written, papers written, and code written are all taken into account to predict the results.
If a data set is suitable for evaluation, then it will definitely play a better role in pre-training. For example, OpenAI's GPT-4 uses the authoritative inference evaluation data set GSM8K. Therefore, there is currently an embarrassing problem in the field of large-scale model evaluation. The demand for data from large-scale models seems to be endless, which leads to the evaluation agencies having to move faster and further than the manufacturers of artificial intelligence large-scale models. However, today’s assessment agencies seem to be simply incapable of doing this
As for why some manufacturers pay special attention to the running scores of large models and try to improve the rankings one after another? In fact, the logic behind this behavior is exactly the same as App developers injecting water into the number of users of their own Apps. After all, the user scale of an App is a key factor in measuring its value, and in the initial stage of the current large-scale AI model, the results on the evaluation list are almost the only relatively objective criterion. After all, in public perception, high scores mean It equals strong performance.
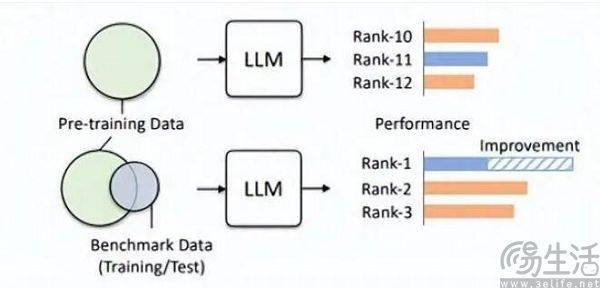
When brushing the rankings may bring a strong publicity effect and may even lay the foundation for financing, the addition of commercial interests will inevitably drive large AI model manufacturers to rush to brush the rankings.
The above is the detailed content of If they disagree, they will score points. Why are big domestic AI models addicted to 'swiping the rankings'?. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 The latest graphics card performance ranking list in 2023
Jan 05, 2024 pm 11:12 PM
The latest graphics card performance ranking list in 2023
Jan 05, 2024 pm 11:12 PM
The latest graphics card benchmark rankings for 2023 have been released. Users who follow the graphics card ladder chart can take a look. Recently, as graphics card manufacturers continue to release new graphics cards, and even introduce new ones to old series, the new list is completely different. ~2023 latest graphics card benchmark rankings, graphics card ladder rankings, 2023 computer graphics card purchasing suggestions: 1. Low-end graphics cards: RTX3050, 5600XT, and 2060S are all good entry-level choices. It is equivalent to buying a graphics card and getting a CPU, which can be used to play LOL, Cf, Overwatch and other lightweight 3D online games, with outstanding cost performance. 2. Entry graphics card: 3060, suitable for most general mainstream 3D games, with medium and low image quality. 3. Mid-range graphics card: NVIDIA: RTX3060Ti, RTX2
 Kirin 9000S unlocked benchmarks exposed: Stunning performance exceeds expectations
Sep 05, 2023 pm 12:45 PM
Kirin 9000S unlocked benchmarks exposed: Stunning performance exceeds expectations
Sep 05, 2023 pm 12:45 PM
Huawei's latest Mate60Pro mobile phone has attracted widespread attention after it went on sale in the domestic market. However, recently there has been some controversy on the benchmark platform about the performance of the Kirin 9000S processor equipped on the machine. According to the test results of the platform, the running scores of Kirin 9000S are incomplete, and the GPU running scores are missing, resulting in the inability of some benchmarking software to adapt. According to information exposed online, Kirin 9000S has achieved astonishing results in the unlocked running score test. The total score is 950935 points. Specifically, the CPU score is as high as 279,677 points, while the previously missing GPU score is 251,152 points. Compared with the total score of 699783 points in the previous AnTuTu official test, this shows the performance improvement of Kirin 9000S.
 The demand for computing power has exploded under the wave of AI large models. SenseTime's 'large model + large computing power” empowers the development of multiple industries.
Jun 09, 2023 pm 07:35 PM
The demand for computing power has exploded under the wave of AI large models. SenseTime's 'large model + large computing power” empowers the development of multiple industries.
Jun 09, 2023 pm 07:35 PM
Recently, the "Lingang New Area Intelligent Computing Conference" with the theme of "AI leads the era, computing power drives the future" was held. At the meeting, the New Area Intelligent Computing Industry Alliance was formally established. SenseTime became a member of the alliance as a computing power provider. At the same time, SenseTime was awarded the title of "New Area Intelligent Computing Industry Chain Master" enterprise. As an active participant in the Lingang computing power ecosystem, SenseTime has built one of the largest intelligent computing platforms in Asia - SenseTime AIDC, which can output a total computing power of 5,000 Petaflops and support 20 ultra-large models with hundreds of billions of parameters. Train at the same time. SenseCore, a large-scale device based on AIDC and built forward-looking, is committed to creating high-efficiency, low-cost, and large-scale next-generation AI infrastructure and services to empower artificial intelligence.
 Researcher: AI model inference consumes more power, and industry electricity consumption in 2027 will be comparable to that of the Netherlands
Oct 14, 2023 am 08:25 AM
Researcher: AI model inference consumes more power, and industry electricity consumption in 2027 will be comparable to that of the Netherlands
Oct 14, 2023 am 08:25 AM
IT House reported on October 13 that "Joule", a sister journal of "Cell", published a paper this week called "The growing energy footprint of artificial intelligence (The growing energy footprint of artificial intelligence)". Through inquiries, we learned that this paper was published by Alex DeVries, the founder of the scientific research institution Digiconomist. He claimed that the reasoning performance of artificial intelligence in the future may consume a lot of electricity. It is estimated that by 2027, the electricity consumption of artificial intelligence may be equivalent to the electricity consumption of the Netherlands for a year. Alex DeVries said that the outside world has always believed that training an AI model is "the most important thing in AI".
 OPPO Reno11 F appears on Geekbench: equipped with Dimensity 7050
Feb 06, 2024 pm 11:10 PM
OPPO Reno11 F appears on Geekbench: equipped with Dimensity 7050
Feb 06, 2024 pm 11:10 PM
According to media reports on February 6, OPPO released the OPPOReno11 series last year, offering two versions: standard version and Pro version. Now OPPO will also bring a new version of the Reno11 series - Reno11F. At present, OPPOReno11F has appeared in the Geekbench6 database. The new machine has a single-core running score of 897 points and a multi-core running score of 2329 points. According to benchmark tests, the new phone is equipped with MediaTek Dimensity 7050 SoC, paired with Mali-G68MC4 GPU and 8GB RAM, and is pre-installed with the ColorOS14 system based on Android 14. According to the news, OPPOReno11F will use a 6.7-inch A
 China Unicom releases large image and text AI model that can generate images and video clips from text
Jun 29, 2023 am 09:26 AM
China Unicom releases large image and text AI model that can generate images and video clips from text
Jun 29, 2023 am 09:26 AM
Driving China News on June 28, 2023, today during the Mobile World Congress in Shanghai, China Unicom released the graphic model "Honghu Graphic Model 1.0". China Unicom said that the Honghu graphic model is the first large model for operators' value-added services. China Business News reporter learned that Honghu’s graphic model currently has two versions of 800 million training parameters and 2 billion training parameters, which can realize functions such as text-based pictures, video editing, and pictures-based pictures. In addition, China Unicom Chairman Liu Liehong also said in today's keynote speech that generative AI is ushering in a singularity of development, and 50% of jobs will be profoundly affected by artificial intelligence in the next two years.
 Four times faster, Bytedance's open source high-performance training inference engine LightSeq technology revealed
May 02, 2023 pm 05:52 PM
Four times faster, Bytedance's open source high-performance training inference engine LightSeq technology revealed
May 02, 2023 pm 05:52 PM
The Transformer model comes from the paper "Attentionisallyouneed" published by the Google team in 2017. This paper first proposed the concept of using Attention to replace the cyclic structure of the Seq2Seq model, which brought a great impact to the NLP field. And with the continuous advancement of research in recent years, Transformer-related technologies have gradually flowed from natural language processing to other fields. Up to now, the Transformer series models have become mainstream models in NLP, CV, ASR and other fields. Therefore, how to train and infer Transformer models faster has become an important research direction in the industry. Low-precision quantization techniques can
 If they disagree, they will score points. Why are big domestic AI models addicted to 'swiping the rankings'?
Dec 02, 2023 am 08:53 AM
If they disagree, they will score points. Why are big domestic AI models addicted to 'swiping the rankings'?
Dec 02, 2023 am 08:53 AM
I believe that friends who follow the mobile phone circle will not be unfamiliar with the phrase "get a score if you don't accept it". For example, theoretical performance testing software such as AnTuTu and GeekBench have attracted much attention from players because they can reflect the performance of mobile phones to a certain extent. Similarly, there are corresponding benchmarking software for PC processors and graphics cards to measure their performance. Since "everything can be benchmarked", the most popular large AI models have also begun to participate in benchmarking competitions, especially in the "Hundred Models" After the "war" began, there were breakthroughs almost every day. Each company claimed to be "the first in running scores." The large domestic AI models almost never fell behind in terms of performance scores, but they were never able to surpass GP in terms of user experience.
