
 Technology peripherals
AI
A photo generates a video. Opening the mouth, nodding, emotions, anger, sorrow, and joy can all be controlled by typing.
Technology peripherals
AI
A photo generates a video. Opening the mouth, nodding, emotions, anger, sorrow, and joy can all be controlled by typing.
A photo generates a video. Opening the mouth, nodding, emotions, anger, sorrow, and joy can all be controlled by typing.

Recently, a study conducted by Microsoft revealed how flexible the video processing software PS is
In this study, you only need to give the AI a Taking photos, it can generate videos of the people in the photos, and the characters' expressions and movements can be controlled through text. For example, if the command you give is "open your mouth," the character in the video will actually open his mouth.

If the command you give is "sad", she will make sad expressions and head movements.
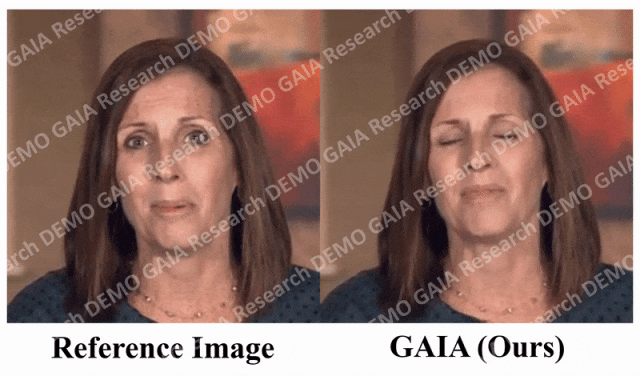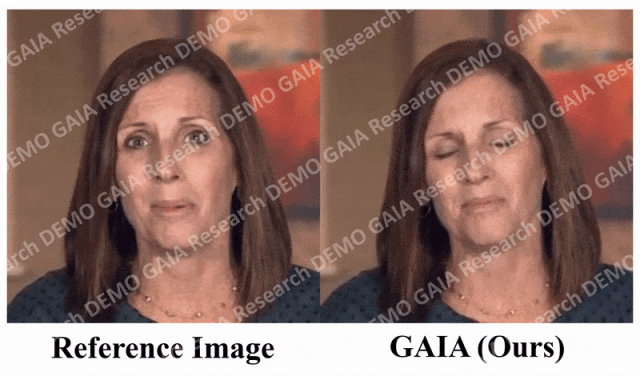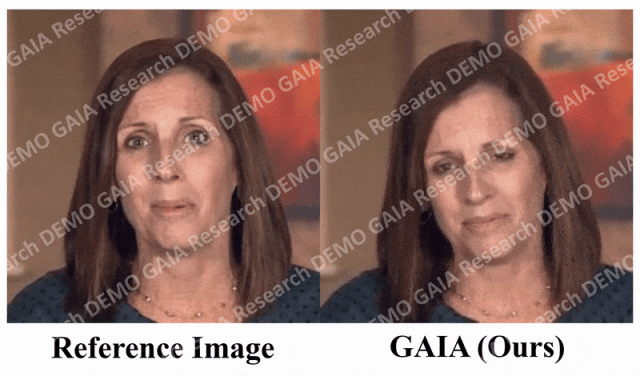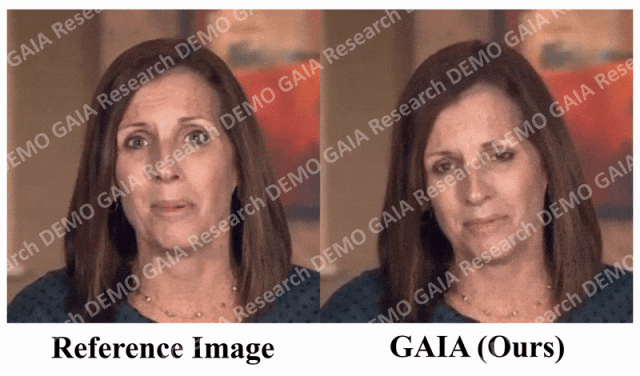
When the command "surprise" is given, the avatar's forehead lines are squeezed together.

In addition, you can also provide a voice to synchronize the mouth shape and movements of the virtual character with the voice. Alternatively, you can provide a live video for the avatar to imitate
If you have more custom editing needs for the avatar's movements, such as making them nod, turn, or tilt their heads , this technology is also supported

This research is called GAIA (Generative AI for Avatar, generative AI for avatars), Its demo has begun to spread on social media. Many people admire its effect and hope to use it to "resurrection" the dead.
But some people are worried that the continued evolution of these technologies will make online videos more difficult to distinguish between true and false, or be used by criminals to defraud. . It seems that anti-fraud measures will continue to be upgraded.
What innovations does GAIA have?
Zero-sample talking avatar generation technology aims to synthesize natural videos based on speech, ensuring that the generated mouth shapes, expressions and head postures are consistent with the speech content. Previous research usually requires specific training or tuning of specific models for each virtual character, or utilizing template videos during inference to achieve high-quality results. Recently, researchers have focused on designing and improving methods for generating zero-shot talking avatars by simply using a portrait image of the target avatar as an appearance reference. However, these methods usually use domain priors such as warping-based motion representation and 3D Morphable Model (3DMM) to reduce the difficulty of the task. Such heuristics, while effective, may limit diversity and lead to unnatural results. Therefore, direct learning from data distribution is the focus of future research
In this article, researchers from Microsoft proposed GAIA (Generative AI for Avatar), which can learn from speech and leaflets Portrait images are synthesized into natural talking virtual character videos, eliminating domain priors in the generation process.

Project address: https://microsoft.github.io/GAIA/Details of related projects can be found on this link
Paper link: https://arxiv.org/pdf/2311.15230.pdf
Gaia reveals two key insights:
-
Use voice to drive the movement of the virtual character, while the background and appearance of the virtual character remain unchanged throughout the video. Inspired by this, this paper separates the motion and appearance of each frame, where the appearance is shared between frames, while the motion is unique to each frame. In order to predict motion from speech, this paper encodes motion sequences into motion latent sequences and uses a diffusion model conditioned on the input speech to predict the latent sequences;
- There is huge diversity in expressions and head gestures when a person is speaking a given content, which requires a large-scale and diverse data set. Therefore, this study collected a high-quality talking avatar dataset consisting of 16K unique speakers of different ages, genders, skin types, and speaking styles, making the generation results natural and diverse.
Based on the above two insights, this article proposes the GAIA framework, which consists of a variational autoencoder (VAE) (orange module) and a diffusion model (blue and green modules) )composition.
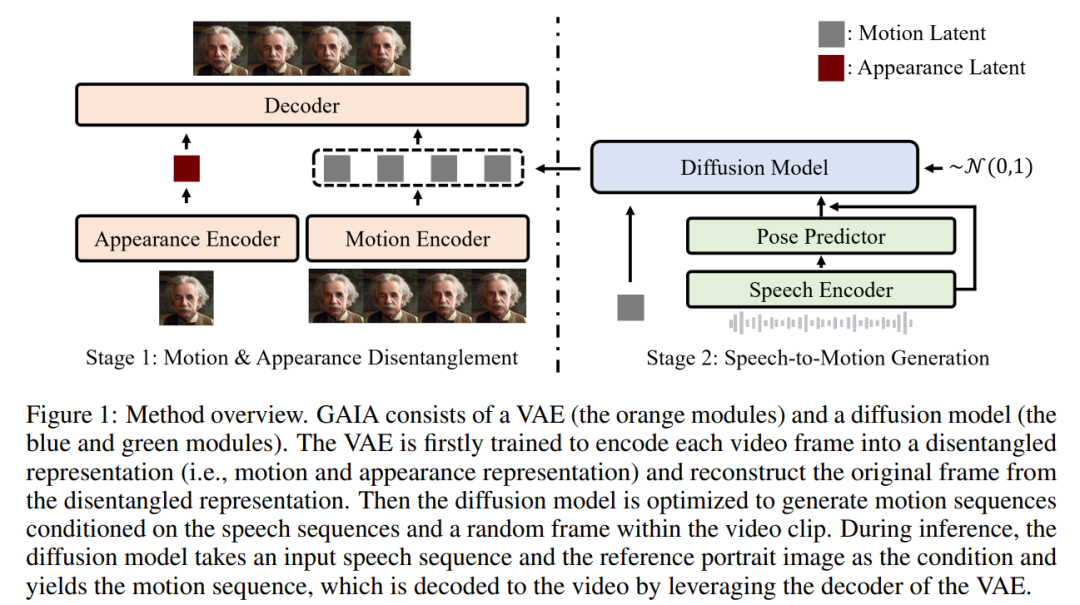
VAE's main function is to decompose movement and appearance. It consists of two encoders (motion encoder and appearance encoder) and a decoder. During training, the input to the motion encoder is the current frame of facial landmarks, while the input to the appearance encoder is a randomly sampled frame in the current video clip.
According to these two The output of the encoder is then optimized to reconstruct the current frame. Once the trained VAE is obtained, the potential actions (i.e. the output of the motion encoder) are obtained for all training data
Then, this article uses a diffusion model to train to predict speech-based and a motion latent sequence of randomly sampled frames in a video clip, thus providing appearance information for the generation process
In the inference process, given a reference portrait image of the target avatar, the diffusion model transforms the image into And the input speech sequence is used as a condition to generate a motion potential sequence that conforms to the speech content. The generated motion latent sequence and reference portrait image are then passed through a VAE decoder to synthesize the speaking video output.
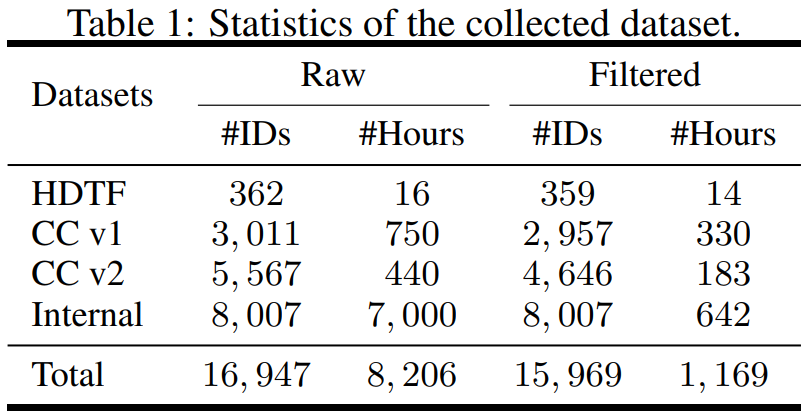
The study was structured in terms of data, collecting datasets from different sources, including High-Definition Talking Face Dataset (HDTF) and Casual Conversation datasets v1&v2 (CC v1&v2). In addition to these three datasets, the research also collected a large-scale internal speaking avatar dataset containing 7K hours of video and 8K speaker IDs. The statistical overview of the data set is shown in Table 1
In order to learn the required information, the article proposes several automatic filtering strategies to ensure training Quality of data:
- To make lip movements visible, the frontal direction of the avatar should be toward the camera;
- To ensure stability, Facial movements in the video should be smooth and should not shake rapidly;
- In order to filter out extreme cases where lip movements are inconsistent with speech, frames in which the avatar is wearing a mask or remaining silent should be deleted.
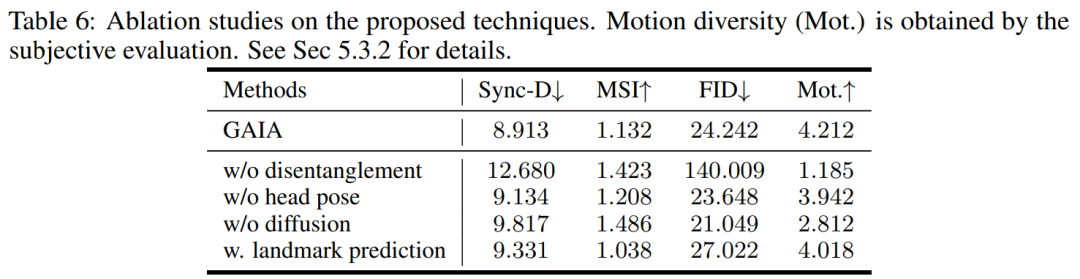
This article trains VAE and diffusion models on filtered data. Judging from the experimental results, this article has obtained three key conclusions:
- #GAIA can generate zero-sample speaking virtual characters, in terms of naturalness, diversity, and lip synchronization quality. and superior performance in terms of visual quality. According to the subjective evaluation of the researchers, GAIA significantly surpassed all baseline methods;
- The size of the training model ranged from 150M to 2B, and the results showed that GAIA is scalable because it is relatively small. Larger models produce better results;
- GAIA is a general and flexible framework that enables different applications, including controllable speaking avatar generation and text-command virtualization Character generation.
How does GAIA work?
During the experiment, the study compared GAIA with three powerful baselines, including FOMM, HeadGAN and Face-vid2vid. The results are shown in Table 2: VAE in GAIA achieves consistent improvements over previous video-driven baselines, demonstrating that GAIA successfully decomposes appearance and motion representations.
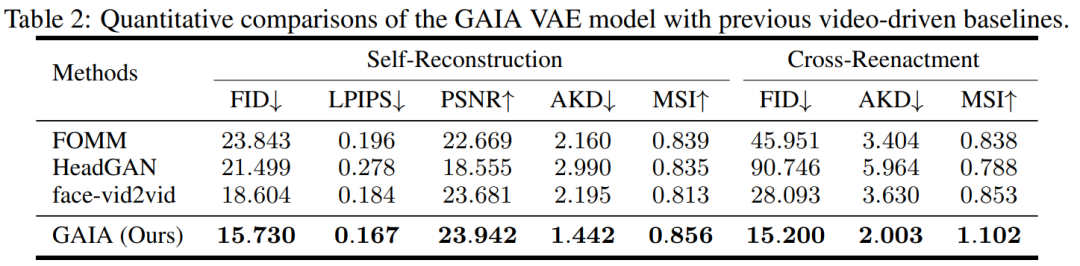
Voice driven results. Speech-driven speaking avatar generation is achieved by predicting motion from speech. Table 3 and Figure 2 provide quantitative and qualitative comparisons of GAIA with MakeItTalk, Audio2Head, and SadTalker methods.
It is clear from the data that GAIA far outperforms all baseline methods in terms of subjective evaluation. More specifically, as shown in Figure 2, even if the reference image has closed eyes or an unusual head pose, the generation results of baseline methods are usually highly dependent on the reference image; in contrast, GAIA exhibits good performance on various reference images. Robust and produces results with higher naturalness, high lip synchronization, better visual quality, and motion diversity

According to Table 3, the best MSI score indicates that the video generated by GAIA has excellent motion stability. The Sync-D score of 8.528 is close to the real video score (8.548), indicating that the generated video has excellent lip synchronization. This study achieved comparable FID scores to the baseline, which may be affected by different head poses, as the study found that the model without diffusion training achieved better FID scores, as detailed in Table 6
The above is the detailed content of A photo generates a video. Opening the mouth, nodding, emotions, anger, sorrow, and joy can all be controlled by typing.. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1389
1389
 52
52

 The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
The world's most powerful open source MoE model is here, with Chinese capabilities comparable to GPT-4, and the price is only nearly one percent of GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Imagine an artificial intelligence model that not only has the ability to surpass traditional computing, but also achieves more efficient performance at a lower cost. This is not science fiction, DeepSeek-V2[1], the world’s most powerful open source MoE model is here. DeepSeek-V2 is a powerful mixture of experts (MoE) language model with the characteristics of economical training and efficient inference. It consists of 236B parameters, 21B of which are used to activate each marker. Compared with DeepSeek67B, DeepSeek-V2 has stronger performance, while saving 42.5% of training costs, reducing KV cache by 93.3%, and increasing the maximum generation throughput to 5.76 times. DeepSeek is a company exploring general artificial intelligence
 KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
KAN, which replaces MLP, has been extended to convolution by open source projects
Jun 01, 2024 pm 10:03 PM
Earlier this month, researchers from MIT and other institutions proposed a very promising alternative to MLP - KAN. KAN outperforms MLP in terms of accuracy and interpretability. And it can outperform MLP running with a larger number of parameters with a very small number of parameters. For example, the authors stated that they used KAN to reproduce DeepMind's results with a smaller network and a higher degree of automation. Specifically, DeepMind's MLP has about 300,000 parameters, while KAN only has about 200 parameters. KAN has a strong mathematical foundation like MLP. MLP is based on the universal approximation theorem, while KAN is based on the Kolmogorov-Arnold representation theorem. As shown in the figure below, KAN has
 Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
The latest video of Tesla's robot Optimus is released, and it can already work in the factory. At normal speed, it sorts batteries (Tesla's 4680 batteries) like this: The official also released what it looks like at 20x speed - on a small "workstation", picking and picking and picking: This time it is released One of the highlights of the video is that Optimus completes this work in the factory, completely autonomously, without human intervention throughout the process. And from the perspective of Optimus, it can also pick up and place the crooked battery, focusing on automatic error correction: Regarding Optimus's hand, NVIDIA scientist Jim Fan gave a high evaluation: Optimus's hand is the world's five-fingered robot. One of the most dexterous. Its hands are not only tactile
 Microsoft releases Win11 August cumulative update: improving security, optimizing lock screen, etc.
Aug 14, 2024 am 10:39 AM
Microsoft releases Win11 August cumulative update: improving security, optimizing lock screen, etc.
Aug 14, 2024 am 10:39 AM
According to news from this site on August 14, during today’s August Patch Tuesday event day, Microsoft released cumulative updates for Windows 11 systems, including the KB5041585 update for 22H2 and 23H2, and the KB5041592 update for 21H2. After the above-mentioned equipment is installed with the August cumulative update, the version number changes attached to this site are as follows: After the installation of the 21H2 equipment, the version number increased to Build22000.314722H2. After the installation of the equipment, the version number increased to Build22621.403723H2. After the installation of the equipment, the version number increased to Build22631.4037. The main contents of the KB5041585 update for Windows 1121H2 are as follows: Improvement: Improved
 Microsoft's full-screen pop-up urges Windows 10 users to hurry up and upgrade to Windows 11
Jun 06, 2024 am 11:35 AM
Microsoft's full-screen pop-up urges Windows 10 users to hurry up and upgrade to Windows 11
Jun 06, 2024 am 11:35 AM
According to news on June 3, Microsoft is actively sending full-screen notifications to all Windows 10 users to encourage them to upgrade to the Windows 11 operating system. This move involves devices whose hardware configurations do not support the new system. Since 2015, Windows 10 has occupied nearly 70% of the market share, firmly establishing its dominance as the Windows operating system. However, the market share far exceeds the 82% market share, and the market share far exceeds that of Windows 11, which will be released in 2021. Although Windows 11 has been launched for nearly three years, its market penetration is still slow. Microsoft has announced that it will terminate technical support for Windows 10 after October 14, 2025 in order to focus more on
 Comprehensively surpassing DPO: Chen Danqi's team proposed simple preference optimization SimPO, and also refined the strongest 8B open source model
Jun 01, 2024 pm 04:41 PM
Comprehensively surpassing DPO: Chen Danqi's team proposed simple preference optimization SimPO, and also refined the strongest 8B open source model
Jun 01, 2024 pm 04:41 PM
In order to align large language models (LLMs) with human values and intentions, it is critical to learn human feedback to ensure that they are useful, honest, and harmless. In terms of aligning LLM, an effective method is reinforcement learning based on human feedback (RLHF). Although the results of the RLHF method are excellent, there are some optimization challenges involved. This involves training a reward model and then optimizing a policy model to maximize that reward. Recently, some researchers have explored simpler offline algorithms, one of which is direct preference optimization (DPO). DPO learns the policy model directly based on preference data by parameterizing the reward function in RLHF, thus eliminating the need for an explicit reward model. This method is simple and stable
 No OpenAI data required, join the list of large code models! UIUC releases StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
No OpenAI data required, join the list of large code models! UIUC releases StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
At the forefront of software technology, UIUC Zhang Lingming's group, together with researchers from the BigCode organization, recently announced the StarCoder2-15B-Instruct large code model. This innovative achievement achieved a significant breakthrough in code generation tasks, successfully surpassing CodeLlama-70B-Instruct and reaching the top of the code generation performance list. The unique feature of StarCoder2-15B-Instruct is its pure self-alignment strategy. The entire training process is open, transparent, and completely autonomous and controllable. The model generates thousands of instructions via StarCoder2-15B in response to fine-tuning the StarCoder-15B base model without relying on expensive manual annotation.
 LLM is all done! OmniDrive: Integrating 3D perception and reasoning planning (NVIDIA's latest)
May 09, 2024 pm 04:55 PM
LLM is all done! OmniDrive: Integrating 3D perception and reasoning planning (NVIDIA's latest)
May 09, 2024 pm 04:55 PM
Written above & the author’s personal understanding: This paper is dedicated to solving the key challenges of current multi-modal large language models (MLLMs) in autonomous driving applications, that is, the problem of extending MLLMs from 2D understanding to 3D space. This expansion is particularly important as autonomous vehicles (AVs) need to make accurate decisions about 3D environments. 3D spatial understanding is critical for AVs because it directly impacts the vehicle’s ability to make informed decisions, predict future states, and interact safely with the environment. Current multi-modal large language models (such as LLaVA-1.5) can often only handle lower resolution image inputs (e.g.) due to resolution limitations of the visual encoder, limitations of LLM sequence length. However, autonomous driving applications require
