
 Technology peripherals
AI
Complete 13 visual language tasks! Harbin Institute of Technology releases the multi-modal large model 'Jiutian', with performance increasing by 5%
Technology peripherals
AI
Complete 13 visual language tasks! Harbin Institute of Technology releases the multi-modal large model 'Jiutian', with performance increasing by 5%
Complete 13 visual language tasks! Harbin Institute of Technology releases the multi-modal large model 'Jiutian', with performance increasing by 5%

In order to deal with the problem of insufficient visual information extraction in multi-modal large language models, researchers from Harbin Institute of Technology (Shenzhen) proposed a double-layer knowledge-enhanced multi-modal large language model-JiuTian- LION).

The content that needs to be rewritten is: Paper link: https://arxiv.org/abs/2311.11860
GitHub: https://github.com/rshaojimmy/JiuTian
Project homepage: https://rshaojimmy.github.io/Projects/JiuTian-LION
Compared with existing work, Jiutian analyzed the internal conflicts between image-level understanding tasks and regional-level positioning tasks for the first time, and proposed a segmented instruction fine-tuning strategy and a hybrid adapter to achieve both Mutual promotion of tasks.
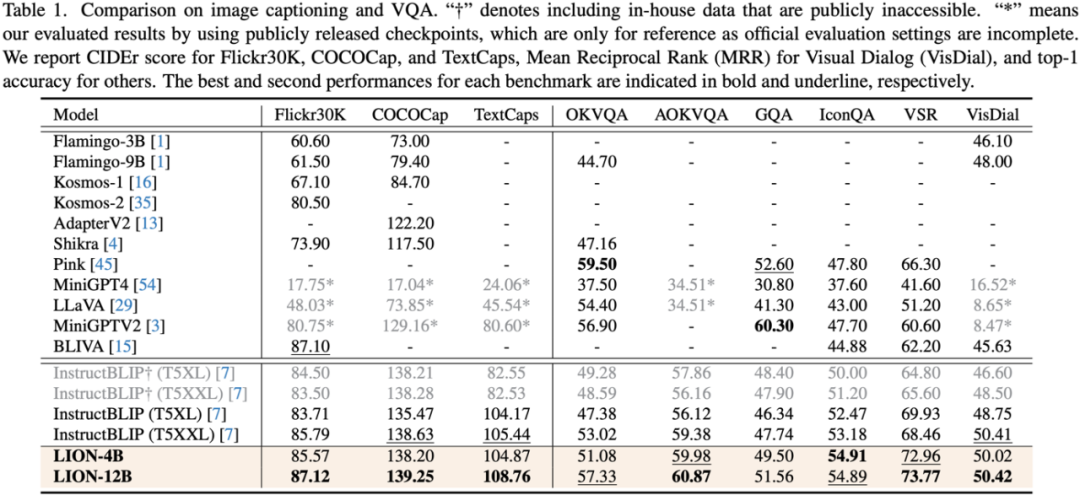
By injecting fine-grained spatial perception and high-level semantic visual knowledge, Jiutian has achieved significant performance improvements in 17 visual language tasks including image description, visual problems, and visual localization. (For example, up to 5% performance improvement on Visual Spatial Reasoning). It has reached the international leading level in 13 of the evaluation tasks. The performance comparison is shown in Figure 1.
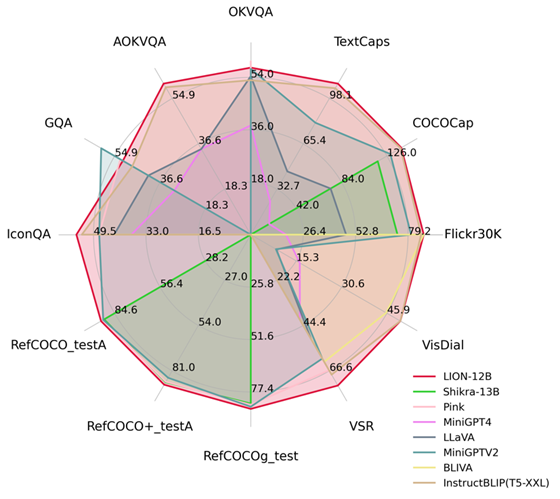
Figure 1: Compared with other MLLMs, Jiutian has achieved optimal performance on most tasks.
九天JiuTian-LION
By giving large language models (LLMs) multimodal awareness capabilities, some work has begun to generate multimodal large language models (MLLMs), And has made breakthrough progress in many visual language tasks. However, existing MLLMs mainly use visual encoders pre-trained on image-text pairs, such as CLIP-ViT
. The main task of these visual encoders is to learn coarse-grained images at the image level. Text modalities are aligned, but they lack comprehensive visual perception and information extraction capabilities for fine-grained visual understanding
To a large extent, this visual information extraction and understanding are insufficient Insufficient problems will lead to multiple defects in MLLMs such as visual localization bias, insufficient spatial reasoning, and object hallucination, as shown in Figure 2
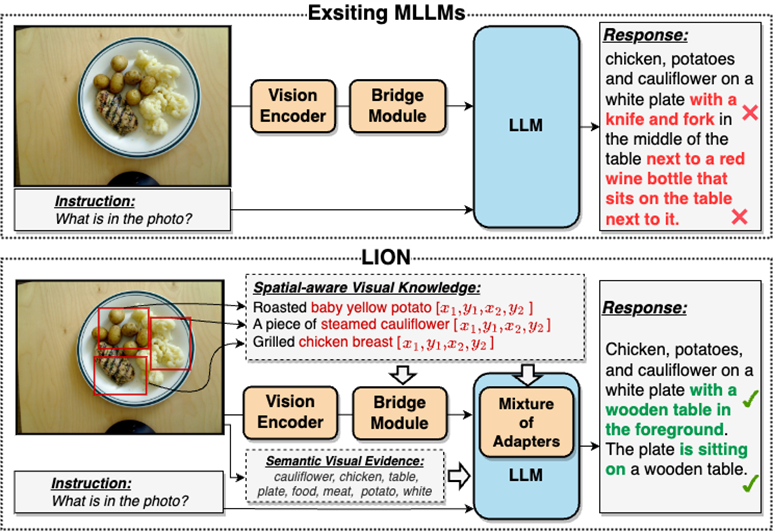
##Please Reference Figure 2: JiuTian-LION is a multi-modal large language model enhanced with double-layer visual knowledge
JiuTian-LION is compared with existing multi-modal large language Models (MLLMs), by injecting fine-grained spatial awareness visual knowledge and high-level semantic visual evidence, effectively improve the visual understanding capabilities of MLLMs, generate more accurate text responses, and reduce the hallucination phenomenon of MLLMs
Double-layer visual knowledge enhanced multi-modal large language model-JiuTian-LION
In order to solve the problem of MLLMs in visual information extraction and understanding In order to solve the shortcomings in this aspect, the researchers proposed a two-layer visual knowledge enhanced MLLMs method, called JiuTian-LION. The specific method framework is shown in Figure 3
This method mainly enhances MLLMs from two aspects, progressively integrating fine-grained Spatial-aware Visual knowledge (Progressive Incorporation of Fine-grained Spatial-aware Visual knowledge) and Soft Prompting of High-level Semantic Visual Evidence under soft prompts.
Specifically, the researchers proposed a segmented instruction fine-tuning strategy to resolve the internal conflict between the image-level understanding task and the region-level localization task. They gradually inject fine-grained spatial awareness knowledge into MLLMs. At the same time, they added image labels as high-level semantic visual evidence to MLLMs, and used soft hinting methods to mitigate the possible negative impact of incorrect labels
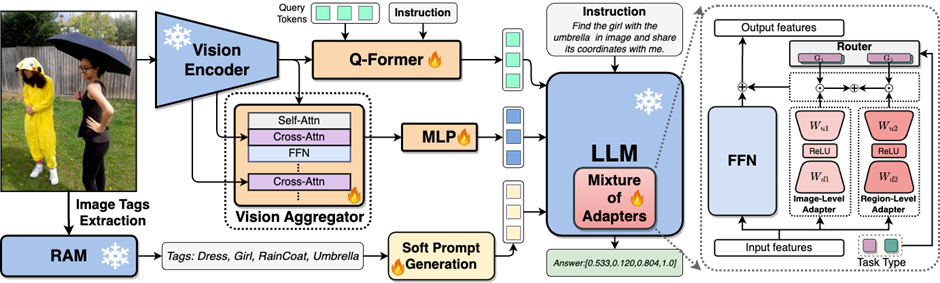
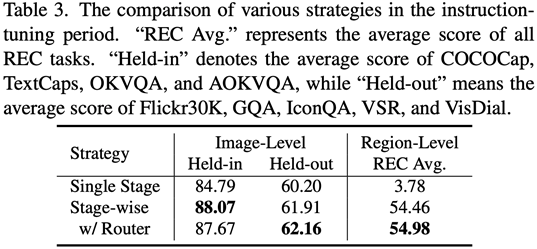
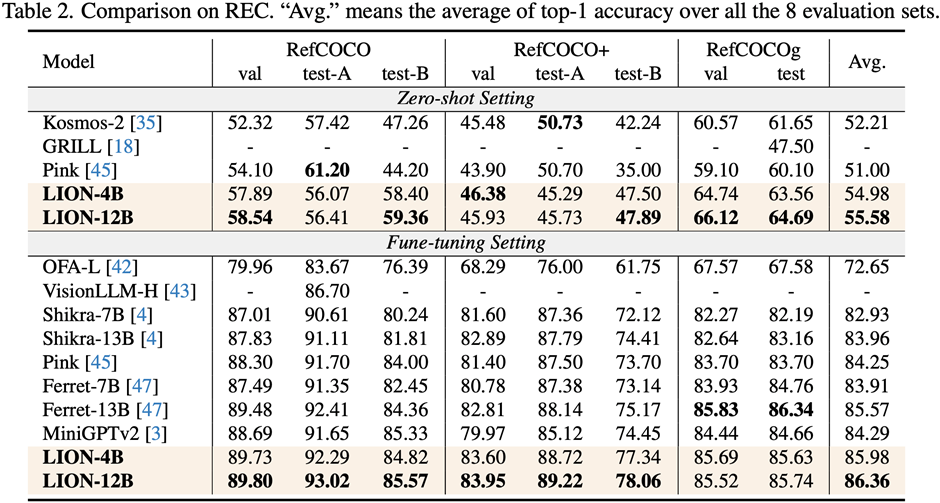
This work uses a segmented training strategy to first learn image-level understanding and regional-level positioning tasks based on Q-Former and Vision Aggregator-MLP branches respectively, and then utilizes a hybrid adapter with a routing mechanism in the final training stage. To dynamically integrate the performance of different branches of knowledge improvement models on two tasks. This work also extracts image tags as high-level semantic visual evidence through RAM, and then proposes a soft prompt method to improve the effect of high-level semantic injection Progressive fusion of fine-grained spatial awareness visual knowledge When directly combining image-level understanding tasks (including image description and visual question answering) with regional-level localization tasks (including instructions Expression understanding, instruction expression generation, etc.) When performing single-stage hybrid training, MLLMs will encounter internal conflicts between the two tasks and thus cannot achieve good overall performance on all tasks. Researchers believe that this internal conflict is mainly caused by two issues. The first problem is the lack of regional-level modal alignment pre-training. Currently, most MLLMs with regional-level positioning capabilities first use a large amount of relevant data for pre-training. Otherwise, it will be difficult to use image-level modal alignment based on limited training resources. Visual feature adaptation to region-level tasks. Another problem is the difference in input and output patterns between image-level understanding tasks and region-level localization tasks. The latter requires the model to additionally understand specific short sentences about object coordinates (started with As shown in Figure 4, the researchers split the single-stage instruction fine-tuning process into three stages: Using ViT, Q-Former and image-level adapters to learn image-level understanding tasks of global visual knowledge; use Vision Aggregator, MLP, and regional-level adapters to learn regional-level positioning tasks of fine-grained space-aware visual knowledge; propose a hybrid adapter with a routing mechanism to dynamically integrate different branches Visual knowledge learned at different granularities. Table 3 shows the performance advantages of the segmented instruction fine-tuning strategy over single-stage training Figure 4: Segmented instruction fine-tuning strategy For high-level semantic visual evidence injected under soft prompts, rewriting is required Researchers propose using image labels as an effective supplement to high-level semantic visual evidence to further enhance the global visual perception understanding ability of MLLMs Specific For example, first extract the image tag through RAM, and then use the specific command template "According to Coupled with the specific phrase "use or partially use" in the template, the soft hint vector can guide the model to mitigate the potential negative impact of incorrect labels. The researchers included image captioning (image captioning), visual question answering (VQA), and directed expression understanding (REC) It was evaluated on 17 task benchmark sets. The experimental results show that Jiutian has reached the international leading level in 13 evaluation sets. In particular, compared with InstructBLIP and Shikra, Jiutian has achieved comprehensive and consistent performance improvements in image-level understanding tasks and region-level positioning tasks respectively, and can achieve up to 5% improvement in Visual Spatial Reasoning (VSR) tasks. As can be seen from Figure 5, there are differences in the abilities of Jiutian and other MLLMs in different visual language multi-modal tasks, indicating that Jiutian performs better in fine-grained visual understanding and visuospatial reasoning capabilities. And be able to output text responses with less illusion The rewritten content is: The fifth picture shows the response to the Nine-day Large Model, InstructBLIP and Qualitative analysis of Shikra’s ability differences Figure 6 shows through sample analysis that the Jiutian model has excellent understanding and recognition capabilities in both image-level and regional-level visual language tasks. The sixth picture: Through the analysis of more examples, the capabilities of the Jiutian large model are demonstrated from the perspective of image and regional level visual understanding (1) This work proposes a new multi-modal large language model-Jiutian: enhanced by double-layer visual knowledge Multimodal large language model. (2) This work was evaluated on 17 visual language task benchmark sets including image description, visual question answering and instructional expression understanding, among which 13 evaluation sets reached the current best performance. (3) This work proposes a segmented instruction fine-tuning strategy to resolve the internal conflict between image-level understanding and region-level localization tasks, and implements two Mutual improvement between tasks (4) This work successfully integrates image-level understanding and regional-level positioning tasks to comprehensively understand visual scenes at multiple levels. This comprehensive approach can be used in the future. Visual understanding capabilities are applied to embodied intelligent scenarios to help robots better and more comprehensively identify and understand the current environment and make effective decisions. 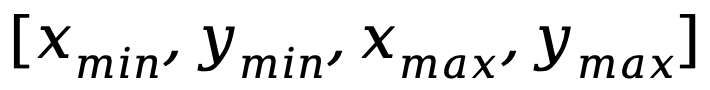 form). In order to solve the above problems, researchers proposed a segmented instruction fine-tuning strategy and a hybrid adapter with a routing mechanism.
form). In order to solve the above problems, researchers proposed a segmented instruction fine-tuning strategy and a hybrid adapter with a routing mechanism. 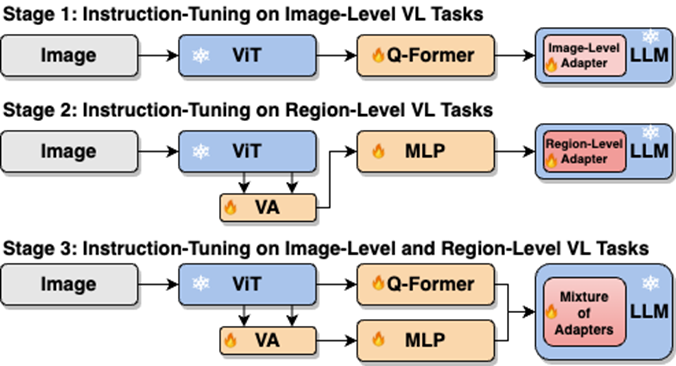
Experimental results


Summary
The above is the detailed content of Complete 13 visual language tasks! Harbin Institute of Technology releases the multi-modal large model 'Jiutian', with performance increasing by 5%. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 WorldCoin (WLD) price forecast 2025-2031: Will WLD reach USD 4 by 2031?
Apr 21, 2025 pm 02:42 PM
WorldCoin (WLD) price forecast 2025-2031: Will WLD reach USD 4 by 2031?
Apr 21, 2025 pm 02:42 PM
WorldCoin (WLD) stands out in the cryptocurrency market with its unique biometric verification and privacy protection mechanisms, attracting the attention of many investors. WLD has performed outstandingly among altcoins with its innovative technologies, especially in combination with OpenAI artificial intelligence technology. But how will the digital assets behave in the next few years? Let's predict the future price of WLD together. The 2025 WLD price forecast is expected to achieve significant growth in WLD in 2025. Market analysis shows that the average WLD price may reach $1.31, with a maximum of $1.36. However, in a bear market, the price may fall to around $0.55. This growth expectation is mainly due to WorldCoin2.
 What does cross-chain transaction mean? What are the cross-chain transactions?
Apr 21, 2025 pm 11:39 PM
What does cross-chain transaction mean? What are the cross-chain transactions?
Apr 21, 2025 pm 11:39 PM
Exchanges that support cross-chain transactions: 1. Binance, 2. Uniswap, 3. SushiSwap, 4. Curve Finance, 5. Thorchain, 6. 1inch Exchange, 7. DLN Trade, these platforms support multi-chain asset transactions through various technologies.
 Why is the rise or fall of virtual currency prices? Why is the rise or fall of virtual currency prices?
Apr 21, 2025 am 08:57 AM
Why is the rise or fall of virtual currency prices? Why is the rise or fall of virtual currency prices?
Apr 21, 2025 am 08:57 AM
Factors of rising virtual currency prices include: 1. Increased market demand, 2. Decreased supply, 3. Stimulated positive news, 4. Optimistic market sentiment, 5. Macroeconomic environment; Decline factors include: 1. Decreased market demand, 2. Increased supply, 3. Strike of negative news, 4. Pessimistic market sentiment, 5. Macroeconomic environment.
 What is the analysis chart of Bitcoin finished product structure? How to draw?
Apr 21, 2025 pm 07:42 PM
What is the analysis chart of Bitcoin finished product structure? How to draw?
Apr 21, 2025 pm 07:42 PM
The steps to draw a Bitcoin structure analysis chart include: 1. Determine the purpose and audience of the drawing, 2. Select the right tool, 3. Design the framework and fill in the core components, 4. Refer to the existing template. Complete steps ensure that the chart is accurate and easy to understand.
 What are the hybrid blockchain trading platforms?
Apr 21, 2025 pm 11:36 PM
What are the hybrid blockchain trading platforms?
Apr 21, 2025 pm 11:36 PM
Suggestions for choosing a cryptocurrency exchange: 1. For liquidity requirements, priority is Binance, Gate.io or OKX, because of its order depth and strong volatility resistance. 2. Compliance and security, Coinbase, Kraken and Gemini have strict regulatory endorsement. 3. Innovative functions, KuCoin's soft staking and Bybit's derivative design are suitable for advanced users.
 How to win KERNEL airdrop rewards on Binance Full process strategy
Apr 21, 2025 pm 01:03 PM
How to win KERNEL airdrop rewards on Binance Full process strategy
Apr 21, 2025 pm 01:03 PM
In the bustling world of cryptocurrencies, new opportunities always emerge. At present, KernelDAO (KERNEL) airdrop activity is attracting much attention and attracting the attention of many investors. So, what is the origin of this project? What benefits can BNB Holder get from it? Don't worry, the following will reveal it one by one for you.
 Aavenomics is a recommendation to modify the AAVE protocol token and introduce token repurchase, which has reached the quorum number of people.
Apr 21, 2025 pm 06:24 PM
Aavenomics is a recommendation to modify the AAVE protocol token and introduce token repurchase, which has reached the quorum number of people.
Apr 21, 2025 pm 06:24 PM
Aavenomics is a proposal to modify the AAVE protocol token and introduce token repos, which has implemented a quorum for AAVEDAO. Marc Zeller, founder of the AAVE Project Chain (ACI), announced this on X, noting that it marks a new era for the agreement. Marc Zeller, founder of the AAVE Chain Initiative (ACI), announced on X that the Aavenomics proposal includes modifying the AAVE protocol token and introducing token repos, has achieved a quorum for AAVEDAO. According to Zeller, this marks a new era for the agreement. AaveDao members voted overwhelmingly to support the proposal, which was 100 per week on Wednesday
 The top ten free platform recommendations for real-time data on currency circle markets are released
Apr 22, 2025 am 08:12 AM
The top ten free platform recommendations for real-time data on currency circle markets are released
Apr 22, 2025 am 08:12 AM
Cryptocurrency data platforms suitable for beginners include CoinMarketCap and non-small trumpet. 1. CoinMarketCap provides global real-time price, market value, and trading volume rankings for novice and basic analysis needs. 2. The non-small quotation provides a Chinese-friendly interface, suitable for Chinese users to quickly screen low-risk potential projects.
