
 Technology peripherals
AI
With less than 1,000 lines of code, the PyTorch team made Llama 7B 10 times faster
Technology peripherals
AI
With less than 1,000 lines of code, the PyTorch team made Llama 7B 10 times faster
With less than 1,000 lines of code, the PyTorch team made Llama 7B 10 times faster

The PyTorch team personally teaches you how to accelerate large model inference.

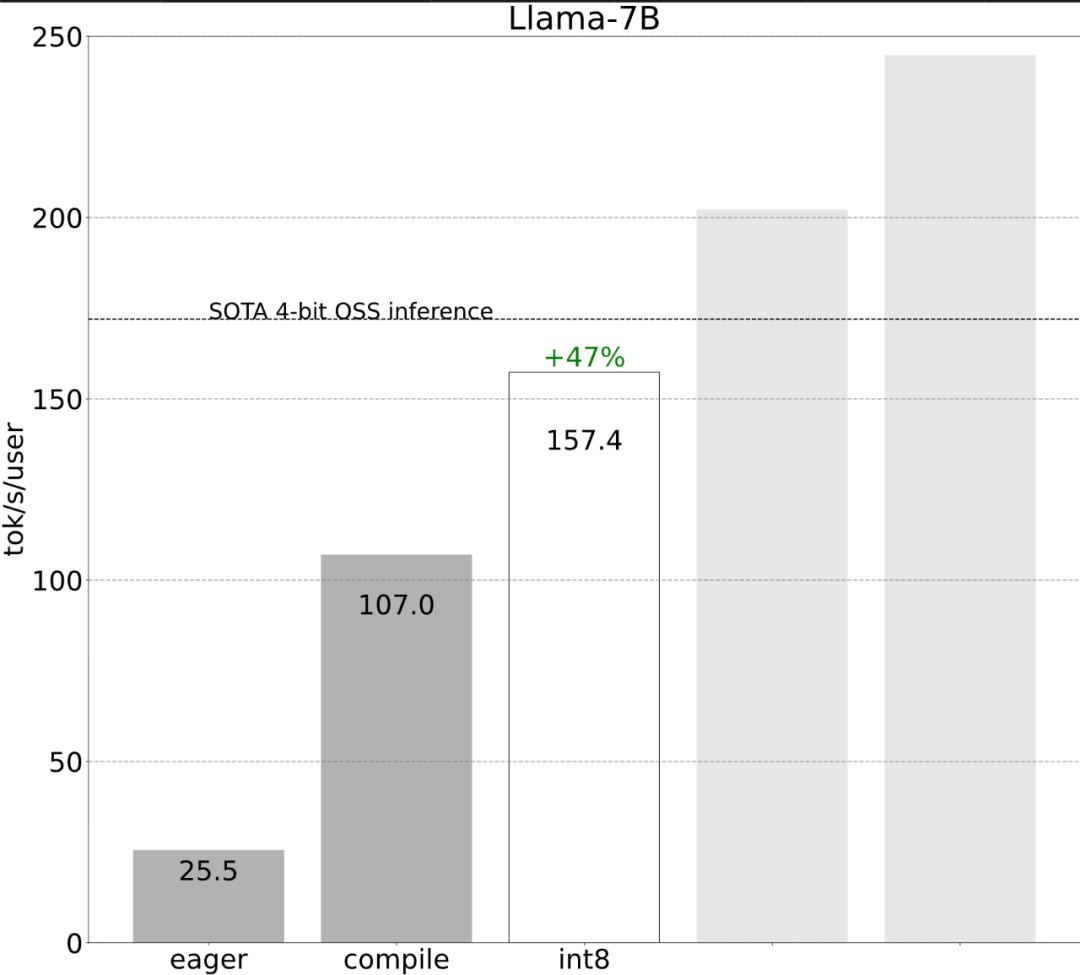
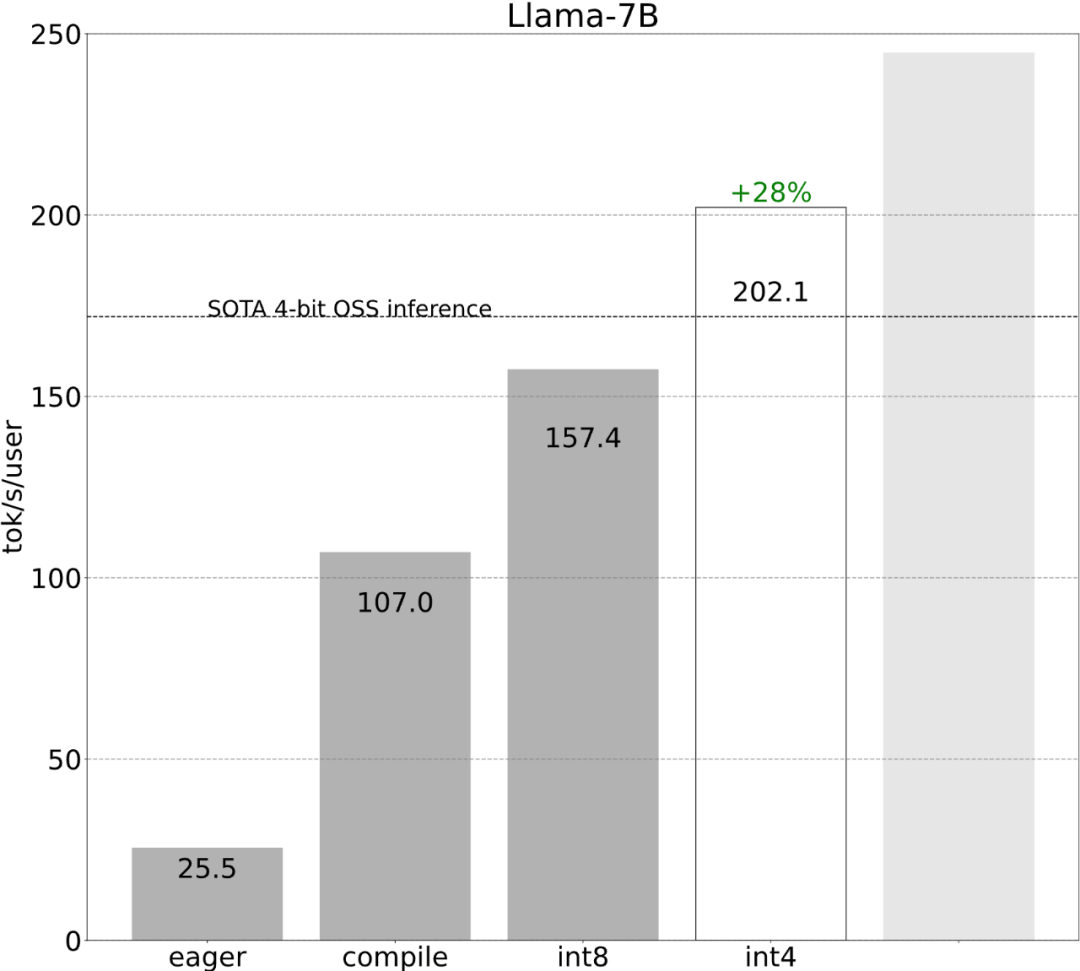
Let’s take a look at the results first. The team rewrote LLM, and the inference speed was 10 times faster than the baseline, without losing accuracy and using less than 1000 lines of pure native PyTorch code!
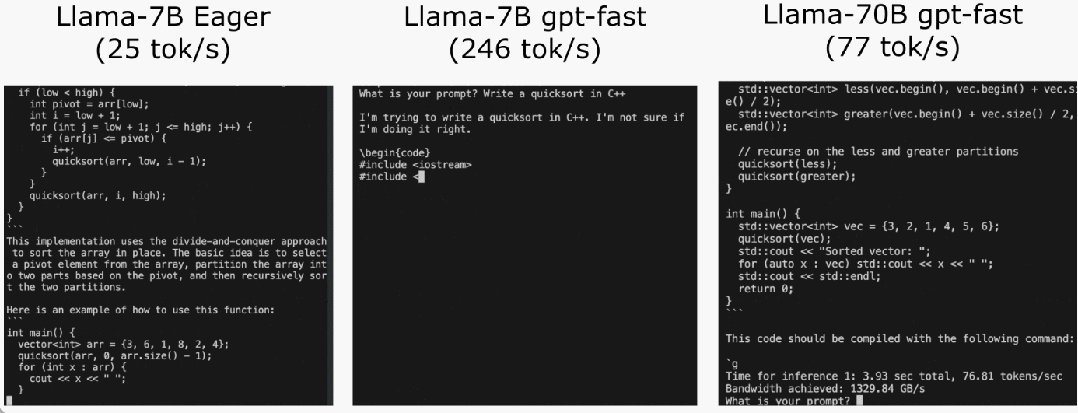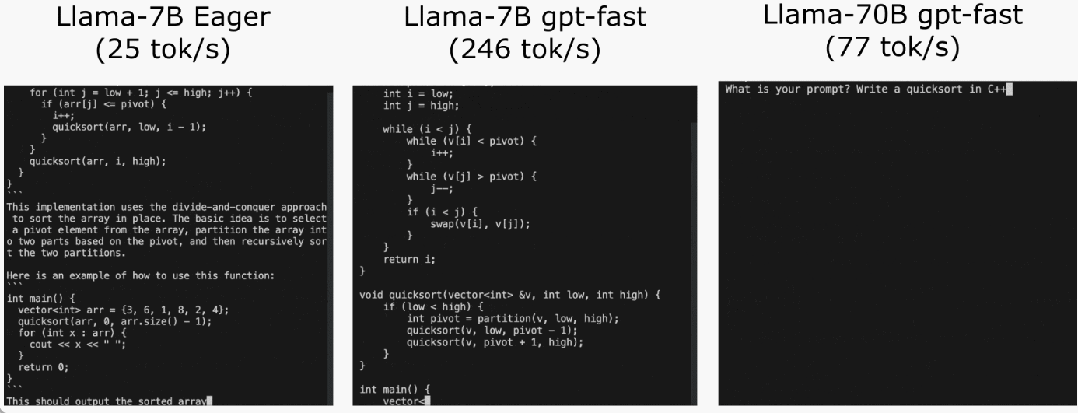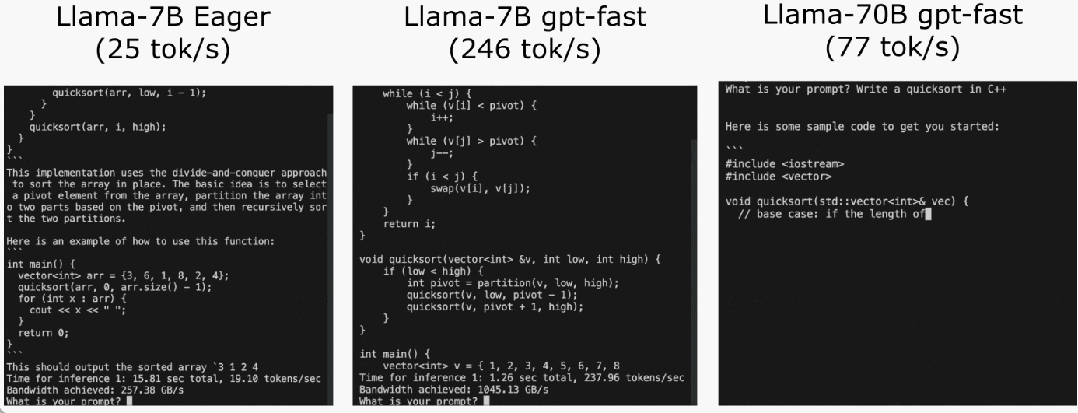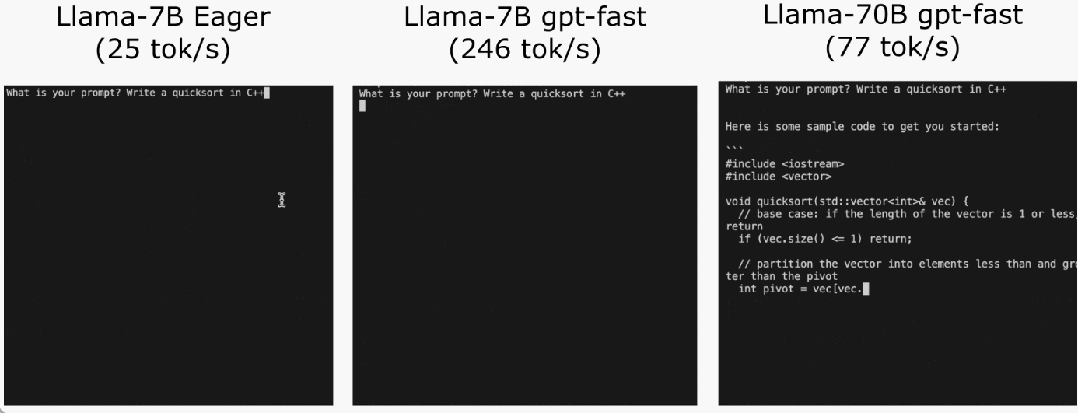
These optimizations include:
- Torch.compile: PyTorch model compiler, PyTorch 2.0 adds a new function called torch.compile (), which can accelerate existing models with one line of code;
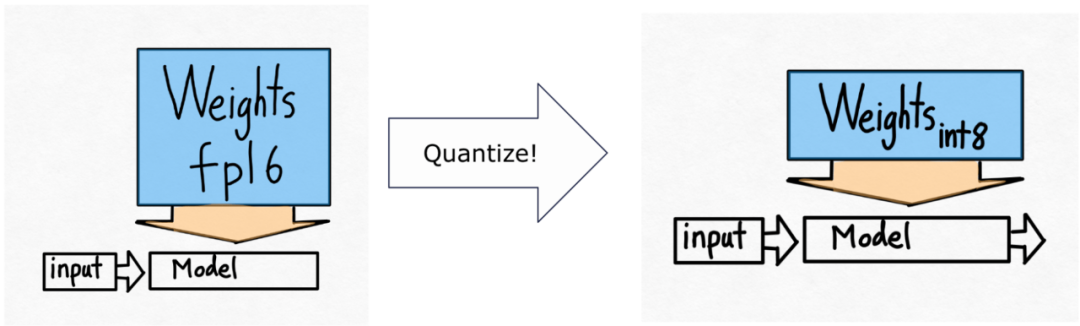
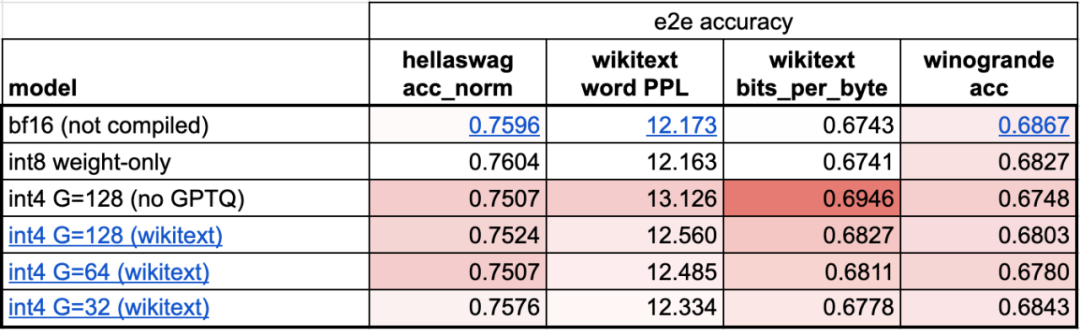
- GPU quantization: by reducing Computational accuracy to accelerate the model;
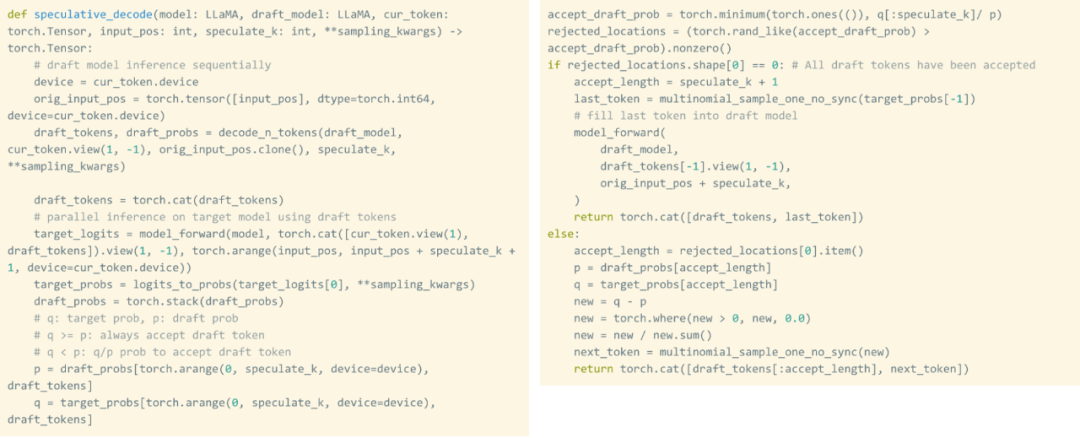
- Speculative Decoding: a large model inference acceleration method that uses a small "draft" model to predict the output of a large "target" model;
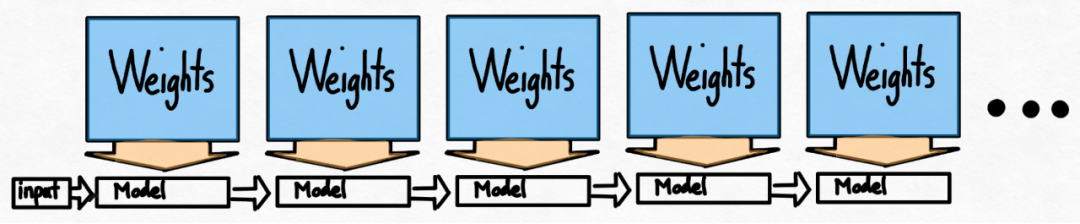
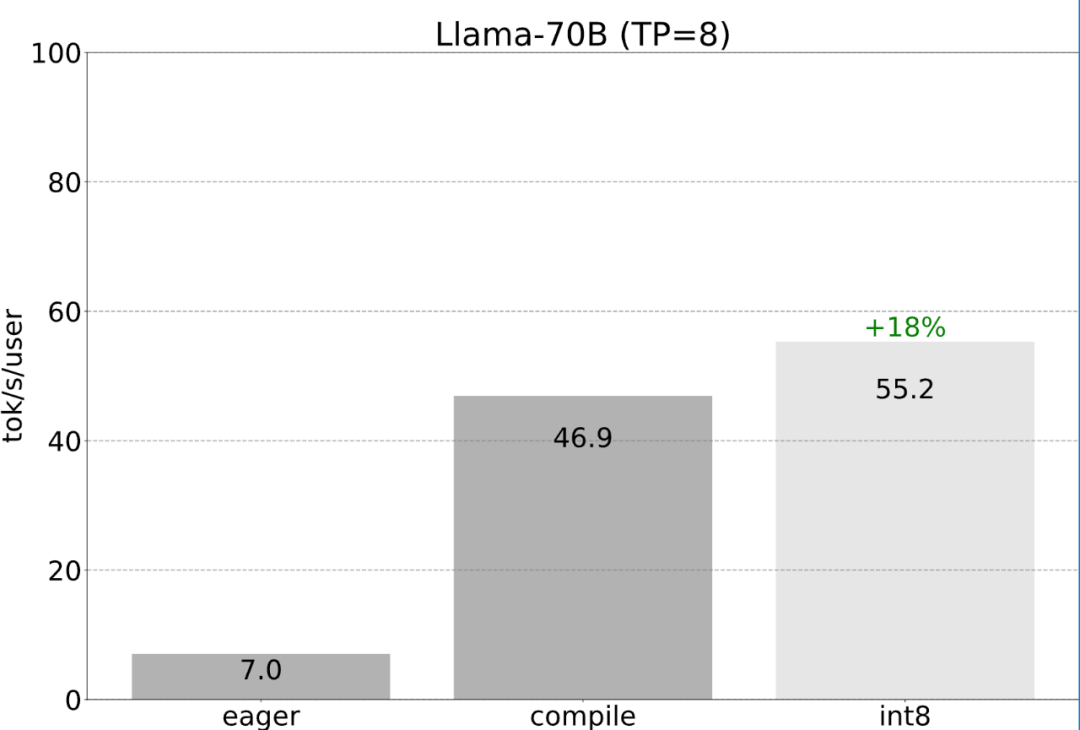
- Tensor Parallel: Accelerate model inference by running models on multiple devices.
Next, let’s see how each step is implemented.
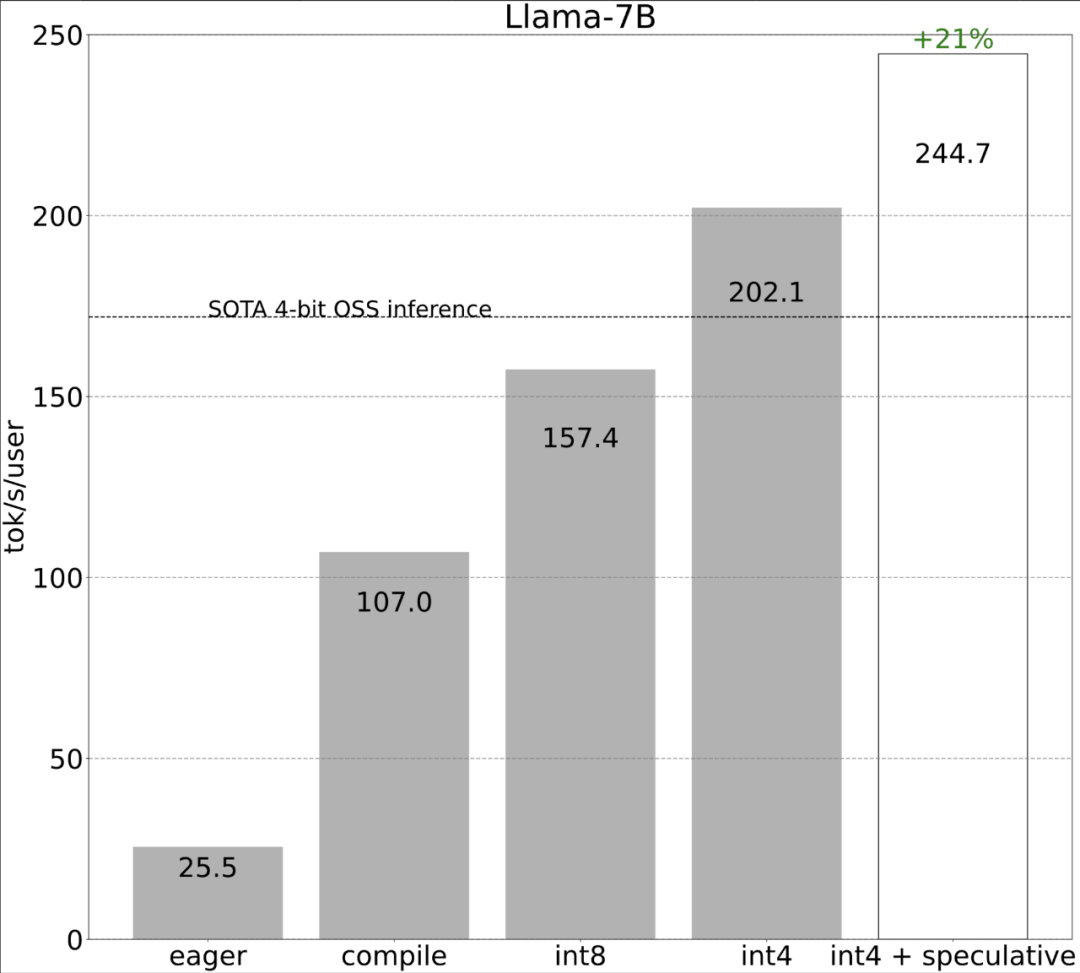
The study shows that without optimization , the inference performance of the large model is 25.5 tok/s, and the effect is not very good:
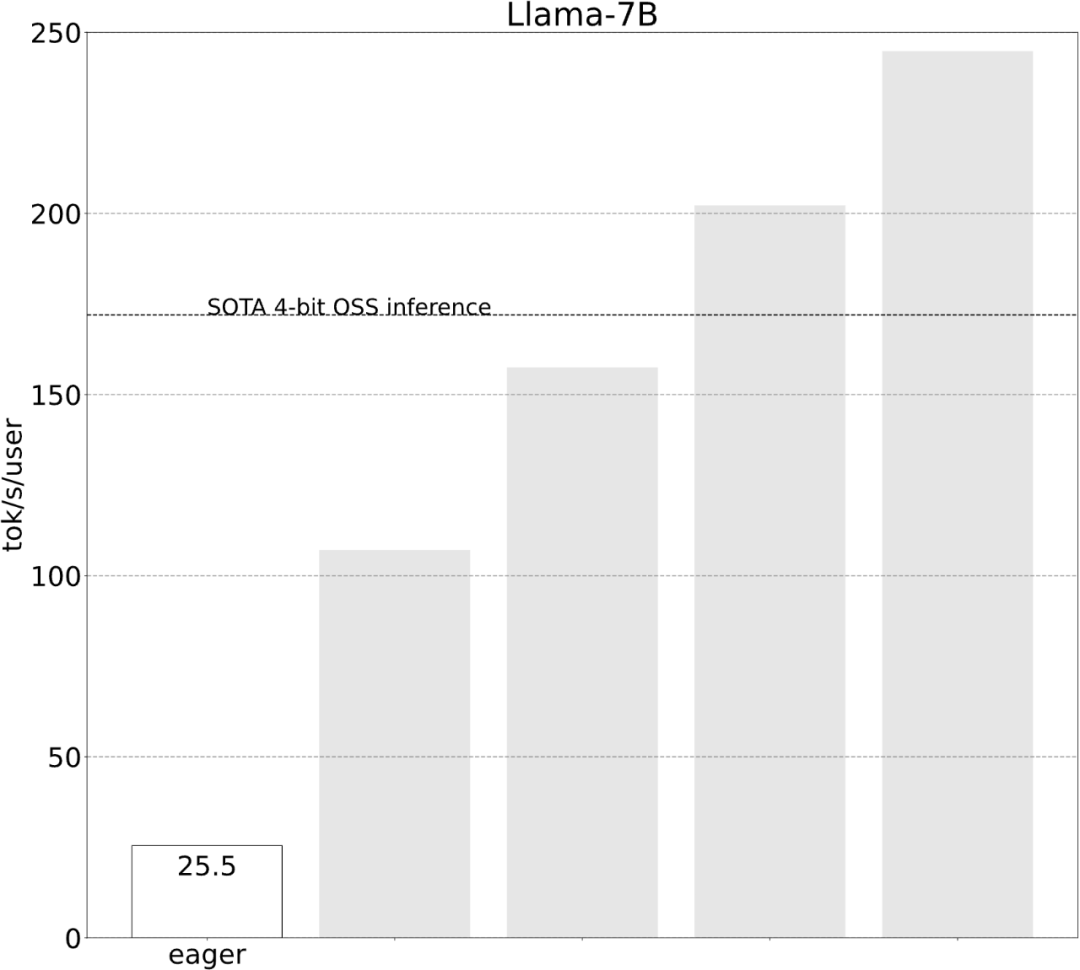 After some exploration, I finally found the reason: excessive CPU overhead. Then there is the following 6-step optimization process.
After some exploration, I finally found the reason: excessive CPU overhead. Then there is the following 6-step optimization process.

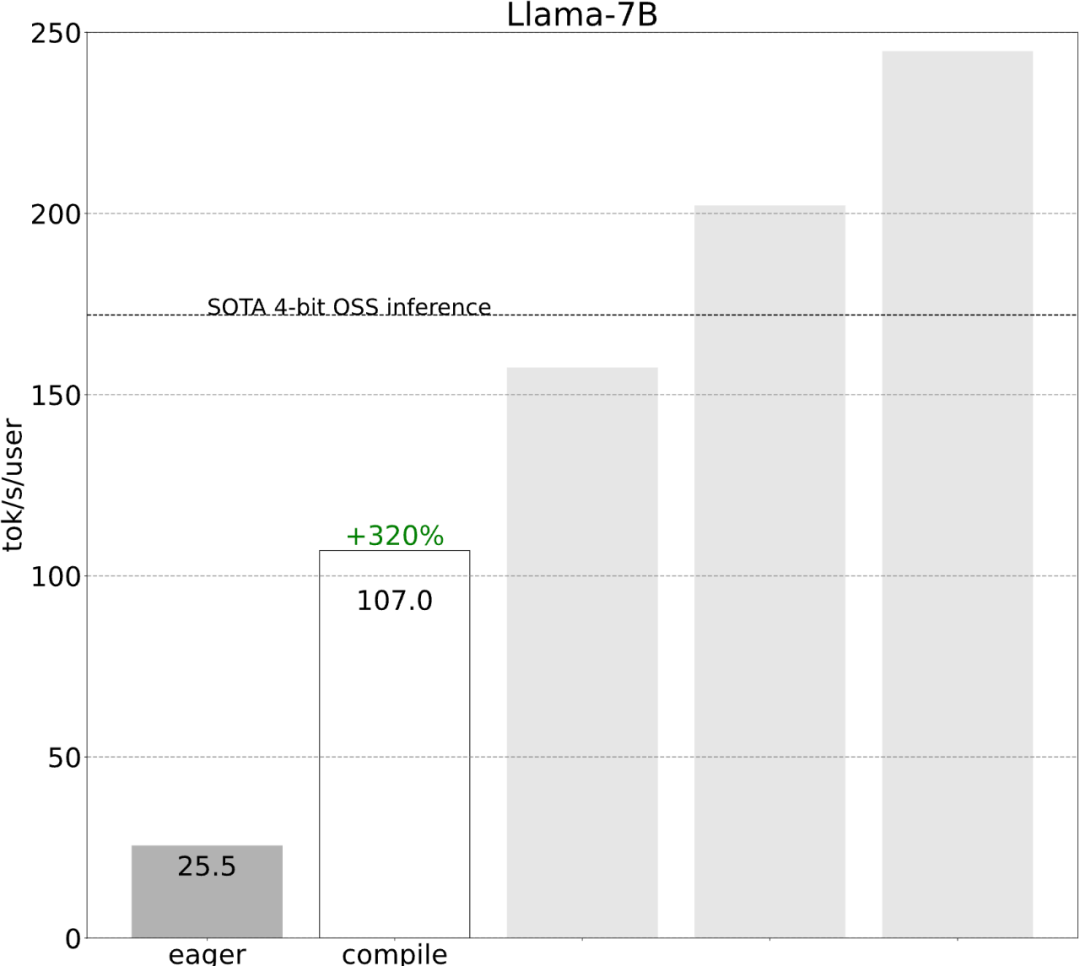
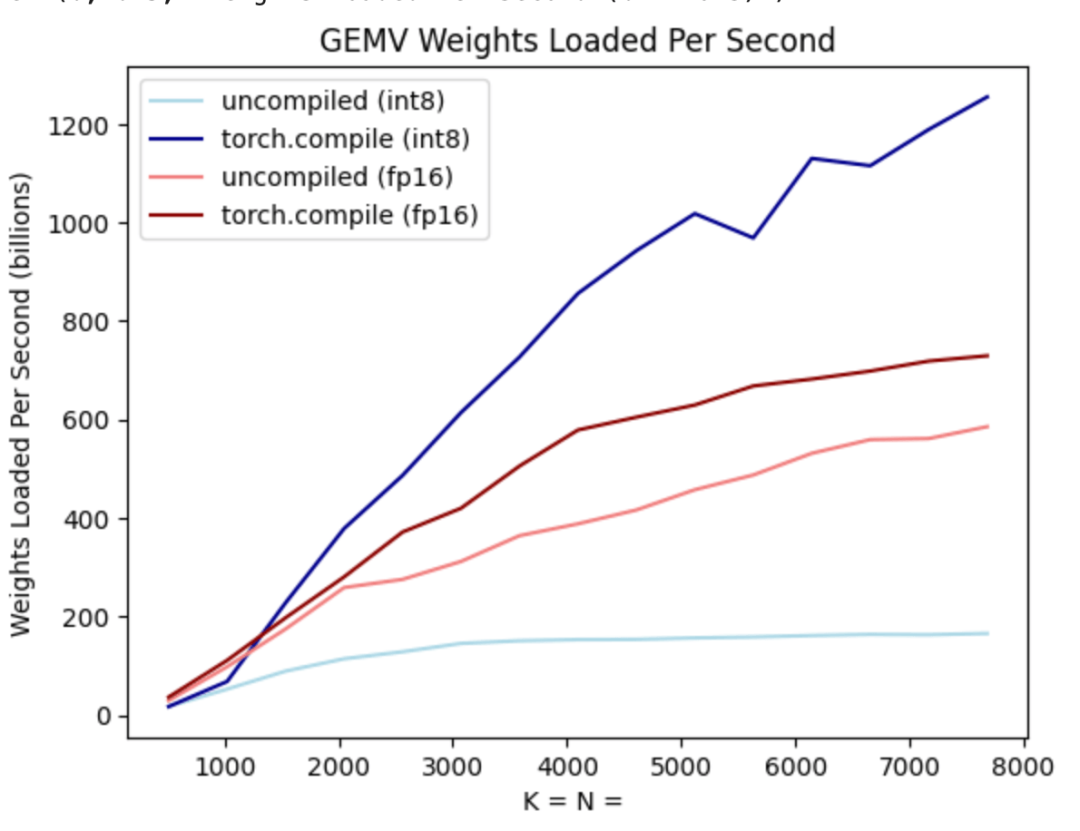
torch.compile allows users to capture larger areas into a single compilation area, especially when mode="reduce-overhead" (refer to the code below), this feature is very useful for reducing CPU overhead. Effective. In addition, this article also specifies fullgraph=True to verify that there is no "graph interruption" in the model (that is, the part that torch.compile cannot compile).
 #However, even with the blessing of torch.compile, there are still some obstacles.
#However, even with the blessing of torch.compile, there are still some obstacles.
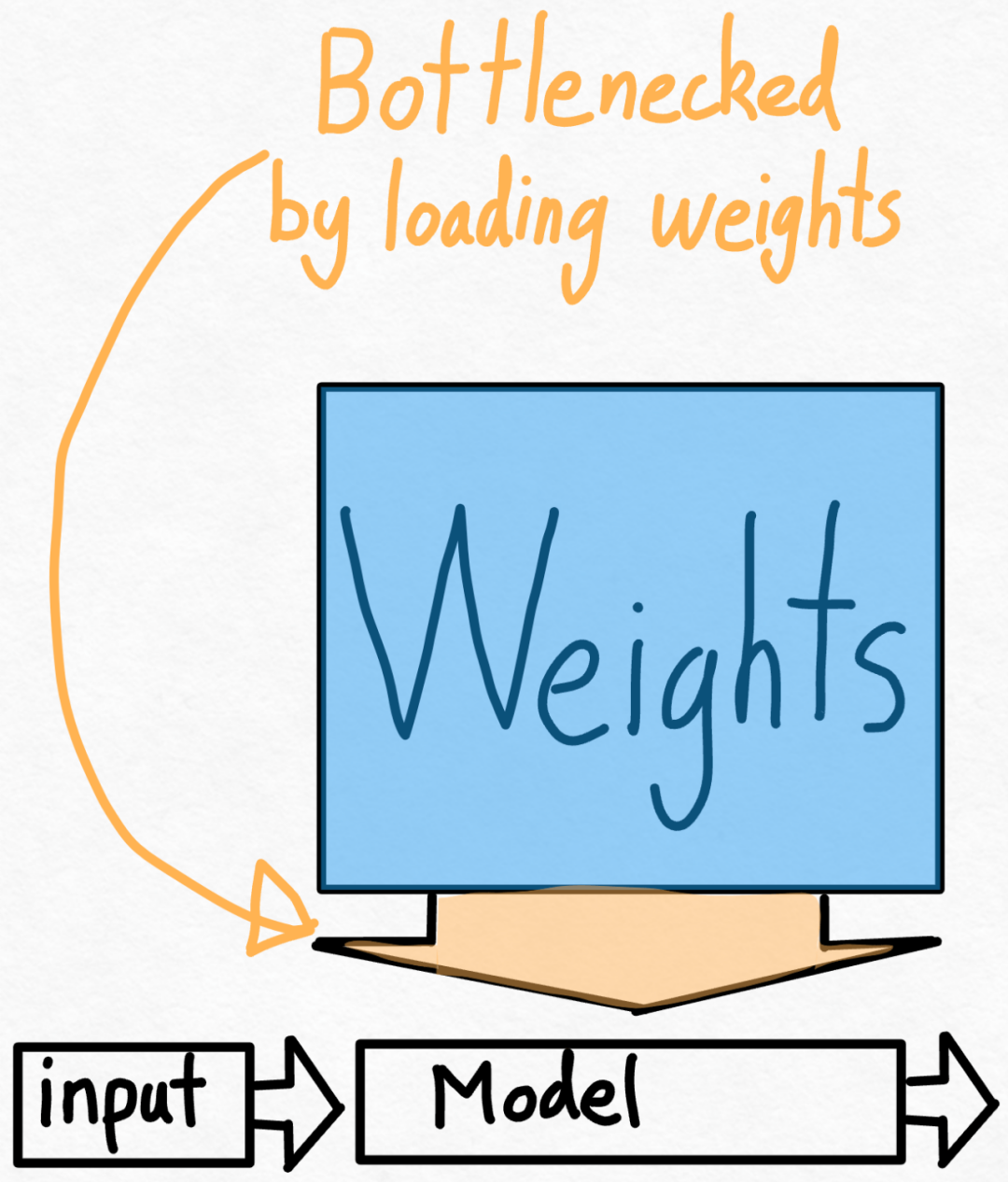
The first hurdle is the kv cache. That is, when the user generates more tokens, the "logical length" of the kv cache will grow. This problem arises for two reasons: first, it is very expensive to reallocate (and copy) the kv cache every time the cache grows; second, this dynamic allocation makes it more difficult to reduce the overhead.
In order to solve this problem, this article uses a static KV cache, statically allocates the size of the KV cache, and then masks out unused values in the attention mechanism.


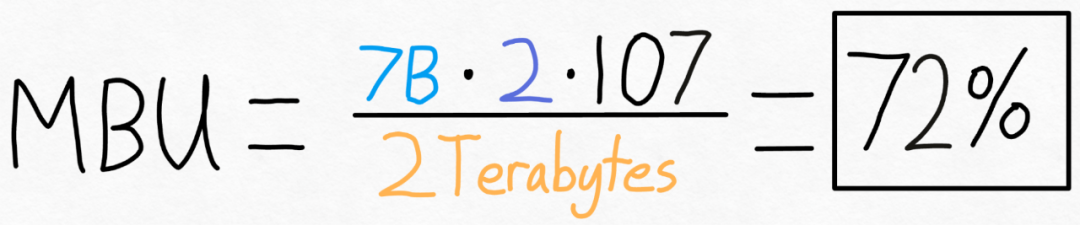



The above is the detailed content of With less than 1,000 lines of code, the PyTorch team made Llama 7B 10 times faster. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 A Diffusion Model Tutorial Worth Your Time, from Purdue University
Apr 07, 2024 am 09:01 AM
A Diffusion Model Tutorial Worth Your Time, from Purdue University
Apr 07, 2024 am 09:01 AM
Diffusion can not only imitate better, but also "create". The diffusion model (DiffusionModel) is an image generation model. Compared with the well-known algorithms such as GAN and VAE in the field of AI, the diffusion model takes a different approach. Its main idea is a process of first adding noise to the image and then gradually denoising it. How to denoise and restore the original image is the core part of the algorithm. The final algorithm is able to generate an image from a random noisy image. In recent years, the phenomenal growth of generative AI has enabled many exciting applications in text-to-image generation, video generation, and more. The basic principle behind these generative tools is the concept of diffusion, a special sampling mechanism that overcomes the limitations of previous methods.
 Generate PPT with one click! Kimi: Let the 'PPT migrant workers' become popular first
Aug 01, 2024 pm 03:28 PM
Generate PPT with one click! Kimi: Let the 'PPT migrant workers' become popular first
Aug 01, 2024 pm 03:28 PM
Kimi: In just one sentence, in just ten seconds, a PPT will be ready. PPT is so annoying! To hold a meeting, you need to have a PPT; to write a weekly report, you need to have a PPT; to make an investment, you need to show a PPT; even when you accuse someone of cheating, you have to send a PPT. College is more like studying a PPT major. You watch PPT in class and do PPT after class. Perhaps, when Dennis Austin invented PPT 37 years ago, he did not expect that one day PPT would become so widespread. Talking about our hard experience of making PPT brings tears to our eyes. "It took three months to make a PPT of more than 20 pages, and I revised it dozens of times. I felt like vomiting when I saw the PPT." "At my peak, I did five PPTs a day, and even my breathing was PPT." If you have an impromptu meeting, you should do it
 The perfect combination of PyCharm and PyTorch: detailed installation and configuration steps
Feb 21, 2024 pm 12:00 PM
The perfect combination of PyCharm and PyTorch: detailed installation and configuration steps
Feb 21, 2024 pm 12:00 PM
PyCharm is a powerful integrated development environment (IDE), and PyTorch is a popular open source framework in the field of deep learning. In the field of machine learning and deep learning, using PyCharm and PyTorch for development can greatly improve development efficiency and code quality. This article will introduce in detail how to install and configure PyTorch in PyCharm, and attach specific code examples to help readers better utilize the powerful functions of these two. Step 1: Install PyCharm and Python
 Introduction to five sampling methods in natural language generation tasks and Pytorch code implementation
Feb 20, 2024 am 08:50 AM
Introduction to five sampling methods in natural language generation tasks and Pytorch code implementation
Feb 20, 2024 am 08:50 AM
In natural language generation tasks, sampling method is a technique to obtain text output from a generative model. This article will discuss 5 common methods and implement them using PyTorch. 1. GreedyDecoding In greedy decoding, the generative model predicts the words of the output sequence based on the input sequence time step by time. At each time step, the model calculates the conditional probability distribution of each word, and then selects the word with the highest conditional probability as the output of the current time step. This word becomes the input to the next time step, and the generation process continues until some termination condition is met, such as a sequence of a specified length or a special end marker. The characteristic of GreedyDecoding is that each time the current conditional probability is the best
 Tutorial on installing PyCharm with PyTorch
Feb 24, 2024 am 10:09 AM
Tutorial on installing PyCharm with PyTorch
Feb 24, 2024 am 10:09 AM
As a powerful deep learning framework, PyTorch is widely used in various machine learning projects. As a powerful Python integrated development environment, PyCharm can also provide good support when implementing deep learning tasks. This article will introduce in detail how to install PyTorch in PyCharm and provide specific code examples to help readers quickly get started using PyTorch for deep learning tasks. Step 1: Install PyCharm First, we need to make sure we have
 All CVPR 2024 awards announced! Nearly 10,000 people attended the conference offline, and a Chinese researcher from Google won the best paper award
Jun 20, 2024 pm 05:43 PM
All CVPR 2024 awards announced! Nearly 10,000 people attended the conference offline, and a Chinese researcher from Google won the best paper award
Jun 20, 2024 pm 05:43 PM
In the early morning of June 20th, Beijing time, CVPR2024, the top international computer vision conference held in Seattle, officially announced the best paper and other awards. This year, a total of 10 papers won awards, including 2 best papers and 2 best student papers. In addition, there were 2 best paper nominations and 4 best student paper nominations. The top conference in the field of computer vision (CV) is CVPR, which attracts a large number of research institutions and universities every year. According to statistics, a total of 11,532 papers were submitted this year, and 2,719 were accepted, with an acceptance rate of 23.6%. According to Georgia Institute of Technology’s statistical analysis of CVPR2024 data, from the perspective of research topics, the largest number of papers is image and video synthesis and generation (Imageandvideosyn
 Five programming software for getting started with learning C language
Feb 19, 2024 pm 04:51 PM
Five programming software for getting started with learning C language
Feb 19, 2024 pm 04:51 PM
As a widely used programming language, C language is one of the basic languages that must be learned for those who want to engage in computer programming. However, for beginners, learning a new programming language can be difficult, especially due to the lack of relevant learning tools and teaching materials. In this article, I will introduce five programming software to help beginners get started with C language and help you get started quickly. The first programming software was Code::Blocks. Code::Blocks is a free, open source integrated development environment (IDE) for
 so fast! Recognize video speech into text in just a few minutes with less than 10 lines of code
Feb 27, 2024 pm 01:55 PM
so fast! Recognize video speech into text in just a few minutes with less than 10 lines of code
Feb 27, 2024 pm 01:55 PM
Hello everyone, I am Kite. Two years ago, the need to convert audio and video files into text content was difficult to achieve, but now it can be easily solved in just a few minutes. It is said that in order to obtain training data, some companies have fully crawled videos on short video platforms such as Douyin and Kuaishou, and then extracted the audio from the videos and converted them into text form to be used as training corpus for big data models. If you need to convert a video or audio file to text, you can try this open source solution available today. For example, you can search for the specific time points when dialogues in film and television programs appear. Without further ado, let’s get to the point. Whisper is OpenAI’s open source Whisper. Of course it is written in Python. It only requires a few simple installation packages.
