

Researchers pointed out that CoDi-2 marks a major breakthrough in the field of developing comprehensive multi-modal basic models
In May of this year, North Carolina The University of Chapel Hill and Microsoft proposed a Composable Diffusion (CoDi) model, making it possible for one model to unify multiple modalities. CoDi not only supports single-modal to single-modal generation, but can also receive multiple conditional inputs and multi-modal joint generation.
Recently, many researchers from UC Berkeley, Microsoft Azure AI, Zoom, and the University of North Carolina at Chapel Hill have upgraded the CoDi system to the CoDi-2 version

Paper address: https://arxiv.org/pdf/2311.18775.pdf
Project address: https://codi-2. github.io/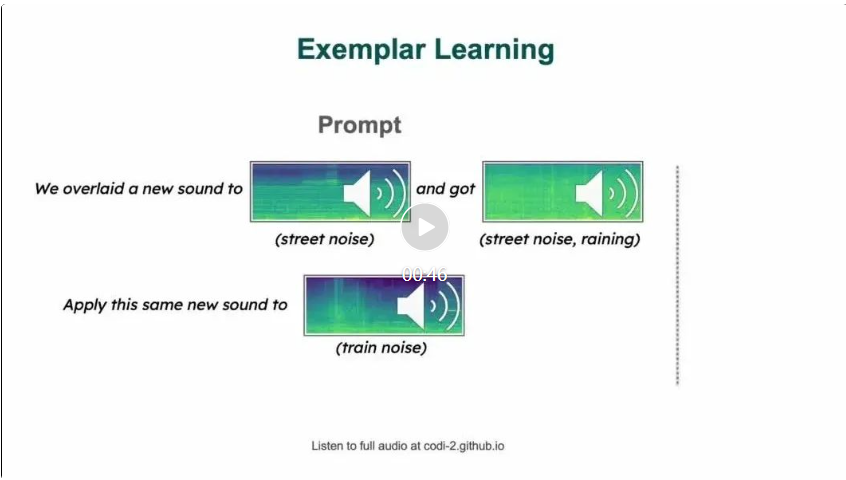
Rewrite the content without changing the original meaning. It needs to be rewritten into Chinese language and the original sentence does not need to appear.
According to Zineng Tang’s paper, CoDi-2 follows complex multi-modal interleaved contextual instructions to generate any modality (text, visual and audio) with zero- or few-shot interactions )

##This link is the source of the picture: https://twitter.com/ZinengTang/status/1730658941414371820
It can be said that as a multi-functional, interactive multi-modal large language model (MLLM), CoDi-2 can perform contextual learning, reasoning, chatting, and editing with any-to-any input-output modal paradigm. Wait for the task. By aligning modalities and languages during encoding and generation, CoDi-2 enables LLM not only to understand complex modal interleaving instructions and contextual examples, but also to autoregressively generate reasonable and coherent multi-modal output within a continuous feature space. . To train CoDi-2, the researchers built a large-scale generative dataset containing contextual multimodal instructions across text, visuals, and audio. CoDi-2 demonstrates a range of zero-shot capabilities for multi-modal generation, such as contextual learning, reasoning, and any-to-any modal generation combinations through multiple rounds of interactive dialogue. Among them, it surpasses previous domain-specific models in tasks such as topic-driven image generation, visual transformation, and audio editing.
Multiple rounds of dialogue between humans and CoDi-2 provide contextual multimodal instructions for image editing.
What needs to be rewritten is: Model Architecture
CoDi-2 is designed to handle text, images and audio in context and other multi-modal inputs, using specific instructions to promote contextual learning and generate corresponding text, image, and audio output. What needs to be rewritten for CoDi-2 is: The model architecture diagram is as follows.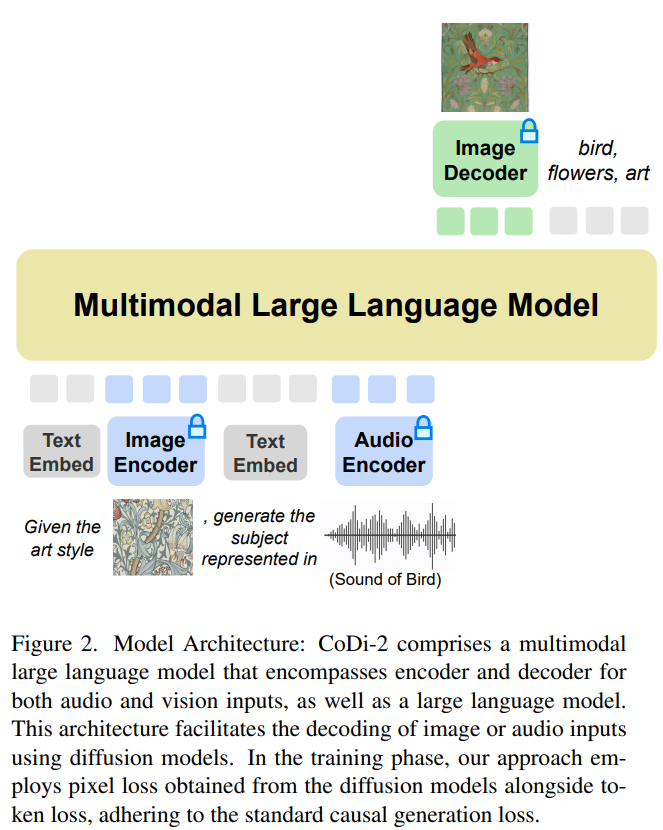
Using multi-modal large language model as the basic engine
This any-to-any basic model can digest interleaved Modal input, understanding and reasoning about complex instructions (such as multi-turn conversations, contextual examples), and interacting with multi-modal diffusers require a powerful basic engine. The researchers proposed MLLM as this engine, which was built to provide multimodal perception for text-only LLMs. Using aligned multi-modal encoder mapping, researchers can seamlessly make LLM aware of modally interleaved input sequences. Specifically, when processing multi-modal input sequences, they first use multi-modal encoders to map multi-modal data to feature sequences, and then special tokens are added before and after the feature sequence, such as "〈audio〉 [audio feature sequence" ] 〈/audio〉”.The basis of multi-modal generation is MLLM
Researchers proposed to integrate the diffusion model (DM) into MLLM to generate multi-modal output. During this process, detailed multimodal interleaving instructions and prompts were followed. The training objectives of the diffusion model are as follows: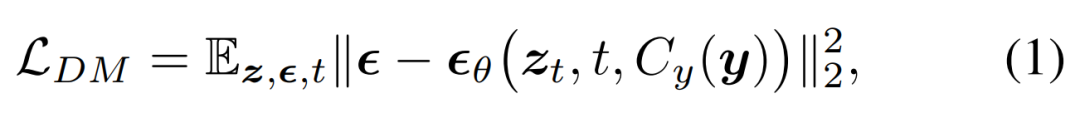
They then proposed training an MLLM to generate conditional features c = C_y (y), which are fed into a diffusion model to synthesize the target output x. In this way, the generative loss of the diffusion model is used to train the MLLM.
Task Type
The model demonstrates its power in the following example task types, which provide a unique way to prompt the model to generate or transform context The multi-modal content in , including text, images, audio, video and their combinations
The rewritten content is: 1. Zero-sample reasoning. Zero-shot inference tasks require the model to reason and generate new content without any previous examples
2. One-time/small number of sample prompts. One or a few sample prompts provide the model with one or several examples to learn from before performing similar tasks. This approach is evident in tasks where the model applies learned concepts from one image to another, or creates a new artwork by understanding the style described in the provided example.
Experiments and results
Model settings
The implementation of the model in this article is based on Llama2, especially Llama-2-7b- chat-hf. The researchers used ImageBind, which has aligned image, video, audio, text, depth, thermal and IMU mode encoders. We use ImageBind to encode image and audio features and project them through a multilayer perceptron (MLP) to the input dimensions of an LLM (Llama-2-7b-chat-hf). MLP consists of linear mapping, activation, normalization and another linear mapping. When LLMs generate image or audio features, they project them back into the ImageBind feature dimension through another MLP. The image diffusion model in this article is based on StableDiffusion2.1 (stabilityai/stable-diffusion-2-1-unclip), AudioLDM2 and zeroscope v2.
In order to obtain higher fidelity original input images or audio, researchers input them into the diffusion model and generate features by concatenating diffusion noise. This method is very effective. It can retain the perceptual characteristics of the input content to the greatest extent, and can add new content or change the style and other instructions. Edit
The content that needs to be rewritten is: Image generation evaluation
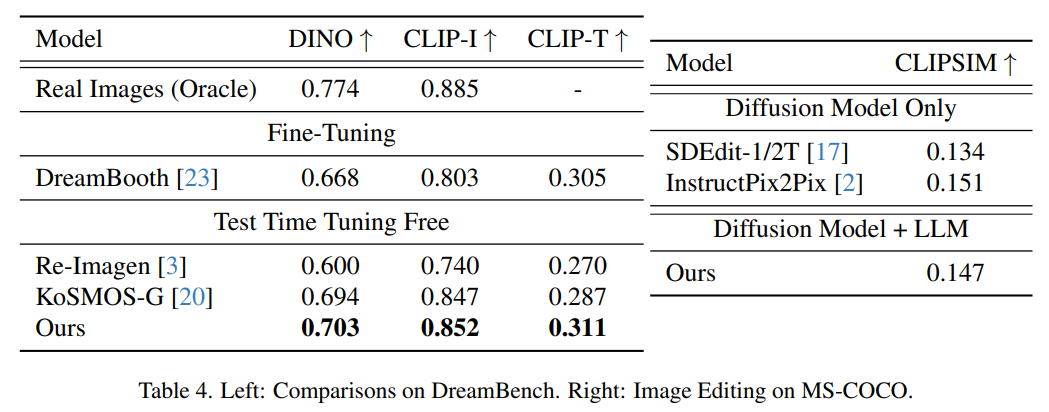
The following figure shows the evaluation results of topic-driven image generation on Dreambench and the FID score on MSCOCO. The method in this paper achieves highly competitive zero-shot performance, demonstrating its generalization ability to unknown new tasks.
Audio Generation Evaluation
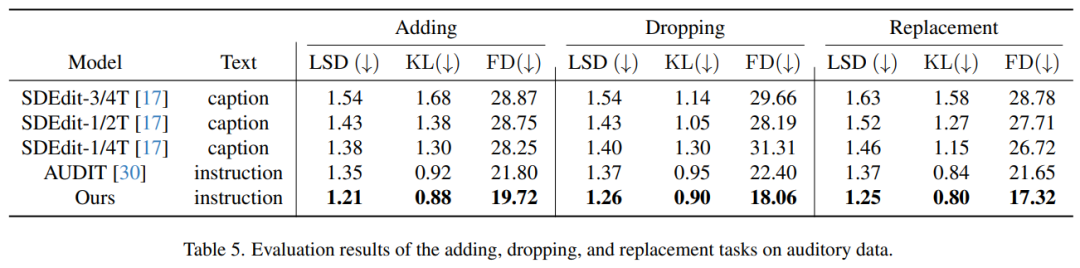
Table 5 shows the evaluation results for audio processing tasks, i.e., adding, deleting, and replacing audio tracks Elements. From the table, it is obvious that our method shows excellent performance compared with previous methods. Notably, it achieved the lowest scores on all metrics - Log Spectral Distance (LSD), Kullback-Leibler (KL) Divergence and Fréchet Distance (FD) across all three editing tasks
Read the original article for more technical details.
The above is the detailed content of Any text, visual, audio mixed generation, multi-modal with a powerful basic engine CoDi-2. For more information, please follow other related articles on the PHP Chinese website!
 How to flash Xiaomi phone
How to flash Xiaomi phone
 How to center div in css
How to center div in css
 How to open rar file
How to open rar file
 Methods for reading and writing java dbf files
Methods for reading and writing java dbf files
 How to solve the problem that the msxml6.dll file is missing
How to solve the problem that the msxml6.dll file is missing
 Commonly used permutation and combination formulas
Commonly used permutation and combination formulas
 Virtual mobile phone number to receive verification code
Virtual mobile phone number to receive verification code
 dynamic photo album
dynamic photo album








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



